Лучшие AI для менеджера в России: 52 модели, 3300+ оценок
AI-модели в этой статье
Мы провели масштабное исследование: 54 модели, оценки от двух независимых LLM-судей, 8 категорий управленческих задач. Это самый полный русскоязычный рейтинг AI для менеджеров на сегодня.
Вопрос остаётся тем же: какой AI реально работает для руководителя в России – без VPN, без костылей?
Методология: коротко
54 модели тестировались на 32 сценариях управленческих задач на русском языке по единой методологии. Запросы – от лица обычного менеджера, без специально отточенных промптов.
Оценку выставляли два судьи – Claude Opus 4.5 и Gemini 3 Pro. Человеческая калибровка (23 оценки) выявила смещения: Opus занижал на 0,39 балла, Gemini завышал на 0,53. Итоговый балл: 70% Opus + 30% Gemini после коррекции. Шкала 1–5.
Что означают баллы на практике:
- 4,5–5,0 – ответ можно использовать сразу: конкретные рекомендации, актуальные данные, чёткая структура. Как если бы вам ответил компетентный коллега.
- 4,0–4,4 – ответ полезен, но нужна доработка: кое-где поверхностно, 1–2 неточности, не всегда учтён контекст вашей ситуации.
- 3,0–3,9 – ответ «в общих чертах верный», но с заметными пробелами: общие фразы вместо конкретики, устаревшие данные, слабая адаптация под задачу. Придётся перепроверять и переписывать.
- Ниже 3,0 – ответ скорее мешает: ошибки в фактах, нерелевантные советы, риск принять неверное решение, если доверять модели.
Быстрый ответ: что брать без VPN
Если не хочется читать дальше – вот ответ на март 2026.
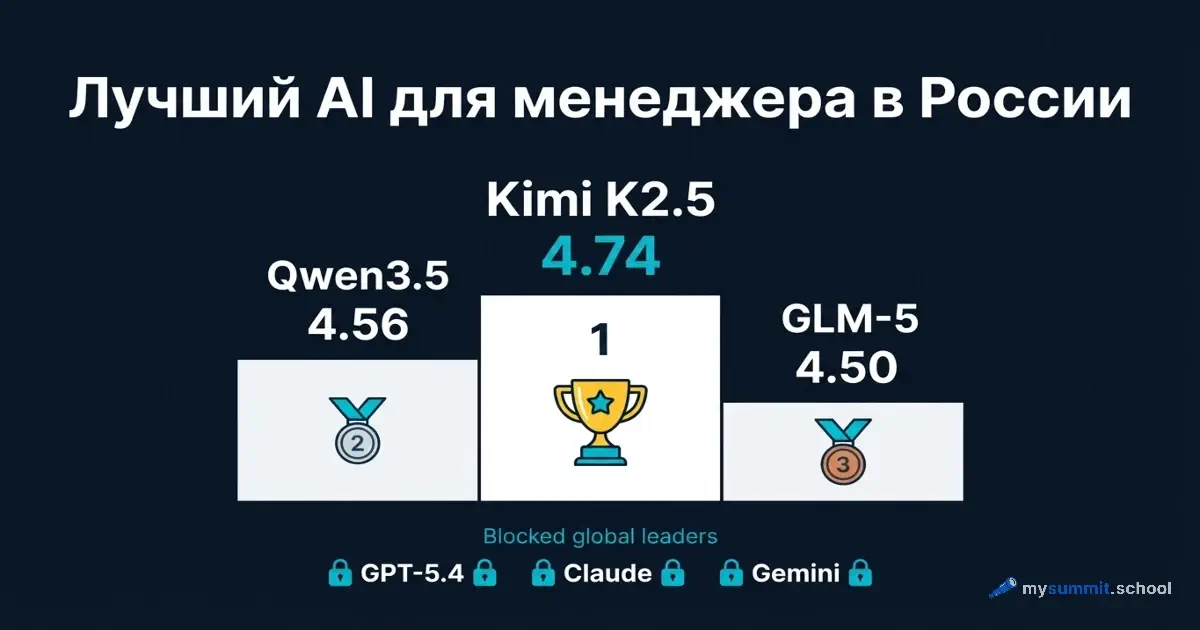
Первый выбор: Kimi K2.5. Балл 4,74 из 5,0 – шестое место в мире, первое среди доступных в России. Веб-чат kimi.com работает без VPN. Бесплатный тариф есть, платные от $19/мес. Уникальная функция – Agent Swarm: 100 параллельных агентов для сложных исследований. Слабое место – русский язык заметно хуже английского.
