Best AI for Managers Without VPN: Research Data

We completed a large-scale study: 33 AI models, 8 categories of management tasks. The question was simple – which AI works best for a manager? But the answer turned out more interesting than we expected.
Especially when it came to models accessible in Russia without a VPN.
What We Tested and How
Before the numbers – a brief note on methodology, because without this context the data means nothing.
33 models were tested on 32 real-world management scenarios: planning, communication, analysis, team management, information retrieval, and more. Each model received identical prompts in Russian – from the perspective of an ordinary manager, without specially crafted prompts. That’s how most people actually work with AI.
Evaluations were performed by two judges – Claude Opus 4.5 and Gemini 3 Pro. We conducted a human calibration with 23 evaluations that revealed systematic biases: Opus underscored by 0.39 points, Gemini overscored by 0.53. After correction, the final score is calculated as 70% Opus + 30% Gemini. More details on this part are in the methodology article.
The scale is 1 to 5. For context: 4.0 is already a solidly good result, 4.5+ is excellent.
The Short Answer: What to Use Without VPN
If you don’t want to read further – here’s the answer.
First choice: DeepSeek V3.2. Final score 4.41 out of 5.0. Free chat at chat.deepseek.com, API costs ~$0.0007 per request – literally pennies. Best result among all models accessible in Russia.
Second choice: Grok 4.1 Fast from xAI. Score 4.37. Available directly via x.ai, no VPN required. Since March 2026, xAI has radically cut prices – now ~$0.0007 per request, comparable to DeepSeek.
Third choice: DeepSeek R1. Score 4.31 – a version with extended reasoning, especially strong for analytical tasks. API ~$0.0028 per request.
That’s it. For most management tasks, these three models are enough.
The rest is details that matter depending on your specific tasks and budget.
The Full Picture: Tiers of Accessible Models

We grouped all tested models into three tiers by final score.
Tier 1: Russia’s Top 3 (>= 4.30)
| Model | Score | Access | Cost / request |
|---|---|---|---|
| DeepSeek V3.2 | 4.41 | chat.deepseek.com + direct API | ~$0.0007 |
| Grok 4.1 Fast | 4.37 | x.ai (X Premium / SuperGrok) | ~$0.0007 |
| DeepSeek R1 | 4.31 | chat.deepseek.com + direct API | ~$0.0028 |
Tier 2: Strong Alternatives (4.00–4.29)
| Model | Score | Access | Cost / request |
|---|---|---|---|
| MiMo v2 Flash (Xiaomi) | 4.27 | API only | ~$0.0004 |
| Mistral Large | 4.25 | chat.mistral.ai (Le Chat) + API | ~$0.0078 |
| Grok 4 Fast | 4.22 | x.ai | ~$0.0007 |
| MiniMax M1 | 4.12 | API only | – |
| Grok 4 | 4.12 | x.ai | ~$0.0007 |
| Grok 3 | 4.11 | x.ai | ~$0.0007 |
Tier 3: Noticeably Weaker (3.50–3.99)
| Model | Score | Access |
|---|---|---|
| Qwen3 235B | 3.94 | chat.qwen.ai |
| Alice AI LLM (Yandex) | 3.84 | alice.yandex.ru / Yandex Browser |
| Gemma 3 27B | 3.73 | API only |
| Qwen3 32B | 3.65 | chat.qwen.ai |
The gap between tiers is significant. If Tier 1 is a confident “B+”, then Tier 3 is closer to a “C+”. Fine for routine tasks. Not enough for serious decisions.
What’s Happening Globally
We deliberately tested models that are blocked in Russia as well. Otherwise, you can’t understand the scale of the “Russia gap.”
The global top looks like this:
| Model | Score | Availability in Russia |
|---|---|---|
| Claude Sonnet 4.5 (Anthropic) | 4.78 | VPN required |
| GPT-5.2 Pro (OpenAI) | 4.78 | VPN required |
| Claude Opus 4.5 (Anthropic) | 4.77 | VPN required |
Average score of the global top 3: 4.78. Average score of Russia’s top 3: 4.36.
