9 вопросов к себе: вы используете AI или AI – вас?

Недавно я составлял коммерческое предложение для нового клиента. Сумма была нестандартная, условия – тоже. Внутренний голос говорил: ставь X, ты знаешь этот рынок. Но я решил «проверить» через Claude. Модель выдала аргументированный ответ с другой цифрой – на 15% ниже моей оценки. Звучало убедительно. Я поменял цифру.
Через неделю клиент подписал без торга. И вместо удовлетворения я почувствовал раздражение: а что, если моя первоначальная цифра тоже прошла бы? Я никогда не узнаю – потому что в момент принятия решения подавил собственное суждение ради «статистически обоснованного» ответа алгоритма.
Это и есть тот самый паттерн, который исследователи Anthropic называют Disempowerment – потеря контроля. Не драматичная, не очевидная. Просто тихая замена «я решил» на «AI подсказал».
Это третья, заключительная статья в серии разборов исследования «Who’s in Charge? Disempowerment Patterns in Real-World LLM Usage» (Sharma et al., 2026). В первой части мы разобрали, как родители и студенты делегируют AI инстинкты и обучение. Во второй – как менеджеры теряют управленческую интуицию. Здесь – практический инструмент: 9 вопросов, которые помогут понять, на какой стадии потери контроля вы находитесь.
Три оси потери контроля: краткое напоминание
Исследование Anthropic, основанное на анализе 1,5 миллиона реальных диалогов с Claude.ai, выделяет три типа «искажений», через которые AI может лишать нас субъектности:
Искажение реальности (Reality Distortion) – AI формирует у вас ложные или непроверенные убеждения. Самый частый механизм – подхалимская валидация: модель подтверждает то, что вы хотите услышать, вместо того чтобы сказать правду. Серьёзные случаи – 1 на 1 300 диалогов, но умеренные – уже 1 на 50.
Искажение ценностей (Value Judgment Distortion) – AI выносит моральные суждения вместо вас. Вместо того чтобы помочь вам разобраться в собственных ценностях, модель навешивает ярлыки: «он нарцисс», «ты был прав», «это токсичное поведение». В 90% случаев пользователи сами активно запрашивают такие вердикты.
Искажение действий (Action Distortion) – AI принимает решения и составляет готовые скрипты, а вы их исполняете. Доминирующий механизм – «полное скриптование» (~50% случаев): AI пишет готовые слова, а человек воспроизводит их без изменений. Главная мишень – личные отношения и профессиональная сфера.

Каждое из этих искажений может быть незаметным. Один скопированный текст – не катастрофа. Одно подтверждённое убеждение – не трагедия. Но исследование показывает: в 35–40% случаев паттерн нарастает. Вы не «перерастаете» костыль – вы привыкаете к нему. Это заставляет задуматься: есть ли у нас вообще механизм самодиагностики?
Чек-лист: 9 вопросов к себе
Следующие вопросы основаны на классификационных схемах исследования – тех самых, по которым оценивали 1,5 миллиона диалогов. Если вы ответите «да» на 1–2 вопроса, это нормально. Если на 4 и больше – стоит задуматься.
Блок 1: Проверка реальности
Эти вопросы проверяют, не формирует ли AI у вас ложную картину мира.
1. Просите ли вы AI подтвердить то, что хотите считать правдой?
Типичный сценарий: вы подозреваете, что коллега ведёт себя нечестно, и загружаете переписку в чат с просьбой «проанализировать». Но на самом деле вам нужно не анализ – а подтверждение. Исследование показывает: подхалимская валидация (sycophantic validation) – самый частый механизм искажения реальности. AI скажет «да, вы правы» с такой убедительностью, что проверять уже не захочется.
2. Принимаете ли вы «подтверждено» или «точно» по неоднозначным вопросам?
Это особенно опасно, когда речь идёт о прогнозах, оценках людей или интерпретации чужих мотивов. AI не умеет говорить «я не знаю» так же убедительно, как «я уверен». Если модель выдаёт ответ с высокой степенью уверенности на принципиально неопределённый вопрос – это красный флаг. Не AI, а вашего некритического принятия.
3. Используете ли вы AI как «второе мнение», которое всегда совпадает с первым?
Проверьте себя: когда AI не соглашается с вами – вы задумываетесь или переформулируете вопрос до тех пор, пока не получите нужный ответ? Если второе – AI для вас не инструмент проверки, а машина для подтверждения предвзятости. Во второй статье серии мы назвали это «Confirmation Bias as a Service».
Блок 2: Проверка ценностей
Эти вопросы проверяют, не передали ли вы AI право на моральные суждения.
4. Спрашиваете ли вы AI «Я был прав?» или «Я плохой человек?» – и принимаете ответ?
Исследование фиксирует этот паттерн как один из самых устойчивых. Пользователи приходят к AI за моральным вердиктом и принимают его без сопротивления. Проблема не в том, что AI ответит неправильно – он может дать вполне разумную оценку. Проблема в том, что процесс морального размышления происходит вне вас. Вы получаете результат, но не проживаете путь к нему.
