Дилемма прозрачности: говорить ли клиенту, что текст написал AI?
Вы написали идеальное письмо клиенту. Тон точный, аргументы выстроены, даже шутка к месту. Проблема одна: писали не вы. Писал Claude. Или ChatGPT. Или Gemini – неважно.
Теперь вопрос: вы скажете об этом клиенту?
Интуиция подсказывает: «Конечно, нет. Какая разница, как написано, если написано хорошо?». Корпоративная этика шепчет: «Нужно быть прозрачным». А наука говорит нечто неожиданное: оба варианта разрушают доверие – но по-разному и с разными последствиями.
Эксперимент, который всё изменил
В 2025 году исследователи Оливер Шильке и Мартин Райманн опубликовали в Organizational Behavior and Human Decision Processes серию из 13 предзарегистрированных экспериментов с участием более 5 000 человек. Спектр сценариев был необычно широким: профессора, пишущие рекомендательные письма; аналитики, готовящие инвестиционные обзоры; руководители, составляющие корпоративную переписку; креативные специалисты, разрабатывающие концепции.
Методология была элегантна в своей простоте. Участники получали одни и те же тексты. Единственная переменная – знали ли они об участии AI в создании текста. Сам факт использования технологии оставался постоянным; менялось только раскрытие.
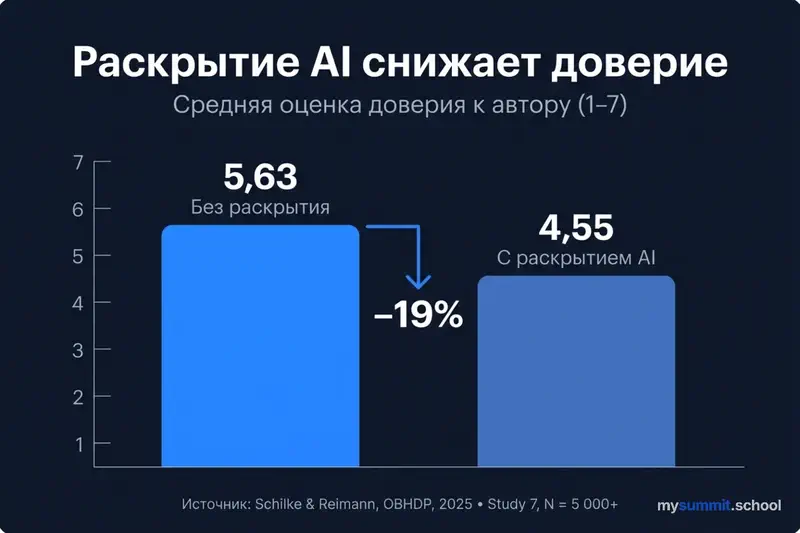
Результат оказался контринтуитивным: явное раскрытие использования AI систематически снижало доверие к автору сообщения. Не к качеству текста – к человеку, который его отправил. Конкретные цифры: доверие к профессорам, использовавшим AI для рекомендательных писем, падало на ~16%. Для инвестиционных фондов, раскрывших AI-участие в аналитических обзорах, – на ~18%. Простая маркировка «создано с помощью AI» отнимала 7–14 процентных пунктов доверия.
Исследователи проверили и «мягкие» формулировки: «AI использовался только для проверки орфографии», «AI помог со структурой». Не помогло. Любое упоминание AI запускало один и тот же механизм обесценивания.
Штраф за аутентичность
Причина – в том, что исследователи назвали штрафом за аутентичность (authenticity penalty). Шильке и Райманн выделили три компонента, которые последовательно разрушаются при раскрытии: типичность (это нормальное поведение для данной роли?), приверженность (автор вложил усилие?) и аутентичность (за словами стоит живой человек?).
Когда получатель узнаёт, что текст создан с помощью AI, происходит мгновенный когнитивный сдвиг. Он начинает сомневаться: это ваши мысли или алгоритм подобрал статистически вероятные формулировки? Забота в письме – искренняя или это шаблон?
Лингвистический анализ подтверждает парадокс: AI-тексты объективно получают более высокие оценки по эмоциональной теплоте, структурной сложности и словарному разнообразию. Но при этом стабильно проигрывают человеческим текстам по аутентичности – ощущению, что за словами стоит живой человек с реальными намерениями.
