Best AI for Managers in Russia: 52 Models, 3,300+ Evaluations

We conducted a large-scale study: 52 models, evaluations from two independent LLM judges, across 8 categories of management tasks. This is the most comprehensive Russian-language AI ranking for managers available today.
The question remains the same: which AI actually works for a manager in Russia – without VPN, without workarounds?
Methodology: Brief
52 models were tested on 32 management task scenarios in Russian using a unified methodology. Prompts came from an ordinary manager’s perspective, without specially optimized prompting.
Two judges evaluated responses – Claude Opus 4.5 and Gemini 3 Pro. Human calibration (23 evaluations) revealed biases: Opus underscored by 0.39 points, Gemini overscored by 0.53. Final score: 70% Opus + 30% Gemini after correction. Scale: 1–5.
What the scores mean in practice:
- 4.5–5.0 – the response is ready to use: specific recommendations, up-to-date data, clear structure. Like getting an answer from a competent colleague.
- 4.0–4.4 – useful but needs refinement: somewhat surface-level in places, 1–2 inaccuracies, doesn’t always account for your specific context.
- 3.0–3.9 – “broadly correct” but with noticeable gaps: generic statements instead of specifics, outdated data, weak adaptation to your task. You’ll need to fact-check and rewrite.
- Below 3.0 – more harmful than helpful: factual errors, irrelevant advice, risk of making a wrong decision if you trust the model.
The Short Answer: What to Use Without VPN
If you don’t want to read further – here’s the answer as of March 2026.
First choice: Kimi K2.5. Score 4.74 out of 5.0 – 6th place globally, 1st among Russia-accessible models. Web chat at kimi.com works without VPN. Free tier available, paid plans from $19/month. Unique feature – Agent Swarm: 100 parallel agents for complex research tasks. Weakness – Russian language noticeably weaker than English.
Second choice: Qwen3.5 Plus. Score 4.56, 13th globally. Free chat at chat.qwen.ai. API costs ~$0.0005 per request – practically free. Strongest direct-access model for planning (4.83).
Third choice: GLM-5 by Z.ai. Score 4.50, 15th globally. Free chat at chat.z.ai, open source. 1st place among all 52 models in team management (4.83). Weakness – regional specifics (3.95).
Fourth choice: DeepSeek V3.2. Score 4.42, 19th globally. Free chat at chat.deepseek.com. API ~$0.0004 per request. Better than GLM-5 and Kimi at understanding Russian context (4.34 in the regional category).
For most daily management tasks, these four models are more than enough.
The Full Picture: Tiers of Accessible Models

All models accessible from Russia – directly or via OpenRouter – grouped by final score.
Tier 1: Elite (>= 4.50)
| Model | Score | Global Rank | Access | Cost / request |
|---|---|---|---|---|
| Kimi K2.5 | 4.74 | 6 | kimi.com (free/paid) | ~$0.0008 |
| MiniMax M2.7 | 4.69 | 7 | API only | ~$0.0005 |
| GPT-5.4 Mini (OpenRouter) | 4.63 | 10 | API only | ~$0.0016 |
| MiMo V2 Omni (Xiaomi) | 4.62 | 11 | API only | ~$0.0007 |
| Qwen3.5 Plus | 4.56 | 13 | chat.qwen.ai (free) | ~$0.0005 |
| Qwen3.5 397B | 4.55 | 14 | chat.qwen.ai (free) | ~$0.0008 |
| GLM-5 | 4.50 | 15 | chat.z.ai (free) | ~$0.0009 |
Seven models – double the count from three months ago. Chinese models dominate: five out of seven are from China.
Tier 2: Strong Models (4.20–4.49)
| Model | Score | Global Rank | Access | Cost / request |
|---|---|---|---|---|
| Nemotron 3 Super (NVIDIA) | 4.48 | 16 | API (free) | free |
| Qwen3 Max | 4.42 | 18 | chat.qwen.ai | ~$0.0014 |
| DeepSeek V3.2 | 4.42 | 19 | chat.deepseek.com (free) | ~$0.0004 |
| Qwen3 Max Thinking | 4.39 | 21 | chat.qwen.ai | ~$0.0014 |
| DeepSeek R1 | 4.33 | 22 | chat.deepseek.com (free) | ~$0.0008 |
| MiMo v2 Flash | 4.29 | 25 | API only | ~$0.0001 |
| Mistral Large | 4.28 | 26 | chat.mistral.ai (Le Chat) | ~$0.0024 |
| MiniMax M2.5 | 4.24 | 28 | API only | ~$0.0004 |
| Claude Sonnet 4.0 (OpenRouter) | 4.22 | 29 | API only | ~$0.0054 |
DeepSeek remains the best price-to-quality ratio among models with a free chat interface.
