Агент вместо чата: анализ данных без copy-paste
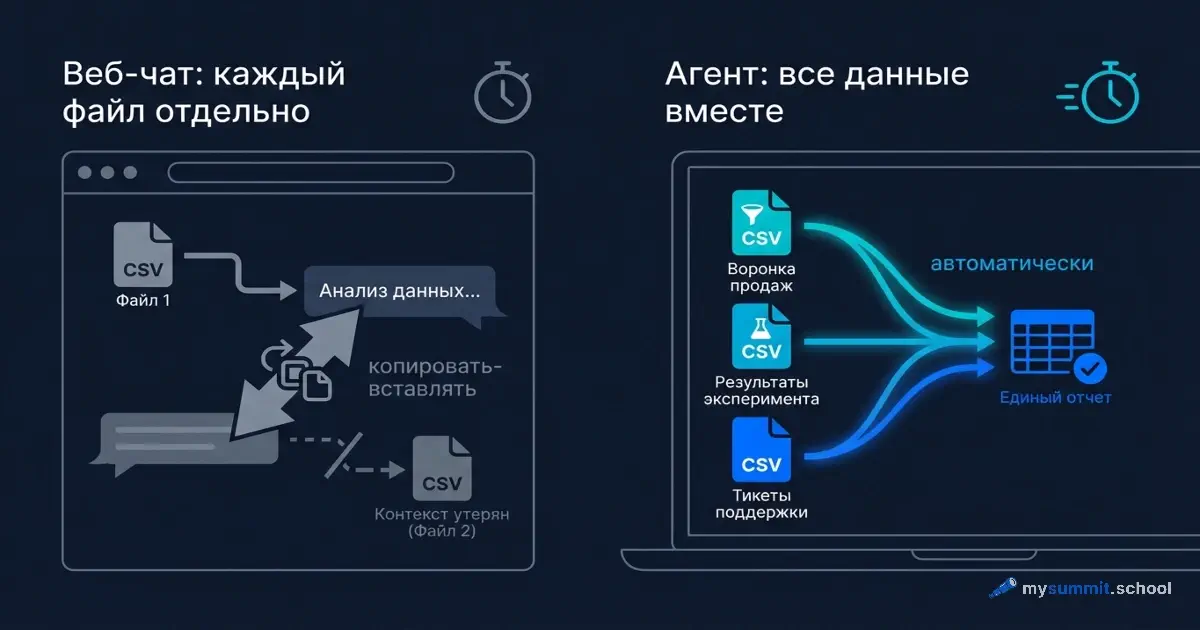
У вас три файла с данными: воронка активации, результаты A/B-теста и тикеты поддержки. Задача – понять, почему онбординг проседает. Вы открываете ChatGPT, загружаете первый файл, задаёте вопрос. Получаете ответ. Загружаете второй файл. ChatGPT спрашивает: «Можете напомнить контекст?» Загружаете третий. Контекст первого файла уже вытеснен.
Через сорок минут у вас три отдельных разговора, ни один из которых не отвечает на исходный вопрос. Потому что вопрос был один, а данные – в трёх местах.
Это не проблема ChatGPT. Это проблема подхода.
Два способа работать с данными
Разница между «чат в браузере» и «агент на вашем ноутбуке» – не в мощности модели. Она в том, кто к кому идёт.
В чате вы приносите данные к модели. По кусочкам, через загрузку файлов, в пределах одного разговора. Модель отвечает на то, что видит прямо сейчас. Следующее сообщение – уже немного другой контекст.
В агентном режиме модель приходит к вашим данным. Агент устанавливается как обычное приложение на ноутбук, видит папку с вашими файлами и работает с ними напрямую – как аналитик, которому дали доступ к вашему компьютеру. Вы пишете ему задачу обычным текстом, как в Slack, – он читает файлы, считает, сохраняет результат. Это та самая идея BYOA – но в практическом, а не концептуальном измерении.
