Как я построил систему оценки резюме на AI-агенте (и почему первая версия была бесполезной)

89% британских рекрутеров планируют увеличить использование AI в найме в этом году. Кандидаты в ответ пишут резюме через ChatGPT. Компании получают сотни одинаково отполированных документов и фильтруют их алгоритмами. CEO Adecco Group подсчитал: в среднем нужно 200 заявок, чтобы получить один оффер. Гонка вооружений, где обе стороны используют одну и ту же технологию.
За четыре месяца я создал больше 20 адаптированных резюме – одни и те же данные, радикально разные документы. Каждое адаптировано под конкретную вакансию: для одной компании акцент на платформенную инженерию, для другой – на масштабирование команд, для третьей – на трансформацию процессов. Данные одни, но перестановка приоритетов меняет всё.
Проблема – как понять, что резюме работает, до того как рекрутер его увидит? Грамматику проверит любой инструмент. Мне нужен был синтетический «первый читатель» – тот, кто смотрит на документ глазами нанимающего менеджера и говорит: «Я бы позвал на интервью» или «Я бы прошёл мимо».
Архитектура: модульный профиль вместо монолитного резюме
Классический подход – один файл CV, который правишь под каждую вакансию. Мой подход – 18 JSON-файлов, разделённых по доменам: достижения, опыт по компаниям, навыки по категориям, образование, сертификаты, контекст ролей. Разные роли тянут разные подмножества данных.
Ключевое архитектурное решение: в данных хранятся точные числа (173 инженера, $2,3 млн экономии), а в документах – округлённые (170+ инженеров, более $2 млн). Когда AI генерирует текст из точных данных, он выглядит естественно. Когда он сам придумывает числа – это заметно. Точные данные на входе, человекочитаемые – на выходе.
Конвейер выглядит так: оценка вакансии (насколько подходит профиль) -> генерация резюме по секциям (каждая секция – отдельный промпт с контекстом вакансии) -> сборка в единый документ -> оценка результата. Четыре шага, каждый – отдельный skill.
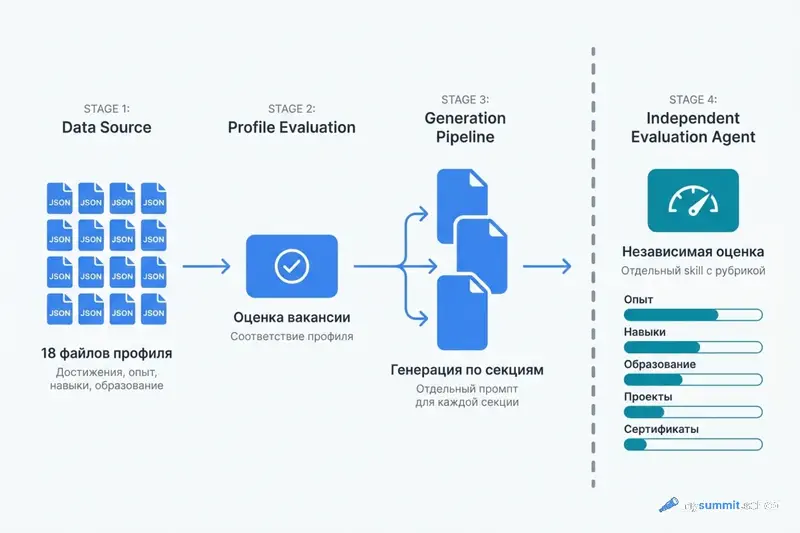
Архитектурно это конвейер из специализированных агентов. Каждый знает свою зону ответственности и получает ровно тот контекст, который нужен для его работы. Логика та же, что описана в разборе агентного анализа данных: специализация вместо монолита.
Что я сделал неправильно с первого раза
Первая версия оценки была монолитной: один промпт, который получал резюме и вакансию, а потом выдавал вердикт. Звучит разумно? Проблема в том, что он хвалил собственный результат.
Два конкретных провала:
Предвзятость самооценки. Система генерировала резюме и она же его оценивала. Результат предсказуем – как попросить автора оценить собственный текст. «Отличная структура, убедительные формулировки, хорошее покрытие требований» – при том что в резюме было зарыто самое релевантное на второй странице.
Отсутствие критериев. Без чётких рамок модель генерировала расплывчатую похвалу. Нет рубрики – нет объективной оценки. Это как ревью кода без чеклиста: рецензент пишет «всё ок» вместо того, чтобы проверить конкретные вещи.
Решение: полностью отдельный skill с жёсткой рубрикой и сгенерированной персоной нанимающего менеджера. Не «оцени резюме», а «ты – нанимающий менеджер с 10 годами опыта, у тебя стопка из 40 резюме, и ты тратишь 30 секунд на первичный скрининг».
