KazLLM and Sovereign AI: A Guide for Kazakhstan's Civil Servants

On 11 February 2026, at a government meeting, President Tokayev publicly criticised KazLLM. The model, launched with great fanfare in December 2024, has just 600,000 users – 3% of the country’s population. For comparison: 2.6 million people in Kazakhstan use ChatGPT. The president was blunt: KazLLM “cannot compete with ChatGPT.”
This statement cuts to the heart of the matter. Why does Kazakhstan need its own language model if global solutions work better? And if sovereign AI is necessary – why is it losing?
The answer is more complicated than it seems. Because KazLLM is not “Kazakhstan’s ChatGPT.” It’s a fundamentally different tool with a different mission. Comparing them is like comparing a national power plant with an imported household appliance.
Why a country needs its own language model
When a civil servant processes citizens’ requests through ChatGPT, three things happen simultaneously. Citizens’ personal data goes to OpenAI’s servers in the US. The context of the Kazakh language – agglutinative morphology, code-switching between Kazakh and Russian – is interpreted with losses. And the state controls neither the service’s availability, nor its cost, nor its data processing policy.
This is not a theoretical risk. When Italy blocked ChatGPT in 2023 over GDPR violations, government processes that depended on it ground to a halt. When OpenAI introduces restrictions for certain regions – the consequences are unpredictable. The question of accountability for decisions made with AI assistance extends far beyond technology.
A sovereign model solves this problem architecturally. Data never leaves the national infrastructure. The model is trained on Kazakh with regional dialects accounted for. And the state controls every element of the stack – from computing power to algorithms.
Kazakhstan is not alone in this. The UAE built Falcon, Japan – Fugaku-LLM, Taiwan – TAIDE, Singapore – SEA-LION. Each of these countries reached the same conclusion: dependence on someone else’s models is a strategic vulnerability.
What KazLLM actually is
KazLLM – officially ISSAI KAZ-LLM – was developed by the Institute of Smart Systems and Artificial Intelligence (ISSAI) at Nazarbayev University in collaboration with QazCode (a division of VEON/Beeline Kazakhstan). International support came from the Barcelona Supercomputing Centre and GSMA Foundry. In March 2025, the model received the GSMA Foundry Excellence Award and was presented at the Mobile World Congress in Barcelona.
Remarkably, despite this international recognition – 600,000 users versus 2.6 million for ChatGPT. The award is impressive, but the numbers tell a different story.
Technically, the model is built on Meta’s Llama 3.1 architecture – a proven open-source framework. The team didn’t build the architecture from scratch but adapted an existing one, retraining the neural weights to prioritise the Kazakh language. Two versions are available: a compact 8-billion parameter version for quick tasks and a full 70-billion parameter version for complex analysis. Both models are openly published on Hugging Face – you can download, test, and deploy them on your own infrastructure.
The key advantage is the data. A dedicated “Token Factory” team at ISSAI spent nine months collecting and curating a training corpus of over 150 billion tokens. Sources include Kazakh web resources, government archives, and academic literature. The model is trained on four languages – Kazakh, Russian, English, and Turkish – with support for code-switching, where a person switches between languages within a single sentence. This is what sets KazLLM apart from global models: a deep understanding of the region’s multilingual reality.
Why, then, is the comparison with ChatGPT misleading? Kazakhtelecom chairman Bagdat Musin framed it through an analogy: a foundational language model is a national power plant. It generates “intellectual energy.” ChatGPT and similar services are household appliances: useful, convenient, but plugged into someone else’s socket.
ISSAI itself published a detailed breakdown of the situation after Tokayev’s criticism. The scale of resources speaks for itself: to build Llama, Meta deployed over 16,000 NVIDIA DGX H100 nodes and more than 400 researchers. The ISSAI team worked with 8 DGX H100 nodes provided by a private telecom company.
At the same time, the institute acknowledges: “AI is a race. New models appear approximately every six months, and KazLLM needs to be developed further.” However, after the model was transferred to Astana Hub in December 2024, ISSAI “was not asked to continue its development.” The model was left without updates while competitors released new versions every quarter.