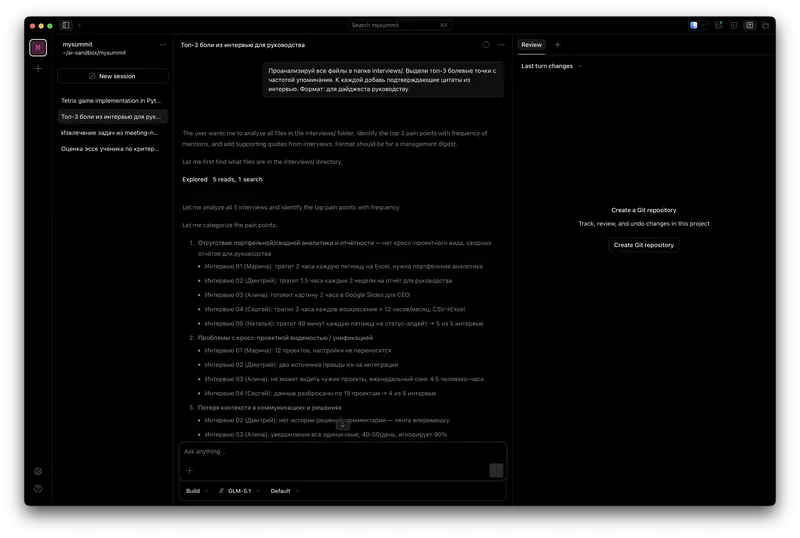
Разница кажется технической. На практике она меняет всё.
Конкретная задача, два способа решения
Представим реальный сценарий. Продакт-менеджер SaaS-сервиса замечает: конверсия новых пользователей в активных застряла на 38% четыре месяца подряд. Есть три таблицы с данными.
Первая – воронка онбординга: регистрация, первое действие, второе действие, приглашение коллеги.
Вторая – результаты A/B-теста новой функции онбординга: контрольная и тестовая группы по 500 компаний каждая.
Третья – 350 тикетов поддержки от новых пользователей за последний квартал.
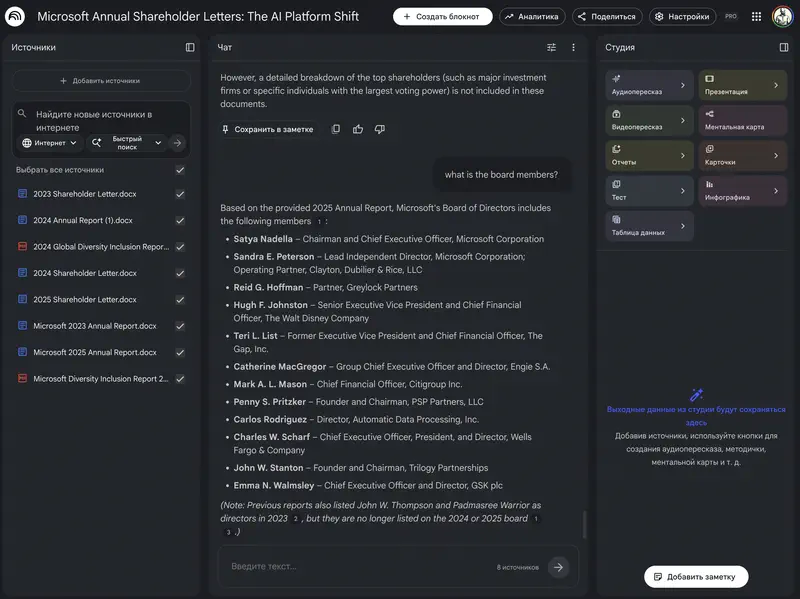
Вопрос: на каком шаге теряем людей, почему, и сработал ли эксперимент?
Вариант 1: ChatGPT, веб-интерфейс
Загружаете воронку. ChatGPT анализирует её и находит главную точку отвала. Хорошо. Загружаете тикеты – хотите понять, на что жалуются пользователи именно на этом шаге. ChatGPT говорит: «Вижу тикеты. Напомните, на каком шаге было падение?» Вы объясняете. Он анализирует.
Загружаете результаты теста. Новый файл. ChatGPT видит их, но уже не помнит точных цифр воронки из первого файла – в каком сегменте конверсия была 55%, а в каком 38%. Чтобы сопоставить, нужно вручную скопировать числа из первого разговора и вставить в третий.
