Агентский ресёрч конкурентов: цикл с поиском и проверкой
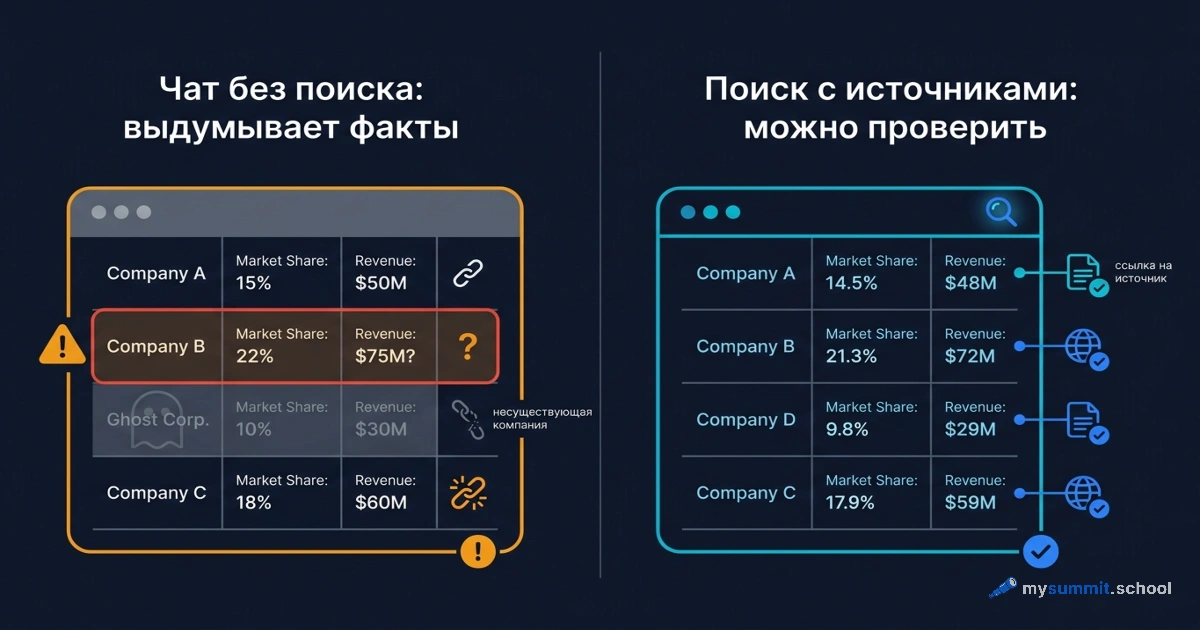
В предыдущем материале «Анализ конкурентов с ИИ: где модель выдумывает факты» мы показали, как наивный чат-бот сочиняет конкурентов: пять компаний в списке, две не существуют, обороты назначены на глаз. Рецепт там был один – проверять каждый факт руками. Но есть способ сократить количество выдумок ещё до проверки: проводить ресёрч не в чате, а в агентском инструменте, который сам ищет, открывает страницы и сверяет найденное за несколько итераций.
Этот материал – практический цикл такого ресёрча: от настройки инструмента до проверенного результата. Тот же пример, что и раньше, – оборудование для установок замедленного коксования (УЗК) для НПЗ. Боль та же, но инструмент другой.
Чем агент отличается от чата
Раз агент тоже ошибается и порой сочиняет – в чём тогда его преимущество перед обычным чатом?
Чат – это один вопрос и один ответ из памяти. Агент – это цикл. Получив цель, он сам решает, что искать, делает запрос в веб, открывает найденные страницы, сравнивает их между собой, помечает то, чего не нашёл, и при необходимости перепроверяет. Ближе к тому, как действует живой аналитик, чем к справочному автомату.
Для ресёрча разница принципиальная. У чата информация либо надёжно лежит в памяти, либо правдоподобно достраивается – и грань между этими режимами вы не видите. У агента есть «руки»: доступ к поиску и к страницам. Он работает с тем, что реально нашёл, а не с тем, что вероятнее всего сказал бы. Выдумки от этого не исчезают, но их становится заметно меньше – и почти у каждой появляется ссылка, которую можно открыть.
О том, как устроен агент как стек (модель, инструменты, память, цикл, управление), мы разобрали отдельно, а о переходе от чата к автономным агентам – в разборе GLM-5. Здесь – ровно столько, сколько нужно для ресёрча.
Что настроить до старта
Три вещи решают, будет ли ресёрч честным:
- Инструмент. OpenCode или Claude Code – берите тот, где агентский цикл включён по умолчанию. Главное, чтобы у модели были «руки»: доступ к веб-поиску и открытию страниц.