The gap is 0.42 points.
In abstract numbers, that seems small. But on a 1-to-5 scale, it’s the difference between “excellent” and “good.” Roughly like A–/B+ in Western grading. For most daily tasks, the difference isn’t critical. For complex analytical or strategic work – it can be noticeable.
What’s interesting is that this gap isn’t uniform across task categories.
How Russia-Accessible Models Handle Different Tasks
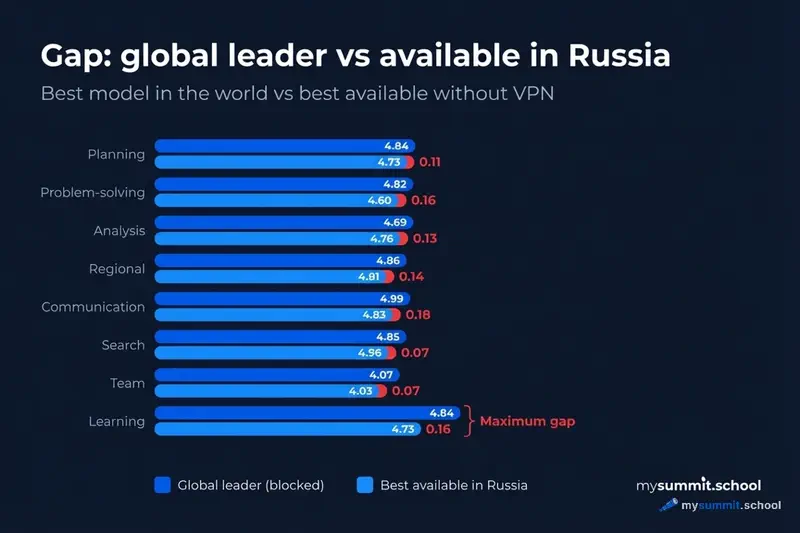
What the categories mean: Planning – creating plans, meeting agendas, task prioritization. Problem Solving – failure analysis, root cause identification, crisis management. Analysis – data interpretation, report insights, risk assessment. Regional – knowledge of Russian legislation, cultural nuances, local practices. Communication – business emails, feedback, team messaging. Research – fact-checking, information gathering, source comparison. Team – people management, conflicts, motivation, performance reviews. Training – development plans, career conversations, training materials.
We looked at 8 categories. In some, the gap with the global top is minimal – in others, it’s substantial.
| Task Category | Global Leader | Score | Best in Russia | Score | Gap |
|---|---|---|---|---|---|
| Planning | Sonnet | 4.84 | DeepSeek V3.2 | 4.73 | 0.11 |
| Problem Solving | Sonnet | 4.84 | DeepSeek V3.2 | 4.68 | 0.16 |
| Analysis & Decisions | Sonnet | 4.83 | DeepSeek R1 | 4.62 | 0.21 |
| Communication | GPT-5 Mini | 4.77 | Grok 4.1 | 4.50 | 0.27 |
| Information Research | GPT-5.2 Pro | 4.69 | DeepSeek R1 | 4.42 | 0.27 |
| Team Management | GPT-5.2 Pro | 4.81 | DeepSeek V3.2 | 4.49 | 0.32 |
| Regional Specifics | GPT-5.2 | 4.56 | DeepSeek V3.2 | 4.34 | 0.22 |
| Training & Development | Opus | 4.81 | DeepSeek V3.2 | 4.30 | 0.51 |
Two conclusions stand out.
First: in planning and problem solving, Russia-accessible models nearly match the global top. A gap of 0.11–0.16 points is practically invisible in real work.
Second: in training and employee development tasks, the gap is at its maximum – 0.51 points. That’s noticeable. If you frequently use AI for writing development plans, competency-based feedback, or career conversations – this is where Russia-accessible models lag most.