Итог через час: три отдельных вывода, которые нужно вручную свести в один. И ещё вопрос: а вдруг где-то округлил или перепутал строки? Проверить это нельзя.
Вариант 2: агент на ноутбуке
Вы открываете папку с тремя таблицами и пишете агенту одним сообщением – как аналитику в Slack:
«Посмотри на воронку активации. Найди главную точку отвала. Затем открой тикеты и посмотри, какие жалобы связаны с этим шагом. Наконец, проверь результаты теста – сработал ли эксперимент в целом и по основному сегменту клиентов.»
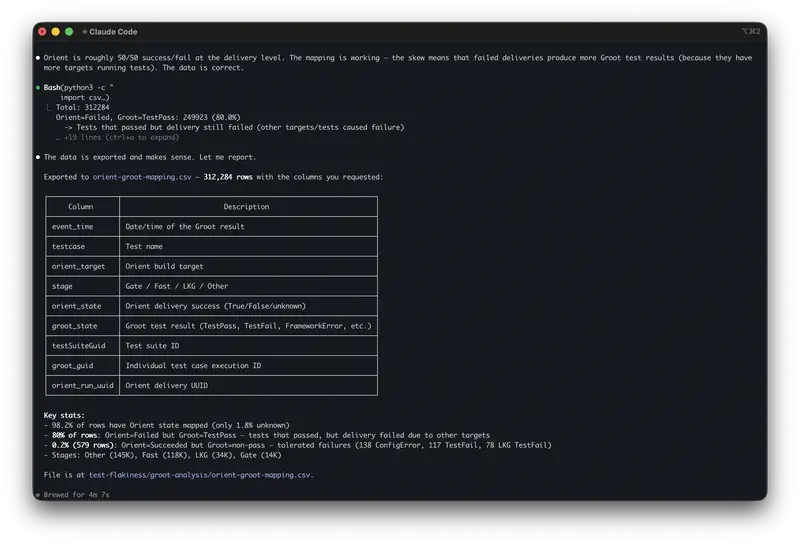
Агент открывает все три файла. Читает их. Пишет программный код для анализа воронки, запускает его, получает числа. Переходит к тикетам, группирует по темам, считает частоты. Загружает данные теста, сравнивает группы, проверяет статистику. Результаты всех трёх файлов находятся в одном контексте одновременно.
Весь процесс занимает несколько минут. Вы видите, как именно агент считал, – и можете проверить каждый шаг.
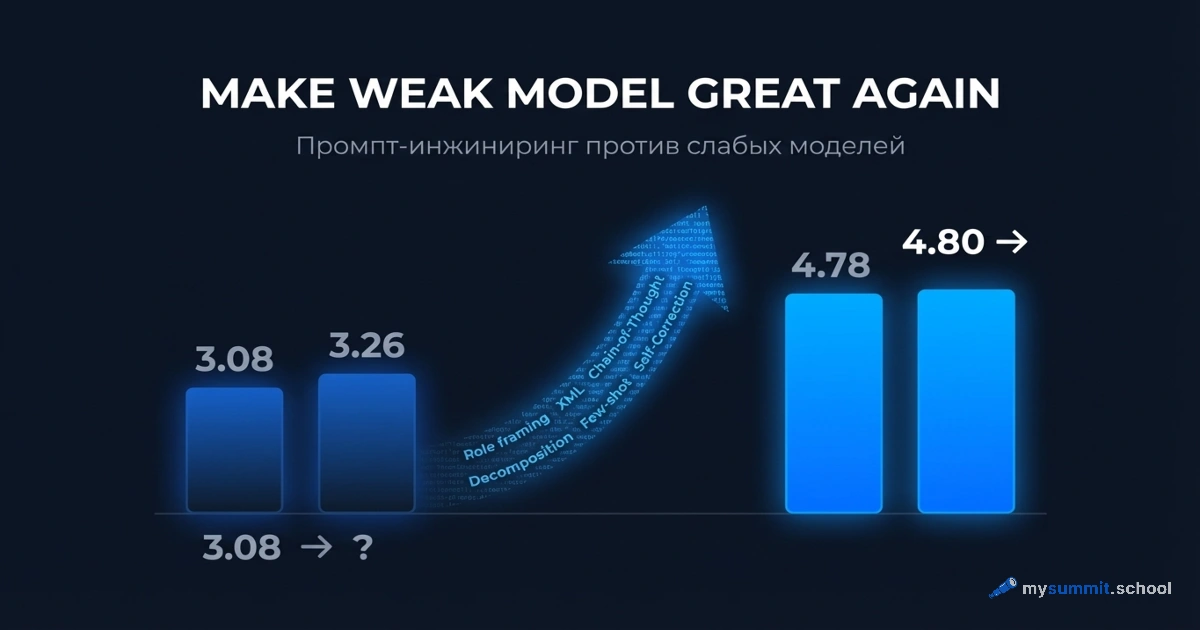
Агентный анализ данных – одна из тем курса. Попробуйте 9 практических задач менеджера в открытом модуле – бесплатно, без регистрации.
