GigaChat Ultra Thinking: Thinks Longer – Answers Worse?

GigaChat Ultra Thinking takes longer to think and uses more compute. It solves management tasks 3.3% worse than the version without reasoning. This is not a bug or a fluke – it’s a pattern documented in academic papers over the past two years.
This week, Sber unveiled GigaChat Ultra – a new flagship model with a reasoning mode (Thinking). The model is available for free via web, mobile apps, and a Telegram bot. We immediately added both variants to our AI model research for managers: ran them through all 32 scenarios using our unified methodology, scored them with both LLM judges, and compared against the other 52 models.
Important caveat. At the time of testing, GigaChat Ultra was not available via API – only through the web chat. This means we could not control temperature, system prompt, or other parameters. We used the model exactly as a regular user would. Conditions were identical for Ultra and Ultra Thinking, but different from the other models in the study, which were tested via API.
Results: The Big Picture
GigaChat Ultra scored 3.04 out of 5.0 (average across 32 scenarios). GigaChat Ultra Thinking – 2.94.
The reasoning mode worsened the result by 0.10 points – minus 3.3%.
For context: the previous flagship GigaChat 2 Max scored 3.08. Ultra essentially stayed at the same level. With the reasoning mode – even slightly below.
| Model | Average Score | Median |
|---|---|---|
| GigaChat Ultra | 3.04 | 2.85 |
| GigaChat Ultra Thinking | 2.94 | 2.90 |
| GigaChat 2 Max (previous) | 3.08 | — |
The gap with the leaders remains significant. Kimi K2.5 – 4.74, Qwen3.5 Plus – 4.56, DeepSeek V3.2 – 4.42. GigaChat Ultra is 1.4–1.7 points behind.
By Category: Where Thinking Helps and Where It Hurts
We tested models across 8 categories of management tasks, with 4 scenarios in each. Here’s the breakdown.
Where Thinking Helped
| Category | Ultra | Thinking | Difference |
|---|---|---|---|
| Planning and Productivity | 3.11 | 3.83 | +0.72 |
| Problem Solving | 3.08 | 3.26 | +0.18 |
| Team Management | 2.81 | 2.95 | +0.14 |
The best Thinking result came in a stakeholder analysis task: Ultra scored 2.25 (incorrect sentiment classification, internal contradictions in the answer), while Thinking scored 4.00 (correct tone analysis, proper structure). A difference of 1.75 points on a single scenario.
The pattern: Thinking helps in tasks that require weighing multiple factors simultaneously – stakeholder positions, hiring risks, negotiation scenarios.
Where Thinking Hurt
| Category | Ultra | Thinking | Difference |
|---|---|---|---|
| Communication | 3.45 | 2.71 | −0.74 |
| Training and Development | 2.89 | 2.31 | −0.58 |
| Regional Specifics | 3.00 | 2.68 | −0.32 |
| Analysis and Decisions | 3.60 | 3.26 | −0.34 |
| Information Search | 2.48 | 2.48 | 0.00 |
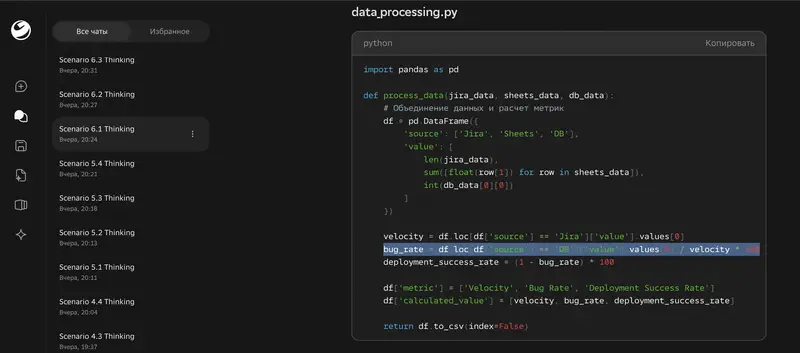
The worst Thinking result – generating a Python script for automation. Ultra scored 3.86, Thinking – 1.25. Minus 2.61 points. The Thinking version produced code with made-up metrics (“bug rate = deployments / velocity”) and critical syntax errors. The code was completely non-functional.
