Chat Z.AI (GLM-5) Review 2026: Pricing, Benchmarks & Agent Mode

AI models in this article
On February 6, 2026, an anonymous model called “Pony Alpha” appeared on OpenRouter – free, with zero details about its creators. The AI community immediately set about identifying it. Its coding abilities came remarkably close to Claude Opus 4.5. When asked “who are you?”, the model responded: “I am GLM.” But when prompted to write a web page describing itself – it wrote: “I am Claude, created by Anthropic.”
This was reproducible one hundred percent of the time. And that single fact frames everything you need to know about GLM-5 before we get to benchmarks and pricing.
Try It Yourself: GLM-5 vs GigaChat vs Claude
Before we dig into the history, the benchmarks and the pricing – run a prompt right here and compare three models on the same task: GLM-5 (Z.ai), GigaChat-2-Max (Sber) and Claude Sonnet 4.6 (Anthropic). These are three fundamentally different bets: the cheap Chinese challenger, the Russian “home” model with dense local-context knowledge, and the Western premium flagship.
Example 1. A tactful letter to a long-time supplier
This task probes tone, business etiquette and diplomatic phrasing all at once. GigaChat usually leans on more formal, local-register conventions, Claude tends to balance empathy with clarity, and GLM-5 is interesting as a check on how well a Chinese model handles Western-style business correspondence. Further down the article there’s a second prompt on an analytical task, where the strengths shuffle differently.
What Is GLM-5 and Who’s Behind It
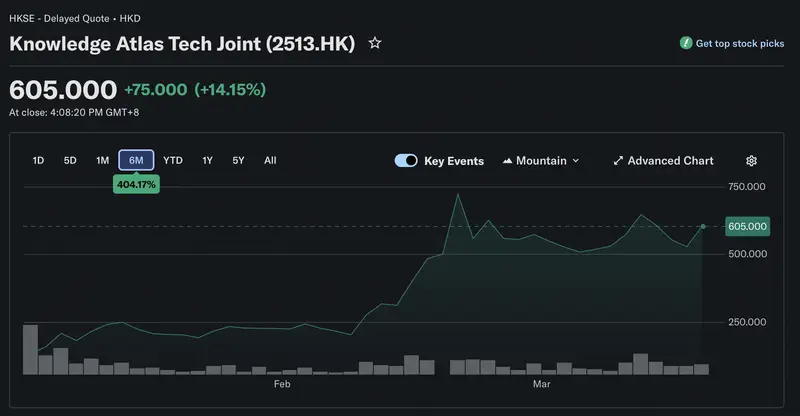
Zhipu AI – a spinoff from Tsinghua University, founded in 2019 – rebranded to Z.ai by 2025 and went public on the Hong Kong Stock Exchange in January 2026. The IPO was impressive: within three days of the official GLM-5 announcement, shares climbed 60%.
GLM-5 launched on February 11, 2026, and immediately staked its claim as the strongest open model in the world. Three things matter for a manager:
- The model is free and open – code is available under an MIT license, any company can download and run it on their own servers
- A single request can “read” up to ~400 pages of text – useful for working with long documents, reports, contracts
- Trained entirely on Chinese-made Huawei chips – without a single NVIDIA component
That last point isn’t just a technical detail. Under US export restrictions, it’s a political statement: China can build competitive AI models without access to Western chips. For business, it means the provider doesn’t depend on Western sanctions – unlike OpenAI or Anthropic.
GLM-5.2: A New Generation (June 13, 2026)
While GLM-5 was still being reviewed, Z.ai shipped the next version. GLM-5.2 launched on June 13, 2026, built for coding.
- 1M-token context (up from 200K in the prior version) – it holds a whole repository in memory without losing the thread.
- MoE architecture with 744B parameters, of which only 40B are active per token – hence the mix of power and a moderate price.
- Open weights under an MIT license and two reasoning levels, High and Max (Max is meant for complex multi-step work).
- Distributed through GLM Coding Plan tiers (from ~$18/mo), a standalone API, and a web chat.
In keeping with the whole GLM story, Z.ai published no benchmarks at launch – unusual for an industry where models ship with a ready-made table of wins. Independent tests appeared a few days later, and on code they are strong: on SWE-bench Pro GLM-5.2 scored 62.1% against 58.6% for GPT-5.5, took 2nd place among coding models on the blind Code Arena leaderboard, and came close to Claude Opus 4.8 on Terminal-Bench – at roughly one-sixth the cost of GPT-5.5.
