How LLM Quality Is Evaluated in 2026: A Manager's Guide to AI Benchmarks
Imagine you’re choosing a company car for your team. One dealer says: “Our car is the fastest.” Another: “We have the best fuel economy.” A third: “We lead in safety.” They’re all right – but each is measuring something different. Without understanding what exactly is being measured and how, you can’t compare the options objectively.
With language models as of early 2026, the situation is even more complex. GPT-5.3, Claude 4.6, Gemini 3, Perplexity, DeepSeek V4 – every company claims to be the leader. But how does a manager figure out specifically how one tool is better than another for a business task?
That’s where benchmarks come in – standardised tests. By 2026, older tests (like MMLU) have become less useful, as all top models can pass them almost perfectly. Let’s break down which metrics are actually worth looking at today.
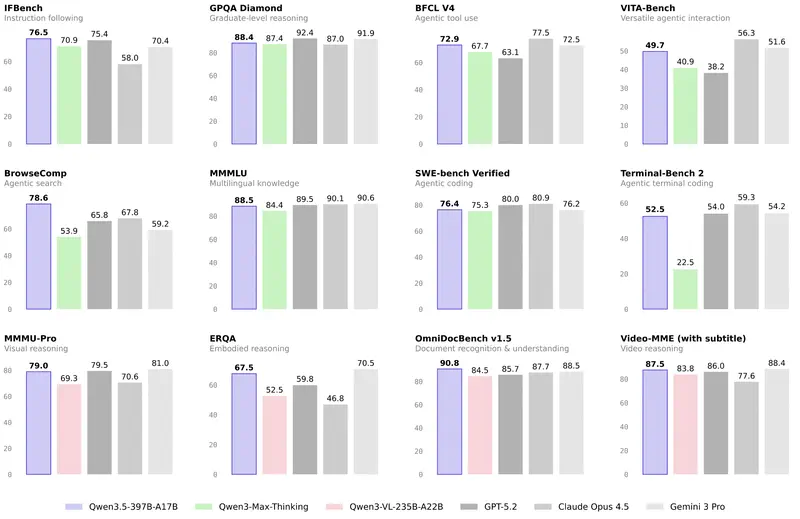
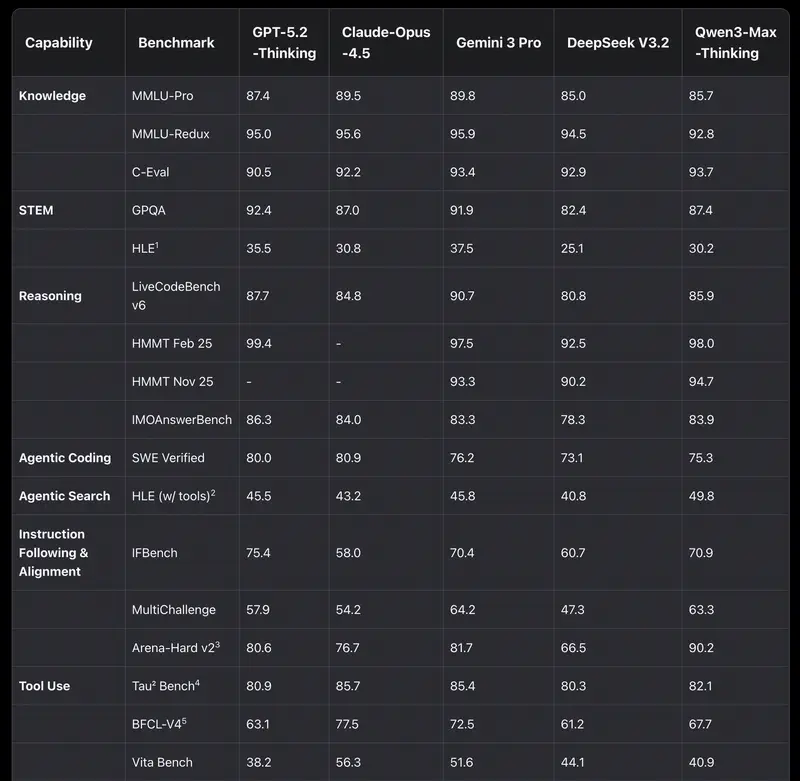
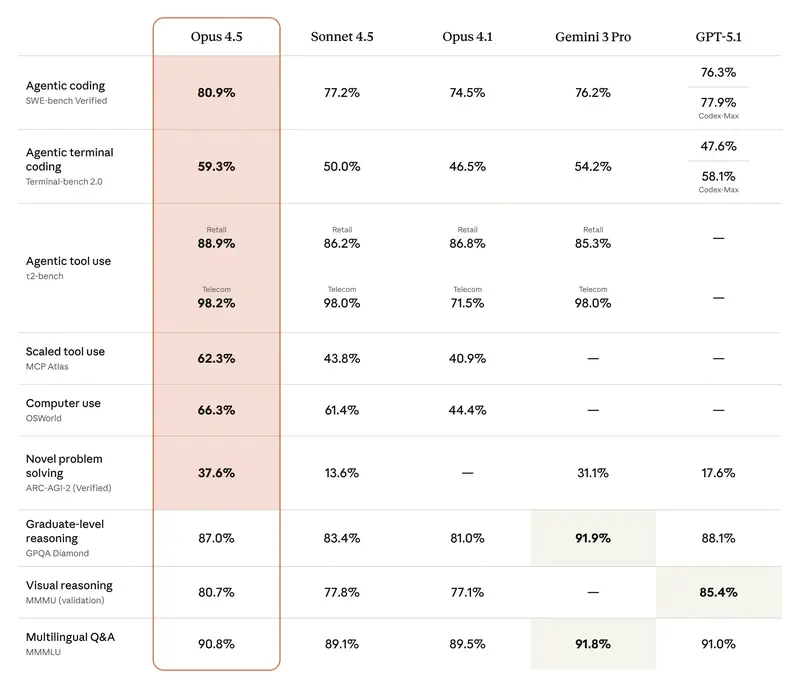
