Kimi K2.5 by Moonshot AI: The Open Chinese Model That Broke Into the Elite

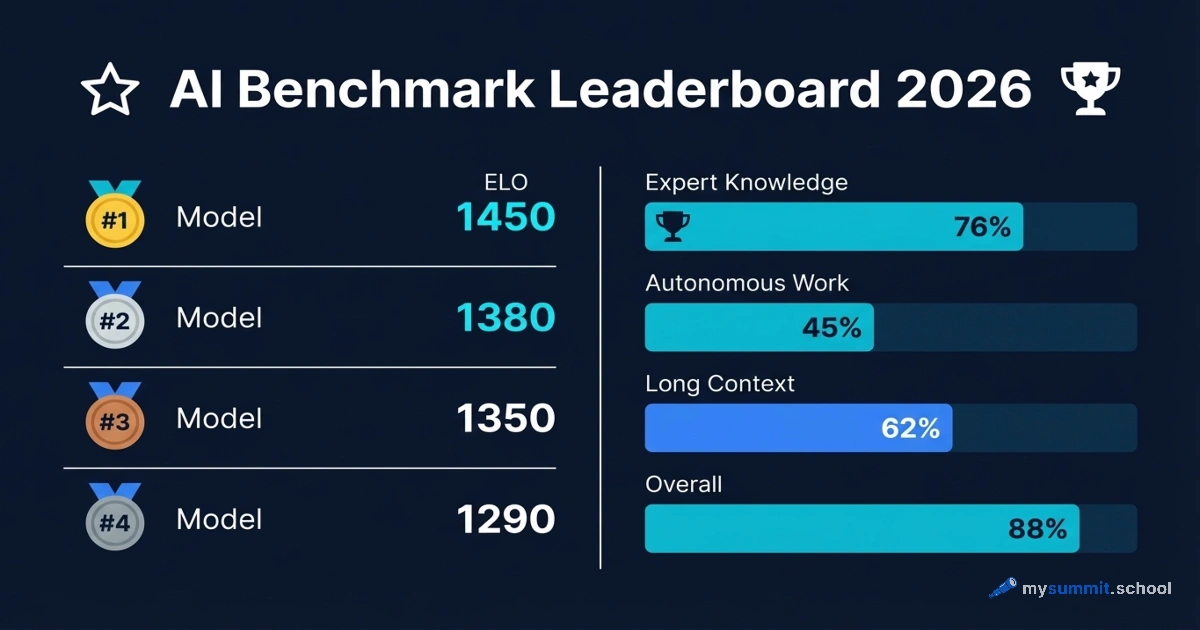
Can an open-source Chinese model compete with the closed flagships from OpenAI and Anthropic? Based on our independent testing – yes. On January 27, 2026, Beijing-based Moonshot AI released Kimi K2.5, and it immediately landed in fourth place globally. Above it – only Claude Opus 4.5, GPT-5.2, and Gemini 3 Pro. All three are closed and paid.
Kimi K2.5 is the first Chinese model to break into the elite cluster alongside the best Western competitors. And that alone makes it worth a closer look.
Who Is Moonshot AI
Moonshot AI is a Beijing startup founded in 2023 by former ByteDance employees (the company behind TikTok). It’s backed by Alibaba and HongShan (formerly Sequoia China). The founder and CEO is Zhilin Yang, an NLP researcher.
The startup bet on two things: long context and agentic capabilities. The first version of Kimi in 2024 attracted attention with a record-setting context window. K2.5 is the third generation, and here both directions converge.
What Kimi K2.5 Can Do
The model has 1 trillion parameters but uses a Mixture-of-Experts architecture: only 32 billion are active at any given moment. This allows it to combine power with efficiency – responses are fast, and API costs are several times lower than Claude or GPT.
