Чего менеджеры хотят от ИИ: данные 40 реальных ответов
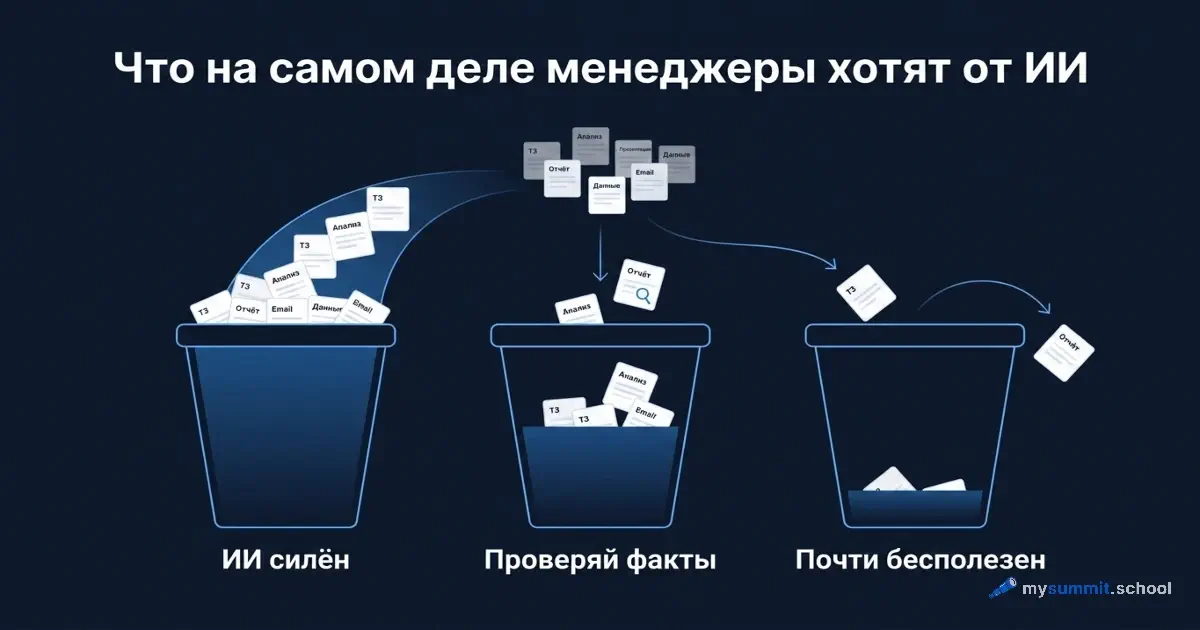
Мы редко знаем, чего люди на самом деле хотят от ИИ. Обычно за нас это решают вендоры в презентациях и блогеры в ленте. Поэтому, когда у нас накопились реальные ответы студентов на простой вопрос, мы решили на них посмотреть.
В одном из уроков модуля для руководителей есть короткое задание: написать одну-две фразы о том, какую рабочую задачу вы хотели бы ускорить с помощью ИИ. Без подсказок, без вариантов ответа. Сорок человек – менеджеры проектов и продуктов, аналитики, специалисты по персоналу – написали, чего они хотят. Это не опрос про намерения «в принципе». Это первичный спрос, снятый с людей, которые завтра пойдут применять инструмент к своей работе.
Картина оказалась интереснее, чем ожидалось. Больше половины запросов сошлись в три понятные группы. И эти три группы почти точно легли на то, что языковые модели реально делают хорошо. А выбросы – запросы, улетевшие куда-то не туда – оказались самым полезным, что было в этих данных.
Сразу оговорюсь про границы наблюдения. Сорок ответов – это не репрезентативная выборка по рынку, а срез одной аудитории: людей, которые уже пришли учиться работать с ИИ. Они мотивированнее среднего и, вероятно, насмотреннее. Но именно поэтому их запросы ценны: это не фантазии о технологии, а формулировки задач от тех, кто собирается их решать. Все ответы здесь анонимны и обобщены до уровня типа задачи – никаких имён, компаний или деталей, по которым можно кого-то узнать.