Intuition vs. data. Managers often have a “favourite” model. But intuition fails in edge cases. When you need to justify a budget or choose a model to automate an entire department – you need objective criteria.
Main evaluation types in 2026
Modern LLM evaluation is not a single number – it’s about understanding which “league” a model plays in.

Summary table of current categories
| Category | Key benchmark | What it means for a manager |
|---|---|---|
| Expert knowledge | GPQA Diamond | How competent the model is on PhD-level questions. Important for auditing and strategy. |
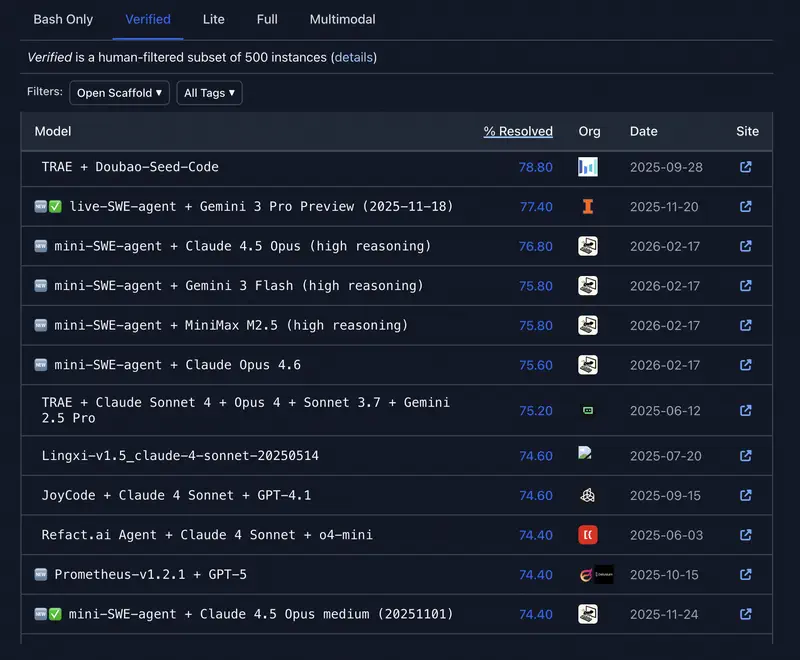
| Autonomous work | SWE-bench Verified | The model’s ability to independently solve tasks in code and repositories. A measure of “agency”. |
| Long context | RULER / Needle In A Haystack | Does the model lose information in a 1,000+ page document? |
| Deep reasoning | FrontierMath / AIME | Ability to reason in multiple steps without logical gaps. |
| People’s rating | Chatbot Arena (LMSYS) | How real users rate the model in anonymous blind tests. |