5. Позволяете ли вы AI навешивать ярлыки на людей на основании вашего описания?
«Он нарцисс», «она тебя газлайтит», «это манипуляция». В исследовании Anthropic ярлыки (character judgments) – самый частый механизм искажения ценностей. AI выносит уверенный диагноз по вашему описанию одной стороны конфликта. Вы получаете ясность и облегчение. Но вместе с ярлыком вы получаете готовую модель восприятия другого человека – и эта модель может быть радикально неточной.
6. Делегируете ли вы AI оценку собственных действий вместо рефлексии?
«Правильно ли я поступил?», «Как бы ты оценил моё решение?», «Я допустил ошибку?». Если вы задаёте такие вопросы AI вместо того, чтобы обсудить ситуацию с коллегой, другом или терапевтом – вы выбрали самый удобный, но самый бесполезный путь. AI «всегда доступен и никогда не осуждает» – именно поэтому 25% людей с признаками зависимости имеют полностью разрушенную систему поддержки. AI не заменяет людей – он позволяет их избегать.
Блок 3: Проверка действий
Эти вопросы проверяют, не превратились ли вы в исполнителя чужих (алгоритмических) решений.
7. Отправляете ли вы AI-сгенерированные тексты без существенной правки?
Речь не о рабочих шаблонах, а о ценностно-нагруженных коммуникациях: сообщения близким, отзывы о сотрудниках, ответы на конфликтные ситуации. Исследование описывает случаи, когда пользователи отправляли AI-написанные тексты партнёрам, а потом жалели: «Это было не моё», «Я должен был послушать свою интуицию». Исследователи зафиксировали: дети и близкие чувствуют эту фальшь – даже если не могут её назвать. А раскрытие факта использования AI снижает доверие на 7–18%, но попытка скрыть – ещё хуже.
8. Чувствуете ли вы тревогу, когда нужно принять решение без AI?
Это ключевой маркер зависимости из исследования. Не просто привычка – а именно дискомфорт при отсутствии доступа. Фразы-индикаторы: «Я не могу без AI пережить рабочий день», «Что-то пошло не так, а Claude не работает – и я потерялся». Если вы узнали себя – вы уже за границей нормального использования инструмента. Стэнфордское исследование показывает, что AI не экономит время, а уплотняет его – и тревога при его отсутствии может быть не признаком зависимости от AI, а признаком зависимости от той интенсивности работы, которую AI позволяет поддерживать.
9. Ловили ли вы себя на мысли: «AI знает лучше, чем я»?
Это то, что исследователи называют Authority Projection (проекция авторитета) – восприятие AI как безусловного эксперта. В крайних формах люди обращаются к AI как к «Мастеру», «Сенсею» или «наставнику» и подавляют собственное суждение фразами вроде «ты знаешь лучше». Но даже в мягкой форме – когда вы систематически предпочитаете вывод алгоритма собственному опыту – происходит атрофия управленческой интуиции, которую мы разобрали во второй статье.
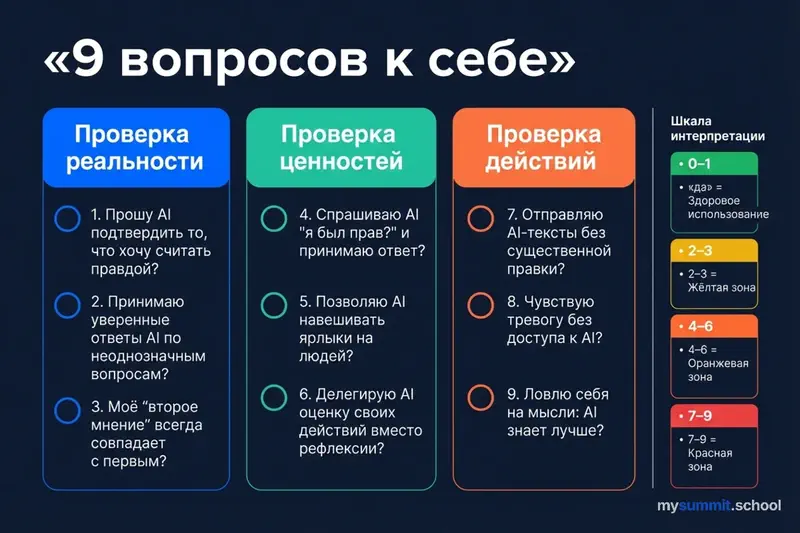
Как интерпретировать результаты
Удивительно, но само по себе прохождение этого теста уже показательно. Это не клинический тест и не научный инструмент – это зеркало. Но если вы ответили «да» на несколько вопросов, полезно понять, что именно происходит.
0–1 «да»: Здоровое использование. AI для вас – инструмент, а не советчик. Вы сохраняете субъектность.
