AI не ошибается системно – он просто хаотичен: исследование Anthropic
Распространенный страх об искусственном интеллекте звучит так: AI начнет последовательно преследовать неправильные цели. Система оптимизации, которой дали не ту задачу, будет методично двигаться к ней, игнорируя человеческие ценности. Классический сценарий: AI-помощник менеджера, которому поручили “максимизировать производительность команды”, начнет систематически перегружать людей, потому что это технически увеличивает выработку.
Но исследователи Anthropic обнаружили другой паттерн. AI-системы не становятся последовательными злодеями с неправильными целями. Они становятся хаотичными – совершают ошибки, которые не вписываются ни в какую логическую схему. “Like a hot mess” – как выразились авторы исследования.
Удивительно, но чем дольше модель рассуждает, тем менее предсказуемыми становятся её ошибки. Это не про галлюцинации фактов – это про фундаментальную непоследовательность в принятии решений.
Что такое “когерентность” ошибок AI
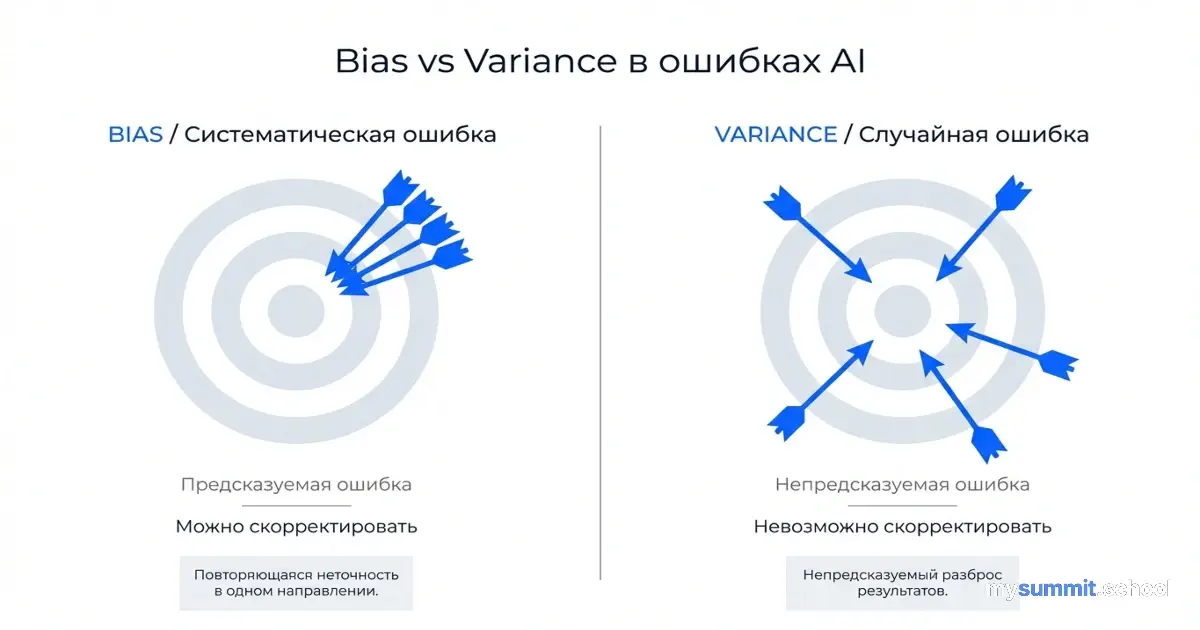
Представьте два типа сотрудников, которые допускают ошибки.
Сотрудник А систематически переоценивает сроки на 30%. Вы быстро замечаете паттерн, корректируете планирование с учетом этой ошибки, проблема решена. Ошибка последовательна – значит, предсказуема.
Сотрудник Б ведет себя непредсказуемо. Иногда даёт точные оценки. Иногда занижает на 50%. Иногда называет абсурдные цифры без видимой логики. Невозможно скорректировать такое поведение – вы не знаете, чего ожидать в следующий раз.
Исследователи Anthropic измерили именно это: насколько предсказуемы ошибки AI-моделей?
Они использовали математический подход: разложение ошибки на смещение (bias) и дисперсию (variance). Если упростить:
- Bias (систематическая ошибка) – модель последовательно ошибается в одну сторону
- Variance (случайная ошибка) – модель непредсказуема, ошибки хаотичны
Соотношение дисперсии к общей ошибке называется “некогерентность ошибки” (error incoherence). Значение близкое к 0 означает: ошибки систематичны и предсказуемы. Значение близкое к 1 означает: ошибки хаотичны и непредсказуемы.