Tier 3: Workhorses (3.80–4.19)
| Model | Score | Global Rank | Access |
|---|---|---|---|
| MiniMax M1 | 4.14 | 30 | API only |
| Qwen3.5 9B | 4.11 | 33 | chat.qwen.ai |
| Mistral Small 4 | 4.05 | 34 | Le Chat / API |
| Perplexity Sonar | 4.00 | 36 | API only |
| Qwen3 235B | 3.97 | 37 | chat.qwen.ai |
| Alice AI LLM (Yandex) | 3.86 | 38 | alice.yandex.ru |
Tier 4: Below Usefulness Threshold (< 3.80)
| Model | Score | Global Rank |
|---|---|---|
| Gemma 3 27B | 3.75 | 39 |
| Qwen3 32B | 3.67 | 40 |
| Gemma 3 12B | 3.58 | 41 |
| Gemma 3 4B | 3.27 | 42 |
| GigaChat-2-Max (Sber) | 3.08 | 44 |
| GigaChat-Max-preview | 3.05 | 46 |
| Llama 4 Maverick | 2.95 | 47 |
| GigaChat-Pro-preview | 2.90 | 48 |
| YandexGPT Pro 5.1 | 3.13 | 43 |
| YandexGPT Pro 5 | 2.85 | 49 |
| GigaChat-2-Pro | 2.82 | 50 |
| YandexGPT Lite | 2.61 | 51 |
| Phi-4 | 2.27 | 52 |
The gap between tiers is significant. Tier 1 is a solid “A–”. Tier 4 – models where errors and superficial answers appear more often than useful ones.
Global Context: The Gap Is Shrinking
The global top 5 consists of models blocked in Russia:
| Model | Score | Russia Access |
|---|---|---|
| GPT-5.4 (OpenAI) | 4.80 | VPN required |
| GPT-5.2 Pro (OpenAI) | 4.78 | VPN required |
| Claude Sonnet 4.5 (Anthropic) | 4.78 | VPN required |
| Claude Opus 4.5 (Anthropic) | 4.78 | VPN required |
| Claude Sonnet 4.6 (Anthropic) | 4.77 | VPN required |
Global top-5 average: 4.78. Russia top-5 average (Kimi, MiniMax M2.7, Qwen3.5 Plus, Qwen3.5 397B, GLM-5): 4.61.
The gap: 0.17 points. Three months ago, when we first published this article, the gap was 0.42. It has shrunk by more than half – not because the global top got worse, but because genuinely strong models became accessible in Russia.
Kimi K2.5 at 4.74 is breathing down the neck of Claude Sonnet 4.6 (4.77). This is no longer “B+ vs A–.” It’s closer to “A– vs A.”
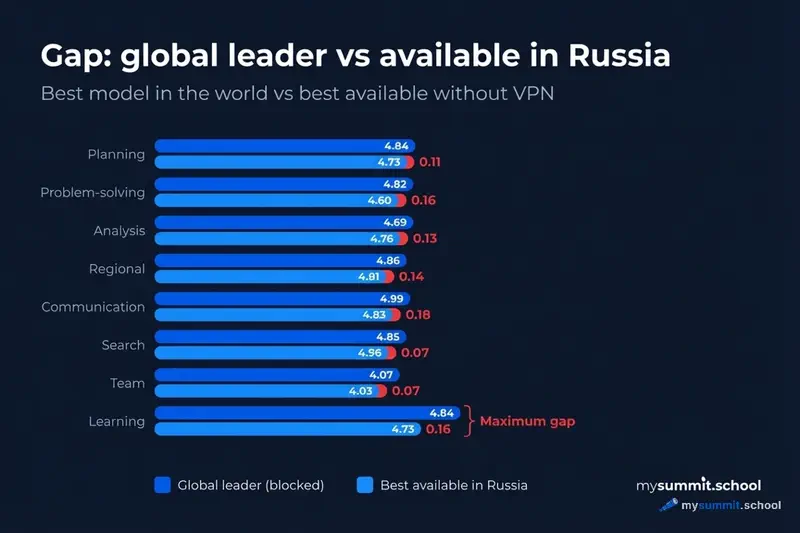
How Accessible Models Handle Different Tasks
What the categories mean: Research – fact-checking, information gathering, source comparison. Communication – business emails, feedback, team messaging. Analysis – data interpretation, report insights, risk assessment. Planning – creating plans, meeting agendas, task prioritization. Problem Solving – failure analysis, root cause identification, crisis management. Training – development plans, career conversations, training materials. Team – people management, conflicts, motivation, performance reviews. Regional – knowledge of Russian legislation, cultural nuances, local practices.