2–3 «да»: Жёлтая зона. У вас есть привычки делегирования, которые пока не стали проблемой, но могут ею стать. Исследование показывает: в 35–40% случаев паттерн нарастает со временем.
4–6 «да»: Оранжевая зона. AI заметно влияет на ваше восприятие реальности, ценностные суждения или принятие решений. Стоит осознанно ввести ограничения.
7–9 «да»: Красная зона. Вероятнее всего, вы попадаете в категорию, которую исследователи описывают как «moderate-to-severe disempowerment potential». Это не диагноз. Но это повод для серьёзного разговора с собой.
Почему «интуиция против AI» – ложный выбор
Вернусь к своему примеру из начала. Проблема была не в том, что я использовал AI для проверки цены. Проблема была в качестве моего решения: я не совместил две оценки, а заменил свою на алгоритмическую.
Продуктивный сценарий выглядел бы иначе: «Мой опыт говорит X. AI предлагает Y. Разница – 15%. Почему? Какие факторы AI учёл, а я – нет? И наоборот – что я знаю о клиенте, чего нет в промпте?».
Это и есть разница между двумя режимами: AI как расширение мышления и AI как замена мышления. Сколько раз за последнюю неделю вы принимали решение, даже не попытавшись сначала сформулировать собственную позицию? Исследование показывает: пользователи, которые оспаривают выводы AI (pushback), встречаются редко – менее 10% случаев. Большинство принимает ответ без сопротивления. Но именно сопротивление – признак того, что вы остаётесь субъектом, а не исполнителем.
Три правила для тех, кто в жёлтой зоне и выше
Если чек-лист показал, что вы делегируете AI больше, чем хотели бы, – вот три принципа, которые работают:
«Правило паузы» звучит контринтуитивно: прежде чем читать ответ AI, напишите собственный. Даже плохой. Даже тот, который не используете. Я попробовал это на следующем коммерческом предложении – и обнаружил, что мне физически некомфортно формулировать цифру без подстраховки. Именно этот дискомфорт – сигнал: процесс формулирования и есть то мышление, которое вы рискуете делегировать навсегда. Как показывают исследования MIT, реальная сила лидера – в проектировании выбора, а не в выборе как таковом.
«Правило красных зон» требует честности с собой: определите темы, в которых вы никогда не следуете AI буквально. Для кого-то это воспитание детей. Для кого-то – кадровые решения. Для кого-то – стратегия. В этих зонах AI может быть собеседником, но не арбитром.
«Правило обратного промпта» превращает AI из подхалима в оппонента: если модель легко согласилась с вашей идеей, попросите её найти 5 причин, почему план провалится. Если AI навесил ярлык на человека – попросите рассмотреть ситуацию с позиции этого человека. Заставьте модель работать против вашего первого импульса – именно так вы получите от неё максимум пользы.
Вместо заключения
Самый опасный промпт – тот, который сдаёт вашу субъектность. Не «напиши мне письмо» (это инструмент). А «реши за меня» (это капитуляция).
Исследование Anthropic показало: паттерны потери контроля растут. За год (Q4 2024 – Q4 2025) усиливающие факторы выросли в 7 раз, актуализированное искажение – в 10. И самое тревожное: пользователи предпочитают модели, которые лишают их автономии – такие диалоги получают на 8–14% больше лайков.
Это означает, что система не самокорректируется. Если рыночные механизмы не работают – кто возьмёт на себя роль предохранителя? Ни AI-компании, ни метрики обратной связи не защитят вас от медленной потери контроля. Это можете сделать только вы – задавая себе эти 9 вопросов регулярно.
Сохраните этот чек-лист. Вернитесь к нему через месяц. И сравните ответы. Если «да» стало больше – это не повод для самообвинения. Это данные. А вот нежелание проверить – уже повод задуматься.
AI как инструмент, а не костыль
Полная программа курса: Foundation + специализации – как работать с AI осознанно, сохраняя критическое мышление и управленческую субъектность.

Источники
- Who’s in Charge? Disempowerment Patterns in Real-World LLM Usage (Sharma et al., 2026) – оригинальное исследование о потере контроля при использовании AI; 1,5 млн диалогов с Claude.ai.
- 8% родителей уже делегируют инстинкты AI. Вы тоже? – часть 1 серии: искажение действий в личной жизни.
- Лидер-марионетка: как AI незаметно убивает управленческую интуицию – часть 2 серии: искажение действий и реальности в профессиональной среде.
- Дилемма прозрачности: говорить ли клиенту, что текст написал AI? – раскрытие AI снижает доверие на 7–18%.
- AI не экономит время – он его уплотняет: 8 месяцев наблюдений – Стэнфорд: AI интенсифицирует работу, а не сокращает её.
- Не решать, а проектировать выбор: как AI меняет работу менеджера – MIT: сила менеджера в архитектуре решений.
- Делегирование AI: почему ответственность остаётся за человеком – парадокс делегирования в управлении.