Декомпозировать задачу выглядит просто. Сложность начинается, когда нужен не «примерно хороший» ответ, а предсказуемо точный. Разница между первой версией системы и рабочей – это навык видеть, где AI убеждает, но ошибается.
Похожая ловушка – в уроке про скрининг резюме в открытом модуле: AI выдаёт уверенный ответ, но усиливает вашу предвзятость. 9 задач, бесплатно.
Доступ сразу после регистрации
Пять измерений оценки: как я декомпозировал взгляд рекрутера
Когда нанимающий менеджер смотрит на резюме, он не думает «общее впечатление 7 из 10». Он проходит через несколько фильтров, каждый со своим весом. Какие именно – и почему именно такие?
Самый тяжёлый фильтр – первое впечатление, 30%. Что менеджер видит за 30 секунд: релевантный заголовок, ключевые метрики, самый важный опыт в верхней трети документа. Большинство резюме проваливают именно этот тест – релевантный опыт закопан на второй странице.
Дальше – покрытие требований, 25%. Каждое обязательное требование из вакансии должно быть явно покрыто в документе. Не подразумеваться – а быть видимым. Вакансия говорит «5+ лет управления инженерами» – в резюме должно стоять число, а не расплывчатое «опытный лидер».
Третье измерение – релевантность достижений, 20%. Не все достижения равны. Для роли в платформенной инженерии «сократил время деплоя на 93%» весит в десять раз больше, чем «увеличил выручку на 40%» – даже если второе объективно впечатляет больше. Оценка проверяет, что акценты расставлены под конкретную вакансию.
Четвёртое – ясность карьерного нарратива, 15%. Резюме рассказывает историю карьеры. Если история не ведёт логически к целевой роли – возникают вопросы. Переход из менеджера инженеров в программного менеджера и обратно? Нанимающий задастся вопросом «почему этот человек метался?» – даже если за переходом стоит логика.
И наконец – конкурентная позиция, 10%. Как это резюме смотрится на фоне типичных кандидатов. Для роли в эстонском технологическом стартапе типичный конкурент – локальный кандидат с EU-опытом. Резюме из Big Tech – одновременно плюс (масштаб) и минус (риск ухода через полгода).
Формула простая: взвешенная сумма пяти оценок по 10-балльной шкале, перевод в вероятность приглашения на интервью. 70%+ – подаёмся, 50–70% – дорабатываем, ниже 50% – серьёзная переработка.
Skill-файлы как архитектура агента
Здесь начинается интересное для инженеров. Skill-файл – это не промпт. Это workflow, контракт между тобой и моделью.
Мой skill оценки резюме состоит из четырёх файлов:
- evaluate-cv.js – точка входа, парсит аргументы, задаёт роль агенту
- workflow.md – пять фаз работы: сбор входных данных, анализ по перспективам, решение об интервью, рекомендации, генерация отчёта
- guidelines.md – принципы оценки, паттерны ошибок (зарытое сокровище, неверный акцент, размытое позиционирование), калибровка оценок
- skill.md – документация для пользователя
Каждый файл отвечает за свою зону. workflow.md – это что делать. guidelines.md – это как делать. skill.md – это зачем. Разделение позволяет менять критерии оценки, не трогая конвейер, и наоборот.
Skill-файлы, модульный контекст, разделение ответственности – попробуйте этот подход на 9 реальных задачах менеджера. Бесплатно, без регистрации.
Доступ сразу после регистрации
Вывод, который пришёл через практику: AI-агентная архитектура требует той же дисциплины, что проектирование распределённых систем. Чёткие интерфейсы. Минимальный контекст на входе. Один skill – одна ответственность. Если skill знает слишком много – результат непредсказуем. Если знает слишком мало – результат бесполезен.
Это не уникальный инсайт – похожая логика работает в любом агентном сценарии. P5.express и агентный ИИ – кейс из проектного менеджмента, где разделение ответственности между агентами определяет, станет ли инструмент рабочим или неуправляемым.
В guidelines.md живут названные антипаттерны. «Зарытое сокровище» – когда самый релевантный опыт закопан на второй странице. «Неверный акцент» – когда резюме выделяет достижения, которые не адресуют требования вакансии. «Размытое позиционирование» – когда документ посылает противоречивые сигналы (разработчик + менеджер + программный менеджер одновременно).
Модель с именованными паттернами работает точнее, чем с абстрактными инструкциями. «Проверь, нет ли зарытого сокровища» – конкретнее, чем «убедись, что важное не зарыто». Данные подтверждают: чёткая структура запроса устраняет больше проблем, чем любой трюк с тоном или КАПСОМ.
Что это даёт на практике
Система не гарантирует интервью – она снижает вынужденные ошибки. Что именно ловит?
Неправильные акценты в достижениях. Резюме для роли в DevOps акцентировало маркетинговые метрики (рост выручки на $2M+). Система указала: «Нанимающий менеджер ищет автоматизацию инфраструктуры, а видит бизнес-метрики. Пространство потрачено не на то.»