Три группы, в которые сошлась половина спроса
Если разложить ответы по смыслу, а не по формулировке, проступают повторяющиеся сюжеты. Три из них собрали вместе больше половины всех запросов.
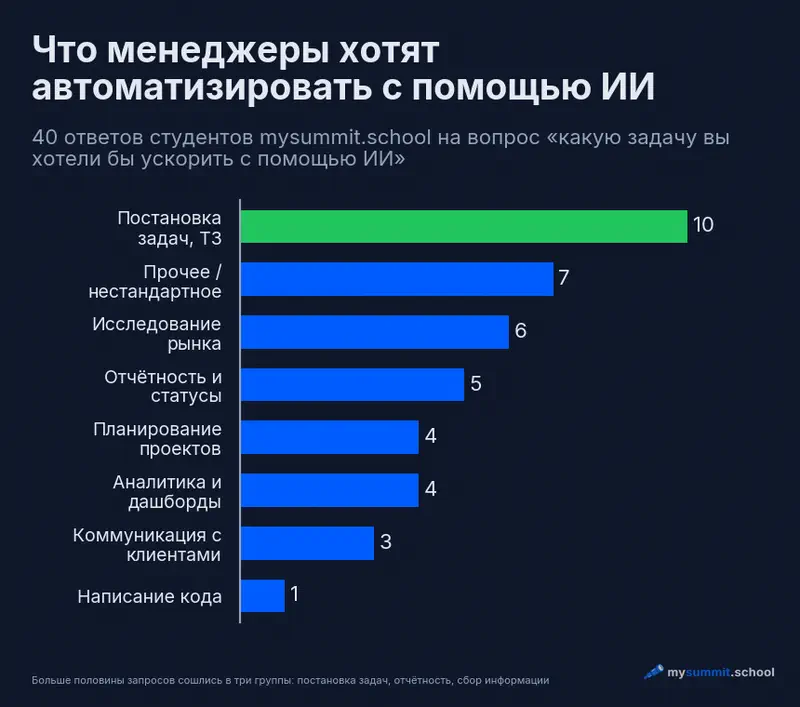
Самая крупная группа – постановка задач разработчикам и качество требований. Примерно каждый четвёртый ответ был про это: улучшить качество требований в постановках от аналитиков, составить ТЗ, проверить описание задачи перед передачей в разработку, стандартизировать постановки, написать user stories по схемам аналитика, собрать тест-план по требованиям. Разные роли, одна боль – превратить размытую мысль в структуру, которую не стыдно отдать команде.
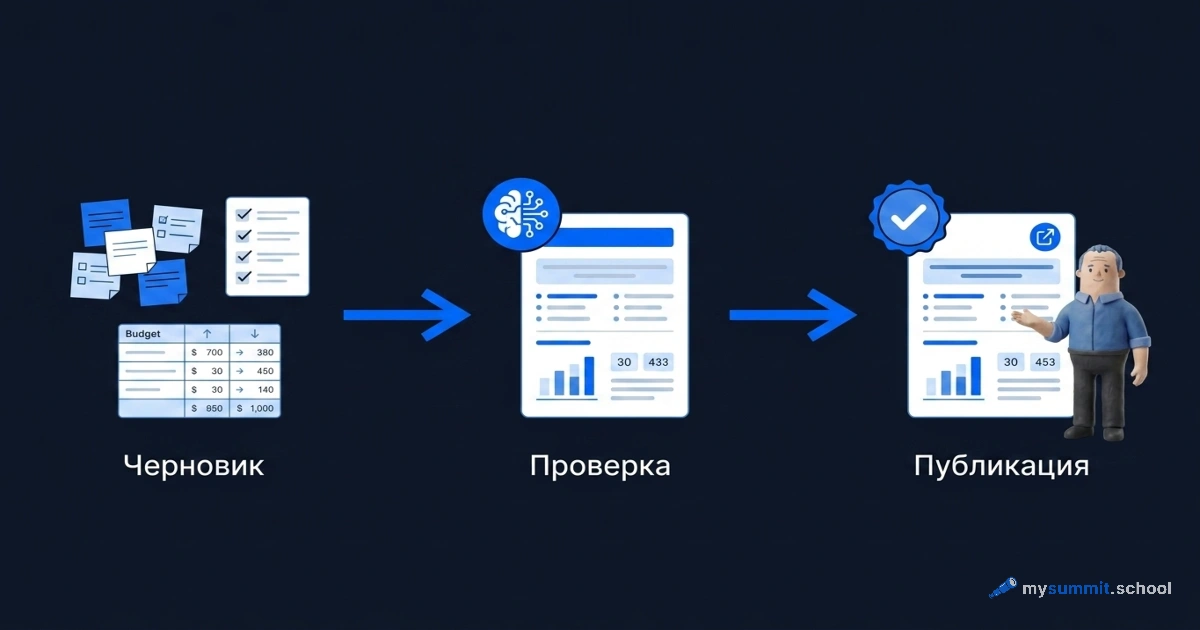
Вторая группа – отчётность и статусы. Еженедельный статус для команды и заинтересованных сторон, краткие резюме по итогам совещаний, отчёты по исполнению бюджета, материалы к ежедневным планёркам. Один человек описал свою мечту довольно точно: автоматически собирать черновик еженедельного отчёта и складывать его в таск-трекер перед публикацией. Перед публикацией – важная деталь, к которой мы ещё вернёмся.
Третья группа – сбор информации и анализ рынка: поиск кейсов применения ИИ в отрасли, анализ конкурентов, систематизация нормативной базы проекта. Рядом с ней держится отдельная группа про данные и дашборды – аналитические платформы, таблицы KPI, отчёты по эффективности кампаний. Я их разделяю намеренно: ресёрч и работа с данными совпадают со сильными сторонами ИИ очень по-разному, и об этом ниже.
