40 GigaChat Case Studies vs the Benchmark: Checking Sber's Numbers

AI models in this article
Sber, Russia’s largest bank and the company behind GigaChat, released a sponsored showcase: forty business cases from companies that deployed GigaChat and reported the results. EdTech, MedTech, HRTech, cybersecurity, PropTech. Polished cards, concrete numbers, real startups.

On the image: the “One step ahead” promo slide from the Sber500×GigaChat accelerator – 40 startups across 9 industries. Claimed effects: business processes up to x16 faster, costs down by up to 90%, up to 95% task automation, and revenue up by up to 30%.
We have a benchmark of our own: 29 models, 4,308 independent evaluations on managerial tasks. In it, GigaChat sits dead last – 29th out of 29 after the second wave of testing. That creates an interesting situation.
Not because Sber is lying. The cases are real, the startups exist, the automation works. The question is different: was this the optimal model for the tasks they were solving?
Where cases like these come from
Sber’s promotional material belongs to a genre with a well-established name: the vendor-sponsored case study. Companies describe their wins with a specific tool, the vendor publishes and promotes them. This is normal practice – every major AI company does it, from Microsoft to Anthropic.
The problem is that a vendor case study answers the question “does the solution work” – not the question “is this the optimal solution.” A company that built a chatbot on GigaChat and cut operator time by 40% is honestly describing a result. But it never ran an A/B test against Qwen 3.6 Flash – because no real company runs a full bake-off across every available model before each project.
That is exactly why independent benchmarks exist in the first place.
What our benchmark shows
We tested AI models across eight categories of managerial tasks – from data analysis and information retrieval to planning and team management. The methodology: two independent LLM judges calibrated against human ratings. For more on how benchmarks work and why you should trust them with caveats, see our earlier piece.
Sber currently runs two main lines: GigaChat 2 Max and GigaChat Ultra. Don’t confuse them – these are different models with different quality levels.
The flagship of the lineup is GigaChat Ultra. Its API is available to enterprise clients under a separate contract; individual developers only get the web interface at gigachat.ru. In our benchmark it placed 28 of 29 with a score of 4.83 – the best result among all Russian models in our test.
The main model with a public API is GigaChat 2 Max, and it’s the one most of the startups in the cases actually use. Place 29 of 29, score 4.20. In the first wave the same model scored 3.08 – significant progress in just a few months.
This distinction matters. Most startups in the cases work through the public API – that is, with GigaChat 2 Max. Those who secured enterprise access to Ultra are running a stronger model – but at a different price. Let’s see how GigaChat 2 Max specifically handles the tasks from the cases.
| Task category | GigaChat 2 Max | GigaChat Ultra |
|---|---|---|
| Information retrieval | 29 / 29 (3.87) | 28 / 29 (4.71) |
| Analysis and decisions | 29 / 29 (4.39) | 28 / 29 (5.44) |
| Planning | 29 / 29 (4.33) | 28 / 29 (5.92) |
| Problem solving | 28 / 29 (4.27) | 29 / 29 (4.25) |
| Regional awareness | 29 / 29 (3.57) | 28 / 29 (3.98) |
| Communication | 28 / 29 (4.74) | 29 / 29 (4.74) |
| Team management | 29 / 29 (4.41) | 28 / 29 (5.16) |
| Learning and development | 29 / 29 (4.00) | 28 / 29 (4.48) |
Both Sber models occupy the bottom two places in the benchmark, but the gap between them is noticeable: Ultra scores 5.92 on planning, Max 4.33. Ultra is API-accessible only to enterprise clients, while Max ships with a public API. Most startups in the cases work with Max.
Forty cases: what kind of tasks
I read all forty cards. The tasks cluster into a few directions.
Roughly a third are chatbots and inbound request handling. An insurance company automated customer query responses, a medical service built an appointment-booking assistant, a bank deployed a support helper. This is a real, workable task for any sufficiently strong LLM.
Another large group is text and document generation: marketing materials, real-estate listings, HR documentation. An HRTech company automated the creation of job descriptions, a PropTech startup wrote apartment listings, a MarTech platform produced ad copy for different segments.