Доступ сразу после регистрации
Что меняется принципиально
Несколько вещей, которые выглядят мелкими, но определяют разницу в качестве анализа.
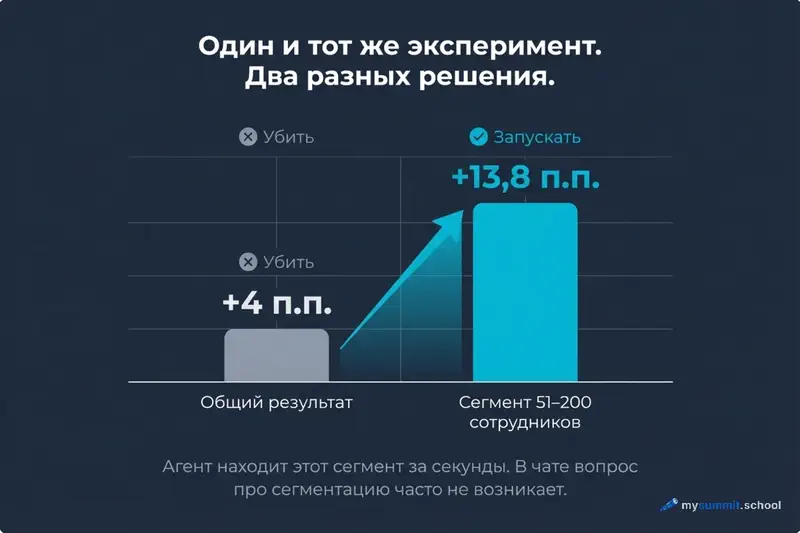
Агент одновременно видит, что на третьем шаге воронки отвал 45%, что в тикетах 31% жалоб именно на этот шаг, и что в эксперименте целевой сегмент показал +13,8 п.п. Эти три факта не нужно сводить вручную – они уже в одном выводе.
Кроме того, агент сохраняет то, как именно он считал. Завтра придут данные за следующий месяц – вы запускаете тот же анализ заново без лишних усилий. Это уже не одноразовый вопрос, а рутина. Именно здесь прячется скрытый налог на ИИ: 37% сэкономленного времени уходит на то, чтобы проверить и переделать результат. Когда у вас есть код, проверить можно за секунды.
Наконец, агент ссылается на конкретные записи в таблице. Вы можете открыть исходный файл и проверить. В чате модель говорит «большинство компаний среднего бизнеса» – и невозможно понять, это реальный паттерн или галлюцинация.
Когда агент всё равно галлюцинирует
Честный раздел, потому что агент – не магия.
Агент галлюцинирует в том же месте, что и чат: когда формулирует интерпретации, а не считает. Когда он считает – вы видите результат конкретного вычисления. Но когда агент говорит «это указывает на проблему с UX» – это его интерпретация, и она может быть неверной.
Хороший приём: после любого вывода попросить агента «покажи, из каких строк таблицы это следует». Агент должен ответить конкретными примерами или показать срез данных. Если он начинает объяснять словами без ссылки на данные – значит, интерпретирует, а не читает.