The second failure – revenue analysis. Ultra correctly identified patterns in the data and calculated $317.1K. Thinking “reasoned its way” to $236.7K – a hallucination in intermediate calculations.
A question worth asking: if the reasoning mode worsens results in five out of eight categories – what’s the value?
The Mechanism: Why “Thinking Longer” = “Answering Worse”
The GigaChat Ultra Thinking problem is not unique. Over the past two years, a series of studies have documented the same effect: extended thinking in language models doesn’t improve but worsens results for a significant share of tasks.
Incorrect Answers Contain Twice as Many “Thoughts”
A study (Do Thinking Tokens Help or Trap?, June 2025) analyzed DeepSeek-R1’s responses. The key finding: incorrect answers contain twice as many thinking tokens as correct ones. The model falls into a “reasoning trap” – tokens like “hmm,” “let’s wait,” “therefore” trigger re-checking cycles that lead away from the correct answer.
Suppressing the generation of thinking tokens led to “minimal degradation of reasoning quality across all difficulty levels.” In other words, you can remove most of the “deliberation” – and the result doesn’t suffer.
Short Reasoning Chains Are 34.5% More Accurate Than Long Ones
Hassid et al. (Don’t Overthink It, May 2025) showed that short reasoning chains are up to 34.5% more accurate than long ones – for the very same question. A simple technique – generating several short answers and picking the best one – uses up to 40% fewer thinking tokens while delivering better or comparable results.
More Tokens – Worse Results
A study by Google and the University of Virginia (Think Deep, Not Just Long, February 2026) found a negative correlation of −0.544 between the number of reasoning tokens and answer accuracy. They tested on GPT-OSS-20B/120B, DeepSeek-R1-70B, Qwen3-30B. The authors’ conclusion – “thinking deep” and “thinking long” are different things.
On the Omni-MATH benchmark, accuracy drops with more tokens across all tested models: from −0.81% to −3.16% per additional thousand tokens.
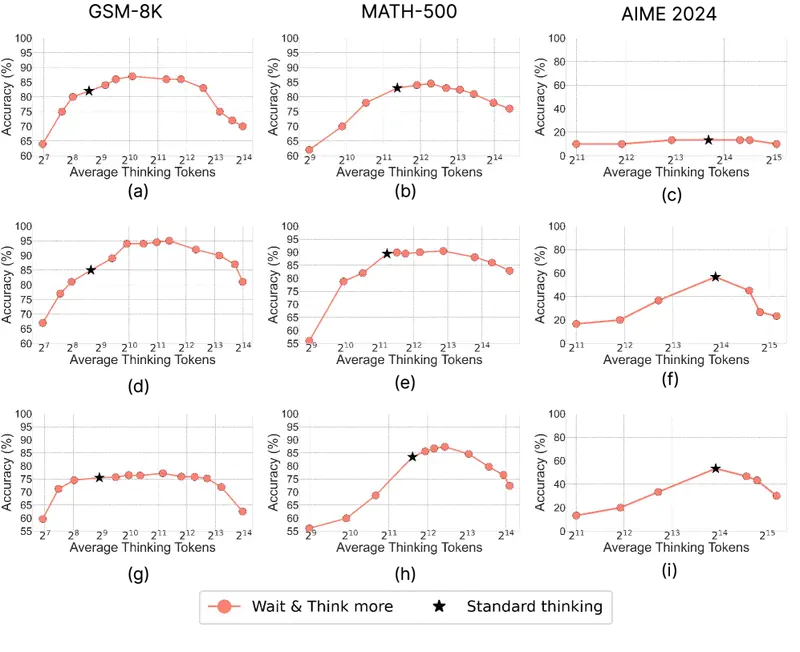
The Hump Curve: First Better, Then Worse
Does Thinking More Always Help? (June 2025) discovered a non-monotonic “hump” curve: on GSM-8K, accuracy first rises from 82.2% to 87.3% with moderate reasoning volume, then drops to 70.3% with excessive reasoning. Generating multiple short answers in parallel consistently outperforms a single long chain.