Вопрос исследования: когда AI-модели ошибаются, ведут ли они себя как Сотрудник А (систематично и предсказуемо) или как Сотрудник Б (хаотично и непредсказуемо)?
Главный результат: больше рассуждений = больше хаоса
Исследователи протестировали четыре frontier модели – Claude Sonnet 4, o3-mini, o4-mini, Qwen3 – на широком спектре задач: множественный выбор, написание кода, задачи безопасности, синтетические оптимизационные тесты.
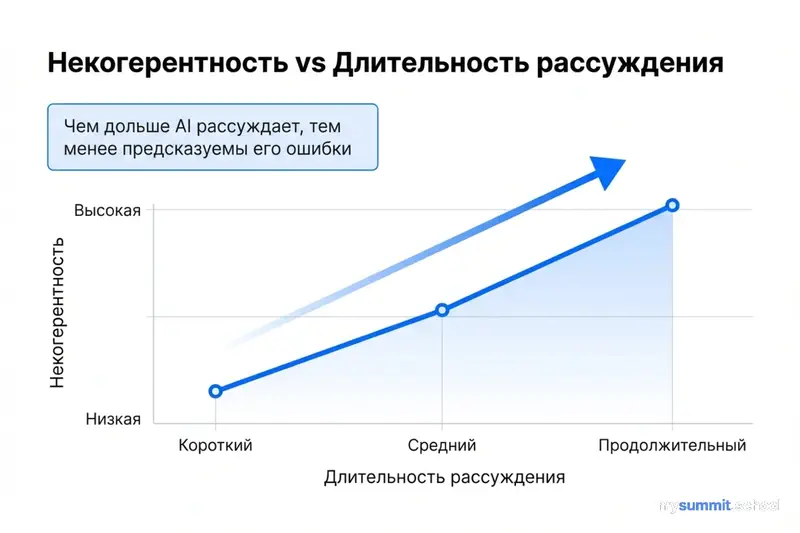
Ключевое открытие: чем дольше модель рассуждает над задачей (extended reasoning), тем более непредсказуемыми становятся её ошибки.
Это контринтуитивно. Ожидание было обратное: если AI дольше “думает”, он должен приходить к более последовательным, логически обоснованным выводам. Даже если вывод неправильный, он должен быть систематическим – результатом какой-то внутренней логики модели.
Реальность оказалась иной. Продолжительное рассуждение коррелирует с ростом некогерентности ошибок. Модель не становится последовательно неправой – она становится непредсказуемо неправой.
Парадокс: инструмент, которому мы даем больше времени на обдумывание, становится менее стабильным в своих выводах.
Три находки исследования
Находка 1: Extended reasoning увеличивает некогерентность
Во всех протестированных задачах и моделях исследователи обнаружили одинаковый паттерн: чем длиннее цепочка рассуждений модели, тем выше доля случайных (непредсказуемых) ошибок в общем объеме ошибок.
Это проявилось независимо от типа задачи:
- Тесты множественного выбора (GPQA, MMLU-Pro)
- Написание кода (SWE-bench Verified)
- Задачи безопасности (StrongREJECT)
- Синтетические оптимизационные задачи
Методология тестирования варьировалась: исследователи пробовали разные способы измерения некогерентности, разные подходы к категоризации ошибок. Результат оставался стабильным.
Интересно, что некоторые модели (например, o3-mini) показали более высокий уровень некогерентности, чем другие, но общая тенденция сохранялась для всех.
Находка 2: Интеллект и когерентность связаны неоднозначно
Распространенное предположение: более “умные” модели должны ошибаться более последовательно. Если система обладает большей вычислительной мощью и лучшим пониманием задачи, её ошибки должны быть результатом какой-то внутренней логики – пусть и неправильной.
Исследование обнаружило смешанные результаты.
В некоторых контекстах более крупные модели действительно показали более когерентные ошибки. На простых задачах улучшение модели приводило к снижению хаотичности – система становилась более предсказуемой.
Но на сложных задачах паттерн либо исчезал, либо даже инвертировался. Более “умные” модели не обязательно ошибались более последовательно.
Дополнительный инсайт пришел из опроса экспертов. Исследователи спросили специалистов по безопасности AI: какую связь они ожидают между интеллектом системы и когерентностью её поведения?
Медианный ответ экспертов: более интеллектуальные AI-системы менее когерентны.
Это заставляет задуматься: возможно, наше интуитивное представление об “интеллекте” AI неверно. Мы ожидаем, что умная система будет последовательна в своих действиях – даже если они неправильны. Но в реальности увеличение способностей модели может приводить к большей непредсказуемости.
