Лучшие AI для менеджера без VPN: данные исследования
Мы завершили масштабное исследование: 33 AI-модели, 8 категорий управленческих задач. Вопрос был простым – какой AI работает лучше для менеджера? Но ответ оказался интереснее, чем мы ожидали.
Особенно когда речь зашла о моделях, доступных в России без VPN.
Что мы проверяли и как
Прежде чем к цифрам – коротко о методологии, потому что без этого контекста данные ничего не значат.
33 модели тестировались на 32 реальных сценариях управленческих задач: планирование, коммуникация, анализ, работа с командой, поиск информации и так далее. Каждая модель получала одинаковые запросы на русском языке – от лица обычного менеджера, без специально отточенных промптов. Именно так большинство людей и работает с AI.
Оценку выставляли два судьи – Claude Opus 4.5 и Gemini 3 Pro. Мы провели человеческую калибровку с 23 оценками, которая выявила систематические смещения: Opus занижал оценки на 0,39 балла, Gemini завышал на 0,53. После коррекции итоговая оценка считается по формуле 70% Opus + 30% Gemini. Подробнее об этой части читайте в статье о методологии.
Шкала – от 1 до 5. Для понимания масштаба: 4,0 – это уже уверенно хороший результат, 4,5+ – отлично.
Простой ответ: что брать без VPN
Если не хочется читать дальше – вот ответ.
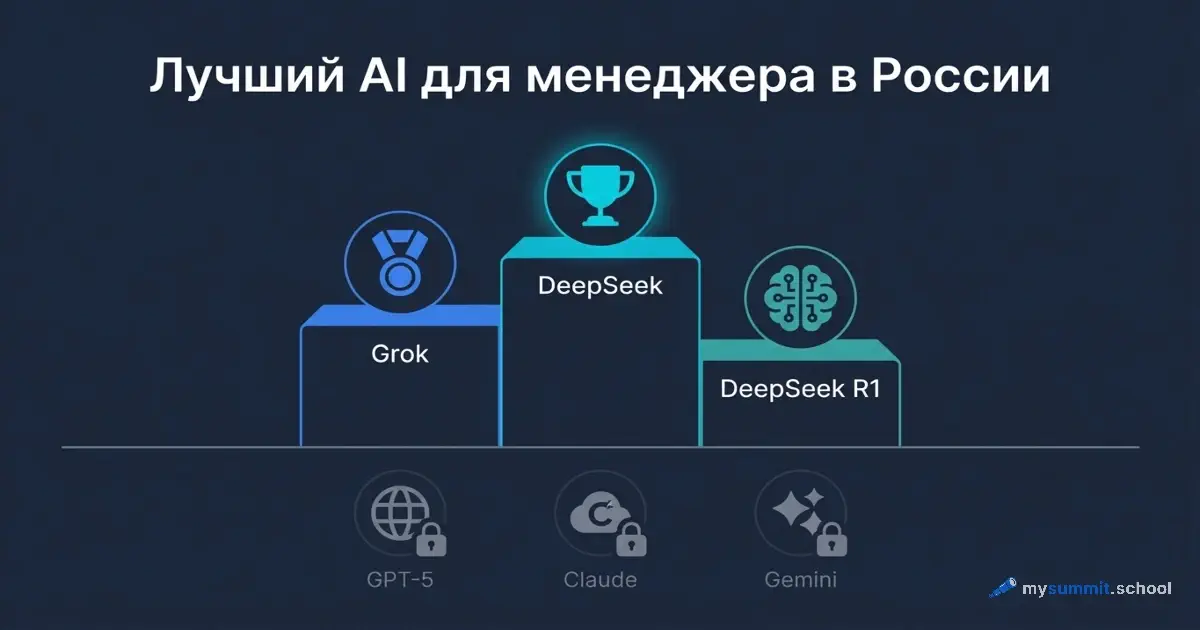
Первый выбор: DeepSeek V3.2. Итоговый балл 4,41 из 5,0. Бесплатный чат на chat.deepseek.com, API стоит ~$0,0007 за запрос – это буквально копейки. Лучший результат среди всех моделей, доступных в России.
