Зубчатый край ИИ: олимпиада – да, аналоговые часы – нет
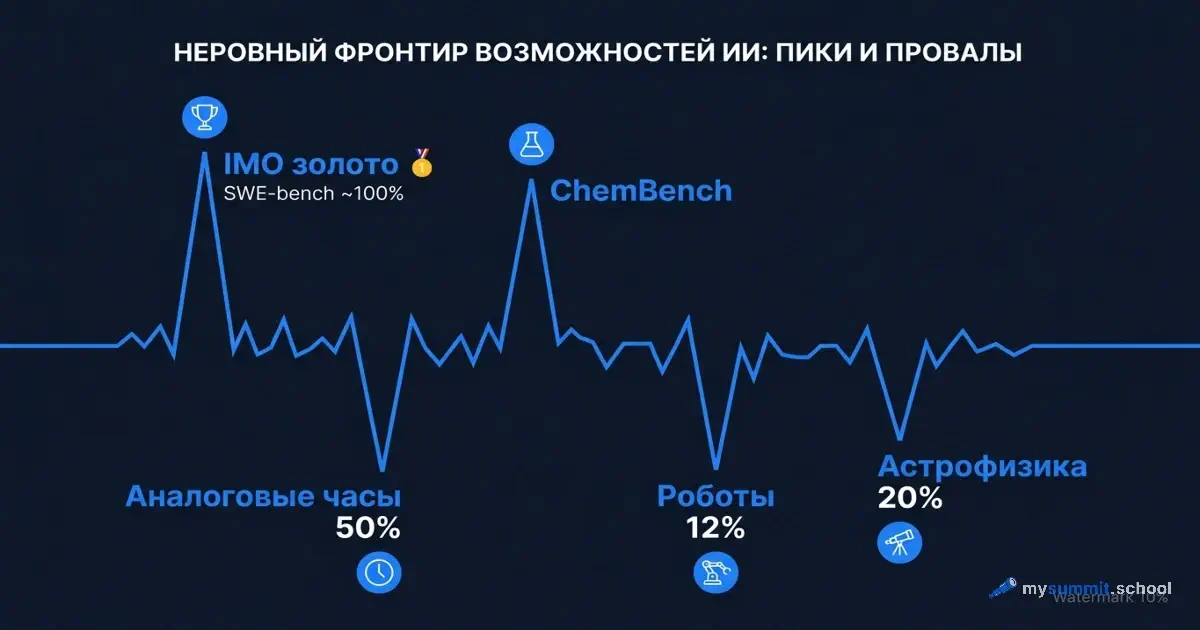
В декабре 2025 года Gemini Deep Think от Google взял золотую медаль на Международной математической олимпиаде – тесте, на котором выживают единицы из тысяч одарённых школьников. В том же году лучшая модель, определяющая время по аналоговым часам, справляется в 50,1% случаев. Чуть лучше, чем подбрасывание монетки.
Stanford AI Index 2026 называет это «jagged frontier» – зубчатый край. Контур того, что ИИ умеет и чего не умеет, не плавная кривая, а изломанный хребет с пиками и провалами, порой разделёнными сантиметрами.
Что такое «зубчатый край»
Представьте радарную диаграмму возможностей, где каждая ось – тип задачи. Олимпиадная математика – почти 100%. Написание кода по описанию бага – почти 100%. Определение времени на циферблате – 50%. Домашняя уборка роботом – 12%.
Это не баг и не временная недоработка. Это фундаментальное свойство нынешнего поколения моделей: они не развиваются равномерно. Прогресс в одной области не гарантирует прогресс в соседней. Модель, которая решает задачу уровня кандидата наук по физике, может не справиться с тем, что пятилетний ребёнок делает за секунду.
AI Index 2026 документирует этот паттерн с хирургической точностью – и именно поэтому третья часть нашего разбора отчёта посвящена не средним показателям, а разбросу.
Зубчатый край – это то, что делает ИИ одновременно впечатляющим в демо и ненадёжным на практике. И чтобы работать с ним, нужно знать не среднюю температуру по больнице, а конкретный профиль: где пики, а где провалы.
Вершины: где ИИ уже превзошёл людей
Начнём с хороших новостей – и они действительно впечатляют.
Математика
Gemini Deep Think заработал золотую медаль на IMO. Для контекста: Международная математическая олимпиада – это не школьная контрольная. Это задачи, над которыми сильнейшие школьники мира думают по четыре-пять часов. Год назад FrontierMath – бенчмарк с задачами исследовательского уровня – давался моделям на 2%. Сейчас разрыв сокращается стремительно.