9 lessons on AI for managers – no registration or payment required
No payment required • Get notified on launch
The YandexGPT Paradox: Why the “Homegrown” Model Loses
Here’s the result that surprised us the most.
Alice (Yandex’s consumer AI assistant, powered by YandexGPT – Russia’s largest domestic language model) scored 3.84 – that’s Tier 3. Lower than DeepSeek, Grok, Mistral, and even MiMo v2 Flash from Xiaomi, which most managers have never heard of.
Particularly telling is the “regional specifics” category – tasks involving Russian laws, regulations, and cultural context. You’d expect Yandex to be unbeatable here. But no: Alice scores 3.68, while GPT-5.2 scores 4.56.
This makes you think. Why does a model trained on Russian language and Russian context lose to an American model on Russia-specific tasks?
Interestingly, Yandex itself claims that Alice AI beats DeepSeek V3.1 and Qwen3-235B in 60% of business tasks. Looking at the details – Alice is strongest in text editing (68% wins over DeepSeek) and summarization (65%). But in text generation, Alice already loses to Qwen (62% in Qwen’s favor), and in open-ended questions – likewise (61% in Qwen’s favor).
An important detail: Yandex compared against DeepSeek V3.1, while we tested the already-released V3.2 – a substantially updated version. Our research shows a different picture: Alice (3.84) trails DeepSeek V3.2 (4.41) across all eight management task categories. The discrepancy is due to different model versions, different methodologies, and different task sets. But in practice, the result for a manager is the same: DeepSeek V3.2 produces more useful and accurate answers.
Our interpretation: a model’s analytical capabilities matter more than its “native language.” DeepSeek speaks Russian excellently and is analytically stronger.
If you’re using YandexGPT through Alice in Yandex Browser as your primary work tool – our data suggests you’re leaving significant potential on the table. The detailed YandexGPT review describes where it’s strong and where it falls short.
More on Yandex’s Models
Four Yandex models participated in the study. Here’s how they performed across categories:
| Category | Alice AI LLM | YandexGPT Pro 5.1 | YandexGPT Pro 5 | YandexGPT Lite |
|---|---|---|---|---|
| Analysis & Decisions | 4.42 | 3.66 | 3.20 | 3.13 |
| Problem Solving | 4.33 | 3.62 | 3.08 | 2.64 |
| Communication | 4.19 | 3.43 | 3.06 | 2.66 |
| Planning | 4.15 | 3.47 | 3.19 | 2.86 |
| Information Research | 3.95 | 2.18 | 2.53 | 2.38 |
| Regional Specifics | 3.68 | 2.95 | 2.50 | 2.37 |
| Team | 3.50 | 3.11 | 2.84 | 2.65 |
| Training & Development | 2.70 | 2.70 | 2.40 | 2.24 |
| Average | 3.86 | 3.14 | 2.85 | 2.61 |
Key observations:
- Alice AI LLM is Yandex’s only competitive model. In analysis (4.42) and problem solving (4.33), it performs at a Tier 2 level. The other three models are noticeably weaker. Alice API costs 0.50 RUB/1K input tokens and 2.00 RUB/1K output tokens (with the current 50% discount applied).
- Training & development is a weak spot for all Yandex models. Even Alice scores only 2.70 here – its lowest category result. For comparison: DeepSeek V3.2 scores 4.30 in the same category.
- YandexGPT Pro 5.1, Pro 5, and Lite average 2.6–3.1. At this level, model responses are more likely to hurt than help – too many inaccuracies and superficial recommendations.
- Regional specifics – supposedly Yandex’s trump card – yields only 3.68 for Alice. DeepSeek V3.2 scores 4.34 in the same category.
More details on the capabilities and limitations of all Yandex models are in the YandexGPT review.