Второй выбор: Grok 4.1 Fast от xAI. Балл 4,37. Доступен через x.ai напрямую, без VPN. С марта 2026 xAI радикально снизила цены – теперь ~$0,0007 за запрос, сопоставимо с DeepSeek.
Третий выбор: DeepSeek R1. Балл 4,31 – версия с расширенным мышлением, особенно хороша для аналитических задач. API ~$0,0028 за запрос.
Всё. Для большинства задач менеджера этих трёх моделей достаточно.
Остальное – детали, которые важны в зависимости от ваших конкретных задач и бюджета.
Полная картина: уровни доступных моделей
Мы разбили все протестированные модели на три уровня по итоговому баллу.
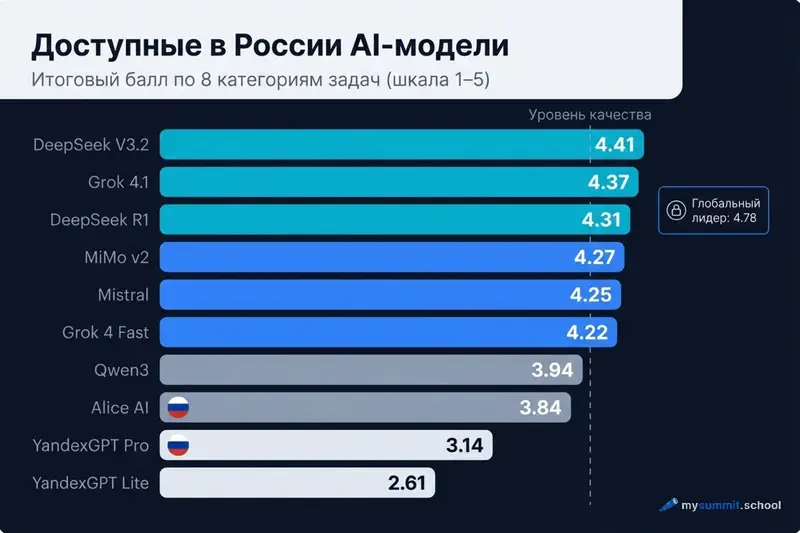
Уровень 1: топ-3 России (≥ 4,30)
| Модель | Балл | Доступ | Стоимость / запрос |
|---|---|---|---|
| DeepSeek V3.2 | 4,41 | chat.deepseek.com + прямое API | ~$0,0007 |
| Grok 4.1 Fast | 4,37 | x.ai (X Premium / SuperGrok) | ~$0,0007 |
| DeepSeek R1 | 4,31 | chat.deepseek.com + прямое API | ~$0,0028 |
Уровень 2: сильные альтернативы (4,00–4,29)
| Модель | Балл | Доступ | Стоимость / запрос |
|---|---|---|---|
| MiMo v2 Flash (Xiaomi) | 4,27 | только API | ~$0,0004 |
| Mistral Large | 4,25 | chat.mistral.ai (Le Chat) + API | ~$0,0078 |
| Grok 4 Fast | 4,22 | x.ai | ~$0,0007 |
| MiniMax M1 | 4,12 | только API | – |
| Grok 4 | 4,12 | x.ai | ~$0,0007 |
| Grok 3 | 4,11 | x.ai | ~$0,0007 |
Уровень 3: заметно слабее (3,50–3,99)
| Модель | Балл | Доступ |
|---|---|---|
| Qwen3 235B | 3,94 | chat.qwen.ai |
| Alice AI LLM (Яндекс) | 3,84 | alice.yandex.ru / Яндекс Браузер |
| Gemma 3 27B | 3,73 | только API |
| Qwen3 32B | 3,65 | chat.qwen.ai |
Разрыв между уровнями ощутимый. Если Уровень 1 – это уверенная «четвёрка с плюсом», то Уровень 3 – скорее «тройка». Для рутинных задач сойдёт. Для серьёзных решений – уже нет.
Что происходит глобально
Мы намеренно тестировали и модели, заблокированные в России. Иначе нельзя понять масштаб «российского разрыва».