Then we enter territory where the benchmark data starts raising questions. Document and data analysis – parsing resumes, medical records, classifying inbound requests. A few cases involve cybersecurity: threat analysis, incident classification, report generation. And separately, specialized vertical tasks like an AI assistant for HR interviews or recommendation systems for EdTech.
Where the benchmark contradicts the marketing
Let’s take three cases from different categories and look at them through the data.
One of the EdTech cases is automating the breakdown of clinical cases for training medical students. The task demands factual accuracy, correct source citations, and an absence of hallucinations.
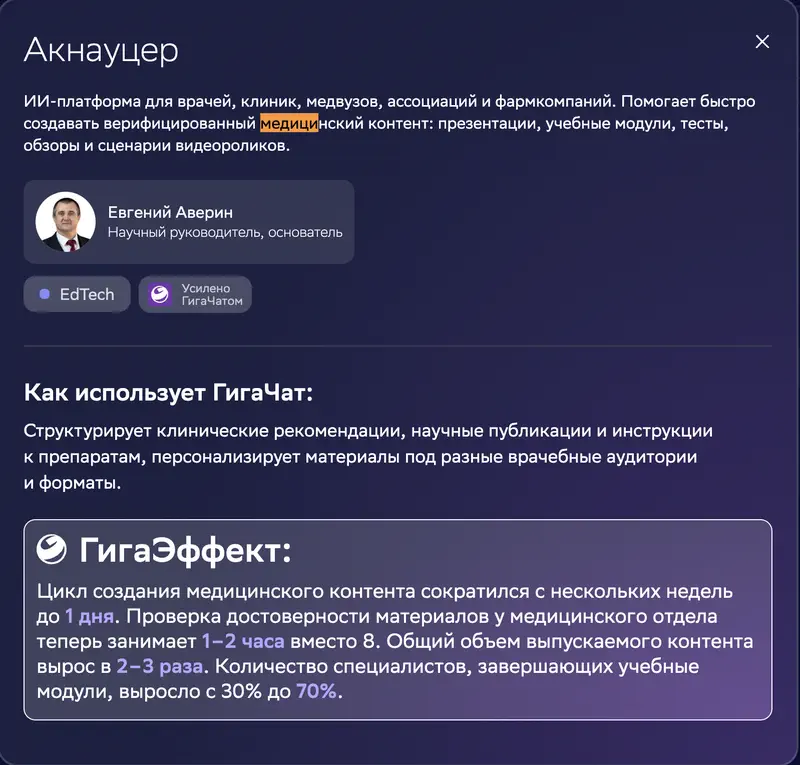
On the case card: Aknaucer, an AI platform for medicine. Claimed “GigaEffect”: content creation cut from several weeks to 1 day, fact-checking from 8 hours to 1–2, output up 2–3×, and the share of specialists completing training modules up from 30% to 70%.
Our benchmark for the “information retrieval” category: GigaChat 2 Max is last, 29th of 29. The specific weakness in the writeup: “finds the right direction of analysis, but invents tool prices, references to studies, and legal norms – using it without re-checking every fact is dangerous.”
The case is perfectly real. But a company that doesn’t re-verify every model output is running on the model that ranks last on accuracy out of 29 available.
Several MarTech companies describe automating the generation of marketing materials. Communication – 28th of 29, GigaChat’s least-weak category. For simple templated copy, that may be enough.