Alem LLM and the Alem.Cloud supercomputer
In parallel with KazLLM, the state deployed an infrastructure project of a different scale. Alem.Cloud is a national supercomputer and the most powerful computing cluster in Central Asia. Its specifications: 2 exaflops of performance (FP8), 512 NVIDIA H200 GPUs.
Acquiring these chips was itself a geopolitical manoeuvre – it required negotiations with the US to obtain export licences amid global restrictions on advanced GPU shipments.
Alem LLM is the second sovereign model running on this infrastructure. Like KazLLM, it is multilingual (Kazakh, Russian, English, Turkish) and designed for government services. The key difference is deep integration with the national computing resource: data is processed on Kazakhstan’s territory, on state-owned equipment.
Built on this infrastructure is the National Artificial Intelligence Platform – a secure environment where government developers and partner universities gain access to computing power, curated datasets, and pre-trained models. At the Davos forum in January 2026, partnerships were announced with NVIDIA, OpenAI, and Scale AI – covering supercomputing, educational infrastructure, and data preparation using RLHF.
AI agents for government: plans vs reality
Abstract models gain value when they turn into concrete tools. Kazakhstan announced the deployment of over ten specialised AI agents for government processes. But it’s important to distinguish plans from reality.
What is already operational:
- AI Therapist – the only agent with a confirmed pilot. Launched in 30 clinics in the Akmola region. It analyses doctor-patient conversations in real time, provides preliminary diagnoses with up to 80% accuracy, and reduces documentation time by up to 40%. Scaling to all medical facilities nationwide is planned.
What has been announced but is still in development:
- AlemGPT / eGov AI – an AI assistant for the government services portal. The Ministry of Digital Development is testing a prototype. By the end of 2026, the plan is to launch 50 AI agents serving ~7 million users.
- Tax Helper – a virtual tax consultant. Announced as part of the tax system digitalisation, but with no launch data available yet.
- QQazaq Law – a legal assistant for checking municipal regulations against legislation. Mentioned in strategic documents, but no evidence of actual deployment.
- e-Otinish AI – a system for processing petitions and citizens’ appeals. Described in conceptual materials, no launch data found.
This gives you pause. The gap between announcements and actual implementation is yet another facet of the problem Tokayev was pointing to. Infrastructure is being built, but the path from a model to a working product in a civil servant’s hands turns out to be longer than planned.
Agents are useless without quality data. The Smart Data Ukimet platform addresses this – by mid-2025 it connected 124 government information systems, supported 80 analytical use cases, and served over 8,500 civil servants. For a department head, this means shifting from reactive to predictive management – forecasting infrastructure failures and allocating resources based on algorithmic insights instead of putting out fires reactively.
Multimodal tools: beyond text
Kazakhstan’s sovereign AI ecosystem extends beyond text models. ISSAI has developed a range of multimodal tools – all available as demos on the institute’s website:
Oylan – a multimodal model (language + audio + video). Potentially applicable for media monitoring, video analysis, and transcription of government archives. The model is closed – unlike KazLLM, Oylan is not published on Hugging Face, and its architecture, according to ISSAI support, is “confidential.”
A curious detail: users in the Telegram community discovered that Oylan identifies itself as Qwen by Alibaba Cloud. ISSAI support called this a “widely known phenomenon in LLMs” – but the question about the model’s actual base went without a direct answer. Based on indirect evidence – multimodality (text + images + video) and version alignment – the base is most likely Qwen2.5-VL or a later variant from the Qwen family.
This is further confirmed by an academic publication: in a research paper by the ISSAI team, the Qolda model is described as built on Qwen3-4B integrated into the InternVL3.5 architecture – the Qwen family is clearly the foundation for the institute’s multimodal projects. Testing also revealed factual errors – the model confused the authorship of Abai’s works and used outdated geopolitical data.
MangiSoz – a speech recognition and synthesis engine with translation. Conceived as a tool for diplomatic correspondence and inter-agency communication in multilingual regions. And once again, a familiar story: during testing, the translation model revealed its identity – Google Gemma. This is not just circumstantial evidence: on ISSAI’s official website (May 2025), it explicitly states that the institute is “exploring potential collaboration with Google on fine-tuning the Gemma model for the Kazakh language.” Thus, at the core of MangiSoz is an open-source model from Google, fine-tuned for the Kazakh language.