Key specs:
- 256K token context window – roughly 350–500 pages of text per request
- Native multimodality – understands text, images, and video out of the box
- Four operating modes: Instant (quick answers), Thinking (deep analysis), Agent (autonomous tasks with tools), and Agent Swarm (parallel execution with up to 100 sub-agents)
- Open source – MIT license, weights available on HuggingFace
Agent Swarm: The Headline Feature
This is a fundamentally new approach. Instead of solving a task sequentially, Kimi K2.5 can split it into subtasks and launch up to 100 specialised sub-agents in parallel. Each sub-agent works independently while the main agent coordinates the result.
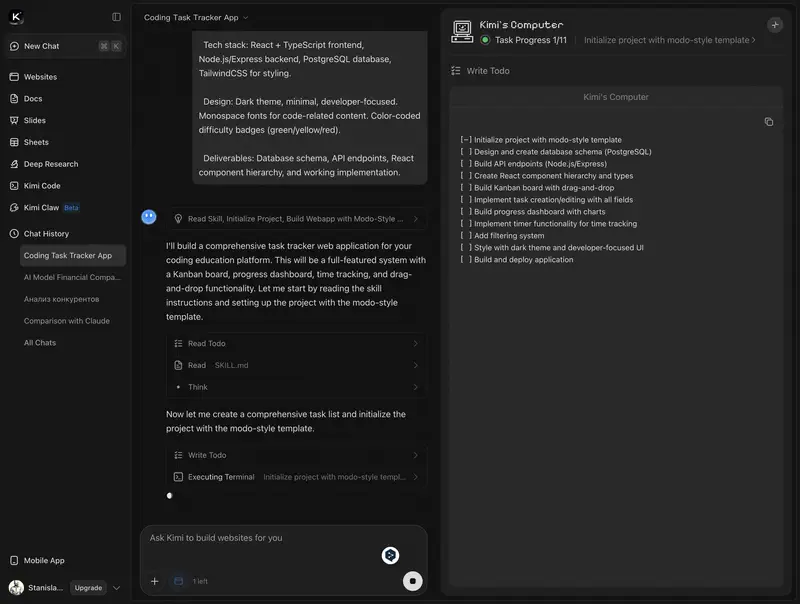
Why wait 10 minutes when you can split the task into 100 threads? In Swarm mode, Kimi K2.5 completes a complex analytical query in 2–3 minutes instead of 10. On the BrowseComp benchmark (web navigation and search), Agent Swarm scored 78.4% – the best result among all tested models, including GPT-5.2.
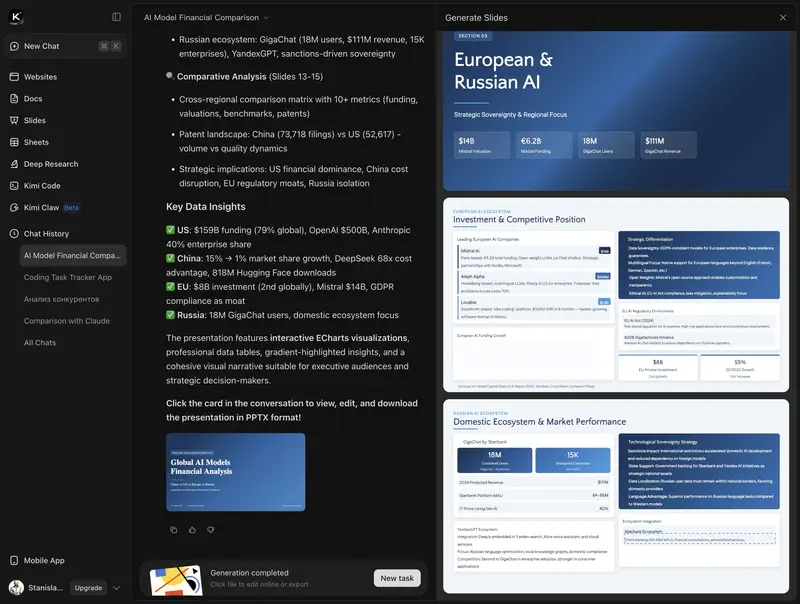
In terms of capabilities, Kimi can compete with Notebook LM from Google. The interactive presentations look quite solid at first glance – though the data is from last year.