Код
SWE-bench Verified – тест, где модель должна найти и исправить реальный баг в реальном репозитории – показал траекторию, которую трудно описать иначе, чем экспоненциальной. В AI Index 2025 мы фиксировали рост с 4,4% до 71,7% за год. В 2026-м результат приблизился к 100%, достигнув уровня человеческого базового показателя. За два года – от провала к насыщению.
Наука
Frontier-модели превзошли средних химиков-профессионалов на ChemBench. Модели вышли на уровень или выше человеческих базовых показателей по PhD-уровневым научным вопросам и мультимодальному рассуждению.
Паттерн узнаваем: когда ИИ находит правильный подход к классу задач, прогресс не линейный – он взрывной. Проблема в том, что этот взрыв происходит не везде одновременно.
Провалы: где ИИ удивительно беспомощен
А теперь – другая сторона хребта.
Аналоговые часы
Лучшая модель определяет время по фотографии обычного циферблата в 50,1% случаев. Это задача, которую решает любой первоклассник. Казалось бы, мультимодальные модели, способные анализировать медицинские снимки и спутниковые фотографии, должны справляться с двумя стрелками на круге. Но нет.
Роботы
В программных симуляциях ИИ-агенты добиваются успеха в 89% случаев. Переносим в реальный мир, в обычные домашние задачи – 12%. Восемь из девяти попыток заканчиваются неудачей. Разрыв между «может в теории» и «может на практике» – почти восьмикратный.
ИИ-агенты
На OSWorld – тесте, где агент должен выполнять задачи в реальной операционной системе – результаты выросли с 12% до примерно 66%. Звучит как прогресс. Но это значит, что каждая третья попытка по-прежнему проваливается. Представьте ассистента, который не справляется с каждым третьим поручением. Вы бы его уволили.
Научная репликация
Модели набирают меньше 20% при репликации исследований в астрофизике и 33% в наблюдении Земли. При том, что на ChemBench они превзошли людей. Тот же ИИ, те же архитектуры – и разброс от «лучше эксперта» до «хуже студента».
Хм.
Зубчатый край в действии: не плавная граница между «может» и «не может», а непредсказуемая линия, петляющая между триумфом и провалом.
Единственный способ узнать, где для вашей команды проходят пики и провалы – попробовать на реальных задачах.
Как не попасть в провал зубчатого края? 9 управленческих задач покажут, на что ИИ способен в вашей области – бесплатно.
Доступ сразу после регистрации
Бенчмарки насыщаются – и это отдельная проблема
Траектория SWE-bench – 4,4% -> 71,7% -> около 100% за два года – впечатляет. Но у неё есть неудобная оборотная сторона: если бенчмарк насыщен, он перестаёт различать модели. Все «отличники» получают одинаковый балл, и тест теряет смысл.
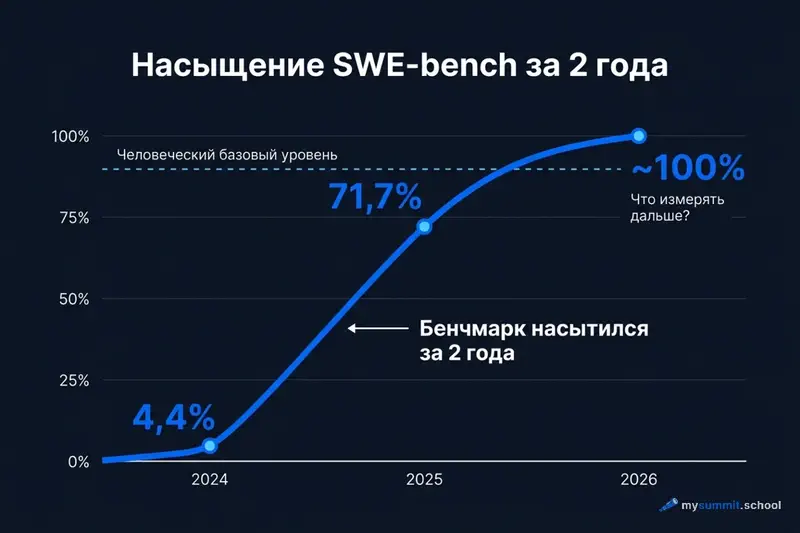
Мы подробно разбирали эту проблему в отдельной статье: почему бенчмарки теряют смысл. AI Index 2026 подтверждает тренд: модели вышли на или превзошли человеческие базовые показатели по ряду ключевых тестов – PhD-уровневая наука, мультимодальное рассуждение, соревновательная математика. Казалось бы – победа. Но когда все бенчмарки «пройдены», как измерять дальнейший прогресс?
И здесь возникает ещё один зубец: безопасность. Количество зафиксированных инцидентов с ИИ выросло с 233 до 362 – рост более чем на 55%. При этом AI Index отмечает, что бенчмарки ответственного ИИ отстают: их разработка не поспевает за развитием моделей. Хуже того, улучшение безопасности может снижать точность – это задокументированный компромисс.
