99% качества за 1,4% цены: что не так с рынком ИИ-моделей
AI-модели в этой статье
Большинство менеджеров выбирают модель ИИ так: берут самую дорогую из доступных. Логика понятная – дороже значит лучше. Так работало с корпоративным софтом последние двадцать лет.
Рынок ИИ-моделей в 2026 году устроен иначе. Стоимость одного запроса варьируется от $0,0001 до $0,17 – три порядка величины. А реальная разница в качестве между десятью лучшими моделями? 0,24 балла по пятибалльной шкале. Тем временем Wharton / GBK Collective фиксируют: треть корпоративных ИИ-проектов не выходит за рамки пилота. А Epoch AI показывает, что лишь 5,6% пользователей применяют ИИ по-настоящему глубоко.
Может, вопрос не в том, какая модель лучше, а в том, даёт ли переплата за премиум пропорционально лучший результат для типичных управленческих задач.
Мы проверили. Ответ оказался жёстче, чем ожидали.
Данные
Между январём и мартом 2026 года мы протестировали 54 модели ИИ по восьми категориям управленческих задач – от составления писем до анализа данных и принятия решений в условиях неполной информации. Полные результаты опубликованы на платформе. Отдельный эксперимент – можно ли промптингом компенсировать слабую модель – показал, что структурированные промпты сокращают разрыв, но не закрывают его полностью. Методология: два ИИ-оценщика (Claude Opus 4.5 и Gemini 3 Pro) плюс калибровка человеком, 2 121 индивидуальная оценка. Каждая модель получает композитный балл от 1 до 5 и стоимость за запрос в долларах.
Цены – снимок апреля 2026 года по данным OpenRouter.ai, единственного агрегатора с единообразным форматом. Предупреждение: цены API меняются быстро. GPT-5.4 за время исследования подешевел с $0,0585 до $0,0158 за запрос. GPT-5.2 Pro, наоборот, подорожал с $0,039 до $0,1659.
В финальной таблице – 53 модели (одну исключили из-за непрозрачного ценообразования).
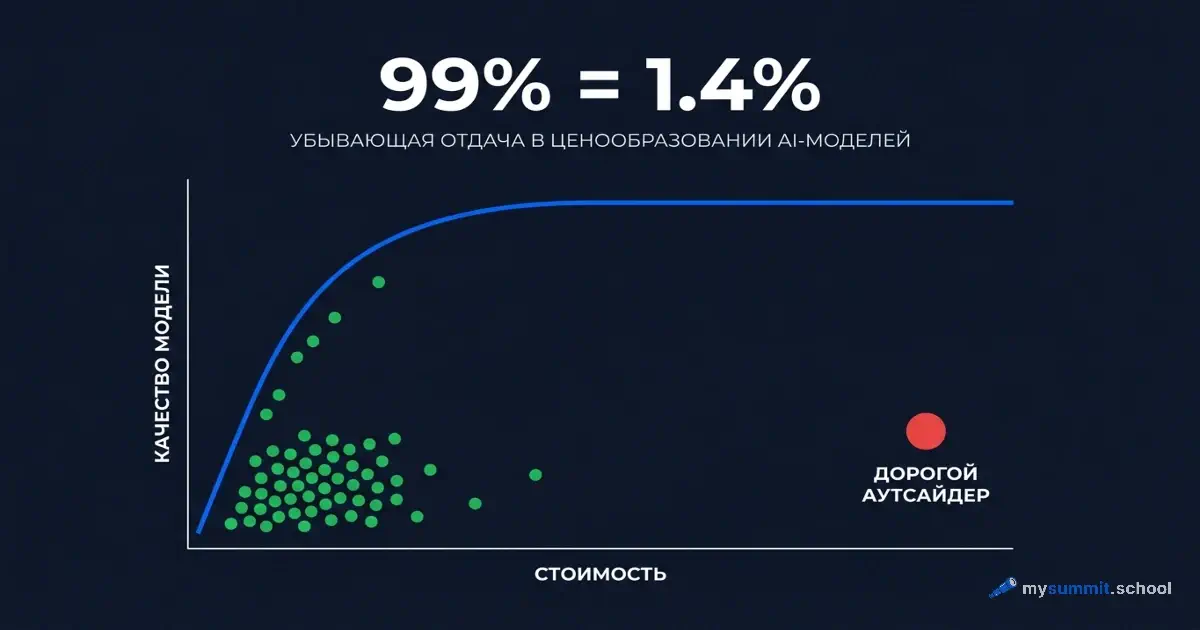
Экстремально убывающая отдача
Зависимость «цена – качество» для моделей ИИ подчиняется логарифмической кривой. Переход от ценовой категории $0,0001 к $0,002 за запрос даёт скачок качества примерно на 1,5 балла. Переход от $0,002 к $0,17 – увеличение цены в 85 раз – даёт прибавку около 0,1 балла.