Второй выбор: Qwen3.5 Plus. Балл 4,56, 13-е место в мире. Бесплатный чат на chat.qwen.ai. API стоит ~$0,0005 за запрос – почти бесплатно. Самая сильная прямая модель в планировании (4,83).
Третий выбор: GLM-5 от Z.ai. Балл 4,50, 15-е место. Бесплатный чат на chat.z.ai, открытый код. Первое место среди всех 52 моделей в управлении командой (4,83). Слабое место – региональная специфика (3,95).
Четвёртый выбор: DeepSeek V3.2. Балл 4,42, 19-е место. Бесплатный чат на chat.deepseek.com. API ~$0,0004 за запрос. Лучше GLM-5 и Kimi в понимании российского контекста (4,34 в региональной категории).
Для большинства ежедневных задач менеджера этих четырёх моделей более чем достаточно.
Полная картина: уровни доступных моделей
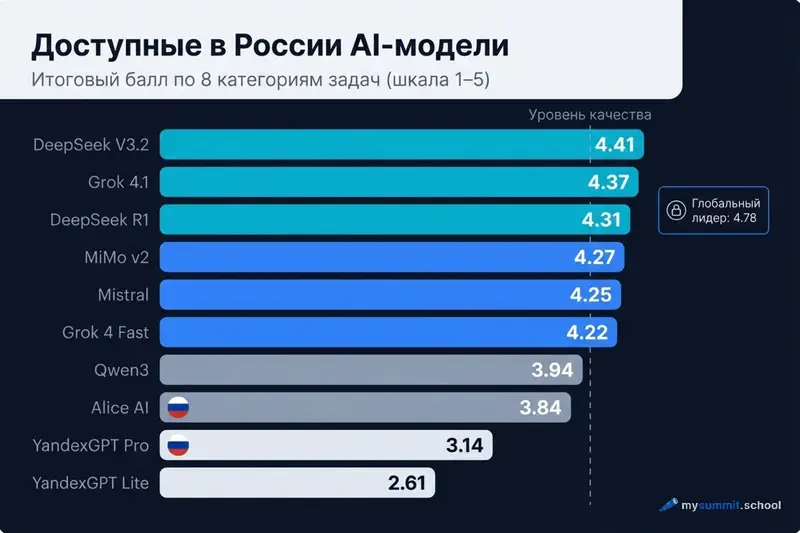
Все модели, доступные из России – напрямую или через по API – разбиты на уровни по итоговому баллу.
Уровень 1: элита (≥ 4,50)
| Модель | Балл | Место в мире | Доступ | Стоимость / запрос |
|---|---|---|---|---|
| Kimi K2.5 | 4,74 | 6 | kimi.com (бесплатно/платно) | ~$0,0008 |
| MiniMax M2.7 | 4,69 | 7 | только API | ~$0,0005 |
| MiMo V2 Omni (Xiaomi) | 4,62 | 11 | только API | ~$0,0007 |
| Qwen3.5 Plus | 4,56 | 13 | chat.qwen.ai (бесплатно) | ~$0,0005 |
| Qwen3.5 397B | 4,55 | 14 | chat.qwen.ai (бесплатно) | ~$0,0008 |
| GLM-5 | 4,50 | 15 | chat.z.ai (бесплатно) | ~$0,0009 |
Семь моделей – вдвое больше, чем три месяца назад. Китайские модели доминируют: пять из семи – из Китая.