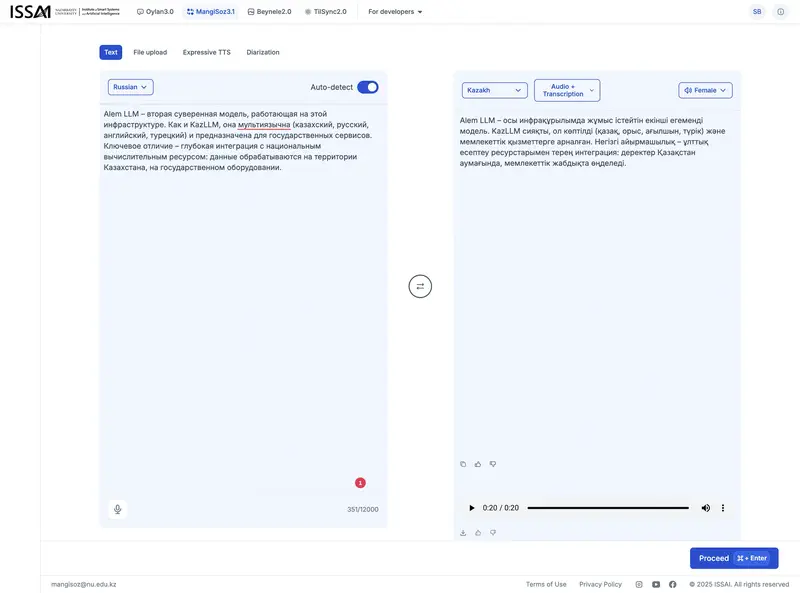
As an example, we translated a fragment of this article from Russian to Kazakh and generated audio output – in both male and female voices:
MangiSoz male voice
MangiSoz female voice
MangiSoz demo with translation between multiple languages:
In the community, real demand for MangiSoz is visible: users are requesting API access and on-premise deployment (without internet) – which is critically important for government agencies with air-gapped networks. According to support, a public API with separate services (TTS, STT, translation) is in the final stages of preparation.
- TilSync – a real-time subtitling system. Designed to provide accessibility for government broadcasts in Kazakh, Russian, and English.
- Beynele – an image generator trained on Central Asian visual culture. Allows creating visual content without dependence on Western generators.
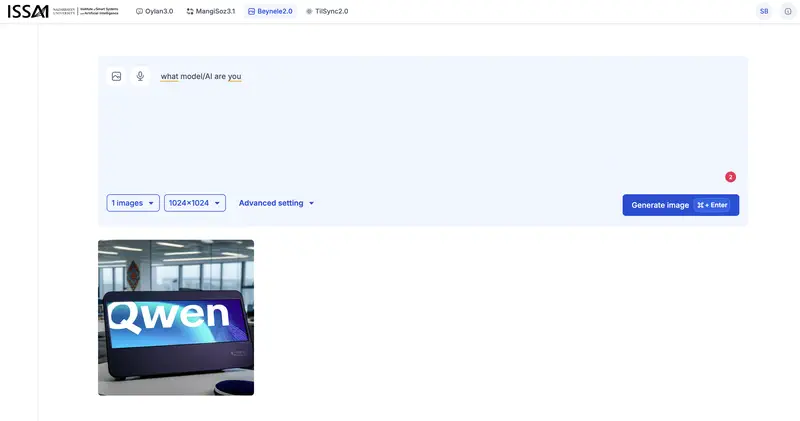
The same story as with Oylan: when asked “what model(AI) are you,” Beynele generated an image with the Qwen logo – a model by Alibaba Cloud. Qwen itself is a text model, not an image generator. But within the Alibaba Cloud ecosystem there is a text-to-image model called Tongyi Wanxiang (通义万相, Wan series), available through the same API. Most likely, Beynele is a fine-tuned Tongyi Wanxiang with Kazakh cultural specifics, operating under the shared Qwen/Tongyi brand.