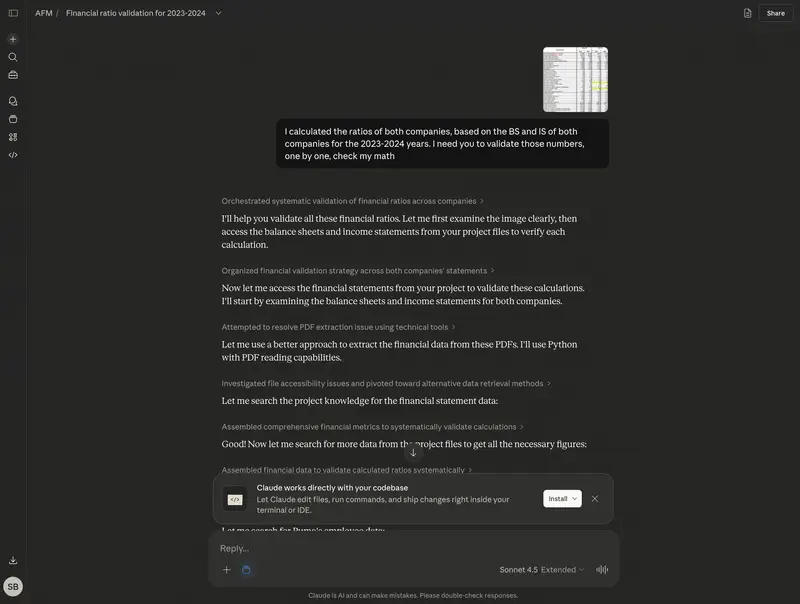
Второй момент: агент не знает вашего бизнес-контекста. Он находит, что в тестовой группе конверсия выросла на 4 п.п. в целом и на +13,8 п.п. в сегменте 51–200 сотрудников. Но вывод «запускать на 100% или нет» – ваш. Для этого нужно знать, какой сегмент является целевым, каков рынок, какова стоимость разработки.
Агент даёт точные данные. Решение принимаете вы.
Что показывает реальный анализ трёх файлов
Разберём конкретно, что находит агент в таком наборе данных.
Воронка активации (500 компаний). Агент считает конверсию на каждом шаге. Первый шаг – 77%, относительно нормально. Второй шаг – 55%. Это проблема: из 385 компаний, сделавших первое действие, только 210 переходят к следующему. Здесь теряется больше половины потенциальных активных пользователей.
Агент формулирует это как «основная точка отвала – переход между шагом 2 и шагом 3, 45% не переходят». Медианное время – 8 часов, тогда как первый шаг занимал 2 часа. Значит, пользователи возвращаются, но не завершают следующее действие.
Тикеты поддержки (350 штук). Агент группирует по темам. Обнаруживает: 31% тикетов – вопрос «как добавить объект вручную?». Ещё 27% – проблемы с подключением внешнего источника. 19% – загрузка файлов.
Это подтверждает гипотезу воронки: люди не понимают, как сделать второе действие. UX неочевиден.
Агент делает дополнительный шаг, который в чате вы, скорее всего, не попросили бы: сегментирует тикеты по размеру компании. Находит, что компании среднего размера (50–200 сотрудников) задают вопрос о ручном добавлении в два раза чаще, чем малые. Это целевой сегмент продукта – что делает проблему важнее.
Результаты теста (1 000 компаний, две группы). Топлайн: контроль 38,4%, тест 42,4%, прирост +4 п.п. – выглядит разочаровывающе. Прогнозировали больше, статистика на грани.
Агент сегментирует по размеру компании. В сегменте 51–200 сотрудников: контроль 39,2%, тест 53,0%, прирост +13,8 п.п. – сильный результат. Именно для целевого сегмента эксперимент сработал.
Вот это изменение – от «провальный эксперимент» к «победа для целевого сегмента» – агент обнаруживает, потому что держит все три файла в контексте одновременно. В чате вам пришлось бы задавать этот вопрос отдельно, и не факт, что он возник бы.
Когда НЕ нужен агент
Агентный режим не всегда оправдан.
Если нужно быстро посмотреть среднее значение в небольшой таблице из 50 строк – ChatGPT справится быстрее. Открывать дополнительный инструмент не нужно.
Если данные конфиденциальны и вы не до конца понимаете, как работает инструмент, – лучше разобраться с этим заранее. Облачные модели (ChatGPT, Claude) обрабатывают данные на серверах провайдера. Это может быть неприемлемо для данных под NDA. Агент, который работает с локальной моделью на вашем ноутбуке, – другой сценарий, но он требует отдельной подготовки.