Уровень 2: сильные модели (4,20–4,49)
| Модель | Балл | Место в мире | Доступ | Стоимость / запрос |
|---|---|---|---|---|
| Nemotron 3 Super (NVIDIA) | 4,48 | 16 | API | Пока что бесплатно, через OpenRouter |
| Qwen3 Max | 4,42 | 18 | chat.qwen.ai | ~$0,0014 |
| DeepSeek V3.2 | 4,42 | 19 | chat.deepseek.com (бесплатно) | ~$0,0004 |
| Qwen3 Max Thinking | 4,39 | 21 | chat.qwen.ai | ~$0,0014 |
| DeepSeek R1 | 4,33 | 22 | chat.deepseek.com (бесплатно) | ~$0,0008 |
| MiMo v2 Flash | 4,29 | 25 | только API | ~$0,0001 |
| Mistral Large | 4,28 | 26 | chat.mistral.ai (Le Chat) | ~$0,0024 |
| MiniMax M2.5 | 4,24 | 28 | только API | ~$0,0004 |
| Claude Sonnet 4.0 (OpenRouter) | 4,22 | 29 | только API | ~$0,0054 |
Здесь DeepSeek – по-прежнему лучшее соотношение цена/качество среди моделей с бесплатным чатом.
Уровень 3: рабочие лошадки (3,80–4,19)
| Модель | Балл | Место в мире | Доступ |
|---|---|---|---|
| MiniMax M1 | 4,14 | 30 | только API |
| Qwen3.5 9B | 4,11 | 33 | chat.qwen.ai |
| Mistral Small 4 | 4,05 | 34 | Le Chat / API |
| Perplexity Sonar | 4,00 | 36 | только API |
| Qwen3 235B | 3,97 | 37 | chat.qwen.ai |
| Alice AI LLM (Яндекс) | 3,86 | 38 | alice.yandex.ru |
Уровень 4: ниже порога полезности (< 3,80)
| Модель | Балл | Место в мире |
|---|---|---|
| Gemma 3 27B | 3,75 | 39 |
| Qwen3 32B | 3,67 | 40 |
| Gemma 3 12B | 3,58 | 41 |
| Gemma 3 4B | 3,27 | 42 |
| GigaChat-2-Max (Сбер) | 3,08 | 44 |
| GigaChat-Max-preview | 3,05 | 46 |
| Llama 4 Maverick | 2,95 | 47 |
| GigaChat-Pro-preview | 2,90 | 48 |
| YandexGPT Pro 5.1 | 3,13 | 43 |
| YandexGPT Pro 5 | 2,85 | 49 |
| GigaChat-2-Pro | 2,82 | 50 |
| YandexGPT Lite | 2,61 | 51 |
| Phi-4 | 2,27 | 52 |
Разрыв между уровнями ощутимый. Уровень 1 – это уверенная «пятёрка с минусом». Уровень 4 – модели, где ошибки и поверхностные ответы встречаются чаще, чем полезные.
Но выбрать модель – половина дела. Вторая половина – понять, какой инструмент для какой задачи использовать. В открытом модуле CH03 – девять практических заданий, где вы проверяете это на реальных управленческих кейсах.
52 модели в рейтинге, но результат зависит от того, как вы формулируете задачу. Открытый модуль CH03 – 9 практических заданий для менеджеров, бесплатно.
Доступ сразу после регистрации
Глобальный контекст: разрыв сокращается
Глобальный топ-5 – это модели, заблокированные в России:
| Модель | Балл | Доступность в РФ |
|---|---|---|
| GPT-5.4 (OpenAI) | 4,80 | ❌ VPN |
| GPT-5.2 Pro (OpenAI) | 4,78 | ❌ VPN |
| Claude Sonnet 4.5 (Anthropic) | 4,78 | ❌ VPN |
| Claude Opus 4.5 (Anthropic) | 4,78 | ❌ VPN |
| Claude Sonnet 4.6 (Anthropic) | 4,77 | ❌ VPN |
Средний балл глобального топ-5: 4,78. Средний балл российского топ-5 (Kimi, MiniMax M2.7, Qwen3.5 Plus, Qwen3.5 397B, GLM-5): 4,61.