И худший сценарий – не ваше собственное раскрытие. Как формулируют исследователи: «Если третья сторона сообщает, что вы использовали AI, – это наихудший возможный исход». Потому что к штрафу за аутентичность добавляется штраф за обман. Механизм тот же, что и в алгоритмическом менеджменте: потеря ощущения контроля запускает цепную реакцию недоверия.
Слепой тест: когда AI побеждает – и проигрывает
Масштаб штрафа за аутентичность наглядно показывает исследование Гагана Джейна, Самридхи Парик и Пера Карлбринга (2024).
На первом этапе (слепое тестирование) 140 участников оценивали ответы на 10 сценариев психологической поддержки – от межличностных конфликтов до управления стрессом. Источник был скрыт. AI-ответы (ChatGPT) получили оценки на уровне или выше ответов магистрантов клинической психологии по всем трём параметрам – аутентичности, профессионализму и практичности. Различия не были статистически значимыми.
На втором этапе (через 6 месяцев, с раскрытием) 111 участников из той же группы оценивали те же самые ответы, но теперь знали, кто их автор. Результат: оценки аутентичности человеческих ответов выросли (с 36,33 до 37,66), а оценки AI остались на месте (34,85 в обоих этапах).
Исследования показывают ещё один любопытный нюанс: общее доверие к AI коррелировало только с практичностью. Ни с аутентичностью, ни с профессионализмом связи не обнаружилось.
Люди готовы признать, что AI полезен. Но не готовы признать, что AI может быть искренним. Утилитарное доверие и эмоциональное доверие – это два разных контура, и раскрытие разрушает именно второй.
Catch-22: скрывать ещё хуже
Казалось бы, решение очевидно – просто не говорить. И действительно, данные Salesforce (опрос 14 000 сотрудников) показывают: 64% выдают AI-сгенерированный контент за свой собственный. По данным WalkMe, 78% используют неодобренные AI-инструменты на работе. Среди руководителей C-уровня цифра ещё выше – 93% признаются в использовании «теневого AI».
Но исследователи Шильке и Райманн предупреждают: раскрытие третьей стороной – коллегой, случайным обнаружением, техническим сбоем – наносит катастрофический и часто непоправимый удар по репутации.
Это уже не «он использовал инструмент». Это «он намеренно ввёл меня в заблуждение».
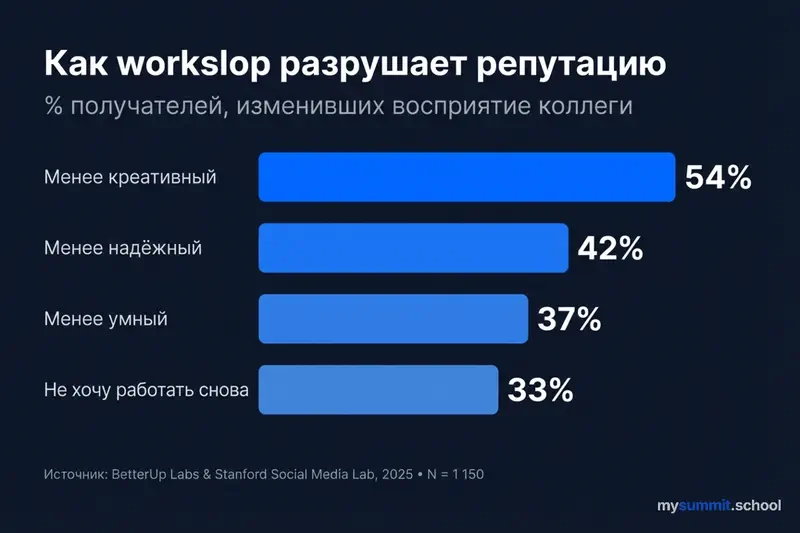
Данные совместного исследования BetterUp Labs (Кейт Нидерхоффер) и Stanford Social Media Lab (Джефф Хэнкок), опрос 1 150 штатных сотрудников в США, количественно описывают этот эффект. Когда получатели обнаруживают, что работа коллеги – AI-сгенерированный «workslop» (контент с внешней полировкой, но без содержательной глубины):
- 54% считают отправителя менее креативным
- 42% – менее заслуживающим доверия
- 37% – менее интеллектуальным
- 33% не хотели бы работать с этим человеком снова
Одно раскрытое AI-письмо может обнулить месяцы выстроенной профессиональной репутации. Это заставляет задуматься: насколько хрупким оказалось то, что мы привыкли считать «профессиональным доверием».