Вот конкретный пример. Claude Sonnet 4.5 набирает 4,78 балла при $0,0165 за запрос. GPT-5.2 Pro – тоже 4,78 балла. Но стоит $0,1659. В десять раз дороже. Одинаковый результат. Мы перепроверили трижды – решили, что ошибка в таблице. Нет, просто так устроен рынок.
А потом мы посмотрели на Kimi K2.5. Балл 4,74 при $0,0023 за запрос. Это 99% качества GPT-5.4 за 1,4% стоимости GPT-5.2 Pro.
Стратегия 80/20
Абстрактные сравнения – это интересно, но что это значит для реального бюджета?
Мы смоделировали три стратегии для команды менеджеров, делающих 1 000 запросов в месяц.
Стратегия «всё на максимум»: все запросы через GPT-5.4. Стоимость: $15,80/месяц. Качество: 4,80.
Стратегия 80/20: 80% рутинных задач (письма, краткие справки, протоколы встреч) через бюджетную модель вроде Qwen3.5 9B, 20% сложных задач (анализ стратегии, отчёты для руководства) через GPT-5.4. Стоимость: $3,32/месяц. Качество: 4,25.
Разница: минус 79% расходов при потере 11% качества. Для 80% задач – черновик письма, пересказ документа, подготовка повестки – разница между моделями за $0,0002 и за $0,016 буквально неразличима.
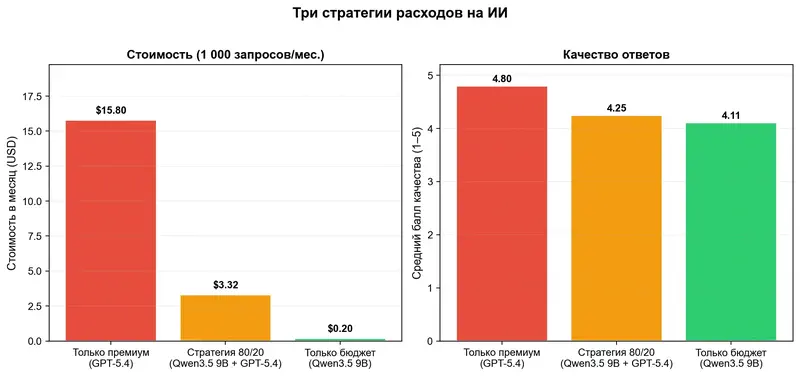
Это не теоретическое упражнение. Для команды из 10 менеджеров по 100 запросов в месяц стратегия 80/20 экономит около $125 ежемесячно по сравнению с подходом «всем – премиум». Сумма не трансформационная, но и не нулевая. А главное – качество на 80% задач остаётся неотличимым.
Арифметика выглядит просто. Сложность начинается, когда нужно решить конкретно: вот задача, вот три модели – какую выбрать и почему. Разница между «кажется, подойдёт» и «знаю, почему выбрал» – это навык, который нарабатывается на реальных задачах.
Какие задачи отдать бюджетной модели, а какие – премиум? Попробуйте 9 управленческих задач на разных моделях – бесплатно, без регистрации.
Доступ сразу после регистрации
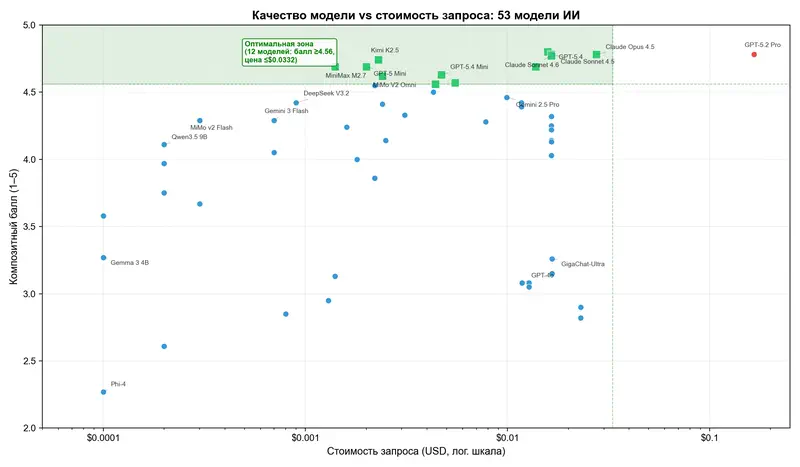
Скрытые чемпионы: показатель «качество на доллар»
Мы ввели метрику PPD (Performance Per Dollar) – балл качества, делённый на стоимость запроса. Чем выше PPD, тем больше качества вы получаете за каждый потраченный доллар.
Результаты переворачивают привычную картину.
| Модель | Балл | Стоимость запроса | PPD |
|---|---|---|---|
| GPT-5.2 Pro | 4,78 | $0,1659 | 28 |
| GPT-5.4 | 4,80 | $0,0158 | 304 |
| Kimi K2.5 | 4,74 | $0,0023 | 2 097 |
| DeepSeek V3.2 | 4,42 | $0,0009 | 4 825 |
| Gemini 3 Flash | 4,29 | $0,0007 | 6 085 |
| MiMo v2 Flash | 4,29 | $0,0003 | 12 434 |
| Qwen3.5 9B | 4,11 | $0,0002 | 21 076 |
Бюджетные модели дают от 40 до 1 700 раз больше качества на доллар, чем GPT-5.2 Pro. Это не ошибка округления. Это структурная неэффективность рынка, на которой можно играть.