Разрыв – 0,17 балла.
Kimi K2.5 с баллом 4,74 буквально дышит в спину Claude Sonnet 4.6 (4,77). Это уже не «B+ против A–». Это ближе к «A– против A».

Как доступные модели справляются с разными задачами
Что означают категории: Поиск – фактчекинг, сбор информации, сравнение источников. Коммуникация – деловые письма, обратная связь, формулировки для команды. Анализ – интерпретация данных, выводы из отчётов, оценка рисков. Планирование – составление планов, повестки встреч, приоритизация задач. Решение проблем – анализ сбоев, поиск корневых причин, антикризисные решения. Обучение – планы развития, карьерные беседы, обучающие материалы. Команда – управление людьми, конфликты, мотивация, performance review. Регионы – знание российского законодательства, культурных особенностей, локальных практик.
| Категория | Глобальный лидер | Балл | Лучший в РФ | Балл | Разрыв |
|---|---|---|---|---|---|
| Поиск информации | GPT-5.2 Pro | 4,69 | Kimi K2.5 | 4,64 | 0,05 |
| Коммуникация | GPT-5 Mini | 4,78 | MiniMax M2.7 | 4,67 | 0,11 |
| Анализ и решения | Claude Sonnet 4.5 | 4,83 | Qwen3.5 397B | 4,78 | 0,05 |
| Планирование | Claude Sonnet 4.5 | 4,84 | Qwen3.5 Plus | 4,83 | 0,01 |
| Решение проблем | Claude Sonnet 4.5 | 4,84 | MiMo V2 Omni | 4,81 | 0,03 |
| Обучение и развитие | Claude Sonnet 4.6 | 4,83 | MiMo V2 Omni | 4,83 | 0,00 |
| Управление командой | GPT-5.4 | 4,84 | MiMo V2 Omni | 4,84 | 0,00 |
| Региональная специфика | GPT-5.4 | 4,61 | MiniMax M2.7 | 4,50 | 0,11 |
Три месяца назад максимальный разрыв был 0,51 балла (обучение). Сейчас ни одна категория не имеет разрыва больше 0,11. В трёх категориях – решение проблем, обучение, управление командой – доступные в России модели сравнялись с глобальным топом.
Это качественный сдвиг. Раньше вопрос был «насколько мы отстаём?». Сейчас по многим задачам ответ – «ни насколько».
В таблице видно: ни одна модель не лидирует во всём. Значит, дело не в выборе «лучшей», а в умении подбирать инструмент под задачу. В открытом модуле – девять заданий, где именно этот навык тренируется на реальных кейсах.
Разрыв между моделями сокращается, но разрыв между «использую эпизодически» и «использую системно» – нет. Открытый модуль CH03 покажет разницу на практике.
Доступ сразу после регистрации
Kimi K2.5: неожиданный лидер
Kimi K2.5 от Moonshot AI – главное открытие рейтинга. Шестое место в мире с баллом 4,74, обходит GPT-5.2 (4,69), GPT-5 Mini (4,69) и Claude Haiku 4.5 (4,57).
Сильные стороны Kimi:
- Поиск информации (4,64) – второй результат в мире после GPT-5.2 Pro. Agent Swarm запускает десятки параллельных подзадач для сбора данных
- Решение проблем (4,78) – на уровне Claude Sonnet 4.5
- Стабильность – ни одна категория не ниже 4,38
Слабые стороны:
- Русский язык заметно слабее английского – в русскоязычных промптах Kimi иногда переходит на английский или даёт менее структурированные ответы
- Скорость в режиме Thinking – 29 секунд на ответ против 5 секунд у Claude Sonnet 4.6
- Требуется иностранная карта для платного тарифа
Подробный разбор – в обзоре Kimi K2.5.