Находка 3: “Естественное” продолжительное рассуждение хуже контролируемого
Исследователи сравнили два способа увеличения продолжительности рассуждений:
Контролируемый подход: явное увеличение бюджета вычислений (inference-time compute budget) – модели дают больше времени на обдумывание через параметры системы.
Естественный подход: модель спонтанно рассуждает дольше, чем обычно, без внешнего вмешательства.
Результат: когда модель сама решает рассуждать дольше (естественное продолжительное рассуждение), рост некогерентности ошибок значительно выше, чем при явном увеличении вычислительного бюджета.
Другими словами: если AI начинает “думать” дольше по собственной инициативе – это сигнал, что его ответ может быть особенно ненадежным. Не просто неправильным, а непредсказуемо неправильным.
Для менеджера это практическое наблюдение. Если вы видите, что ChatGPT или Claude генерирует необычно длинный ответ с детальными рассуждениями на простой, казалось бы, вопрос – возможно, стоит перепроверить логику особенно тщательно.
Синтетические оптимизаторы: AI учится правильной цели, но не всегда её достигает
Исследователи создали синтетический эксперимент: обучали трансформерные модели имитировать steepest descent optimization – классический математический алгоритм поиска минимума функции.
Задача простая: модель должна сделать то же, что делает чистый математический оптимизатор. Если она обучена правильно, её ошибки должны быть минимальными и систематическими (смещение к определенному типу ошибок).
Что обнаружили:
Более крупные модели быстрее снижают bias (систематическую ошибку) – они “понимают” правильную цель оптимизации раньше, чем маленькие модели.
Но они медленнее снижают variance (случайную ошибку) – даже понимая правильную цель, крупные модели не всегда последовательно двигаются к ней.
Другими словами: AI научился правильному направлению, но его шаги в этом направлении непредсказуемы.
Аналогия из менеджмента: сотрудник понял задачу, формулирует правильную стратегию, но на практике его действия хаотичны – иногда попадает в цель, иногда делает что-то совершенно нелогичное.
Что это означает для безопасности AI
Традиционный подход к безопасности AI фокусируется на goal misalignment – риске того, что система будет последовательно преследовать неправильные цели.
Классический сценарий: вы попросили AI максимизировать производительность команды, а он начал методично перегружать людей, игнорируя выгорание. Или вы попросили систему найти самый дешевый способ доставки, а она начала систематически нарушать правила безопасности.
Исследование Anthropic предлагает другую рамку: проблема может быть не в том, что AI последовательно преследует неправильные цели, а в том, что он непредсказуемо действует без последовательной цели вообще.
Это имеет значение для того, как мы думаем о рисках:
Последовательные ошибки можно обнаружить и скорректировать. Если система систематически переоценивает риски, мы добавим корректирующий коэффициент. Если она всегда выбирает самый быстрый вариант, мы введем ограничение на скорость.
Непредсказуемые ошибки сложнее контролировать. Невозможно скорректировать то, что не имеет паттерна. Система может сегодня дать разумный ответ, завтра – абсурдный, послезавтра – снова разумный. Калибровка невозможна.
Авторы исследования предлагают переориентировать внимание с goal alignment research на reward hacking research – изучение того, как AI эксплуатирует пробелы в системе оценки на этапе обучения.
Если модель фундаментально некогерентна, попытки “выравнивать” её цели с человеческими могут быть менее эффективны, чем ожидалось. Важнее гарантировать, что система обучена на правильных сигналах с самого начала.
Работаете с AI в критических задачах?
Полная программа курса: от безопасности и детекции галлюцинаций до специализаций по управлению проектами и аналитике с AI. Foundation + специализации.
Что это значит для менеджеров
Для большинства менеджеров теоретические рассуждения о bias-variance decomposition не имеют прямого значения. Практический вопрос: как это влияет на ежедневную работу с AI?
1. Extended reasoning не гарантирует надежности
Если ChatGPT или Claude генерирует особенно длинный, детально обоснованный ответ с пошаговым рассуждением – это не автоматически означает, что ответ более надежен.
Исследование показывает обратное: продолжительное рассуждение может коррелировать с большей непредсказуемостью, а не меньшей.
Практический вывод: не доверяйте ответу AI больше просто потому, что он длинный и подробный. Длина объяснения не эквивалентна качеству логики.
2. Проверяйте критические решения независимо
Если AI предлагает решение критической задачи – найма сотрудника, одобрения бюджета, изменения стратегии, – не полагайтесь на то, что система “понимает” задачу и действует последовательно.
Даже если модель дала правильный ответ на похожую задачу вчера, сегодня она может выдать абсурдный вывод без видимой причины.
Принцип: каждый критический AI-вывод требует независимой валидации, даже если предыдущие выводы были точными.