Итого: бенчмарки насыщаются быстрее, чем создаются новые. Инциденты растут. Инструменты измерения безопасности отстают. А 90% заметных frontier-моделей производятся индустрией, а не академией – то есть теми, кто менее всего заинтересован в жёстких стандартах оценки.
Вот это – зубчатый край уже не возможностей модели, а самой системы контроля.
Почему это важно для бизнеса
Можно прочитать заголовок «ИИ берёт золото на олимпиаде» и решить, что пора внедрять модели во все процессы. Можно прочитать «роботы справляются в 12% случаев» и решить, что ИИ – пустой хайп. Оба вывода одинаково ошибочны.
Зубчатый край означает, что обобщение – главная ловушка. Модель, которая блестяще пишет код, может не справиться с анализом таблицы. Модель, превосходящая химиков, проваливается в астрофизике. ИИ-агент, выполняющий 66% задач на компьютере, – это не «почти готовый ассистент», это инструмент, на который нельзя положиться без проверки.
Для менеджера это означает три вещи.
Во-первых, нельзя экстраполировать. Успех ИИ на одной задаче вашего отдела не предсказывает успех на соседней. Каждый процесс нужно тестировать отдельно. Это дольше и скучнее, чем читать отчёты о золотых медалях, но это единственный надёжный подход.
Во-вторых, «среднее качество» – бесполезная метрика. Когда мы тестировали 53 модели, разница между моделями в среднем составляла десятые доли балла. Но на конкретных задачах разброс был огромным. Средняя температура по больнице – плохой ориентир для лечения.
В-третьих, рост инцидентов – это не абстрактная статистика. 362 задокументированных случая за год – это ваш потенциальный риск. Особенно если вы внедряете ИИ в области, где модель «в среднем» справляется, но на конкретном подклассе задач попадает в провал.
Практические навыки работы с ИИ – лучшая защита от неприятных сюрпризов.
Научитесь находить, где ИИ сильнее всего для ваших задач. Бесплатный модуль: 9 реальных сценариев, 30 минут.
Доступ сразу после регистрации
Как работать с зубчатым краем
Стратегия, которая работает, – это не «внедрить ИИ» и не «подождать, пока дозреет». Это систематическое картирование: где в вашем рабочем контексте проходит зубчатый край.
Тестируйте на своих задачах, а не на чужих. SWE-bench и IMO – это чужие задачи. Ваши – другие. Возьмите пять типичных задач вашей команды, прогоните через две-три модели, оцените результат. Это даст вам больше, чем все отчёты вместе взятые. Мы описывали этот подход – методология переносится на любой контекст.
Не обобщайте из заголовков. «ИИ решает олимпиадные задачи» не значит «ИИ решает ваши задачи». «Роботы справляются в 12% случаев» не значит «ИИ бесполезен для вашего бизнеса». Каждый заголовок – точка на зубчатом краю, и расстояние до вашей точки может быть огромным.
Разделяйте задачи по надёжности. Для одних процессов ИИ уже надёжнее человека. Для других – нет, и не будет в ближайший год. Используйте ИИ на пиках, держите людей в провалах. Стратегия 80/20: рутинные задачи, где ИИ стабильно хорош, автоматизируете; критичные задачи в зонах провала – оставляете за людьми.
Следите за краем, а не за средней. Зубчатый край – не статичная линия. Год назад SWE-bench был на 4,4%. Области, где сегодня провал, через год могут стать пиками. Но могут и не стать. Регулярная переоценка – не перфекционизм, а необходимость.
Есть соблазн думать, что зубчатый край – временное явление. Что через пару лет модели «выровняются» и станут одинаково хороши во всём. Возможно, так и будет. Но возможно, что неравномерность – фундаментальное свойство текущих архитектур. Возможно, мы увидим новые пики и новые провалы, просто в других местах. Epoch AI фиксирует, что 62% пользователей применяют ИИ лишь на одну-две задачи – и, возможно, это не лень, а интуитивная адаптация к зубчатому краю.
Зубчатый край – это не приговор и не временное неудобство. Это рабочая реальность ИИ в 2026 году, и чем точнее вы знаете, где проходят пики и провалы для вашего контекста, тем больше пользы вы извлечёте – и тем меньше рискуете. Золотая медаль на олимпиаде и монетка на аналоговых часах – это один и тот же ИИ. Вопрос только в том, какую задачу вы ему поручите.
Зубчатый край – не повод ждать
Курс MySummit учит находить пики и обходить провалы ИИ на реальных управленческих задачах. Не средние показатели – а конкретные навыки для вашего контекста.


Stanislav Belyaev
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.