Скрытый налог: эвристика усилий и $9 млн в год
Чтобы понять глубину реакции, нужно обратиться к эвристике усилий, ментальному искажению. Десятилетия исследований показывают: люди инстинктивно приравнивают видимое усилие к качеству результата. Стихотворение, на которое «ушло три года», оценивается выше идентичного, написанного «за полчаса». Костюм ручной работы – дороже фабричного, даже если они неотличимы.
AI сломал эту связь. Безупречный текст теперь создаётся за секунды – и перестал быть сигналом компетентности. Когда руководитель узнаёт, что блестящий отчёт подчинённого – продукт одного промпта, включается ощущение обмана. Не потому что отчёт плох, а потому что предполагаемое усилие оказалось иллюзией. Синтез Microsoft Research (~50 исследований) подтверждает: пользователи, получившие некорректные рекомендации AI, работают медленнее, чем те, кто выполнял задачу вообще без AI.
А финансовый ущерб от workslop конкретен. По данным BetterUp и Стэнфорда:
| Показатель | Значение |
|---|---|
| Доля сотрудников, получавших workslop за последний месяц | 40% |
| Среднее время на разбор одного инцидента | 1 час 56 минут |
| Стоимость потерянного времени на сотрудника в месяц | $186 |
| Скрытый ущерб для организации в 10 000 человек | >$9 млн / год |

Получатель workslop тратит почти два часа на то, чтобы восстановить контекст, проверить факты и исправить ошибки. AI сэкономил отправителю 30 минут – и переложил два часа работы на коллегу. «Продуктивность» одного оборачивается потерями для всех.
Но BetterUp нашли и противоположный паттерн. 28% сотрудников используют AI как «пилоты» – активно редактируют, проверяют, дополняют своим контекстом. Остальные 72% – «пассажиры», делегирующие AI и отправляющие результат без правок. Разница в результатах: «пилоты» показывают в 3,6 раза более высокую продуктивность и в 3,1 раза более высокую лояльность компании. Похожий паттерн – интенсификация работы через AI – описан в исследовании Института будущего труда.
Почему объяснения не помогают (а социальное одобрение – да)
Интуитивное решение – сделать AI прозрачнее: объяснить, как он работает, показать логику рекомендаций. Но исследование Лаборатории инновационных наук Гарварда (LISH), обнаружило обратный эффект.
Масштаб эксперимента: 17 245 решений о распределении запасов по 425 товарным позициям в 186 магазинах. Когда менеджеры видели логику алгоритма – какие переменные он учитывал, какие веса присваивал, – они начинали чаще его игнорировать. Исследователи назвали этот механизм «самонадеянная отладка» (overconfident troubleshooting): прозрачность создавала иллюзию понимания. «Я вижу, что он учитывает, и я знаю лучше». Собственный опыт и интуиция побеждали данные.
А вот «чёрный ящик» – алгоритм без видимой логики – получал значительно больше доверия. При одном условии: сотрудники знали, что их коллеги участвовали в разработке и тестировании системы. Исследователи назвали это «социальным одобрением» (social proofing) – доверие к технологии через доверие к людям, которые за ней стоят.
Финансовый эффект был измерим: следование рекомендациям алгоритма приносило +$36,95 дополнительной выручки на каждое решение о распределении в четвёртом квинтиле и +$104,96 – в верхнем квинтиле. Менеджеры, которые игнорировали алгоритм из-за «прозрачной логики», теряли реальные деньги.
Работа Microsoft Research подтверждает этот парадокс: объяснения не снижают чрезмерное доверие к AI, а в некоторых случаях усиливают его. Пользователи интерпретируют наличие объяснений как сигнал проверенности системы – даже если объяснения неинформативны. Исследование Васконселоса и коллег из Стэнфорда показало: объяснения снижают избыточное доверие только когда они проще, чем сама задача. Если объяснение так же сложно, как задача, пользователь рационально пропускает верификацию (примечание: исследование опубликовано еще в 2023 году, но затрагивало щепетильную тему – вакцинация).
Разрыв между руководством и командой
Ситуацию усложняет радикальное расхождение в восприятии AI на разных уровнях организации – паттерн, который хорошо виден в корпоративном внедрении AI в целом.