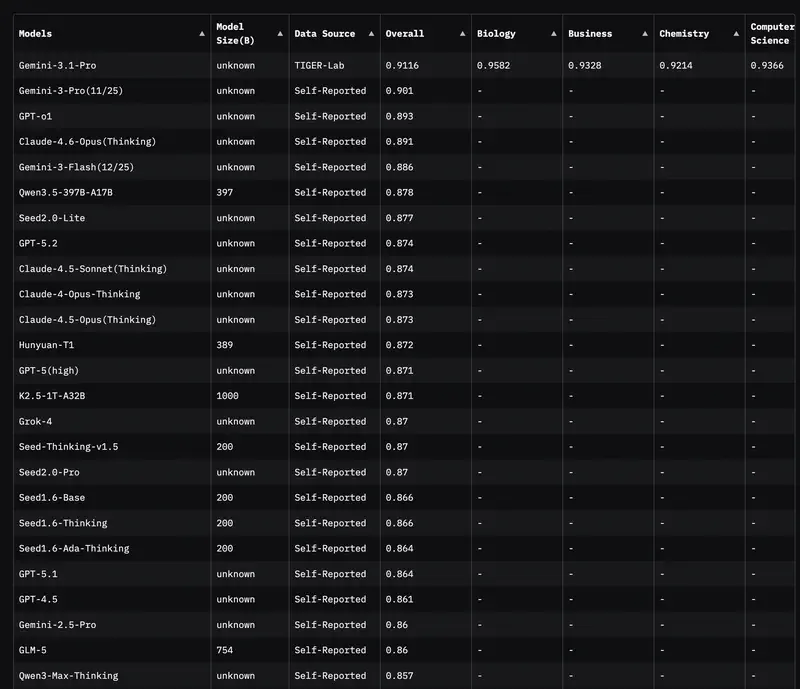
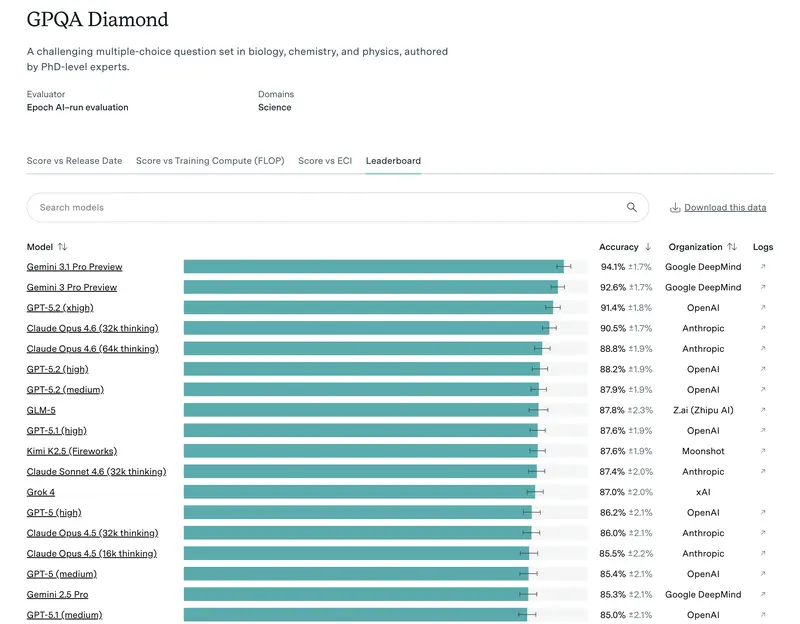
1. Academic breadth (MMLU and GPQA Diamond)
Everyone used to look at MMLU (tests across 57 disciplines). But in 2026, this test has become a “basic hygiene minimum.” If a model scores below 85–90%, it simply doesn’t belong in the top tier.
Today the gold standard is GPQA Diamond. These are questions so difficult that even human experts with internet access get them wrong 60% of the time. If a model scores 75%+ here, it means you can trust it to review the most complex legal or financial documents.
2. Agentic efficiency (SWE-bench and GAIA)
For managers, this is the most important metric in 2026. It measures not “eloquence” but the ability to get work done.
- SWE-bench Verified – shows how many real software bugs the model was able to find and fix on its own.
- GAIA – tests the model on tasks requiring browser use, file search, and tool usage.
3. User ratings: Chatbot Arena
The most authoritative “people’s” ranking. On the lmarena.ai platform, people blindly compare model responses.