Глобальный топ выглядит так:
| Модель | Балл | Доступность в РФ |
|---|---|---|
| Claude Sonnet 4.5 (Anthropic) | 4,78 | ❌ VPN |
| GPT-5.2 Pro (OpenAI) | 4,78 | ❌ VPN |
| Claude Opus 4.5 (Anthropic) | 4,77 | ❌ VPN |
Средний балл глобального топ-3: 4,78. Средний балл российского топ-3: 4,36.
Разрыв – 0,42 балла.
В абстрактных числах это кажется немного. Но на шкале от 1 до 5 это разница между «отлично» и «хорошо». Примерно как А–/B+ на западной системе оценок. Для большинства ежедневных задач разница не критична. Для сложных аналитических или стратегических – может ощущаться.
Интересно то, что этот разрыв не равномерен по категориям задач.
Как российские модели справляются с разными задачами

Что означают категории: Планирование – составление планов, повестки встреч, приоритизация задач. Решение проблем – анализ сбоев, поиск корневых причин, антикризисные решения. Анализ – интерпретация данных, выводы из отчётов, оценка рисков. Регионы – знание российского законодательства, культурных особенностей, локальных практик. Коммуникация – деловые письма, обратная связь, формулировки для команды. Поиск – фактчекинг, сбор информации, сравнение источников. Команда – управление людьми, конфликты, мотивация, performance review. Обучение – планы развития, карьерные беседы, обучающие материалы.
Мы смотрели на 8 категорий. В некоторых из них разрыв с глобальным топом минимален – в других существенен.
| Категория задач | Глобальный лидер | Балл | Лучший в РФ | Балл | Разрыв |
|---|---|---|---|---|---|
| Планирование | Sonnet | 4,84 | DeepSeek V3.2 | 4,73 | 0,11 |
| Решение проблем | Sonnet | 4,84 | DeepSeek V3.2 | 4,68 | 0,16 |
| Анализ и решения | Sonnet | 4,83 | DeepSeek R1 | 4,62 | 0,21 |
| Коммуникация | GPT-5 Mini | 4,77 | Grok 4.1 | 4,50 | 0,27 |
| Поиск информации | GPT-5.2 Pro | 4,69 | DeepSeek R1 | 4,42 | 0,27 |
| Управление командой | GPT-5.2 Pro | 4,81 | DeepSeek V3.2 | 4,49 | 0,32 |
| Региональная специфика | GPT-5.2 | 4,56 | DeepSeek V3.2 | 4,34 | 0,22 |
| Обучение и развитие | Opus | 4,81 | DeepSeek V3.2 | 4,30 | 0,51 |
Два вывода бросаются в глаза.
Первый: в планировании и решении задач российские модели почти догоняют глобальный топ. Разрыв в 0,11–0,16 балла практически незаметен в реальной работе.
Второй: в задачах обучения и развития сотрудников разрыв максимален – 0,51 балла. Это уже ощутимо. Если часто используете AI для написания планов развития, обратной связи по компетенциям, карьерных разговоров – здесь российские модели уступают заметнее.
9 уроков по AI для менеджеров – без регистрации и оплаты
Без платёжных данных • Доступ сразу после регистрации
Парадокс YandexGPT: почему «родная» модель проигрывает
Вот результат, который удивил нас больше всего.
Alice набрала 3,84 – это Уровень 3. Ниже DeepSeek, Grok, Mistral и даже MiMo v2 Flash от Xiaomi, о котором большинство менеджеров никогда не слышали.
Особенно показательна категория «региональная специфика» – задачи, где учитываются российские реалии, законодательство, культурные особенности. Казалось бы, именно здесь Яндекс должен быть вне конкуренции. Но нет: Alice набирает 3,68, тогда как GPT-5.2 – 4,56.
Это заставляет задуматься. Почему модель, обученная на русском языке и российском контексте, проигрывает американской модели в задачах с российской спецификой?