- Веб-поиск. Без него агент снова отвечает из памяти. Включите и проверьте, что он работает, а не имитируется: модель цитирует конкретные страницы, а не отговаривается «данными из открытых источников».
- MCP-подключения. MCP (Model Context Protocol) – стандарт для связи с внешними источниками: поиском, страницами, базами, API. Для ресёрча хватает веб-поиска и загрузки страницы, но именно MCP даёт доступ к живой информации, которой особенно мало на нишевых B2B-рынках.
Эти три настройки решают, будет ли агент вообще способен на честный ресёрч. Но способен – не значит умеет: дальше всё решает цикл, по которому вы его ведёте.
Откройте агентский цикл ресёрча на реальной задаче и сами увидите, где ИИ находит источники, а где всё ещё додумывает. 9 управленческих ситуаций, бесплатно и без регистрации.
Доступ сразу после регистрации
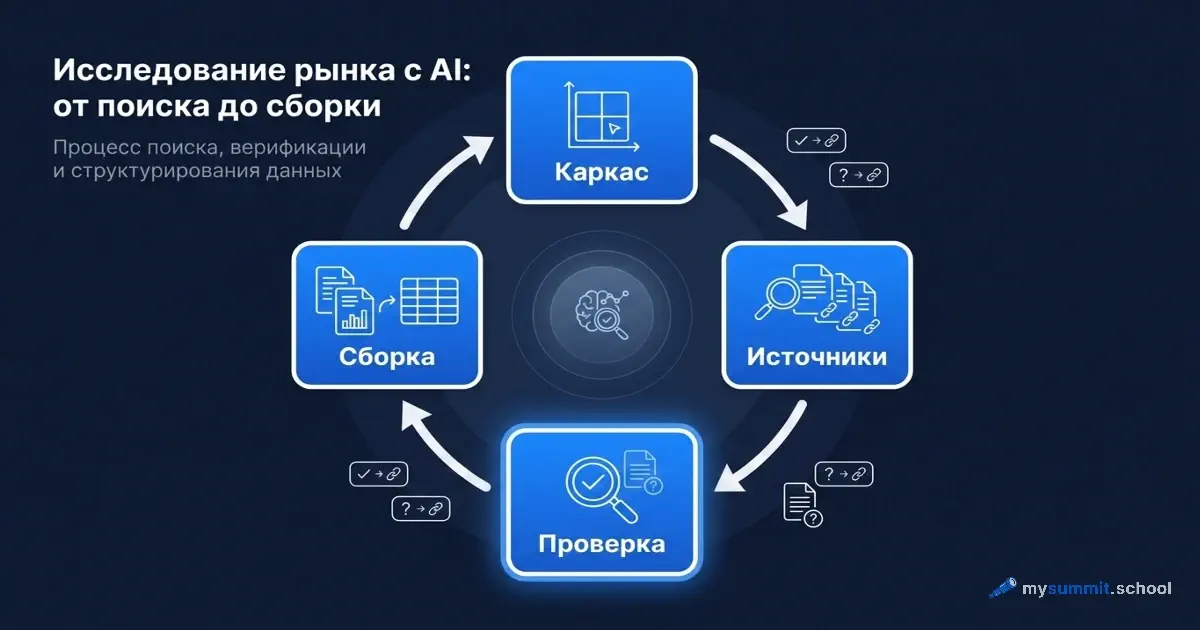
Цикл ресёрча за четыре шага
Всю работу я разбиваю на четыре шага. Первые два задаёт один промпт, но в агенте они выполняются последовательно, с поиском. Третий – отдельный проход в свежем окне, чтобы проверяющий не защищал собственный результат. Четвёртый – сборка только из проверенного.
Шаг 1. Каркас и план
Сначала агент строит скелет анализа: по каким осям сравнивать игроков и что выяснить про каждого. Это структура – та часть, где ИИ надёжен. Здесь выдумывать нечего, и модель быстро собирает разумный набор критериев даже для незнакомой ниши.
Обратите внимание: на этом этапе мы намеренно запрещаем модели называть компании. Так каркас не успевает обрасти выдумками, а список вопросов из шага 2 становится чеклистом, по которому дальше проверяется каждый найденный игрок.
Шаг 2. Сбор с источниками
Теперь агент идёт в поиск и заполняет каркас реальными игроками. Правило одно: каждое утверждение – название, цифра, год, проект – должно быть подкреплено ссылкой. Чего подтвердить не удалось, помечается отдельно, а не подменяется догадкой.