Разрывы в карьерном нарративе. Переход из Engineering Manager в Technical Program Manager без объяснения – тревожный сигнал для нанимающего. Система предлагает конкретную формулировку, которая превращает вопрос в аргумент в пользу кандидата.
Конкретные переписывания вместо абстрактных советов. Не «добавь больше деталей», а: текущее «Managed engineering team» -> предлагаемое «Managed cross-functional engineering team of 12 (8 engineers, 2 QA, 2 DevOps) across 3 time zones». С объяснением, почему второе работает лучше с точки зрения нанимающего менеджера.
Типичный цикл: первая оценка – 45–55% (есть что улучшить), после критических изменений – 65–75%, после доработки – 75–85%. Три итерации, каждая – 5 минут.
Открытый вопрос: пределы самооценки через AI
Система оценивает для медианного нанимающего менеджера. Но каждый менеджер оценивает по-своему: один ценит историю карьеры, другой сканирует только числа, третий отбрасывает всех из Big Tech по принципу «не впишутся в нашу культуру». Медианная модель не предскажет нетипичное решение.
И есть более глубокий вопрос. Исследование Xu, Li & Jiang (2025) на 2 245 реальных резюме показало: LLM систематически предпочитают резюме, которые сгенерировали сами. Предпочтение собственного результата – от 67% до 82% в зависимости от модели. GPT-4o предпочитает собственный результат в 80%+ случаев. В симуляции найма по 24 профессиям кандидаты, использовавшие ту же модель что и оценщик, получали приглашение на интервью на 23–60% чаще, чем равные по квалификации кандидаты с человеческими резюме.
Когда AI оценивает контент, который сам же и сгенерировал, возникает измеримое искажение. Моя система снижает эту проблему отдельным skill с жёсткой рубрикой и сгенерированной персоной, но не устраняет полностью. Авторы исследования предлагают два способа снижения: системный промпт, явно инструктирующий игнорировать стиль и фокусироваться на содержании, и ансамбль из нескольких моделей для голосования. Оба снижают искажение на 17–63%.
Красивого финала здесь не будет. Это рабочая система с известными ограничениями, не готовый продукт.
От эксперимента к системе
Статья показала, как AI-агент декомпозирует сложную задачу. Курс учит строить такие системы для своих рабочих задач – от промптов до агентных workflow.
Попробовать самому
Весь код – skill-файлы, модульный профиль, workflow оценки – открыт на GitHub. Чтобы разобраться, как это устроено, достаточно пяти минут и бесплатной модели:
- Скачайте ZIP-архив с кодом или склонируйте репозиторий:
git clone https://github.com/mysummit-school/looking-for-a-job.git - Откройте папку в OpenCode, Claude Code или любом другом AI-ассистенте для кода – хватит бесплатного тарифа
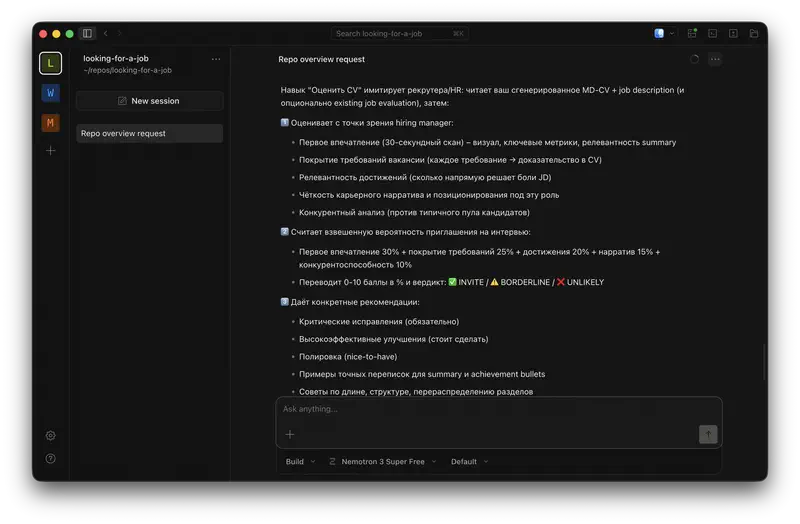
- Спросите агента, как устроены skill-файлы: что делает
workflow.md, какguidelines.mdзадаёт критерии, зачем нужно разделение на фазы - Заполните
profile/своими данными – JSON-файлы с плейсхолдерами покажут структуру - Попросите агента подготовить резюме под конкретную вакансию – он прочитает workflow и сделает всё по шагам
Агент следует конвейеру из статьи: оценка вакансии, генерация по секциям, сборка, независимая проверка. Все инструкции – в markdown-файлах, которые вы можете читать и менять.



Stanislav Belyaev
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.