99% Quality at 1.4% of the Price: What's Wrong with the AI Model Market
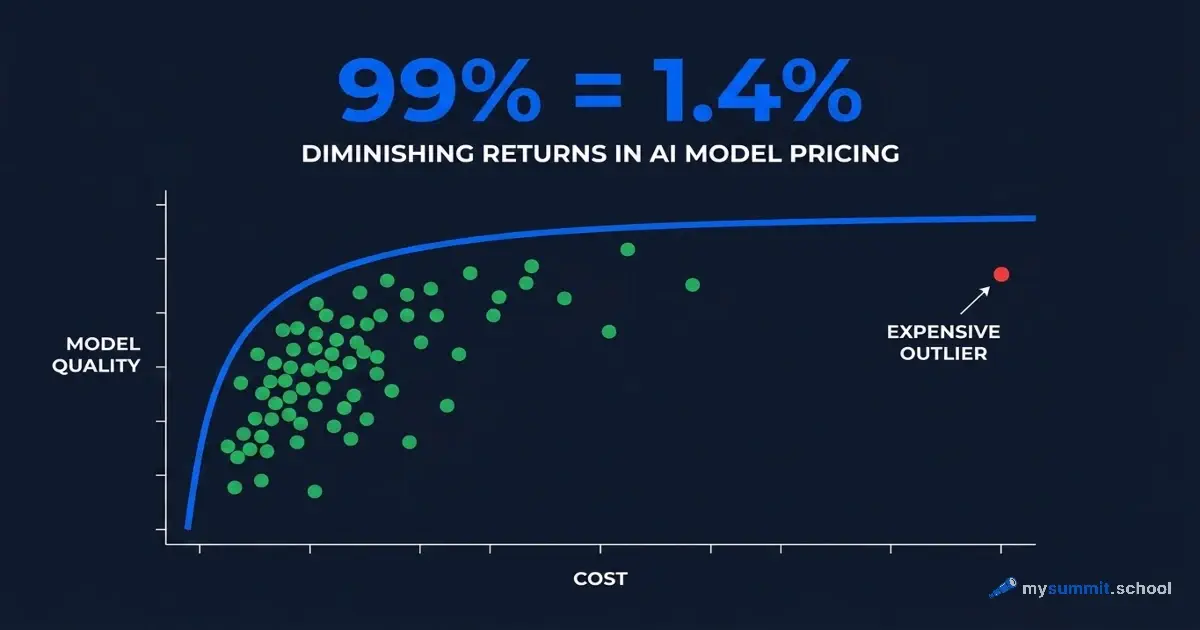
Most managers pick an AI model the same way: grab the most expensive one available. The logic makes sense – pricier means better. That’s how enterprise software worked for the last twenty years.
The AI model market in 2026 works differently. The cost per query ranges from $0.0001 to $0.17 – three orders of magnitude. And the actual quality difference between the top ten models? 0.24 points on a five-point scale. Meanwhile, Wharton / GBK Collective reports that a third of corporate AI projects never get past the pilot stage. And Epoch AI shows that only 5.6% of users apply AI in any genuinely deep way.
Maybe the question isn’t which model is best, but whether paying a premium delivers proportionally better results for typical management tasks.
We tested it. The answer was harsher than we expected.
The Data
Between January and March 2026, we tested 54 AI models across eight categories of management tasks – from drafting emails to data analysis and decision-making under incomplete information. Full results are published on our platform. A separate experiment – whether prompt engineering can compensate for a weaker model – showed that structured prompts narrow the gap but don’t close it entirely. Methodology: two AI evaluators (Claude Opus 4.5 and Gemini 3 Pro) plus human calibration, 2,121 individual evaluations. Each model receives a composite score from 1 to 5 and a cost per query in dollars.
Prices are a snapshot from April 2026, sourced from OpenRouter.ai – the only aggregator with a uniform pricing format. A caveat: API prices change fast. GPT-5.4 dropped from $0.0585 to $0.0158 per query during the study. GPT-5.2 Pro, meanwhile, went from $0.039 to $0.1659.
The final table includes 53 models (one was excluded due to opaque pricing).
Extremely Diminishing Returns
The price-quality relationship for AI models follows a logarithmic curve. Moving from the $0.0001 to the $0.002 price tier produces a quality jump of roughly 1.5 points. Moving from $0.002 to $0.17 – an 85x price increase – yields about 0.1 points.