For a manager, this is relevant in scenarios like “analyse 10 competitor websites and compile a summary” or “prepare a report based on multiple sources.”
What the Benchmarks Show
On standard industry benchmarks, Kimi K2.5 competes confidently with the best closed models:
| Benchmark | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | DeepSeek V3.2 |
|---|---|---|---|---|
| HLE with tools | 50.2% | 45.5% | 43.2% | 40.8% |
| BrowseComp (Agent Swarm) | 78.4% | 54.9% | 24.1% | 67.6% |
| SWE-Bench Verified (code) | 76.8% | 80.0% | 80.9% | 73.1% |
| AIME 2025 (maths) | 96.1% | 100.0% | 92.8% | 93.1% |
| VideoMMMU (video) | 86.6% | 85.9% | 84.4% | – |
Kimi K2.5 leads in agentic tasks (search, navigation, autonomous operation) and video comprehension. It trails Claude in coding and GPT-5.2 in maths. But these are gaps of 3–4 percentage points, not a chasm.
As always, benchmarks and real-world performance are different things. But the direction is clear: Kimi K2.5 is playing in the same league as the flagships.
How Kimi K2.5 Performed in Our Testing
In our comparison of 34 models on real management tasks, Kimi K2.5 earned 4th place with a score of 4.74 out of 5.0 – and became the only Chinese model in the elite cluster.
For context: the elite cluster contains just three other models besides Kimi – Claude Opus 4.5 (4.81), Claude Sonnet 4.5 (4.78), and GPT-5.2 (4.76). Kimi K2.5 earned its place among them.
Where Kimi K2.5 is especially strong:
- Information search – 2nd among all models (4.643)
- Learning and development – 4th place (4.720)
- Communication – 4th place (4.653)
- Analysis and decision-making – 4th place (4.779)
And the most notable thing – consistency. Kimi K2.5 showed the lowest variance in scores across categories: the gap between best and worst results is just 0.13 points. For most models, that spread is 2–3 times wider. This means Kimi K2.5 is equally reliable regardless of task type.
Kimi K2.5 vs Other Chinese Models
For a manager choosing between available tools, the comparison within the ‘Chinese group’ matters more than an abstract race against Claude.
| Model | Our score | Rank | Key strength | Chat access | Cost |
|---|---|---|---|---|---|
| Kimi K2.5 | 4.74 | #4 | Versatility, search | kimi.com | Free / $19–199/mo |
| Qwen3.5 Plus | 4.56 | #8 | Planning | chat.qwen.ai | Free (API only) |
| Qwen3.5 397B | 4.55 | #9 | Analysis & decisions | chat.qwen.ai | Free (API only) |
| GLM-5 (Z.ai) | 4.50 | #10 | Team management (#1) | chat.z.ai | Free (API only) |
| DeepSeek V3.2 | 4.42 | #13 | Cost efficiency | chat.deepseek.com | Free (API only) |
| Qwen3 Max | 4.42 | #14 | Reasoning | chat.qwen.ai | Free (API only) |
| DeepSeek R1 | 4.33 | #17 | Analytics | chat.deepseek.com | Free (API only) |
Takeaways from the table:
Kimi K2.5 is the best Chinese AI overall. The gap from the nearest competitor (Qwen3.5 Plus) is 0.18 points – that’s significant when the general level is above 4.5.
But it’s not the best in every category. GLM-5 remains #1 in team management. DeepSeek V3.2 offers the lowest cost per token. Qwen3.5 Plus is stronger in planning.
On accessibility, Kimi stands out. It’s the only model in the global top 4 with a free chat interface. DeepSeek and GLM-5 are also free, but trail in quality. Kimi’s paid plans ($19–199/mo) unlock agentic capabilities that competitors simply don’t offer in a chat interface.
How to Access Kimi K2.5
Web Interface: kimi.com
The website kimi.com is accessible globally. Sign in with a Google account – it takes about 10 seconds.
The interface is available in English and Chinese. The model understands and responds in many languages, though quality is noticeably higher in English and Chinese than in other languages – a pattern common to all Chinese models.