ISSAI has a Telegram community where you can follow updates and ask the developers questions.
An important caveat: all four tools are at the research demo stage. No independent reviews or comparisons with analogues (Google Translate, Whisper, Midjourney) were found at the time of writing. In the Telegram community, users report technical issues – zero tokens on new accounts, unstable API performance. Support is responsive, but these are characteristic signs of an early-stage product. For a civil servant planning implementation, this means: worth testing, but don’t count on production-grade reliability just yet.
The Artificial Intelligence Act: a framework for everyone
On 18 January 2026, Kazakhstan’s Law on Artificial Intelligence (No. 230-VIII) came into force – the first comprehensive AI law in Central Asia. Signed on 17 November 2025, it was developed with coordination from 13 government bodies with the participation of sociologists, philosophers, and lawyers.
Key provisions of the law:
- A risk-level classification system for AI systems (similar to the EU AI Act).
- Transparency requirements for the use of AI in government decisions.
- AI-generated works are protected by copyright only when there is a creative human contribution (prompting, editing). A right to opt out of data use for training is provided.
- Explicit prohibitions on using AI for psychological manipulation of citizens.
For civil servants, this means: any agency-level AI deployment must undergo regular audits for compliance with ethical standards and citizens’ rights.
Problem number one: the skills gap
The infrastructure is there. The models are there. The law is there. AI agents are deployed. But Tokayev’s criticism points to the core problem – the gap between technology and its adoption.
600,000 KazLLM users versus 2.6 million ChatGPT users – this is not a verdict on the model’s quality. It is an indicator that people don’t know why and how to use sovereign tools. A model that is neither understood nor used is worthless – no matter how powerful it is. This is not Kazakhstan-specific – a similar gap has been documented worldwide.
The AI Qyzmet programme – mandatory AI certification for civil servants – is designed to close this gap. The AI Sana programme targets training 650,000 students. The Alem.ai centre in Astana plans to produce 10,000 AI specialists annually by 2029.
But the scale of the challenge is enormous. Educational programmes are only beginning to roll out, while civil servants are already working with ChatGPT today – using it for tasks where sovereign tools would be safer and more accurate. Research confirms: without systematic training, technology doesn’t take root.
This is worth reflecting on: the state is investing billions in technology that sits idle because users haven’t been trained to work with it.
What this means for civil servants
We tested Oylan, MangiSoz, and Beynele – and saw a familiar picture. The models work, but with caveats. Oylan confused the authorship of Abai’s works and named Biden as the sitting US president in late 2025. MangiSoz produces acceptable translations, but behind the facade is Google Gemma. As Anthropic’s research shows, AI systems don’t fail consistently – they fail chaotically – and this applies to any model, sovereign or global.
Sovereign AI is no longer the future. The platform, models, and agents exist. The question is not whether your agency will use AI, but whether you will manage the process – or whether it will happen spontaneously, through employees’ personal ChatGPT accounts. At the same time, global models aren’t going anywhere: ChatGPT, Claude, Gemini remain powerful tools for tasks that don’t involve citizens’ personal data.
Research shows that AI doesn’t reduce work – it intensifies it, creating new skill requirements. When AI Qyzmet becomes mandatory, civil servants with practical skills will be in a leadership position.
The main challenge of Kazakhstan’s sovereign AI is not technological. The state has built world-class infrastructure and has so far failed to convince its own officials to use it. 16,000 DGX H100 nodes at Meta, 8 nodes at ISSAI, zero updates after the model was handed off – and a president asking why it doesn’t work like ChatGPT. Perhaps the question should be framed differently: not “why is KazLLM worse than ChatGPT,” but “who exactly was supposed to be developing it after December 2024?”
Sovereign AI is being deployed. Those who know how to use it will be ahead
A course on generative AI for civil servants and managers: ChatGPT, Claude, prompting, critical evaluation – hands-on practice, no registration required.
Sources
All links and data are current as of February 2026. Kazakhstan’s sovereign AI ecosystem is actively evolving – we recommend verifying information for the latest updates.