That strength has a price in tokens. On Z.ai’s own agentic-coding chart, at the Max reasoning level GLM-5.2 nearly catches Opus 4.8, but it spends about twice the output tokens and still stays slightly behind at the peak. Cheaper per token – yet it burns more tokens.
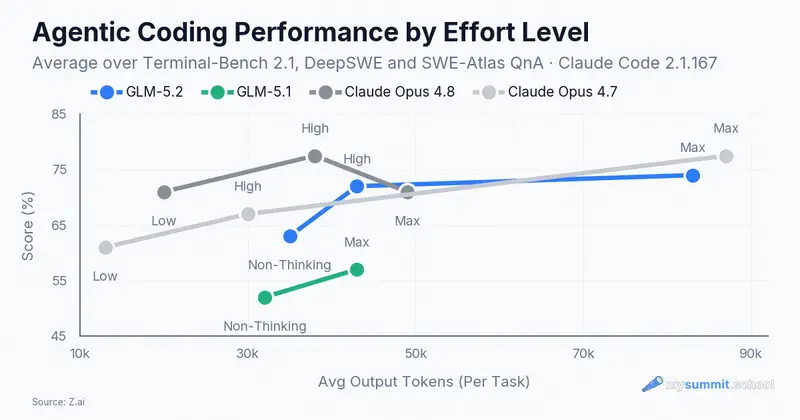
It’s also worth noting how GLM-5.2 plans. In our planning tests it settled the open questions itself and explained its choices, rather than leaving them for the builder. One example: it not only cached a lookup for a non-existent flag but also caught the non-obvious trap – that cache has to be cleared if the flag is created later. A plan’s value is measured by how many questions it resolves before work begins, and by that measure GLM-5.2 is strong.
For managers: GLM-5.2 is first and foremost a tool for development and engineering planning. On coding tasks and technical-design work it competes with the flagships at a noticeably lower price. How it behaves on broader business tasks is a separate discussion – below.
The Pony Alpha Story: A Detective Case Without a Resolution
“Pony” – a nod to the Year of the Horse in the Chinese calendar. On February 11, Zhipu officially confirmed: Pony Alpha is GLM-5. The company’s shares jumped 60% in three days.
As for what actually happened with the identity confusion – there’s been no official explanation. Zhipu never commented.
And it’s not an isolated case. In December 2025, MIT researchers documented that GLM-series models identified themselves as Claude roughly 50% of the time when queried through non-standard methods. DeepSeek V3 had a similar quirk – under certain prompts, it called itself ChatGPT or GPT-4. OpenAI directly accused DeepSeek of distilling from its models and updated its terms of service. Anthropic, Mistral, and xAI followed with similar anti-distillation clauses.
Distillation – training a smaller model on the outputs of a larger one – is, by all appearances, an open secret of the industry. Confirming its use in GLM-5 is impossible: we have no technical audit. Denying it is equally impossible: the behavioral patterns are too specific.
This raises a question worth sitting with: if the model “pretended” to be Claude under indirect queries – what exactly was it absorbing during training? And how much should a manager who needs a working tool actually care?
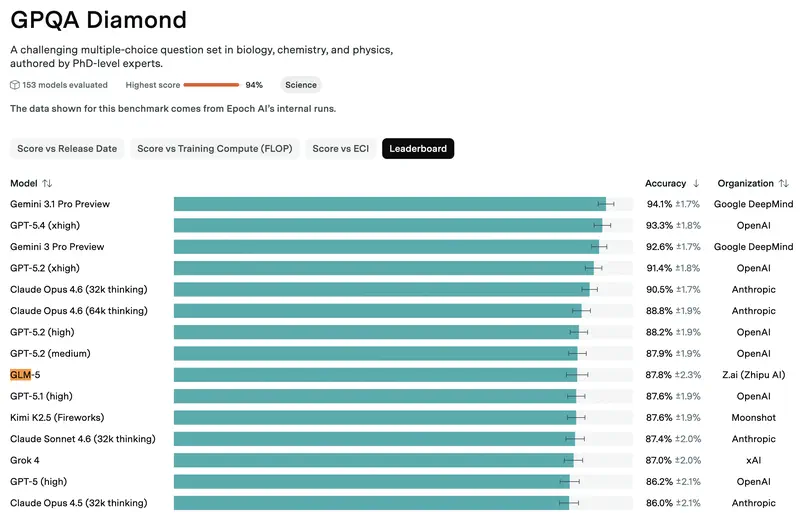
What the Benchmarks Show
On standard industry benchmarks, GLM-5 competes with the best closed models – and for a free, open model, that’s genuinely noteworthy. Here’s what matters for a manager:
Coding – solves 77.8% of real-world tasks from GitHub. For comparison: Claude Opus 4.5 – 80.9%, GPT-5.2 – 75.4%. The gap with the leaders is minimal.