Любопытно, что три самые частые группы – это ровно то, на чём языковые модели работают надёжнее всего. Постановка задач, отчётность, ресёрч – задачи про текст, структуру и переформулирование. Совпадение спроса и сильной стороны инструмента почти идеальное. То есть, аудитория интуитивно тянется туда, где выигрыш реальный, даже не зная заранее, как устроена модель. Это перекликается с общей картиной внедрения: реальное использование ИИ в командах концентрируется на одной-двух конкретных задачах, а не размазывается на всё сразу.
Почему именно эти задачи ложатся на сильные стороны ИИ
Стоит разобрать механизм, иначе совпадение выглядит случайным. Языковая модель хорошо делает то, что является работой с текстом: взять неструктурированный вход и привести его к нужной форме. Превратить три абзаца сырой мысли в ТЗ с критериями приёмки. Собрать заметки со встречи в резюме с решениями и ответственными. Сжать десять страниц в полстраницы выводов.
Постановка задач разработчикам – это работа с текстом в чистом виде. У менеджера или аналитика в голове есть понимание, что нужно, но оно не оформлено. Модель не придумывает требования за человека – она помогает их выгрузить, структурировать и проверить на полноту. Это та задача, где ИИ закрывает не творческую часть, а трудоёмкую: оформление, выравнивание формата, поиск пропущенных пунктов.
Отчётность устроена похоже. Исходные факты у менеджера уже есть – в переписке, в трекере, в заметках. Задача не в том, чтобы их добыть, а в том, чтобы собрать в читаемую форму под конкретного адресата. Это переупаковка, и модель в ней сильна.