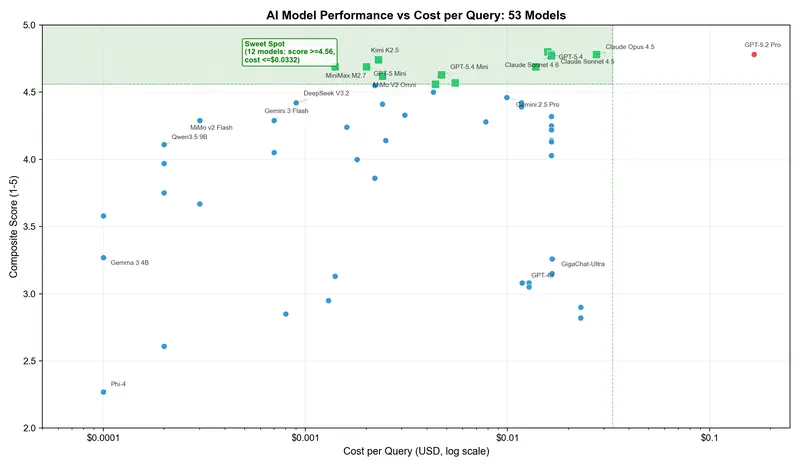
Here’s a concrete example. Claude Sonnet 4.5 scores 4.78 at $0.0165 per query. GPT-5.2 Pro also scores 4.78. But costs $0.1659. Ten times more expensive. Same result. We triple-checked – assumed it was a spreadsheet error. No, that’s just how the market works.
Then we looked at Kimi K2.5. Score: 4.74 at $0.0023 per query. That’s 99% of GPT-5.4’s quality for 1.4% of GPT-5.2 Pro’s price.
The 80/20 Strategy
Abstract comparisons are interesting, but what does this mean for an actual budget?
We modeled three strategies for a team of managers making 1,000 queries per month.
“All-in on premium” strategy: all queries through GPT-5.4. Cost: $15.80/month. Quality: 4.80.
80/20 strategy: 80% of routine tasks (emails, brief summaries, meeting notes) through a budget model like Qwen3.5 9B, 20% of complex tasks (strategy analysis, executive reports) through GPT-5.4. Cost: $3.32/month. Quality: 4.25.
The difference: minus 79% in costs with an 11% quality loss. For 80% of tasks – drafting an email, summarizing a document, preparing an agenda – the difference between a $0.0002 model and a $0.016 model is literally indistinguishable.
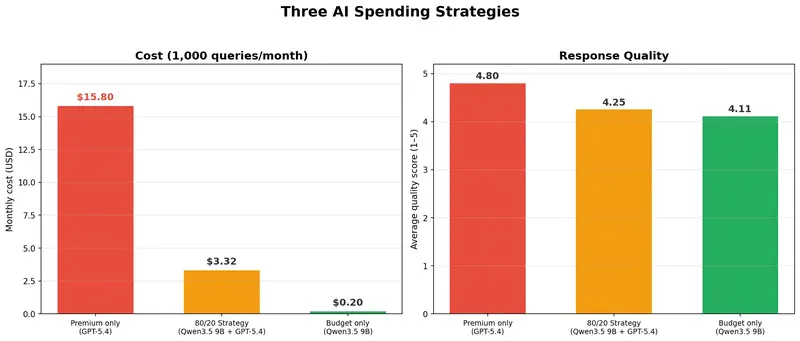
This isn’t a theoretical exercise. For a team of 10 managers at 100 queries per month each, the 80/20 strategy saves about $125 monthly compared to the “premium for everyone” approach. Not a transformational sum, but not zero either. And crucially – quality on 80% of tasks remains indistinguishable.
The arithmetic looks simple. The complexity begins when you need to decide concretely: here’s a task, here are three models – which one do you pick and why? The difference between “seems like it’ll work” and “I know why I chose this” is a skill built through real tasks.
Which tasks go to a budget model and which to premium? Try 9 management tasks on different models -- free, no registration required.
No payment required • Get notified on launch
Hidden Champions: The Performance Per Dollar Metric
We introduced a metric called PPD (Performance Per Dollar) – the quality score divided by cost per query. The higher the PPD, the more quality you get for every dollar spent.