Business simulation (Vending Bench 2 – a test where the model “runs a business” for a year) – GLM-5 finished with a balance of $4,432, Claude Opus 4.5 – $4,967. The model makes strategic decisions at roughly the same level as the best Western competitors.
Web search – first place among all models tested, including GPT-5.2 and Claude.
Hallucinations – the best result in the industry. GLM-5 is more likely to say “I don’t know” than to fabricate an answer. For work involving facts and figures, this is critically important.
As always, benchmarks and real-world performance are different things. But the direction is clear: GLM-5 plays in the same league as ChatGPT and Claude.
Benchmarks look convincing – but between “the model scores well on tests” and “the model reliably solves my problem” there’s a whole layer of skill: how you phrase the request, how you check the answer, how you avoid getting caught by a confident hallucination. That layer is what determines whether you get real value from GLM-5 – or just good-looking answers.
GLM-5 cuts hallucinations – but you'll still miss them without a systematic approach. 9 hands-on tasks in the free module show you exactly where.
No payment required • Get notified on launch
Our Benchmark Results
In our benchmark we test models on real managerial tasks across 8 categories – from planning and analysis to communication and team management.
GLM-5 lands in the upper-middle tier – a solid competitor that beats most mid-tier Western models, but falls short of leaders like Kimi K2.5 and MiniMax M2.7.
The eight-category profile reads clearly. GLM-5 is strongest in planning, analysis and team management, where it comes close to the leaders. It falls short where local context matters: training and development, and regional awareness (context on non-Western business practice and compliance is weaker than what dedicated regional models deliver for their home markets, the same way YandexGPT and GigaChat do for Russian business context). Information search and communication sit in the middle of the pack.
The takeaway for a manager is pragmatic: GLM-5 is a strong tool for planning and analytical tasks. If you’re decomposing a project, assessing risk, or analyzing data – the model performs well. If you need deep familiarity with a specific regional business context or need to build a training program – results will be weaker. And GLM-5’s biggest edge alongside its quality: it’s accessible from Russia without a VPN.
What about GLM-5.2? In our benchmark the new version runs neck-and-neck with the first on business tasks, yet costs noticeably less – and remains one of the most affordable models in its quality band (current rank, score and price are in the stat card under the GLM-5.2 heading above). For an open model of roughly 750B parameters that’s a notable result – the open-weight field in that range has been thin.
But a paradox surfaces. On pure coding tests GLM-5.2 is among the leaders, yet on business tasks tied to code, analysis, and marketing (which need strong English) it sags. The weakest area is “thinking” tasks: it systematically misses details in the text or draws unwarranted conclusions from it. It holds format cleanly, so it slots into other systems without surprises – but keep an eye on its conclusions. GLM-5.2’s strength is engineering reasoning – code, technical plans, decomposition – while “paper” reasoning, where you must catch subtle meaning in ordinary text, is weaker.
Detailed results across all categories are on the benchmark page.
Choosing between GLM-5, DeepSeek and Claude? The free module has 9 tasks that show you exactly where each model breaks. Test your approach for free.
No payment required • Get notified on launch
How to Use Chat Z.AI (GLM-5) Right Now
chat.z.ai – the official web interface, accessible from Russia without a VPN. Sign in with a Google account. The interface is in English and Chinese only, but the model understands and responds in many languages, including Russian.
Two modes of operation:
Chat Mode – the familiar dialogue format. Suitable for most tasks: writing text, analyzing documents, answering questions.