Qwen3.5: тихая революция от Alibaba
Qwen3.5 Plus (13-е место, 4,56) и Qwen3.5 397B (14-е место, 4,55) – два варианта одной семейства, оба с прямым доступом из России через chat.qwen.ai.
Что выделяет Qwen3.5:
- Планирование – 4,83 у Plus, 4,82 у 397B. Это лучший результат среди всех доступных моделей и третий в мире
- Анализ – 4,78 у 397B. Второй результат в мире после Claude Sonnet 4.5
- Цена API – $0,26 за миллион входных токенов у Plus. Это в 10 раз дешевле Kimi и в 60 раз дешевле Claude
Слабое место – обучение и развитие (4,22–4,30). Для HR-задач лучше взять Kimi или MiMo V2 Omni.
Парадокс российских моделей: Яндекс и Сбер
YandexGPT
Alice AI LLM набрала 3,86 – 38-е место из 52. Это Уровень 3. Ниже Kimi, Qwen, GLM-5, DeepSeek, Mistral, MiniMax и даже MiMo v2 Flash от Xiaomi.
Показательна категория «региональная специфика» – задачи с российскими реалиями, законодательством, культурными особенностями. Alice набирает 3,68. Kimi K2.5 – 4,38. DeepSeek V3.2 – 4,34.
А самое слабое место Alice – обучение и развитие: 2,70. Для сравнения: DeepSeek V3.2 в этой же категории – 4,30. MiMo V2 Omni – 4,83.
Остальные модели Яндекса – YandexGPT Pro 5.1 (3,13), Pro 5 (2,85), Lite (2,61) – ниже порога практической полезности.
Подробнее – в обзоре YandexGPT.
GigaChat
В обновлённом исследовании мы добавили четыре модели Сбера. Результаты неутешительные:
| Модель | Балл | Место | Стоимость API ($/1M токенов) |
|---|---|---|---|
| GigaChat-2-Max | 3,08 | 44 | $7,22 / $7,22 |
| GigaChat-Max-preview | 3,05 | 46 | $7,22 / $7,22 |
| GigaChat-Pro-preview | 2,90 | 48 | $5,56 / $5,56 |
| GigaChat-2-Pro | 2,82 | 50 | $5,56 / $5,56 |
GigaChat – самые дорогие модели в исследовании с самым низким результатом. DeepSeek V3.2 стоит $0,27/$1,10 за миллион токенов и набирает 4,42 – в 1,4 раза выше по баллу при цене в 20 раз ниже. Подробнее – в обзоре GigaChat.
Чат vs API: что доступно без технических навыков
Большинство менеджеров используют чат-интерфейсы, а не API. Вот что реально доступно «кнопкой»:
Бесплатные чат-интерфейсы:
- Kimi K2.5 – kimi.com. Лучший общий результат среди доступных. Бесплатный тариф с лимитами
- Qwen3.5 – chat.qwen.ai. Лучшая модель для планирования и аналитики
- GLM-5 – chat.z.ai. Лучшая модель для управления командой
- DeepSeek – chat.deepseek.com. Лучшая модель для российской специфики среди бесплатных чатов
- Mistral – chat.mistral.ai. Хорошая альтернатива для европейского контекста
- YandexGPT/Alice – alice.yandex.ru. Бесплатно, удобно, но 38-е место из 52
Только через API (для разработчиков):
- MiniMax M2.7 (7-е место в мире) – никакого чата, но отличный результат
- MiMo V2 Omni (11-е место) – рекордсмен в обучении и командной работе
- Nemotron 3 Super (16-е место) – бесплатный API от NVIDIA
Стратегия использования: какую модель для какой задачи
Ни одна модель не лидирует во всех категориях. Оптимальная стратегия – использовать разные модели для разных задач:
| Задача | Лучшая доступная модель | Балл |
|---|---|---|
| Планирование проекта | Qwen3.5 Plus | 4,83 |
| Анализ данных и отчётов | Qwen3.5 397B | 4,78 |
| Решение проблем | MiMo V2 Omni | 4,81 |
| Написание писем и коммуникация | MiniMax M2.7 | 4,67 |
| Поиск информации | Kimi K2.5 | 4,64 |
| Обучение и развитие сотрудников | MiMo V2 Omni | 4,83 |
| Управление командой | MiMo V2 Omni | 4,84 |
| Российская специфика | MiniMax M2.7 | 4,50 |
Если выбирать одну модель для всего – Kimi K2.5. У неё самый ровный профиль: минимальный балл 4,38 (регионы), максимальный 4,78 (анализ). Разброс всего 0,40 – лучший показатель стабильности.