The results flip the conventional picture.
| Model | Score | Cost/Query | PPD |
|---|---|---|---|
| GPT-5.2 Pro | 4.78 | $0.1659 | 28 |
| GPT-5.4 | 4.80 | $0.0158 | 304 |
| Kimi K2.5 | 4.74 | $0.0023 | 2,097 |
| DeepSeek V3.2 | 4.42 | $0.0009 | 4,825 |
| Gemini 3 Flash | 4.29 | $0.0007 | 6,085 |
| MiMo v2 Flash | 4.29 | $0.0003 | 12,434 |
| Qwen3.5 9B | 4.11 | $0.0002 | 21,076 |
Budget models deliver 40 to 1,700 times more quality per dollar than GPT-5.2 Pro. This isn’t a rounding error. It’s a structural market inefficiency you can exploit.
The “AI Tax” – And Who Pays It
Why does this even matter? Doesn’t everyone use AI the same way?
No. Research by Epoch AI / Ipsos found that 62% of AI users perform simple tasks – quick lookups, short drafts. Only 5.6% use AI deeply. For that 62%, the difference between a $0.002 query and a $0.17 query is literally invisible.
But the costs are visible. Workday’s 2026 report introduces the term “AI tax” – 37% of time “saved” by AI goes toward fixing its mistakes. But there’s another tax – a financial one: overpaying for a premium model on tasks where a budget model would perform just as well.
Brookings reports: among Americans who use AI, only 19% say it makes them more productive at work. 4% say significantly more productive. Google Cloud’s ROI report shows the other side: companies that see real results achieve them not by buying an expensive model, but by matching the right tool to the right task. Maybe the issue isn’t the tool – it’s how you choose it and what you spend on.
The 'task -> tool -> price' table is in Lesson 8 of the open module. 9 practical management tasks with AI, free.
No payment required • Get notified on launch
Practical Recommendations
If you manage an AI budget for a team – here’s what you can do this week.
Classify your tasks: email drafts, document summaries, policy lookups, meeting notes – that’s routine work, 70–80% of queries. Strategic analysis, executive materials, working with ambiguous data – complex tasks, 20–30%.
Set up routing: route routine tasks to a budget model (Kimi K2.5, Qwen3.5 Plus, DeepSeek V3.2 – all available via API), complex tasks to premium (GPT-5.4, Claude Sonnet 4.5). Technically, this could be an API gateway, a messenger bot with two buttons, or simply a team agreement: “for emails we use X, for analytics we use Y.” For tools that let you work with multiple models, see our OpenCode guide. For local model options, there’s a separate deep dive.
Measure: after a month, compare – did quality on routine tasks change? If not, you just cut your AI costs by 70–80% with no loss in output.
Caveats
Our benchmark tests specific categories of tasks. Premium models may indeed be stronger on complex multi-step reasoning or tasks we didn’t test. GPT-5.2 Pro, despite its price, shows remarkable consistency (standard deviation of 0.082) – some budget models have higher variance. The “AI evaluating AI” approach has its biases, though human calibration mitigates them.
And most importantly: these numbers are a snapshot of the market in April 2026. Prices change weekly. But the structural picture – extremely diminishing returns at the top price tier – is unlikely to change: too many competing models, prices falling too fast.
Conclusion
The hypothesis that “more expensive means proportionally better” is refuted by data. The AI model market in 2026 exhibits extremely diminishing returns: the premium markup is real and measurable. This doesn’t mean premium models are useless – for the 20% of tasks where quality is critical, the difference may justify the price. But using GPT-5.4 to summarize meeting notes is roughly like commuting to work by helicopter: technically superior, economically absurd.
The gap between price and quality in the AI model market is wider than ever – and unlikely to narrow in the coming year. But the more interesting question is this: if Kimi K2.5 delivers 99% of GPT-5.4’s quality at 1.4% of the price, what exactly is a manager buying when they choose premium? The provider’s reputation? Habit? Or the comfort of knowing “we use the best” – even when that “best” doesn’t show up in the results?
Full data is available in our study of 53 models.
From Experiment to System
Choosing a model is just one task in the course. The Foundation covers prompt engineering and critical thinking with AI. The Project Management specialization breaks down how to integrate AI into a manager's operational rhythm -- from drafts to analytics.



Stanislav Belyaev
Engineering Leader at Microsoft18 years leading engineering teams. Founder of mysummit.school. 700+ graduates at Yandex Practicum and Stratoplan.