В агентском инструменте этот шаг выполняется с реальным поиском: модель обходит источники, открывает страницы и приписывает каждой строке ссылку. На выходе – таблица, у части строк есть подтверждение, часть помечена [НЕ ПРОВЕРЕНО]. Это уже не «уверенный ответ из памяти», а гипотеза с видимыми границами.
Шаг 3. Проверка-скептик
Самый важный шаг и тот, который чаще всего пропускают. Результат шага 2 нужно прогнать через второй промпт – в новом окне или другой модели. Причина проста: тот, кто написал ответ, не станет искать в нём ошибку. Проверять должен «посторонний» скептик.
В агенте этот шаг тоже идёт с поиском: скептик не просто «читает» таблицу, а открывает указанные ссылки и сверяет, действительно ли там есть приписанное. Именно здесь ловится самое коварное – реальная ссылка, пересказанная неточно. После этого прохода у вас остаётся только то, что пережило проверку.
Шаг 4. Сборка проверенного
Финал – не «дополнить анализ», а собрать результат только из того, что прошло шаг 3. Здесь хорошо работает режим с собственными источниками: вы кладёте в запрос проверенный материал, и модель синтезирует из него таблицу или служебную записку, не имея возможности ничего выдумать – ей неоткуда.
Разбор на примере УЗК
На узком рынке оборудования для установок замедленного коксования (тот же пример, на котором мы показывали выдумки наивного чат-бота) цикл работает именно так, как описано. После шага 1 у вас каркас: оси сравнения (ориентация на новое строительство или модернизацию, собственный инжиниринг, реализованные проекты на российских НПЗ) и чеклист из десятка вопросов.
После шага 2 – таблица игроков, у части строк есть ссылки на профильные издания и сайты производителей, несколько строк помечены [НЕ ПРОВЕРЕНО]. На этом этапе соблазн остановиться максимален: таблица выглядит законченной. Но именно среди непомеченных строк чаще всего прячется выдумка.
Шаг 3 убирает её: скептик открывает ссылки, и выясняется, что одна компания существует, но не делает УЗК-оборудование, а ссылка у другой ведёт на страницу, где приписанного проекта нет. Шаг 4 собирает из остатка короткий, но честный список – который уже можно класть в основу решения. Короткий проверенный список всегда полезнее длинного с выдумками.
Где агент всё ещё ошибается
Агент не делает ресёрч безошибочным – он делает его проверяемым. Несколько ловушек остаются.
Самая частая и незаметная – неточный пересказ реального источника: ссылка настоящая, страница существует, но модели приписано то, чего там нет. Рядом стоит ловушка посложнее – синтез «из ниоткуда»: обойдя десятки страниц, агент собирает уверенный тезис, которого нет ни в одной по отдельности, и обилие источников создаёт иллюзию надёжности. Это тот самый случай, который HBR называет thinkslop – результат выглядит профессионально, но за ним не стоит реальной проверки. Бывают и совсем приземлённые проблемы: страница найдена, но данные на ней за прошлый период или закрыты пейволом, а модель пересказывает то, что видела краем. Наконец, цена и время – агентский цикл с поиском идёт минуты, а не секунды, и стоит дороже одиночного чата: для первичной карты рынка это оправданно, для быстрого вопроса – избыточно.
Ни одна из этих ловушек не снимается автоматически. Все они закрываются одним и тем же: открыть источники и сверить ключевые строки самому. Агент убирает ручной труд со сбора, но не с проверки.
Три решения определяют всё остальное: включить веб-поиск, чтобы у агента были «руки»; требовать источник к каждому факту и пометку ко всему непроверенному; проверять в отдельном окне, чтобы проверяющий не защищал свой же текст.
Агент превращает ресёрч из лотереи «повезёт или сочинит» в процесс «ищет, показывает источник, оставляет след». Проверять всё равно нужно. Но проверять то, у чего есть ссылка, – это минуты. Проверять то, что выглядит как факт, а выдумано целиком, – невозможно, потому что вы не знаете, где искать. В этом и есть разница между чатом и агентом для рыночного ресёрча.
От правдоподобной выдумки к проверяемому ресёрчу
Фундамент курса – это рабочие циклы с ИИ: где модель ускоряет ресёрч, где сочиняет и как построить процесс, в котором выдумки видны сразу. На реальных управленческих задачах, а не на абстрактных примерах.

Часто задаваемые вопросы
Чем агентский инструмент отличается от ChatGPT или Perplexity с поиском?
Нужны ли навыки программирования, чтобы делать ресёрч агентом?
Что такое MCP и зачем он для рыночного ресёрча?
Можно ли полностью доверить анализ конкурентов агенту и не проверять?

mysummit.school
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.