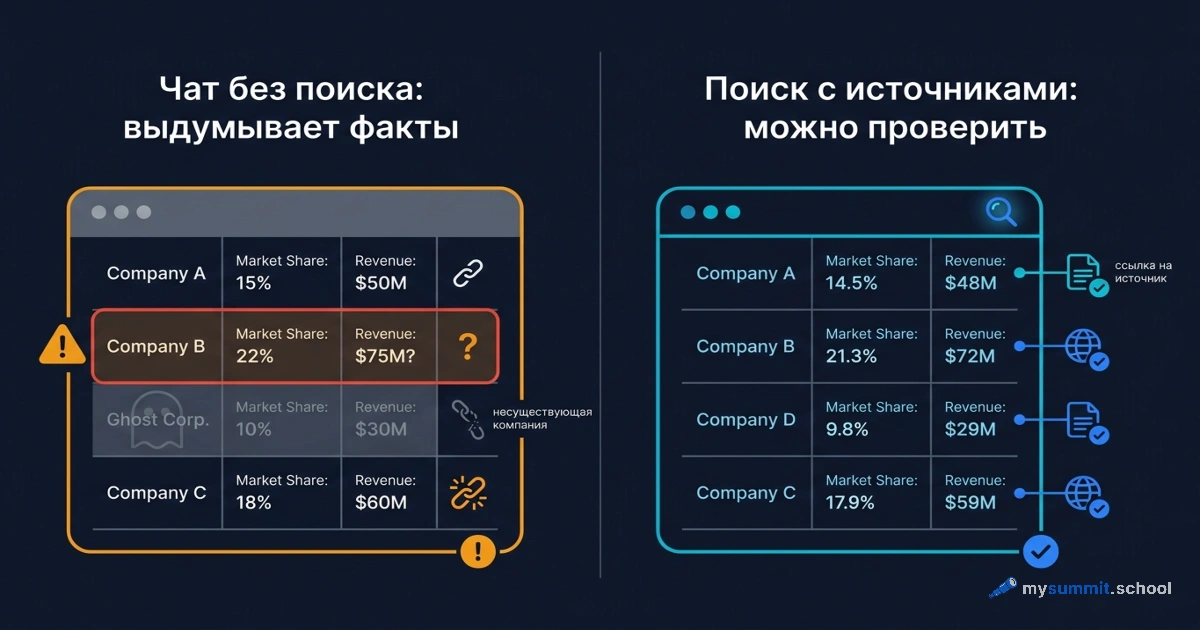
А вот с ресёрчем и данными сложнее, и здесь начинаются нюансы. Поиск кейсов и систематизация – это работа с текстом, модель справится. Но анализ конкретных цифр продаж или построение дашборда в BI-системе – это уже не текст. Это доступ к данным, точность вычислений и подключение к закрытой системе. Модель может написать формулу или объяснить логику, но она не заменит саму систему и легко ошибётся в арифметике, если её об этом попросить напрямую.
Разрыв между «помогает с текстом про данные» и «считает сами данные» – одна из главных ловушек ожиданий. Человек видит, что ИИ бодро рассуждает про аналитику, и делает вывод, что ему можно доверить расчёт. Доверять можно рассуждению о методе, проверять нужно каждую цифру.
Перед тем как раздавать ИИ задачи команде, полезно самому пройти десяток типовых управленческих ситуаций и увидеть, где он реально ускоряет, а где тихо подсовывает правдоподобную ошибку. Без этого граница между сильным и слабым применением остаётся теоретической.
Проверьте 9 реальных задач менеджера и сами увидите, на каких из них ИИ ускоряет работу, а на каких ошибается. Бесплатно, без регистрации.
Доступ сразу после регистрации
Выбросы, которые ценнее средних ответов
Самое полезное в этих сорока ответах – не три большие группы, а пять-шесть запросов, которые улетели куда-то в сторону. Их легко списать как шум, но именно они показывают, как люди думают об ИИ, когда у них ещё нет рабочей модели его возможностей.
Кто-то хотел получить список документов для оформления гражданства. Кто-то – научиться делать фильмы. Кто-то – проанализировать свою дату рождения (цифры опускаю). Кто-то – засечь реальное время пробега на дистанции. Кто-то – заносить товарно-материальные ценности в учётную систему.