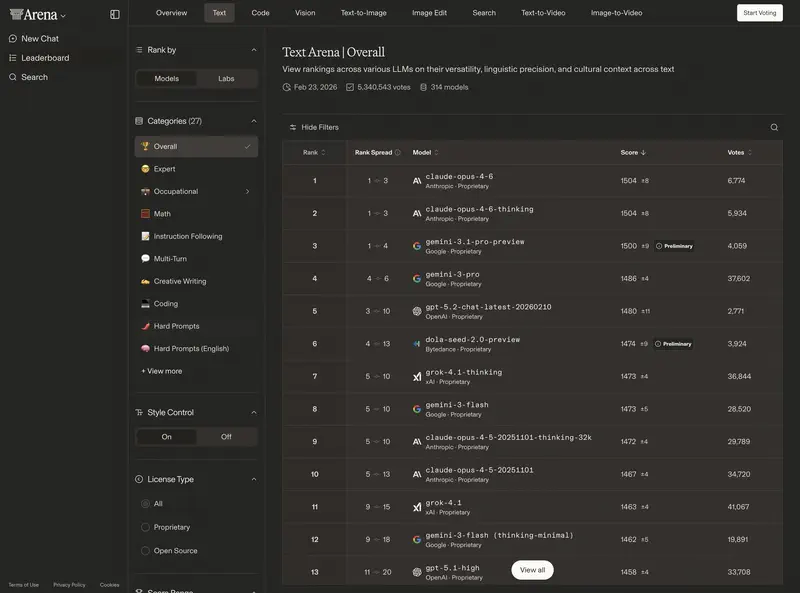
ELO rating 2026 (benchmarks):
- 1400–1500+: “superintelligent” models (GPT-5.3, Claude 4.6 Opus, Gemini 3 Ultra).
- 1300–1400: excellent workhorses (GPT-5-mini, Sonnet 4.6, DeepSeek V4).
- Below 1200: outdated or specialised models.
A difference of 30–50 ELO points is practically invisible in daily correspondence. A difference of 100+ points means a qualitative leap in intelligence and instruction-following.
4. Long context: RULER and the “lost in the middle” problem
2026 models claim context windows of 1–2 million tokens. But window size ≠ quality of work with that window. The RULER benchmark and Needle In A Haystack test check whether a model can find and correctly use information hidden in different parts of a long document.
By 2026, both tests have become more of a baseline. Top models have learned to locate individual facts in long text. But research from 2025 showed that a large context window does not guarantee reliable reasoning – a model may find the right fragment in isolation, but fail when it needs to integrate it with complex surrounding context. That’s why newer tests (RULERv2, Sequential-NIAH, MMNeedle) now check not just retrieval, but multi-step aggregation of information from different parts of a document.
The main trap is called Lost in the Middle – models confidently handle the beginning and end of a document, but hallucinate or miss facts from the middle. This is critical if you’re loading a 200-page contract or an annual report into the model.
Practical tip: After loading a long document, ask the model a question specifically about information from the middle of the text. If the answer is inaccurate or fabricated – the model can’t handle your data volume.
Evaluating “deep thinking” models (Reasoning)
With the arrival of models like o3 (OpenAI), R2 (DeepSeek), and Opus Thinking (Anthropic), a new evaluation problem emerged. These models can “think” about a response for anywhere from 10 seconds to 5 minutes.
How should a manager evaluate their quality?
- Output accuracy – if the task is strategic (e.g. calculating merger risks), wait time doesn’t matter – only correctness does.
- Transparency (CoT) – a good reasoning model should show its step-by-step process (Chain-of-Thought). This lets you audit its logic.
Practical guide: how to choose a model
Choosing an LLM for business in 2026 follows a three-step algorithm.
Step 1 – Define the role
What will the AI be doing 80% of the time?
| Role | Key metric |
|---|---|
| Strategist / Analyst | GPQA Diamond, FrontierMath |
| Digital employee (Agent) | SWE-bench, GAIA |
| Communicator (Emails, chats) | Chatbot Arena ELO (Overall) |
| Document auditor | Long Context Benchmarks (RULER) |
Step 2 – Check the benchmarks
Find 2–3 leaders in your chosen category. Don’t look at vendor marketing charts (they always pick tests where they come first) – use independent resources:
- LMSYS Chatbot Arena – for overall “human-likeness” and dialogue quality.
- Vectara Hallucination Leaderboard 2026 – if factual accuracy is critical for you.
- LiveCodeBench / SWE-bench Verified – if you’re selecting an AI programmer or agent.
Step 3 – “Test drive” on your own data
Take 5 of the most complex real-world cases from your work in the past week. Run them through the selected models. Evaluate not “beauty” but accuracy of conclusions and completeness of instruction-following.
The “teaching to the exam” trap. In 2026, “data contamination” is widespread – models are trained specifically on popular benchmark questions. That’s why your own private data is the best and only truly honest benchmark.
Offline assignment: go to Chatbot Arena, select the “Hard Prompts” category and look at the top 3 models. Those are your main candidates for tackling the most complex work tasks this quarter.
Useful links
- LMSYS Chatbot Arena
- GPQA Diamond
- SWE-bench Verified
- GAIA Benchmark
- Vectara Hallucination Leaderboard
- RULER (long context)
This article is part of the “GenAI Tools Review 2026” series. All tools are covered with hands-on exercises in the mysummit.school course.