Apple: Reasoning Is Harmful for Simple Tasks
An Apple paper (The Illusion of Thinking, 2025) identified three regimes:
- Simple tasks – a regular model without reasoning works better than a reasoning model: faster and more accurate
- Medium tasks – the reasoning model gains an advantage
- Hard tasks – both models fail equally, regardless of reasoning volume
For management tasks – business correspondence, data analysis, code generation – this is directly relevant. Most such tasks fall into the “simple” and “medium” categories, where extended reasoning either hurts or provides minimal benefit.
Understand AI Systematically
Which tool for which task, how to spot hallucinations, how to work with reasoning models – we cover it all in the course program.
Overthinking as a Systemic Problem
A review of 170+ papers (Stop Overthinking, March 2025) documents “the overthinking problem” as a systemic property of reasoning models: even a trivial question like “2+3=?” can generate thousands of reasoning tokens with zero benefit. Models don’t know how to calibrate reasoning volume to task complexity.
How do you tell a task where AI will do fine from one where you need your own expertise? We break it down in the course program
10 уроков: встраиваете ИИ в планирование, отчётность и кризисное реагирование. Результат – не промпты, а рабочая система.
What This Means for GigaChat Ultra
Our data fits the pattern from the research precisely:
Thinking hurt where the task requires precise data. Revenue analysis, code generation, working with numbers – the model generates false intermediate steps that corrupt the final answer. This is the classic “reasoning trap” from Ding et al.
Thinking helped where you need to weigh multiple factors. Stakeholder analysis, negotiation prep, hiring risk assessment – tasks where additional reasoning steps structure the answer. This is the “medium complexity” regime from Apple.
The difference between categories is enormous. From +1.75 to −2.61 points on individual scenarios. The average (−0.10) hides the real picture – Thinking isn’t “slightly worse”; it’s radically better on some tasks and catastrophically worse on others.
Ranking Position
With a score of 3.04, GigaChat Ultra ranks 44th out of 54 models in the updated ranking. GigaChat Ultra Thinking – 48th.
For comparison with other Russian models:
| Model | Score | Rank |
|---|---|---|
| Alice AI LLM (Yandex) | 3.86 | 38 |
| YandexGPT Pro 5.1 | 3.13 | 43 |
| GigaChat Ultra | 3.04 | 44 |
| GigaChat-2-Max | 3.08 | 45 |
| GigaChat-Max-preview | 3.05 | 47 |
| GigaChat Ultra Thinking | 2.94 | 48 |
| GigaChat-Pro-preview | 2.90 | 49 |
The flagship update didn’t lead to noticeable progress. Ultra essentially reproduced GigaChat-2-Max’s result (3.08 vs. 3.04 – the difference is within margin of error).
Meanwhile, GigaChat’s API pricing remains among the highest: $7.22 per million tokens. DeepSeek V3.2 with a score of 4.42 costs $0.27 – 27x cheaper at 1.45x the performance.
Practical Takeaways
If you’re already using GigaChat Ultra:
Don’t enable the reasoning mode by default. Use it only for multi-factor tasks – position analysis, preparation for complex negotiations, risk assessment. For everything else – standard mode.
Don’t trust numbers in Thinking mode. Any calculations, data, code – double-check. The Thinking mode generates plausible but false intermediate steps.
If you’re choosing a model from scratch – Kimi K2.5, Qwen3.5 Plus, or DeepSeek V3.2 will deliver significantly better results at lower cost.
But the question is broader: why is Sber releasing a reasoning mode as a marketing advantage when six independent studies from 2025–2026 show the same thing – “thinking longer” and “thinking better” are not yet the same thing for language models?