Эти запросы кажутся разными, но за ними один общий механизм. Человек воспринимает ИИ как универсальную кнопку «сделай»: раз он умеет отвечать на любой вопрос, значит, умеет всё. Отсюда и список документов (модель его выдумает с устаревшими деталями), и анализ даты рождения (тут вообще нет задачи, которую можно решить), и ввод позиций в учётную систему (модель не имеет к ней доступа и ничего туда не занесёт).
Из забавного – запрос про фильмы и про время на дистанции честнее остальных. Они показывают не наивность, а здоровое любопытство: человек прощупывает границы, не имея карты. Это нормальная стадия. Проблема не в том, что люди задают такие вопросы, а в том, что без обратной связи они сделают неверный вывод. Попросят список документов, получат правдоподобную выдумку, примут её за правду – и либо обожгутся на практике, либо, наоборот, разочаруются и решат, что ИИ бесполезен.
Выбросы – это не глупость аудитории. Это отсутствующая ментальная модель. И ровно её даёт практика: пара неудачных заходов с понятным объяснением, почему не сработало, стоит десяти статей про «возможности ИИ». Любопытно, что исследования фиксируют похожее поведение в командах: люди скрывают, как пользуются ИИ, именно потому, что не уверены в своей карте его возможностей.
Простая диагностика на три корзины
Из всей этой картины складывается рабочий инструмент, который менеджер может применить к собственному списку задач в понедельник утром: сортировка по трём корзинам. Никакой теории про природу языковых моделей – только вопрос к каждой задаче.
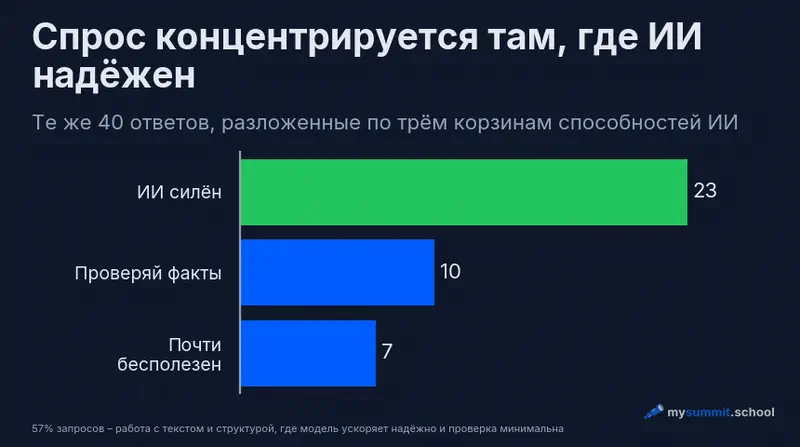
Первая корзина – ИИ силён. Сюда попадает всё, что является работой с текстом и структурой: превратить размытый запрос в ТЗ с критериями приёмки, собрать резюме встречи, сравнить два варианта решения по заданным критериям, переписать письмо под другого адресата. Признак этой корзины – исходная информация у вас уже есть, нужно привести её в форму. Здесь ИИ ускоряет надёжно, проверка нужна минимальная.
Вторая корзина – помогает, но проверяйте каждый факт. Сюда идут задачи про факты и данные, где модель ускоряет старт, но способна ошибиться: поиск кейсов, обзор рынка, черновик аналитической записки, объяснение метода расчёта. Признак этой корзины – результат выглядит правдоподобно, но содержит проверяемые утверждения. ИИ даёт каркас за минуты, а дальше работает ваша экспертиза: вы перепроверяете цифры, ссылки и факты.
Третья корзина – ИИ почти бесполезен в одиночку. Точный расчёт без инструментов, доступ к закрытой корпоративной системе, проверяемые свежие факты, действие в физическом мире. Заносить позиции в учётную систему, посчитать точное время на дистанции, выдать актуальный список документов для госуслуги – всё это либо требует доступа, которого у модели нет, либо точности, которой она не гарантирует. Здесь ИИ не помощник, а источник уверенно сформулированной ошибки.