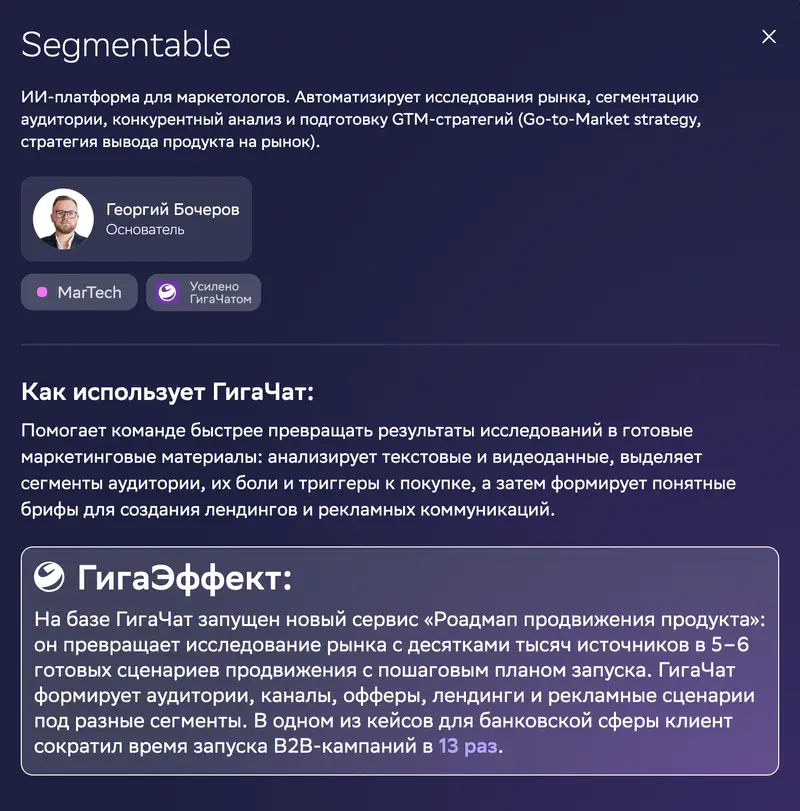
On the case card: Segmentable, an AI platform for marketers. Claimed “GigaEffect”: its “product promotion roadmap” service turns market research across tens of thousands of sources into 5–6 ready launch scenarios, and in one banking case the client cut B2B campaign launch time by 13×.
The cybersecurity situation is more interesting. One case is a system for classifying infosec incidents and generating threat reports. The task assumes precise analysis, concrete conclusions, actionable recommendations.
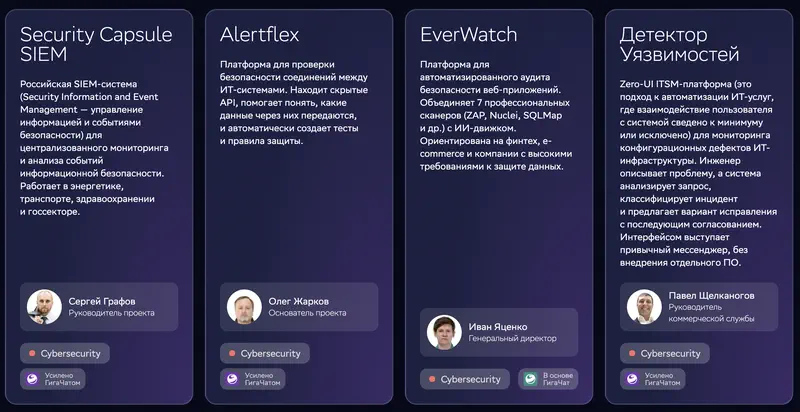
On the image: four GigaChat-powered cybersecurity products. Security Capsule SIEM – a Russian SIEM for centralized infosec monitoring; Alertflex – checks data exchange between IT systems via API and auto-generates protection rules; EverWatch – automated web-app audit combining 7 scanners (ZAP, Nuclei, SQLMap) with an AI engine; Vulnerability Detector – a Zero-UI ITSM platform where an engineer describes a problem in a messenger and the system classifies the incident and proposes a fix.
Our benchmark for “analysis and decisions” and “problem solving”: 29th and 28th of 29. The writeup: “correctly identifies the general direction of a solution, but provides no weighting criteria, no scenario analysis, and no concrete recommendations – it essentially restates the prompt.”
An incident-classification report written by the model ranked 29th on analytics out of 29 available – that’s automating document creation. The threat analysis still rests with a human. The difference is significant.
The paradox of absolute vs. competitive scoring
There’s a nuance here worth understanding, because it’s counterintuitive.
GigaChat 2 Max scores 4.20 out of 10 – below the middle of the scale. But even the absolute score poorly conveys real competitiveness. Our experiment with prompting techniques showed that even the best prompting techniques don’t close the gap between a weak and a strong model. GigaChat and Alice with optimal prompts still lost to GPT-5.4 and Claude using naive queries. The v2 release got stronger – but the principle holds: the absolute score overstates competitiveness.