«Налог на ИИ» – и кто его платит
Почему это вообще проблема? Разве все не используют ИИ одинаково?
Нет. Исследование Epoch AI / Ipsos показало, что 62% пользователей ИИ выполняют простые задачи – быстрые справки, короткие черновики. Лишь 5,6% используют ИИ глубоко. Для тех 62% разница между запросом за $0,002 и запросом за $0,17 буквально невидима.
А вот расходы видимы. Workday в отчёте 2026 года вводит термин «налог на ИИ» – 37% времени, «сэкономленного» с помощью ИИ, уходит на исправление его ошибок. Но есть и другой налог – финансовый: переплата за премиальную модель на задачах, где бюджетная справилась бы не хуже.
Brookings фиксирует: среди американцев, которые используют ИИ, только 19% считают, что он делает их продуктивнее в работе. 4% – что делает значительно продуктивнее. Google Cloud в отчёте по ROI показывает другую сторону: компании, которые видят реальный результат, добиваются его не покупкой дорогой модели, а точным выбором инструмента под задачу. Может, дело не в инструменте, а в том, как его выбирают и на что тратят?
Таблица «задача -> инструмент -> цена» – в уроке 8 открытого модуля. 9 практических задач менеджера с ИИ, бесплатно.
Доступ сразу после регистрации
Практическая рекомендация
Если вы управляете бюджетом на ИИ для команды – вот что можно сделать на этой неделе.
Классифицировать задачи: черновики писем, пересказы документов, справки по регламентам, протоколы встреч – это рутина, 70–80% запросов. Стратегический анализ, материалы для руководства, работа с неоднозначными данными – сложные задачи, 20–30%.
Настроить маршрутизацию: рутину – на бюджетную модель (Kimi K2.5, Qwen3.5 Plus, DeepSeek V3.2 – все доступны из России напрямую), сложные задачи – на премиум (GPT-5.4, Claude Sonnet 4.5). Технически это может быть API-шлюз, бот в мессенджере с двумя кнопками или просто договорённость в команде «для писем используем X, для аналитики – Y».
Измерить: через месяц сравнить – изменилось ли качество на рутинных задачах? Если нет – вы только что сократили расходы на ИИ на 70–80% без потери результата.
Для выбора конкретной модели под российские реалии – Kimi K2.5 (4,74 балла, лучший среди доступных из России), Qwen3.5 Plus (4,56 балла, дешевле), DeepSeek V3.2 (4,42 балла, ещё дешевле). Подробный разбор доступности и локальных моделей – отдельная тема. Инструменты для работы с несколькими моделями – в статье об OpenCode.
Оговорки
Наш бенчмарк тестирует конкретные категории задач. Возможно, премиальные модели действительно сильнее на сложных многошаговых рассуждениях или задачах, которые мы не тестировали. GPT-5.2 Pro, при всей его дороговизне, показывает поразительную стабильность (стандартное отклонение 0,082) – на некоторых бюджетных моделях разброс выше. Подход «ИИ оценивает ИИ» имеет свои искажения, хотя калибровка человеком их смягчает.
И главное: эти числа – снимок рынка в апреле 2026 года. Цены меняются еженедельно. Но структурная картина – экстремально убывающая отдача на верхнем ценовом сегменте – вряд ли изменится: слишком много конкурирующих моделей, слишком быстро дешевеют.
Итог
Гипотеза «дороже – пропорционально лучше» опровергнута данными. Рынок ИИ-моделей в 2026 году демонстрирует экстремально убывающую отдачу: надбавка за премиум реальна и измерима. Это не значит, что премиальные модели бесполезны – для 20% задач, где качество критично, разница может оправдывать цену. Но использовать GPT-5.4 для пересказа протокола совещания – это примерно как летать на вертолёте на работу: технически превосходно, экономически бессмысленно.
Разрыв между ценой и качеством на рынке ИИ-моделей сейчас больше, чем когда-либо – и вряд ли сузится в ближайший год. Но интереснее другой вопрос: если Kimi K2.5 даёт 99% качества GPT-5.4 за 1,4% цены, что именно покупает менеджер, выбирая премиум? Репутацию провайдера? Привычку? Или уверенность, что «мы используем самое лучшее» – даже если это «лучшее» не видно в результате?
Полные данные – в нашем исследовании 53 моделей.
От эксперимента к системе
Выбор модели – одна из задач курса. Фундамент закрывает промпт-инжиниринг и критическое мышление с ИИ. Специализация «Управление проектами» разбирает, как встроить ИИ в операционный ритм менеджера – от черновиков до аналитики.



Stanislav Belyaev
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.