Chat vs. API: What’s Available Without Technical Skills
An important clarification: the study was conducted via API. But most managers use chat interfaces, not code. Here’s what’s actually available “by clicking a button”:
Chat interfaces:
- DeepSeek – free chat at chat.deepseek.com. Works without VPN, no registration via Russian phone number needed. Just open it and start working.
- Grok – via X Premium ($8/month) or SuperGrok ($30/month) at x.ai. Requires a subscription, but direct access.
- Qwen – free chat at chat.qwen.ai. Tier 3 models, but suitable for simple tasks.
- YandexGPT/Alice – via alice.yandex.ru or Yandex Browser. Free and convenient, but the quality is as the study showed.
- Mistral – free Le Chat at chat.mistral.ai. A good alternative, especially for European context.
API only:
- MiMo v2 Flash – no chat interface, developers only. But ~$0.0004 per request.
- MiniMax M1 – same situation.
If you don’t want to deal with APIs – your choice is DeepSeek for daily work and Grok as a pricier but high-quality alternative.
The 80/20 Strategy: How to Optimize Costs
If you’re willing to work through the API – there’s a smart strategy.
Not all tasks are equal. Drafting a letter to a partner is one thing. Analyzing a financial report before a board meeting is another.
For 80% of tasks, a cheaper model is enough: MiMo v2 Flash ($0.0004/request) or DeepSeek V3.2 ($0.0007/request). For 20% of complex tasks – DeepSeek R1 ($0.0028/request) or Grok 4.1 Fast ($0.0007/request).
Rough calculation for 1,000 requests per month:
- 80/20 strategy with MiMo + DeepSeek R1: ~$0.85/month
- DeepSeek V3.2 only for everything: ~$0.73/month
- Grok 4.1 Fast only for everything: ~$0.70/month
Yes, you read that right – less than a dollar per month. With the new March 2026 pricing, API access to the best Russia-accessible models costs less than a cup of coffee. The cost question is essentially moot – choose based on quality.
This approach – using AI as a co-pilot with different tiers of tools – is something we cover in detail in our comprehensive GenAI tools comparison.
Important Caveats
A few things to consider before making decisions based on this data.
Models get updated. Since testing (January 2026), GPT-5.2 has already become GPT-5.4, Qwen has released new versions. GPT-4o, which ranked 29th, was officially discontinued in February 2026 – but this doesn’t affect the conclusions since it was already underperforming. The other models from the study remain available. We don’t expect major ranking shifts for management tasks – large models improve gradually. But if you’re testing a specific version – check that it’s still current.
GigaChat was not tested. GigaChat is a large language model by Sberbank, Russia’s largest bank. We deliberately excluded it from this study – it’s a separate story involving enterprise access agreements and a specific regulatory context. Possibly in the next study. If you’re interested in the model’s current state – the GigaChat review provides an up-to-date picture.
API != chat interface. We tested via API with standard prompts. The actual experience using chat may differ – different system prompts, varying context, different operating modes.
Naive user. All prompts were composed without special prompt optimization. If you know how to work with AI – your results will be better across all models. The gaps between them may change.
Conclusion
The good news: a 0.42-point gap with the global top isn’t a catastrophe. Russian AI users have access to “B+” level tools, while the global top is “A–.” For most daily management tasks, this is perfectly acceptable.
DeepSeek V3.2 is the obvious first choice. Free chat, cheap API, best score among accessible models. The detailed DeepSeek review will help you figure out exactly how to use it.
Grok is a strong alternative with direct access via x.ai. The Grok review describes its strengths and scenarios where it outperforms DeepSeek.
As for betting on YandexGPT as your primary work tool – the data doesn’t support that.
Paradoxically, in 2026, the best AI for a Russian-speaking manager is a Chinese model. How this happened and what it says about the industry’s development – that’s a good question for a separate analysis.
Master AI systematically – no more guessing
9 lessons on working with AI for managers: which tool for which task, how to avoid hallucinations, how to build an effective workflow. No registration or payment required.