Если нужен бесплатный чат с прямым доступом – Qwen3.5 Plus. Сильнейшая модель с нулевыми затратами.
Такой подход – использовать AI как co-pilot с разными уровнями инструментов – мы подробно разбираем в сравнительном обзоре всех GenAI-инструментов.
Стоимость: вопрос фактически снят
Примерный расчёт при 1000 запросов в месяц через API:
| Стратегия | Стоимость/мес |
|---|---|
| Только DeepSeek V3.2 | ~$0,40 |
| Только Qwen3.5 Plus | ~$0,50 |
| 80% MiMo v2 Flash + 20% Kimi K2.5 | ~$0,24 |
| Только Kimi K2.5 | ~$0,80 |
Меньше доллара в месяц за AI уровня мирового топ-15. Стоимость перестала быть фактором выбора – выбирайте по качеству. А для задач с конфиденциальными данными или работы офлайн есть вариант вообще без подписки – локальные LLM на вашем ноутбуке.
Важные оговорки
Модели обновляются быстро. С момента начала исследования (январь 2026) появились Qwen3.5, Kimi K2.5, MiniMax M2.7, GigaChat-2 и другие. Мы добавляем новые модели по мере выхода, но snapshot всегда отстаёт от реальности на несколько недель.
API ≠ чат. Исследование проводилось через API со стандартными запросами. Реальный опыт в чате может отличаться – другие системные промпты, контекст, режимы работы.
Наивный пользователь. Все запросы – без специальной оптимизации промптов. Если вы умеете работать с AI – ваши результаты будут лучше у всех моделей.
OpenRouter – серая зона. Модели, доступные через OpenRouter (Kimi, MiniMax, GPT-5.4 Mini, Claude Sonnet 4.0), технически работают из России, но это не прямой доступ от провайдера. Стабильность и условия могут меняться. Оплата все еще требуется иностранной картой.
Итог
За три месяца ландшафт изменился радикально. Разрыв между глобальным топом и лучшими доступными в России моделями сократился с 0,42 до 0,17 балла. В трёх из восьми категорий разрыва больше нет вообще.
Kimi K2.5 – новый лидер среди доступных моделей. Qwen3.5 – лучшее бесплатное решение с прямым доступом. DeepSeek V3.2 – по-прежнему лучший выбор для задач с российским контекстом.
А вот YandexGPT и GigaChat – в хвосте рейтинга. Парадокс: лучшие AI для русскоязычного менеджера в 2026 году – это китайские модели. Российские разработки отстают не на проценты, а в разы по соотношению цена/качество.
54 модели изучены. Следующий шаг – ваш
Рейтинг показывает, что доступные модели уже на уровне мирового топа. Но модель – это инструмент, а результат определяет навык. Полная программа курса: от основ промпт-инжиниринга до специализаций по управлению проектами и аналитике. Научитесь выбирать правильный инструмент для каждой задачи.




Stanislav Belyaev
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.