We unpacked this effect in detail in our article Why AI Benchmarks Lie. Scores on the scale pile up near the mean, and a small gap in points corresponds to a large gap in win rate. When Qwen 3.6 Flash scores 7.60 in our benchmark against 4.20 for GigaChat 2 Max, this isn’t “80% better.” It means that in a head-to-head comparison, Qwen wins the overwhelming majority of the time.
That’s exactly why “works” and “optimal” are two different things.
Evaluating results on real tasks – knowing when an output is genuinely good versus when it merely looks good – is the focus of the course’s open module. Nine managerial scenarios, each with a non-obvious catch, no sign-up required.
None of Sber's 40 cases include an A/B test against alternative models. The open module gives you 9 tasks where you evaluate the results yourself and learn to tell 'works' from 'optimal'. Free.
No payment required • Get notified on launch
One case under the microscope: ESME AI and project documentation
The abstract benchmark scores don’t show what the difference between models actually looks like. One of the forty cases lets us see it – and, along the way, work out where the benchmark data applies directly and where it needs to be read with care.
ESME AI is a tool for developers and general contractors. A 360° site-capture platform with a built-in AI assistant. GigaChat helps work with design and construction documentation: the user asks in plain language, the assistant finds the information in drawings, specifications, and regulations. The claimed effect: “searching for project information dropped from tens of minutes to a few, and decision-making sped up by 30–50%.”
The task is real. Anyone who has worked on a site knows the pain: an average project runs into hundreds, sometimes thousands of sheets across disciplines (architectural, structural, HVAC, plumbing, electrical), plus specifications, quantity schedules, general notes, and a regulatory layer (codes, standards). A question like “what concrete grade does the design specify for the third-floor slab?” is ten-to-forty minutes of leafing through pages. Cutting that “from tens of minutes to a few” is plausible – if the search actually works.
Why the benchmark is a weak proxy here
Here we have to be honest with our own data. Our benchmark measures managerial reasoning: analyze a situation, plan, draw a conclusion. Documentation search works differently. It’s a RAG-class task (retrieval-augmented generation): the system first pulls the right fragment from the project’s actual PDF, and the model extracts the answer from it – not from the “memory” accumulated during training.
That changes the picture. GigaChat’s signature weakness – “invents references to studies and legal norms” – is a failure of generation from trained data. When the model answers strictly from an attached drawing fragment, that failure is suppressed. So the 29th place on “information retrieval” is a weak proxy for the question “will the assistant find the right concrete grade.” On a well-built RAG pipeline, even a weak model behaves more acceptably than it does in free-form generation.
What actually breaks this kind of automation
The problem is that for construction documentation, the main risks lie somewhere other than where the benchmark measures – and some of them are more dangerous than ordinary hallucinations.
The first thing that breaks a system like this in practice is reading the drawing itself. Drawings are vector PDFs or DWG files: text in title blocks, callouts, dimension chains, hatching, and embedded tables. General-purpose recognition systems stumble on this, and if the parsing went wrong, the model confidently answers from the corrupted text. Specifications and schedules are multi-page tables with merged cells, and most “wrong value” errors are born here, not in hallucinations.
Next: the answer rarely sits on a single sheet. “Concrete grade for the third-floor slab” is a chain: plan -> section -> specification -> general notes on the structural sheets, sometimes a separate sheet. To assemble the answer you have to traverse heterogeneous documents. This is exactly where the assistant quietly returns a plausible but wrong value.
There’s a less obvious risk too – versioning. Documentation is alive: revisions, change notices, “issued for construction” stamps, redlines. If a stale revision made it into the index, the assistant will confidently serve a cancelled value – with a citation to a real but outdated sheet. That’s more dangerous than a hallucination: it looks authoritative and verifiable.
Finally, the cost of error and citability. An engineer can’t act on the answer “B25” without a pointer to the volume, sheet, and specification line. An error in concrete grade or rebar class means a structural defect. And if the assistant doesn’t turn verification into a three-second glance at the source, the time savings evaporate: to trust the answer you’ll still have to find the source by hand.