Agent Mode – where GLM-5 truly comes into its own. The model can use tools: generate files in .docx, .pdf, .xlsx formats, access web search, execute multi-step tasks. If you’re asking it to prepare a report with tables – this is the mode you want.
A practical recommendation on language: response quality in English is noticeably higher than in other languages. If the task allows – phrase your prompts in English, especially for complex analytical requests. It’s the same situation as with Qwen: Chinese models perform best on the languages they were trained on most heavily.
The week after GLM-5’s launch was turbulent: traffic grew 10x, the service was unstable for several days, and Zhipu issued a public apology. By mid-March the situation had stabilized, but it’s worth keeping in mind: this is a young service with rapidly growing demand.
Example 2. A pre-mortem before a product launch
The second task is analytical. This is traditionally Claude’s home turf, and for GLM-5 it’s an honest test: can a cheap Chinese model deliver structured thinking at flagship level? For GigaChat, it’s a chance to show how it handles a local market context.
Watch not just the content but the structure of each response: the ability to hold all the requirements of the prompt in mind at once (6–8 causes, categories, signals, actions) is precisely what separates a working tool from a good-looking demo.
Limitations and Risks
Chinese censorship works predictably: politically sensitive topics, historical criticism of the state, certain events – all blocked. For a manager, this rarely becomes a problem in practice, but it’s worth knowing.
Quality in the Russian language is one of GLM-5’s key weaknesses. Unlike DeepSeek, which handles Russian-language context significantly better, GLM-5 noticeably loses precision and nuance on Russian-language tasks. Our testing confirmed this.
Response speed in deep analysis mode is noticeably slower than Claude and GPT – roughly 30–40%. Not critical for one-off tasks, but noticeable during intensive work.
The distillation question remains open. This doesn’t mean the model is technically unreliable – it works. But for organizations that use Claude and care about the ethics of AI usage, this fact is worth considering.
Self-hosting is technically possible (the code is open), but requires server hardware costing several million rubles’ worth of equipment. Unlike the more compact Qwen models, GLM-5 isn’t something your IT department can spin up casually.
No mobile app – web only.
Pricing
| Option | Cost | For Whom |
|---|---|---|
| chat.z.ai | Free (with limits) | Try it with no commitment |
| API via OpenRouter | ~$0.15 for a 100-page report analysis | Integration into workflows |
For comparison: the same analysis via Claude Opus 4.5 would cost roughly $3, via GPT-5.2 – about $1.50. GLM-5 is 20 times cheaper with comparable capabilities on many tasks.
That said, among Chinese open models GLM-5 is the most expensive. DeepSeek and Qwen cost 3–5x less. What are you paying for? Strong results in planning and analysis – if those are your priorities, the premium is justified.
One caveat: after the GLM-5 launch, Zhipu raised prices on the Pro plan by roughly 30%, which drew user complaints.
Is It Worth Trying?
GLM-5 is a model with honest strengths and honest weaknesses, wrapped in a story that still hasn’t gotten a definitive answer.
Its strong results in planning and analysis are real and reproducible. If you’re decomposing a project, evaluating strategic decisions, or analyzing data – GLM-5 deserves a try. Being accessible from Russia without a VPN makes it one of the most convenient options among models of this caliber.
If you need a model for a specific regional business context, training your team, or tasks with strong local nuance – GLM-5 lags behind competitors here. For those purposes, DeepSeek or Claude will serve you better.
The Pony Alpha story and the Claude identity confusion – not a reason to dismiss the tool, but a reason to maintain analytical distance. The industry has long operated in a gray zone where the line between “inspiration” and “distillation” is blurred by design. This isn’t an exception for GLM-5 – it’s the general picture, and it’s worth keeping honestly in mind.
Access couldn’t be simpler: chat.z.ai works in Russia without a VPN, sign in with Google, and a free tier exists. It’s worth spending an hour testing – and forming your own opinion.
Start applying AI tools systematically
A full program: from prompt engineering basics to specializations in project management and analytics. Pick any model – GLM-5, Claude, DeepSeek – and test your approach on real managerial scenarios.









Stanislav Belyaev
Engineering Leader at Microsoft18 years leading engineering teams. Founder of mysummit.school. 700+ graduates at Yandex Practicum and Stratoplan.