| Category | Global Leader | Score | Best in Russia | Score | Gap |
|---|---|---|---|---|---|
| Information Research | GPT-5.2 Pro | 4.69 | Kimi K2.5 | 4.64 | 0.05 |
| Communication | GPT-5 Mini | 4.78 | MiniMax M2.7 | 4.67 | 0.11 |
| Analysis & Decisions | Claude Sonnet 4.5 | 4.83 | Qwen3.5 397B | 4.78 | 0.05 |
| Planning | Claude Sonnet 4.5 | 4.84 | Qwen3.5 Plus | 4.83 | 0.01 |
| Problem Solving | Claude Sonnet 4.5 | 4.84 | MiMo V2 Omni | 4.81 | 0.03 |
| Training & Development | Claude Sonnet 4.6 | 4.83 | MiMo V2 Omni | 4.83 | 0.00 |
| Team Management | GPT-5.4 | 4.84 | MiMo V2 Omni | 4.84 | 0.00 |
| Regional Specifics | GPT-5.4 | 4.61 | MiniMax M2.7 | 4.50 | 0.11 |
Three months ago, the maximum gap was 0.51 points (training). Now no category has a gap greater than 0.11. In three categories – problem solving, training, team management – Russia-accessible models have matched the global top.
This is a qualitative shift. The question used to be “how far behind are we?” Now, for many tasks, the answer is “we’re not.”
How to use these models systematically? See the course program
10 уроков: встраиваете ИИ в планирование, отчётность и кризисное реагирование. Результат – не промпты, а рабочая система.
Kimi K2.5: The Unexpected Leader
Kimi K2.5 by Moonshot AI is the standout discovery of the updated ranking. 6th globally with a score of 4.74, surpassing GPT-5.2 (4.69), GPT-5 Mini (4.69), and Claude Haiku 4.5 (4.57).
Kimi’s strengths:
- Information research (4.64) – 2nd globally after GPT-5.2 Pro. Agent Swarm launches dozens of parallel sub-tasks for data collection
- Problem solving (4.78) – on par with Claude Sonnet 4.5
- Consistency – no category below 4.38
Weaknesses:
- Russian language is noticeably weaker than English – Kimi sometimes switches to English or gives less structured responses in Russian prompts
- Speed in Thinking mode – 29 seconds per response vs 5 seconds for Claude Sonnet 4.6
- Foreign credit card required for paid tier
Full review – in the Kimi K2.5 review.
Qwen3.5: The Quiet Revolution from Alibaba
Qwen3.5 Plus (13th, 4.56) and Qwen3.5 397B (14th, 4.55) – two variants from the same family, both with direct access from Russia via chat.qwen.ai.
What sets Qwen3.5 apart:
- Planning – 4.83 for Plus, 4.82 for 397B. The best result among all accessible models and 3rd globally
- Analysis – 4.78 for 397B. 2nd globally after Claude Sonnet 4.5
- API pricing – $0.26 per million input tokens for Plus. That’s 10x cheaper than Kimi and 60x cheaper than Claude
Weakness – training and development (4.22–4.30). For HR tasks, Kimi or MiMo V2 Omni are better choices.
The Russian Model Paradox: Yandex and Sber
YandexGPT
Alice AI LLM scored 3.86 – 38th out of 52. That’s Tier 3. Below Kimi, Qwen, GLM-5, DeepSeek, Mistral, MiniMax, and even Xiaomi’s MiMo v2 Flash.
The “regional specifics” category is telling – tasks involving Russian laws, regulations, and cultural context. Alice scores 3.68. Kimi K2.5 – 4.38. DeepSeek V3.2 – 4.34.
Alice’s weakest spot is training and development: 2.70. For comparison: DeepSeek V3.2 in the same category – 4.30. MiMo V2 Omni – 4.83.
The remaining Yandex models – YandexGPT Pro 5.1 (3.13), Pro 5 (2.85), Lite (2.61) – are below the practical usefulness threshold.
More details in the YandexGPT review.
