40 GigaChat Case Studies vs the Benchmark: Checking Sber's Numbers
Sber, Russia’s largest bank and the company behind GigaChat, released a sponsored showcase: forty business cases from companies that deployed GigaChat and reported the results. EdTech, MedTech, HRTech, cybersecurity, PropTech. Polished cards, concrete numbers, real startups.

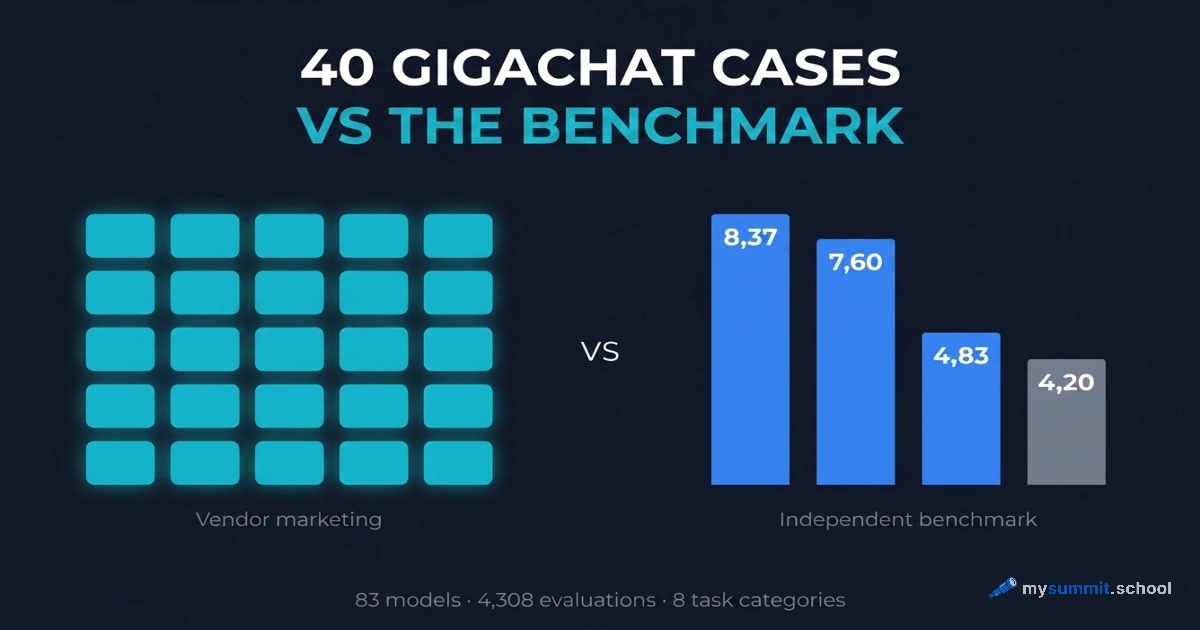
On the image: the “One step ahead” promo slide from the Sber500×GigaChat accelerator – 40 startups across 9 industries. Claimed effects: business processes up to x16 faster, costs down by up to 90%, up to 95% task automation, and revenue up by up to 30%.
We have a benchmark of our own: 29 models, 4,308 independent evaluations on managerial tasks. In it, GigaChat sits dead last – 29th out of 29 after the second wave of testing. That creates an interesting situation.
Not because Sber is lying. The cases are real, the startups exist, the automation works. The question is different: was this the optimal model for the tasks they were solving?
Read more