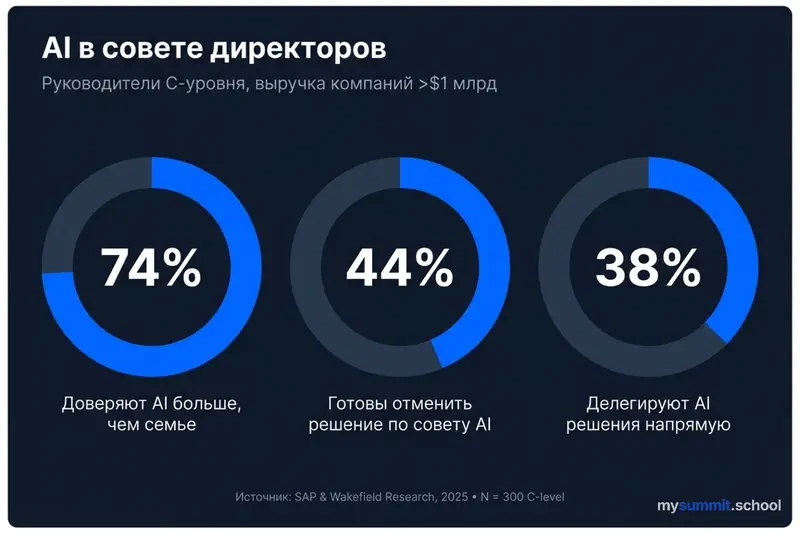
Исследование SAP и Wakefield Research («AI Has a Seat in the C-Suite», март 2025) опросило 300 руководителей C-уровня компаний с выручкой свыше $1 млрд. Цифры поразительны:
- 74% доверяют AI больше, чем семье и друзьям в вопросах стратегических рекомендаций
- 44% готовы позволить AI отменить уже принятое бизнес-решение
- 38% делегируют AI принятие решений напрямую
- В компаниях, где AI уже заменяет традиционные процессы принятия решений, эта доля достигает 55%
На линейном уровне – противоположная динамика. По данным BCG «AI at Work 2025» (10 600+ сотрудников, 11 стран), 72% работников регулярно используют AI – но это средняя температура. 78% менеджеров и 85%+ руководителей работают с AI еженедельно, а внедрение на фронтлайн-уровне застряло на 51% – цифра не изменилась с 2023 года. Только 25% линейных сотрудников получают какое-либо руководство от менеджеров по использованию AI, и лишь 36% считают своё обучение достаточным.
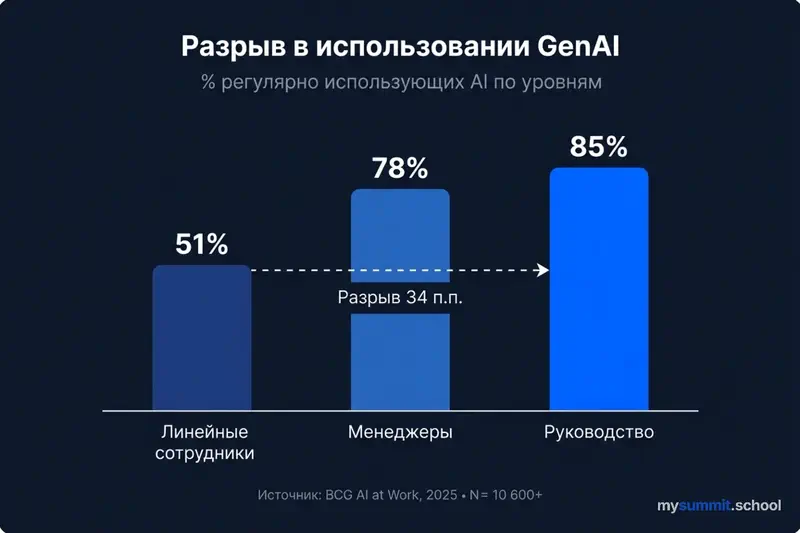

При этом 54% сотрудников готовы использовать AI-инструменты даже без разрешения компании – «теневой AI» растёт. А 41% опрошенных опасаются потерять работу из-за AI в ближайшие десять лет, причём руководители тревожатся больше (43%), чем линейные сотрудники (36%).