Если задача – написать текст, придумать структуру, обсудить решение – агент не даёт преимуществ. Его ценность именно в работе с файлами.
Как начать: инструменты для России
Из инструментов, о которых говорят чаще всего: Claude Code от Anthropic (требует подписку за $100 в месяц и в России официально недоступен), Kilo Code (расширение для VS Code, хорошо для тех, кто уже работает с кодом), OpenCode (открытое ПО, работает с любыми моделями).
Для старта без VPN и практически бесплатно – OpenCode с российскими (доступны только локально) или китайскими моделями. Kimi K2 и DeepSeek доступны в России напрямую, стоят доли цента за запрос и по качеству аналитики не уступают GPT-4o на структурированных данных.
OpenCode ставится как обычное приложение и запускается с папки с вашими файлами. Первый анализ – за 15 минут после установки. Подробнее о том, как это работает на практике, – в статье об OpenCode. Там же три задачи, которые стоит попробовать в первый день.
Агент читает файлы, считает, сегментирует данные. Проверьте свой подход к анализу на 9 реальных задачах менеджера – бесплатно, без регистрации.
Доступ сразу после регистрации
Что меняется в работе
Агентный анализ – не замена аналитику. Это способ убрать трение между вопросом и ответом.
Раньше между «я хочу понять, почему проседает метрика» и «вот анализ по трём файлам с сегментацией» – несколько часов работы или запрос к аналитику со временем ответа в несколько дней. Теперь – несколько минут.
Это меняет, какие вопросы вообще задают. Когда анализ стоит дорого, задают только важные вопросы. Когда стоит дёшево – начинают проверять гипотезы, которые раньше казались недостаточно важными для запроса.
В нашем примере с тремя файлами именно так и произошло. Топлайн теста выглядел плохо – +4 п.п., статистика на грани. Обычный вывод: итерировать или убить. Но агент за несколько секунд сегментировал данные – и оказалось, что для целевого сегмента результат сильный (+13,8 п.п.). Это решение «запускать» вместо «убить».
Удивительно, но самое важное здесь – не скорость. Важнее другое: анализ становится воспроизводимым. Через месяц, когда придут новые данные, вы запускаете тот же анализ заново. Это уже не разовый ответ – это аналитическая рутина.
Возможно, стоит различать два вида работы с данными: разовые вопросы (для них чат подходит хорошо) и регулярные аналитические рутины (для них агент меняет ситуацию принципиально). Большинство PM-задач, которые реально влияют на решения – воронки, когорты, эксперименты – это второй тип.
Что дальше: агент на ваших данных
Эта статья показала один тип задачи – разовый анализ трёх таблиц. Но настоящая ценность агента появляется позже: когда анализ перестаёт быть разовым и становится рутиной.
Это уже не «использовать агент», а «построить личного агента» – со своими рутинами, подключённого к вашим реальным данным.
Именно этому посвящён курс «Личный агент для менеджера», который мы запускаем. Несколько конкретных вещей поверх этой статьи:
- Вы начинаете с реальных данных с первого дня – уже на третий день курса агент работает с вашей настоящей почтой. Вы выгружаете её как обычный файл на ноутбуке, без участия ИТ-службы.
- По ходу курса вы собираете набор готовых сценариев под свои задачи – они остаются у вас после курса.
- После каждого блока вы загружаете результат работы и получаете персональный разбор – не самооценку, а реальный фидбек.
- Живой Q&A с автором, Telegram-канал одногруппников, разбор кейсов.
- Курс построен на инструментах, доступных в России без VPN. Стоимость за весь курс – несколько долларов за запросы к модели.
Курс готовится к запуску. Если хотите попасть в первую когорту – форма для записи чуть выше.
Инструмент есть. Теперь – навык
Пока курс «Личный агент» готовится к запуску, начните с основ: Фундамент курса закрывает промпт-инжиниринг и критическое мышление – без них агент выдаёт цифры, но не инсайты. Специализация «Управление продуктом» разбирает AI-анализ данных и работу с агентами на PM-задачах.