Интересно, что сам Яндекс заявляет, что Alice AI побеждает DeepSeek V3.1 и Qwen3-235B в 60% бизнес-задач. Если посмотреть детали – Alice сильнее всего в редактировании текстов (68% побед над DeepSeek) и суммаризации (65%). Но в генерации текстов Alice уже проигрывает Qwen (62% в пользу Qwen), а в ответах на открытые вопросы – тоже (61% в пользу Qwen).
Важная деталь: Яндекс сравнивал с DeepSeek V3.1, а мы тестировали уже V3.2 – существенно обновлённую версию. Наше исследование показывает другую картину: Alice (3,84) уступает DeepSeek V3.2 (4,41) по всем восьми категориям управленческих задач. Причины расхождения – разные версии моделей, разные методологии и разный набор задач. Но на практике для менеджера результат один: DeepSeek V3.2 выдаёт более полезные и точные ответы.
Наша интерпретация: аналитические способности модели важнее, чем «родной язык». DeepSeek прекрасно говорит по-русски и при этом аналитически сильнее.
Если вы используете YandexGPT через Алису в Яндекс Браузере как основной рабочий инструмент – наши данные говорят, что вы оставляете значительный потенциал на столе. Подробный разбор YandexGPT описывает, в чём он силён, а в чём проигрывает.
Подробнее о моделях Яндекса
В исследовании участвовали четыре модели Яндекса. Вот как они показали себя по категориям:
| Категория | Alice AI LLM | YandexGPT Pro 5.1 | YandexGPT Pro 5 | YandexGPT Lite |
|---|---|---|---|---|
| Анализ и решения | 4,42 | 3,66 | 3,20 | 3,13 |
| Решение проблем | 4,33 | 3,62 | 3,08 | 2,64 |
| Коммуникация | 4,19 | 3,43 | 3,06 | 2,66 |
| Планирование | 4,15 | 3,47 | 3,19 | 2,86 |
| Поиск информации | 3,95 | 2,18 | 2,53 | 2,38 |
| Региональная специфика | 3,68 | 2,95 | 2,50 | 2,37 |
| Команда | 3,50 | 3,11 | 2,84 | 2,65 |
| Обучение и развитие | 2,70 | 2,70 | 2,40 | 2,24 |
| Среднее | 3,86 | 3,14 | 2,85 | 2,61 |
Несколько наблюдений:
- Alice AI LLM – единственная конкурентоспособная модель Яндекса. В анализе (4,42) и решении проблем (4,33) она показывает результат на уровне Tier 2. Остальные три модели – заметно слабее. API Alice стоит 0,50 ₽/1K входных и 2,00 ₽/1K выходных токенов (с учётом действующей скидки 50%).
- Обучение и развитие – слабое место всех моделей Яндекса. Даже Alice набирает здесь только 2,70 – это самый низкий результат среди всех её категорий. Для сравнения: DeepSeek V3.2 в этой же категории – 4,30.
- YandexGPT Pro 5.1, Pro 5 и Lite набирают 2,6–3,1 в среднем. Это уровень, при котором ответы модели скорее вредят, чем помогают – слишком много неточностей и поверхностных рекомендаций.
- Региональная специфика – казалось бы, козырь Яндекса – даёт у Alice только 3,68. У DeepSeek V3.2 – 4,34 в той же категории.
Подробнее о возможностях и ограничениях всех моделей Яндекса – в обзоре YandexGPT.
Чат vs API: что доступно без технических навыков
Важное уточнение: исследование проводилось через API. Но большинство менеджеров используют чат-интерфейсы, а не пишут код. Вот что реально доступно «кнопкой»:
Чат-интерфейсы:
- DeepSeek – бесплатный чат на chat.deepseek.com. Работает без VPN, без регистрации через российский номер. Просто открываете и работаете.
- Grok – через X Premium ($8/мес) или SuperGrok ($30/мес) на x.ai. Требует подписки, но доступ прямой.
- Qwen – бесплатный чат на chat.qwen.ai. Модели Уровня 3, но для простых задач подойдёт.
- YandexGPT/Alice – через alice.yandex.ru или Яндекс Браузер. Бесплатно, удобно, но качество – как показало исследование.