Where the benchmark is relevant after all
The ESME task has two layers. The first is fact extraction: that’s about pipeline quality, see above. The second is analysis and synthesis: “assess the risks for this node,” “compare two solution options.” The difference between model classes is directly visible here, and the benchmark catches it.
We don’t have access to ESME AI’s specific prompts, but the analytical layer of such a task is exactly what we tested in our prompting-techniques experiment. Let’s take a comparable scenario – business analysis based on concrete data.
The task from the experiment:
An online electronics retailer, 45 employees. Over the last quarter revenue fell 18%, while website traffic rose 12%. Average order value dropped from $95 to $68. Returns climbed from 4% to 11%. The ad budget was increased by 30%. What’s going on and what should we do?
Every model received the same prompt, with no techniques applied.
GigaChat 2 Max (29th place, score 3.02) produced 53 lines of text. Six “possible causes,” six blocks of recommendations: “conduct a product quality analysis,” “improve logistics and delivery,” “upskill staff.” No concrete numbers from the prompt appear in the analysis. No prioritization. Bottom line: “a comprehensive approach to the problem is required.”
For ESME AI this means: on the analytical layer the model will say “you need to check the specification,” but it’s unlikely to set priorities and turn what it finds into a substantive conclusion.
Alice AI LLM (YandexGPT, score 3.85) did noticeably better: structure appeared – “ABC analysis of the assortment,” “price scrapers,” “usability test of the funnel,” a “short-term priorities for 2 weeks” block. But the prioritization is flat and there’s no laid-out crisis timeline.
GPT-5.4 (1st place, score 4.38) started differently – with a calculation: “average order value dropped by roughly 28%.” The model did the math rather than restating the prompt. Then: a 10-day crisis plan with roles for each of the 45 people, ranked hypotheses, and a list of “first thing tomorrow morning” actions.
Three tiers – three classes of output:
| Model | Computes the numbers? | Prioritizes hypotheses? | Gives an operational plan? | Factual accuracy |
|---|---|---|---|---|
| GigaChat 2 Max | No | No | Generic advice | 58.9% |
| Alice AI LLM | Partly | No | Priorities, but no timeline | 75.0% |
| GPT-5.4 | Yes (28% AOV drop) | Yes (by likelihood) | 10-day plan with roles | 83.9% |
The factual accuracy in the table comes from the business-analysis experiment, where the model generates the answer itself, with no attached documents. It doesn’t mean the ESME assistant will get 41% of drawing queries wrong: on grounded search with citations the picture is different. But the number shows the class. Where “document analysis” means not just finding a line but computing, prioritizing, and assembling a conclusion, GigaChat 2 Max stays at the level of generic advice.
In the head-to-head experiment, GigaChat 2 Max with the best prompting technique beat GPT-5.4 only in 4% of cases. Alice AI LLM – in 28–36%. At a 4% win rate, the gap is no longer about nuance, but about the class of tasks the model can solve.
Switching the model here is worth it: both Russian alternatives – Alice AI LLM and DeepSeek V4 Flash – are available in Yandex Cloud for Russian companies. DeepSeek V4 Flash sits 12th in our benchmark (7.34 points) and costs $0.20 / $0.60 per million tokens – 12 times cheaper than GigaChat at significantly higher quality. But honestly: switching the model fixes the analytical layer and reduces hallucinations, while the main construction risks – drawing parsing, versioning, citability – live in the pipeline, and no model will close them.
How to make an assistant like this reliable
If you’re building a product like this seriously, the order of priorities looks roughly like this.
The biggest reliability gain is structuring the data instead of searching across PDFs. Parse the specifications and schedules once into a human-verified database (element -> material -> grade -> sheet -> revision). Then “concrete grade for the third-floor slab” becomes a precise query against data rather than a fuzzy text search.
Every answer must carry a citation: volume, sheet, line – plus the shown drawing fragment. Verification becomes a glance, and only then are the time savings real.
Retrieval and generation should be separated. Fragment extraction runs on embeddings and a reranker; the model only finalizes the answer with a hard instruction: “answer strictly from context, otherwise say ’not found’.” This is what makes choosing a stronger model meaningful.
You need a versioning layer: the assistant answers “per revision such-and-such” and warns if a newer one exists for the sheet.