GigaChat
In the updated study, we added four Sber models. The results are disappointing:
| Model | Score | Rank | API Cost ($/1M tokens) |
|---|---|---|---|
| GigaChat-2-Max | 3.08 | 44 | $7.22 / $7.22 |
| GigaChat-Max-preview | 3.05 | 46 | $7.22 / $7.22 |
| GigaChat-Pro-preview | 2.90 | 48 | $5.56 / $5.56 |
| GigaChat-2-Pro | 2.82 | 50 | $5.56 / $5.56 |
GigaChat models are the most expensive in the study with the lowest scores. DeepSeek V3.2 at $0.27/$1.10 per million tokens scores 4.42 – 1.4x higher at 20x lower cost. More in the GigaChat review.
Chat vs. API: What’s Available Without Technical Skills
Most managers use chat interfaces, not APIs. Here’s what’s available “by clicking a button”:
Free chat interfaces:
- Kimi K2.5 – kimi.com. Best overall result among accessible models. Free tier with limits
- Qwen3.5 – chat.qwen.ai. Best model for planning and analytics
- GLM-5 – chat.z.ai. Best model for team management
- DeepSeek – chat.deepseek.com. Best model for Russian context among free chats
- Mistral – chat.mistral.ai. Good alternative for European context
- YandexGPT/Alice – alice.yandex.ru. Free and convenient, but 38th out of 52
API only (for developers):
- MiniMax M2.7 (7th globally) – no chat, but excellent results
- MiMo V2 Omni (11th) – record-holder in training and team management
- Nemotron 3 Super (16th) – free API from NVIDIA
Usage Strategy: Which Model for Which Task
No single model leads in every category. The optimal strategy is to use different models for different tasks:
| Task | Best Accessible Model | Score |
|---|---|---|
| Project planning | Qwen3.5 Plus | 4.83 |
| Data analysis and reports | Qwen3.5 397B | 4.78 |
| Problem solving | MiMo V2 Omni | 4.81 |
| Emails and communication | MiniMax M2.7 | 4.67 |
| Information research | Kimi K2.5 | 4.64 |
| Employee training and development | MiMo V2 Omni | 4.83 |
| Team management | MiMo V2 Omni | 4.84 |
| Russian regional specifics | MiniMax M2.7 | 4.50 |
If choosing one model for everything – Kimi K2.5. It has the most even profile: minimum score 4.38 (regional), maximum 4.78 (analysis). A spread of just 0.40 – the best consistency metric.
If you need a free chat with direct access – Qwen3.5 Plus. The strongest model at zero cost.
This approach – using AI as a co-pilot with different tiers of tools – is covered in detail in our comprehensive GenAI tools comparison.
Cost: The Question Is Essentially Moot
Rough calculation for 1,000 API requests per month:
| Strategy | Cost/month |
|---|---|
| DeepSeek V3.2 only | ~$0.40 |
| Qwen3.5 Plus only | ~$0.50 |
| 80% MiMo v2 Flash + 20% Kimi K2.5 | ~$0.24 |
| Kimi K2.5 only | ~$0.80 |
| Nemotron 3 Super (NVIDIA) | free |
Less than a dollar per month for AI ranked in the global top 15. Cost is no longer a selection factor – choose based on quality. And for confidential data or offline work, there’s a zero-subscription option – local LLMs on your own laptop.
Important Caveats
Models update quickly. Since the study began (January 2026), Qwen3.5, Kimi K2.5, MiniMax M2.7, GigaChat-2, and others have been added. We add new models as they’re released, but any snapshot is always a few weeks behind reality.
API != chat. The study was conducted via API with standard prompts. The actual chat experience may differ – different system prompts, context, operating modes.
Naive user. All prompts were composed without prompt optimization. If you know how to work with AI – your results will be better across all models.
OpenRouter – gray area. Models accessible via OpenRouter (Kimi, MiniMax, GPT-5.4 Mini, Claude Sonnet 4.0) technically work from Russia, but this isn’t direct provider access. Stability and terms may change.
Conclusion
In three months, the landscape has changed radically. The gap between the global top and the best Russia-accessible models has shrunk from 0.42 to 0.17 points. In three out of eight categories, there is no gap at all.
Kimi K2.5 is the new leader among accessible models. Qwen3.5 is the best free solution with direct access. DeepSeek V3.2 remains the best choice for tasks involving Russian context.
Meanwhile, YandexGPT and GigaChat sit at the bottom of the ranking. The paradox: the best AI for a Russian-speaking manager in 2026 is a Chinese model. Russian-made solutions lag not by percentages, but by multiples in price-to-quality ratio.
Master AI systematically
Which tool for which task, how to avoid hallucinations, how to build an effective workflow – it's all in the course program.


Stanislav Belyaev
Engineering Leader at Microsoft18 years leading engineering teams. Founder of mysummit.school. 700+ graduates at Yandex Practicum and Stratoplan.