- Mistral – бесплатный Le Chat на chat.mistral.ai. Хорошая альтернатива, особенно для европейского контекста.
Только через API:
- MiMo v2 Flash – никакого чата нет, только для разработчиков. Зато ~$0,0004 за запрос.
- MiniMax M1 – аналогично.
Если вы не хотите разбираться с API – ваш выбор это DeepSeek для ежедневной работы и Grok как более дорогая, но качественная альтернатива.
Стратегия 80/20: как оптимизировать затраты
Если вы всё-таки готовы работать через API – есть разумная стратегия.
Не все задачи одинаковые. Написать черновик письма партнёру – одно. Проанализировать финансовый отчёт перед советом директоров – другое.
Для 80% задач достаточно дешёвой модели: MiMo v2 Flash ($0,0004/запрос) или DeepSeek V3.2 ($0,0007/запрос). Для 20% сложных задач – DeepSeek R1 ($0,0028/запрос) или Grok 4.1 Fast ($0,0007/запрос).
Примерный расчёт при 1 000 запросов в месяц:
- 80/20 стратегия с MiMo + DeepSeek R1: ~$0,85/мес
- Только DeepSeek V3.2 для всего: ~$0,73/мес
- Только Grok 4.1 Fast для всего: ~$0,70/мес
Да, вы прочитали правильно – меньше доллара в месяц. С новыми ценами марта 2026 года API-доступ к лучшим российским моделям стоит дешевле чашки кофе. Вопрос стоимости фактически снят – выбирайте по качеству.
Такой подход – использовать AI как co-pilot с разными уровнями инструментов – мы подробно разбираем в сравнительном обзоре всех GenAI-инструментов.
Важные оговорки
Несколько вещей, которые нужно учитывать, прежде чем принимать решения на основе этих данных.
Модели обновляются. С момента тестирования (январь 2026) GPT-5.2 уже стал GPT-5.4, Qwen вышел в новых версиях. GPT-4o, занявший 29-е место, официально снят с производства в феврале 2026 – но это не влияет на выводы, поскольку он и так проигрывал. Остальные модели из исследования по-прежнему доступны. Мы не ожидаем кардинальных изменений рейтинга для управленческих задач – крупные модели совершенствуются постепенно. Но если вы тестируете конкретную версию – проверяйте актуальность.
GigaChat не тестировался. Мы сознательно исключили его из этого исследования – это отдельная история с корпоративным доступом, соглашениями и особым регуляторным контекстом. Возможно, в следующем исследовании. Если вас интересует текущее состояние модели – обзор GigaChat даёт актуальную картину.
API ≠ чат-интерфейс. Мы тестировали через API со стандартными запросами. Реальный опыт использования в чате может отличаться – другие системные промпты, различный контекст, разные режимы работы.
Наивный пользователь. Все запросы составлялись без специальной оптимизации промптов. Если вы умеете работать с AI – ваши результаты будут лучше у всех моделей. Разрывы между ними могут меняться.
Итог
Хорошая новость: разрыв с глобальным топом в 0,42 балла – это не катастрофа. Российские пользователи AI имеют доступ к инструментам уровня «B+», тогда как глобальный топ – это «A–». Для большинства ежедневных управленческих задач это вполне приемлемо.
DeepSeek V3.2 – очевидный первый выбор. Бесплатный чат, дешёвое API, лучший балл среди доступных. Подробный обзор DeepSeek поможет разобраться, как именно его использовать.
Grok – сильная альтернатива с прямым доступом через x.ai. Обзор Grok описывает его особенности и сценарии, где он опережает DeepSeek.
А вот ставить на YandexGPT как основной рабочий инструмент – данные этого не поддерживают.
Парадоксально, но в 2026 году лучший AI для русскоязычного менеджера – это китайская модель. Как это произошло и что это говорит о развитии индустрии – хороший вопрос для отдельного разбора.
Разберитесь с AI системно – без угадывания
9 уроков по работе с AI для менеджеров: какой инструмент для какой задачи, как избежать галлюцинаций, как выстроить рабочий процесс. Без регистрации и оплаты.