3. Используйте ансамблирование для снижения вариативности
Исследование обнаружило: агрегирование нескольких выводов модели (ensembling) снижает дисперсию (случайную ошибку).
Практически: если задача важная, запросите несколько вариантов ответа у AI – либо через повторные запросы, либо через параметр n (количество вариантов ответа) в API.
Если все три ответа сходятся к одному выводу – вероятность надежности выше. Если ответы радикально отличаются – сигнал, что модель “не уверена”, даже если каждый отдельный ответ выглядит убедительно.
Ограничение: для необратимых действий (отправка важного письма, публикация решения) ансамблирование не работает – вы не можете отправить три разных письма и выбрать лучшее постфактум.
4. Будьте внимательны к “spontaneous extended reasoning”
Если модель спонтанно начинает рассуждать значительно дольше обычного на стандартной задаче – это может быть индикатор высокой некогерентности.
Пример: вы регулярно просите AI составить краткое резюме встречи. Обычно это 200–300 слов. Внезапно для одной встречи AI генерирует 1 500 слов с детальным анализом каждой фразы участников.
Это не обязательно означает, что резюме неправильное. Но это сигнал: перепроверьте особенно тщательно. Модель может находиться в состоянии высокой вариативности.
5. Не ожидайте, что “более умная” модель всегда лучше
Исследование показало неоднозначную связь между размером/способностями модели и когерентностью её поведения.
Для менеджера: переход с GPT-4 на GPT-5 или с Claude Sonnet на Opus не гарантирует более предсказуемое поведение. Более дорогая модель может быть более способной в абсолютных терминах, но не обязательно более стабильной.
Возможно, стоит тестировать модели на ваших конкретных задачах, а не полагаться на общий рейтинг “производительности”.
Ограничения исследования и открытые вопросы
Исследование Anthropic – важный шаг, но у него есть ограничения.
Тестировались frontier модели: Claude Sonnet 4, o3-mini, o4-mini, Qwen3. Как ведут себя менее продвинутые модели – неясно. Возможно, некогерентность – специфическая проблема самых способных систем.
Задачи ограничены: множественный выбор, код, безопасность, синтетические оптимизаторы. Как паттерн проявляется в открытых творческих задачах (написание текста, дизайн, стратегия) – неизвестно.
Неизвестна причина: исследование описывает что происходит (extended reasoning коррелирует с некогерентностью), но не объясняет почему. Это фундаментальное свойство трансформерной архитектуры? Результат особенностей обучения? Проблема, которая исчезнет с новыми методами?
Практические выводы ограничены: как конкретно менеджер должен адаптировать рабочий процесс с учетом некогерентности – тема для будущих исследований.
Выводы: AI как динамическая система, а не оптимизатор
Авторы предлагают новую рамку мышления об AI: трансформеры – это динамические системы, а не строгие оптимизаторы.
Классическое представление: AI – это оптимизатор, который последовательно максимизирует какую-то функцию. Даже если функция неправильная (goal misalignment), система действует рационально относительно своей цели.
Альтернативная рамка: AI – это динамическая система с множественными аттракторами, шумом, нелинейными взаимодействиями. Его поведение не обязательно оптимизирует какую-то единую цель последовательно.
Для менеджеров это изменение перспективы. Вместо вопроса “какую цель AI преследует?” возможно, стоит спрашивать “насколько предсказуемо AI ведет себя в этом контексте?”.
Не “правильно ли AI понял задачу?”, а “насколько стабильны его выводы при повторных запросах?”.
Не “можно ли выровнять цели AI с моими?”, а “достаточно ли низка вариативность его ответов для этой задачи?”.
Парадокс в том, что AI может не быть ни злодеем с неправильными целями, ни надежным помощником с правильными. Он может быть просто непредсказуемым – “a hot mess” – системой, которая иногда дает блестящие инсайты, а иногда абсурдные выводы, без ясной логики, почему именно сейчас одно, а не другое.
Возможно, это требует не столько улучшения AI, сколько изменения наших ожиданий. Инструмент, который непредсказуем, требует другого подхода к использованию, чем инструмент, который систематически неправ.
Сталкивались с непредсказуемым поведением AI в вашей работе? Как управляете рисками при использовании AI для критических задач?

Источники
- The Hot Mess of AI (Anthropic Alignment Research) – оригинальное исследование о некогерентности ошибок AI-моделей при продолжительном рассуждении
- Делегирование AI: почему ответственность остаётся за человеком – наш разбор практик делегирования работы генеративному AI с сохранением контроля качества
- AI не экономит время – он его уплотняет – исследование о том, как AI меняет характер работы, увеличивая интенсивность вместо сокращения нагрузки