Низкая AI-грамотность усиливает разрыв. По данным HR Brew и Censuswide (2024), сотрудники с низкой AI-грамотностью испытывают в 6 раз больше тревоги, в 7 раз больше страха и в 8 раз больше подавленности – по сравнению с AI-грамотными коллегами. А эксперимент Джейкобса и коллег (2021 год, 220 клиницистов, назначение антидепрессантов) показал: врачи с низкой AI-грамотностью в 7 раз чаще следовали некорректным рекомендациям алгоритма.
Это зеркальное отражение дилеммы прозрачности: руководство навязывает AI «для эффективности», сотрудники отвечают теневым AI «для выживания». Прозрачность сверху порождает непрозрачность снизу.
От парадокса к протоколу: что предлагает наука
Исследования не просто диагностируют проблему – они предлагают конкретные механизмы выхода из тупика. Четыре стратегии, каждая с доказательной базой.
1. Нормализация вместо раскрытия
Шильке и Райманн указывают на ключевой нюанс: штраф за аутентичность срабатывает, когда AI-использование воспринимается как нетипичное для данной роли. Профессор, использующий AI для оценки, – нетипично. Аналитик, использующий AI для обзора, – уже ближе к норме.
Вывод: вместо того чтобы решать, раскрывать или скрывать, – стоит сделать AI-использование нормативно ожидаемым. Когда все в команде открыто используют AI, компонент типичности перестаёт разрушаться. Это уже не «он подменил работу алгоритмом», а «он использовал стандартный инструмент, как и все».
Опыт SAP SuccessFactors подтверждает: когда AI встроен в рутинные процессы помощи – постановку целей, обратную связь коллегам – он перестаёт быть исключением:
| Метрика | Изменение |
|---|---|
| Качество обратной связи (по оценке сотрудников) | 80% позитивный консенсус |
| Частота обратной связи (4+ раз в год) | +47% |
| Удовлетворённость процессом постановки целей | +30% |
2. Социальное одобрение вместо технической прозрачности
Гарвардское исследование в Tapestry даёт конкретный рецепт: вовлекайте конечных пользователей в выбор, тестирование и валидацию AI-инструментов. Когда сотрудники знают, что их коллеги с аналогичным опытом участвовали в разработке системы, доверие к «чёрному ящику» оказывается выше, чем к прозрачному алгоритму.
Это масштабируется: не нужно объяснять каждому, как работает модель. Достаточно, чтобы люди, которым доверяет команда, сказали: «Мы проверили – работает». Данные BetterUp дополняют: обучение реляционным навыкам (умение слушать, задавать вопросы, давать контекст) увеличивает взаимодействие сотрудников с AI на 30% и повышает качество результатов.
3. Когнитивные точки трения вместо автоматического принятия
Бучинча и коллеги (2021, 199 респондентов, Гарвард) показали: если попросить человека сначала подумать самому, а потом показать ответ AI – он будет меньше слепо доверять модели. Microsoft Research выделяет три конкретных механизма:
- Сигналы неопределённости: AI, который говорит «я не уверен в этом ответе», снижает чрезмерную опору эффективнее, чем числовые показатели вроде «уверенность 73%». Первое запускает критическое мышление, второе – создаёт иллюзию точности.
- AI-самокритика: модель, которая аргументирует против собственного вывода, помогает пользователю увидеть слабые места. Это один из самых перспективных паттернов из синтеза 2025 года.
- Предварительное суждение: пользователь формулирует свой ответ до того, как увидит рекомендацию AI. Простой порядок действий меняет всё.
Но есть важная оговорка: пользователи оценивали эти интерфейсы как наименее удобные. Существует обратная корреляция между эффективностью и привлекательностью. То, что работает, – раздражает. То, что нравится, – не помогает. Внедряя подобные механимзы, вам необходимо давать четкие объяснения – зачем вы это делаете.
4. «Пилоты», а не «пассажиры»
BetterUp и Стэнфорд предлагают чёткую рамку. 28% сотрудников-«пилотов» – тех, кто активно редактирует, проверяет и дополняет AI-результат контекстом – показывают в 3,6 раза более высокую продуктивность и в 3,1 раза более высокую лояльность. Остальные 72% – «пассажиры», делегирующие AI без правок.
Разница не в инструменте, а в установке. И эта установка поддаётся тренировке: сотрудники, прошедшие обучение реляционным навыкам, на 30% активнее взаимодействуют с AI и производят контент более высокого качества. Организации, которые устанавливают чёткие правила использования AI, определяют конкретные сценарии и подкрепляют человеческое суждение, – значительно реже сталкиваются с workslop.