For critical queries – concrete grade, rebar, fire-resistance rating – the assistant must have the right to say “I don’t know”: either an exact citation or a refusal. “Not found” is a feature, not a bug.
ESME’s unique asset is pairing 360° capture with documentation. The step from “search the documents” to “compare the fact (360° capture) against the design” – deviations, percent complete, defects. That step is what closes the real site-control task and goes beyond just speeding up search.
And finally – test on your own documents. A hundred real queries with verified answers, measuring three metrics: retrieval completeness, citation accuracy, and the share of stale revisions. A general-purpose benchmark won’t tell ESME whether their pipeline is safe – only a test like this will.
If you have no choice: how to improve GigaChat’s output
Suppose you work in an organization where GigaChat is the only approved tool. On-premise, an enterprise contract, security requirements. What can you do?
Our prompting-techniques experiment tested ten approaches on GigaChat 2 Max – from role framing to XML markup and chain-of-thought.
The best result came from technique #4 – few-shot: an 89% win rate over the naive prompt. You take an example of a good answer to a similar (but different) task and add it to the prompt before your own question. The model calibrates against the example – and produces a structured, concrete answer instead of generic phrases.
On the same online-retailer task, GigaChat 2 Max with a few-shot example produced a different result: instead of listing six generic categories – a structured diagnosis with references to specific numbers from the prompt (“average order value drop from $95 to $68”), a timeline of recommendations (this week / 2–3 weeks / within a month), and a “What we don’t yet know” section.
GigaChat 2 Max data from the experiment:
| Technique | Score (out of 5) | Lift over baseline | Wins vs naive prompt |
|---|---|---|---|
| T0 (no techniques) | 3.02 | – | – |
| T4 (few-shot) | 3.63 | +20% | 89% |
| T2 (structured output) | 3.43 | +14% | 82% |
| T10 (XML + Markdown) | 3.59 | +19% | 78% |
| T3 (chain-of-thought) | 3.55 | +18% | 79% |
But here’s the important caveat: GigaChat 2 Max with the best technique (3.63) is still below Qwen 3.6 Flash (7.60) or DeepSeek V4 Pro (7.75) with no techniques at all. Prompt engineering doesn’t close the architectural gap – it makes a weak model tolerable, not competitive.
The remaining question is where to get the example. The most practical route: run the task once through a strong model (DeepSeek V4 Flash is free in its web interface, Kimi K2.6 is accessible without a VPN), save the result, and use it as an example for GigaChat on similar tasks. This isn’t “cheating” – it’s calibration.
Alternatives available in Russia
This is perhaps the most concrete part of the piece. If a company from one of Sber’s cases is solving tasks from our list, what other models are available to it – and what does the benchmark say? For a detailed tool-by-task comparison, see our review of GenAI tools for managers.
All the models listed below work without a VPN, are available via API, and are present on the Russian market.
| Model | Place (of 29) | Score | Price (in/out, $/M tokens) |
|---|---|---|---|
| MiMo v2.5 Pro | 3 | 8.37 | $1 / $3 |
| Kimi K2.6 | 5 | 8.27 | $0.74 / $3.49 |
| Qwen 3.6 Plus | 7 | 7.94 | $0.33 / $1.95 |
| MiMo v2.5 | 8 | 7.82 | $0.40 / $2 |
| DeepSeek V4 Pro | 10 | 7.75 | $0.43 / $0.87 |
| Qwen 3.6 Flash | 14 | 7.60 | $0.25 / $1.50 |
| MiniMax M2.7 | 15 | 7.58 | $0.30 / $1.20 |
| GigaChat 2 Max | 29 | 4.20 | $7.22 / $7.22 |
The cost difference matters, and we covered it in our analysis of the AI “premium tax”. GigaChat 2 Max costs $7.22 per million tokens both in and out. Qwen 3.6 Flash – $0.25 in and $1.50 out. If a company’s peak load is 10 million input tokens and as many output: GigaChat runs about $144, Qwen 3.6 Flash about $17.50. And Qwen ranks 14th against 29th.