Возьмите свой список из пяти-семи регулярных задач и разложите по корзинам. Скорее всего, окажется, что одна-две из них живут в первой корзине и просто ждут, когда вы перестанете делать их вручную. С них и стоит начинать.
Граница между первой и второй корзиной – это и есть навык, который отделяет случайную удачу от стабильного результата. Сформулировать задачу так, чтобы модель не додумывала, проверить ответ в правильном месте, понять, где доверять нельзя. Этот навык передаётся, но не появляется сам от факта установки приложения.
Разложите свои задачи по корзинам на практике: 9 управленческих ситуаций, где сразу видно, где ИИ надёжен, а где врёт. Бесплатно, без регистрации.
Доступ сразу после регистрации
Готовый шаблон для самой частой задачи
Раз постановка задач разработчикам оказалась запросом номер один, имеет смысл дать под неё копируемый промпт – конкретный инструмент, который вставляешь и адаптируешь.
Ниже – шаблон, который берёт размытую формулировку задачи и превращает её в структурированное ТЗ с критериями приёмки. Главное в нём – он не позволяет модели додумывать требования за вас. Если чего-то не хватает, шаблон заставляет ИИ задать вопрос, а не сочинить ответ.
Обратите внимание на пункт с открытыми вопросами. Большинство проблем с ТЗ не в том, что они плохо написаны, а в том, что в них есть дыры, которые автор не заметил. Модель, которой запрещено додумывать, эти дыры подсвечивает – и это часто полезнее самой структуры.
Когда первый проход даст результат, попробуйте короткий второй промпт – проверку готового ТЗ на полноту перед передачей в разработку:
Два этих шага вместе закрывают именно ту боль, которую чаще всего называли в ответах: качество требований перед передачей в разработку. Первый собирает структуру, второй её атакует. То самое «перед публикацией» из запроса про отчётность – здесь оно встроено в процесс. Аналогичный принцип – черновик плюс проверка человеком – работает и в других задачах, например в обработке входящих клиентских запросов.
Что стоит зафиксировать
Спрос реальных руководителей на ИИ оказался на удивление здравым. Больше половины запросов сошлись туда, где модели сильны: текст, структура, переупаковка информации. Аудитория интуитивно нащупывает правильные задачи ещё до того, как разбирается в механике.
Слабое место не в выборе задач, а в калибровке доверия. Те же люди, которые точно просят помочь с ТЗ, готовы поверить выдуманному списку документов или доверить модели расчёт, который она не вытянет. Разрыв проходит не между умными и наивными запросами, а внутри головы одного человека – между задачей из первой корзины и задачей из третьей, которые внешне выглядят одинаково уверенно.
Диагностика на три корзины не требует понимать, как устроена нейросеть. Она требует одного вопроса к каждой задаче: исходные данные у меня уже есть и нужно привести их в форму, или я прошу модель добыть факты и посчитать? В первом случае – вперёд. Во втором – вперёд, но с проверкой каждой цифры. А некоторые задачи стоит честно оставить инструментам, которые для них предназначены.
И последнее наблюдение, которое меня не отпускает. Самыми ценными в данных оказались не аккуратные средние ответы, а выбросы – запросы людей, которые тянутся к ИИ без карты его возможностей. Это и есть точка, где обучение работает: не рассказать про возможности, а дать пару задач, на которых карта рисуется сама. Вопрос к вам – а в какой корзине живёт ваша самая частая задача?
Научитесь видеть, где ИИ надёжен, а где врёт
Фундамент курса строит ту самую ментальную модель: какие задачи отдавать ИИ без сомнений, какие – с проверкой, а какие не отдавать вообще. На реальных управленческих ситуациях, а не на абстрактных примерах.

Часто задаваемые вопросы
Какие задачи руководители чаще всего хотят ускорить с помощью ИИ?
С какими задачами ИИ справляется плохо?
Как понять, подходит ли моя задача для ИИ?
Почему постановка задач разработчикам – самая частая задача для ИИ у менеджеров?

mysummit.school
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.