Что с этим делать: карта действий
Данные указывают на конкретные шаги для менеджера, который использует AI и управляет командой, использующей AI.
Для личной коммуникации:
- Вместо «Это написал AI» скажите «Я подготовил с помощью AI и доработал под наш контекст». Фокус на вашем вкладе, а не на инструменте – так вы избегаете и штрафа за аутентичность, и штрафа за обман.
- Добавляйте следы человеческого мышления: личный опыт, конкретные примеры из совместной работы, ссылки на предыдущие обсуждения – всё, что AI не может знать.
- Формулируйте свою позицию до запуска AI. Это превращает вас из «пассажира» в «пилота» – и снижает риск слепого принятия AI-ответа.
Для управления командой:
- Стоит внедрять аудит процесса: оценивать не полированный результат, а путь к нему – черновики, итерации, точки, где сотрудник не согласился с AI.
- AI-использование стоит нормализовать в команде: когда все открыто работают с AI, компонент типичности перестаёт разрушаться.
- Стройте социальное доверие: вовлекайте команду в выбор и тестирование AI-инструментов. Гарвардское исследование в Tapestry доказало: доверие к системе растёт через доверие к коллегам, которые её одобрили.
- Давайте AI в руки, а не на голову. Опыт SAP: AI для помощи сотруднику формирует доверие, AI для контроля – разрушает.
- Закрывайте разрыв в AI-грамотности. Врачи с низкой AI-грамотностью в 7 раз чаще следуют некорректным рекомендациям. Обучение – не факультатив, а инфраструктура доверия.
Дилемма прозрачности не имеет идеального решения. Раскрытие снижает доверие на 7–18%. Сокрытие – разрушает его, когда правда всплывает. Но между этими полюсами есть рабочая зона: использовать AI как инструмент, а не как автора. Добавлять свой голос, а не делегировать его.
Возможно, стоит различать два вопроса: «Написал ли это AI?» и «Стоит ли за этим текстом человек, которому не всё равно?». Первый вопрос – про технологию. Второй – про отношения. И именно ответ на второй определяет, сохраните ли вы доверие.
AI пишет – вы решаете, как подать
Полная программа курса: Foundation + специализации – как использовать AI в профессиональной коммуникации, сохраняя доверие и этические стандарты.
Как AI помогал в создании этой статьи (следуя собственным рекомендациям – раскрываем):
- Разведка темы. AI помог найти и систематизировать исследования, статьи и кейсы по теме. Но каждый источник был прочитан человеком, данные перепроверены по оригинальным публикациям, а черновик статьи написан вручную.
- Инфографика. Все изображения сгенерированы AI. Но промпты – описания данных, композиции и источников – написаны человеком на основе прочитанных исследований.
- Редактура. AI проверял структуру статьи на соответствие редакционным стандартам и фокусу на аудиторию. Но сами стандарты, голос бренда и редакционная политика – разработаны нами.
Мы – «пилоты», не «пассажиры».

Источники
- Schilke, O. & Reimann, M. (2025). The authenticity penalty of AI disclosure. Organizational Behavior and Human Decision Processes, 188. DOI
- Niederhoffer, K. & Hancock, J. (2025). AI-generated workslop is destroying productivity. Harvard Business Review. HBR
- Jain, G., Pareek, S. & Carlbring, P. (2024). Perception of AI-generated mental health responses. Internet Interventions, 38. DOI
- BCG (2025). AI at Work 2025: Momentum Builds, but Gaps Remain. BCG
- SAP & Wakefield Research (2025). AI Has a Seat in the C-Suite. SAP
- Bucinca, Z. et al. (2021). To trust or to think: Cognitive forcing functions. Proceedings of the ACM on Human-Computer Interaction, 5(CSCW1). DOI
- Vasconcelos, H. et al. (2023). Explanations can reduce overreliance on AI systems during decision-making. Proceedings of the ACM on Human-Computer Interaction, 7(CSCW1). DOI
- Jacobs, M. et al. (2021). How machine-learning recommendations influence clinician treatment selections. Translational Psychiatry, 11, 108. DOI
- Microsoft Research (2024). Appropriate Reliance on GenAI. PDF