Cheapness alone isn’t an argument. GigaChat has a genuine advantage – on-premise deployment. For banks, government bodies, and defense enterprises where data can’t leave the perimeter, it’s the only choice. We wrote about this in our practical guide to GigaChat. But for the cloud-based startups in the cases, that advantage is irrelevant.
Five questions for any AI vendor
This isn’t only about Sber. Microsoft publishes Copilot cases, Anthropic publishes Claude cases, Google publishes Gemini cases. The format is identical. The questions should be identical too.
Start with the simplest: which task exactly was automated – and does it fall within the model’s strengths? A chatbot for simple questions works on any model. Analyzing medical records or legal risk – not so much.
The second question is about metrics. “Cut time by 40%” sounds great. But 40% of what? If an operator spent 20 minutes per reply and now spends 12 – the saving is real. If the model produces a draft in 30 seconds but an editor spends 15 minutes fixing it – the efficiency is different. And what would things look like with no AI at all?
Was there a test against alternative models? Almost never. That’s understandable: a company is solving a business problem, not running comparative testing. But the absence of an A/B test means the phrase “GigaChat let us” is more accurately read as “with GigaChat we managed to” – without any claim that other models would have done worse.
A separate topic is verification. If the task requires accurate data (factual references, legal citations, medical conclusions) and there’s no systematic check of every output, that’s a risk. The question isn’t whether the model hallucinates sometimes. The question is how many errors slip through and what they cost.
And finally: what happens on the edge cases? Most AI products work well on typical queries. The interesting behavior is on the atypical ones – a rare region, a non-standard situation, a borderline legal case. This is exactly where the gap between 3rd and 29th place shows itself most.
Click “Run” and compare the answers. Pay attention to specificity: does the model name real infosec standards and metrics, or does it stop at generic phrases? This is exactly where the difference between 5th and 29th place in the benchmark shows up.
An honest admission: the progress is real
GigaChat 2 Max is in last place – but you have to read that as a trajectory. In the first wave of testing, the same line scored 3.08. Now it’s 4.20. A 36% gain over a few months is significant progress on quality, even if the ranking stays last.
Sber’s engineering effort is visible. If the pace holds, in a year or two GigaChat could land in the upper half of the table. That’s an open question, and it’s in the interest of Russian users for the answer to be yes.
The forty startups in the cases are also doing real work. GigaChat-based automation works for many of them. For some tasks – especially business correspondence and simple chatbots – it’s a reasonable choice. For others, the benchmark data raises the question of optimality.
It’s possible that some of them chose GigaChat for non-technical reasons: an existing enterprise contract with Sber, security requirements, pressure from leadership. Those are real considerations too, and the benchmark doesn’t account for them.
The question is different: when you make a technical decision about which model to choose – what do you check?
Telling “the model produced a plausible result” from “the model produced a correct result” is a skill you only build on concrete tasks. That’s exactly what the course’s open module trains: nine managerial scenarios where the gap between “sounds convincing” and “is correct” is non-obvious.
Forty cases with no A/B test is the norm for vendor marketing. In the open module you practice evaluating results on 9 managerial tasks. Free, no sign-up required.
No payment required • Get notified on launch
What to do with this information
If you use GigaChat – especially in an on-premise or Enterprise setup – this isn’t an argument to switch right now. There are tasks where the model works acceptably. There are situations where there’s no choice.
A useful move is to figure out which tasks you rely on GigaChat’s accuracy for, and what level of verification you have built in. Our detailed GigaChat review and our GigaChat Ultra Thinking test show concrete situations where the model errs most often: information retrieval, legal norms, regional data.
If you’re deciding which model to choose for a new project – the benchmark data and the five questions above give you a structure. The full ranking of 29 models, broken down by category, is on our research page.
If you’re reading the next vendor case study – whether from Sber, Microsoft, or Anthropic – ask the same five questions. The answers usually aren’t in the case text.
From case studies to your own judgment
The course's third chapter breaks down eight AI tools with data: what each one can do, where it hallucinates, which tasks it's optimal for. Test results on managerial tasks, not a rehash of the marketing.


Stanislav Belyaev
Engineering Leader at Microsoft18 years leading engineering teams. Founder of mysummit.school. 700+ graduates at Yandex Practicum and Stratoplan.