Three main modes of operation:
- Instant – quick answers for everyday tasks: drafting messages, answering questions, working with documents
- Thinking – deep analysis with chain-of-thought reasoning, the model shows its thinking process
- Agent – autonomous task execution: document generation (.docx, .pdf, .xlsx), web search, multi-step operations. If you’re asking it to prepare a report with tables – this is the mode
Mobile Apps
Kimi is available for iOS and Android. The functionality mirrors the web version, including all operating modes.
Pricing
Free Tier (Adagio)
- Unlimited text queries in Instant and Thinking modes
- Up to 3 agent requests per month (documents, spreadsheets, presentations)
- 1 Deep Research request per month
- Queue during peak hours
The free tier is enough to test the model and determine whether it suits your tasks. For daily work – it won’t be sufficient.
Paid Plans
| Plan | Price | What You Get |
|---|---|---|
| Moderato | $19/mo | More agent requests, priority, presentation generation |
| Allegretto | $39/mo | Higher limits, multi-agent tasking, access to Kimi Claw |
| Vivace | $199/mo | Unlimited agents, maximum speed, extended context |
API Pricing
| Option | Input tokens | Output tokens | ~Cost of analysing a 100-page report |
|---|---|---|---|
| Moonshot API (direct) | $0.60 / 1M | $3.00 / 1M | ~$0.50 |
| OpenRouter | $0.45 / 1M | $2.20 / 1M | ~$0.35 |
For comparison: Claude Opus 4.5 for a similar task costs around $3, GPT-5.2 – $1.50. Kimi K2.5 is 6–8x cheaper than Claude.
But among Chinese models, Kimi isn’t the most budget-friendly. DeepSeek V3.2 costs 3x less, Qwen3.5 Plus – 1.5x less.
Limitations and Risks
Non-English languages – a predictable weakness. Like GLM-5, Kimi K2.5 performs noticeably better in English and Chinese. In other languages, the model manages but loses nuance. If your task allows it – write your prompts in English.
Response speed – Agent Swarm is fast for complex tasks, but the standard Thinking mode is slower than Claude and GPT. In an independent test, Kimi K2.5’s median response time was 29.2 seconds versus 4.6 for Claude Sonnet 4.6. This raises a question: if Agent Swarm promises speed through parallelism, why is the standard mode 6x slower than competitors? For one-off queries it’s tolerable; for intensive work – it’s noticeable.
Chinese censorship works the same way as with other Chinese models: politically sensitive topics are blocked. For management tasks, this rarely becomes an issue.
Model size – 1 trillion parameters means running Kimi K2.5 on your own servers is unrealistic for a typical company. This isn’t Qwen3.5 9B, which you can deploy on a single GPU.
Should You Try It?
Kimi K2.5 is objectively the strongest Chinese AI model as of March 2026. Fourth place globally, elite cluster placement, the unique Agent Swarm technology – this isn’t marketing, it’s the result of independent testing.
For a manager, the recommendation depends on context. If you need a versatile tool with strong search, analysis, and agentic capabilities – Kimi K2.5 is worth trying. Especially if your tasks involve working with multiple sources, preparing reports, or multi-step research.
If cost is the primary concern – DeepSeek V3.2 remains the best value. It costs 3x less and delivers solid performance across most categories. If your focus is team management, HR tasks, and feedback – GLM-5 is still #1 in that category.
The surprising thing is that the strongest Chinese model of March 2026 isn’t the one that got the most press at the start of the year. Kimi K2.5 surpassed both DeepSeek and Qwen without loud proclamations. Which raises a question worth sitting with: how reliable is media hype as a guide when choosing a working tool?
Head to kimi.com, sign in with Google, and spend an hour testing. The free tier is enough to form your own opinion.
We analyse Kimi K2.5 and other AI tools in practice
9 diagnostic lessons: try applying Kimi K2.5 and other models to real tasks – and discover what mistakes most managers make. No registration required.
Continue learning
Open the textbook and pick up where you left off