Kimi by Moonshot in 2026: K2.6, K2.7-Code and Agents for Managers

Can an open-source Chinese model compete with the closed flagships from OpenAI and Anthropic? Based on our independent testing – yes. Kimi by Moonshot AI was the first Chinese model to join the elite group of the world’s best, competing directly with GPT-5.4 and Claude Sonnet 4.5 – and it stays free for basic use.
Over 2026, Kimi grew from a single model into a family: the flagship K2.6 for everyday work, the specialised K2.7-Code for development, and the desktop agent Kimi Work that runs tasks right on your machine. Below: what that gives a manager, our benchmark results, and how to get started.
Who Is Moonshot AI
Moonshot AI is a Beijing startup founded in 2023 by former ByteDance employees (the company behind TikTok). It’s backed by Alibaba and HongShan (formerly Sequoia China). The founder and CEO is Zhilin Yang, an NLP researcher.
The startup bet on two things: long context and agentic capabilities. The first version of Kimi in 2024 attracted attention with a record-setting context window. In early 2026 K2.5 carried both directions into the elite tier, and by summer it was succeeded by K2.6 and the coding-focused K2.7-Code.
What Kimi Can Do
All Kimi models are built on a Mixture-of-Experts architecture: 1 trillion parameters, but only 32 billion active at any given moment. This combines power with efficiency – responses are fast, and API costs are several times lower than Claude or GPT.
Key specs:
- 256K token context window – roughly 350–500 pages of text per request
- Native multimodality – understands text, images, and video out of the box
- Four operating modes: Instant (quick answers), Thinking (deep analysis), Agent (autonomous tasks with tools), and Agent Swarm (parallel sub-agents – up to 100 in K2.5 and 300 in K2.6)
- Open source – MIT license, weights available on HuggingFace
Agent Swarm: The Headline Feature
This is a fundamentally new approach. Instead of solving a task sequentially, Kimi can split it into subtasks and launch dozens or hundreds of specialised sub-agents in parallel (up to 300 in K2.6, coordinating as many as 4,000 steps). Each sub-agent works independently while the main agent coordinates the result.
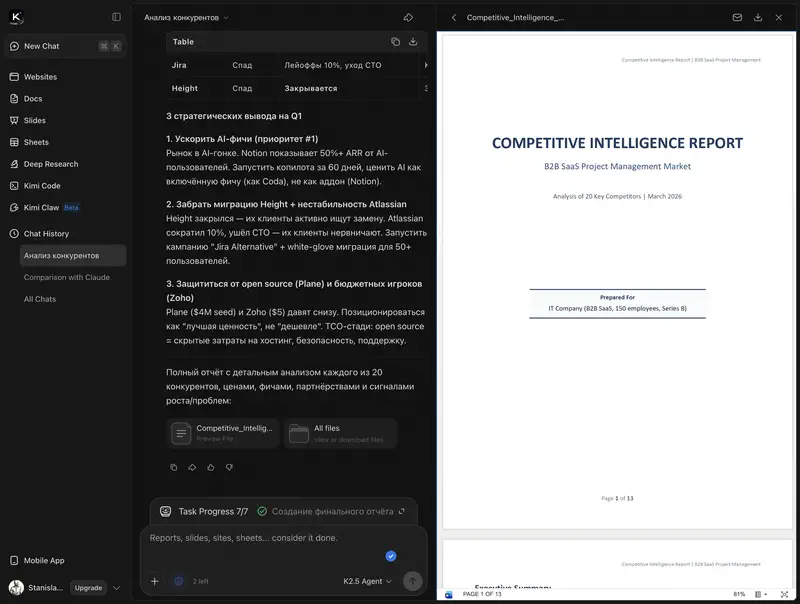
Why wait 10 minutes when you can split the task into 100 threads? In Swarm mode, Kimi K2.5 completes a complex analytical query in 2–3 minutes instead of 10. On the BrowseComp benchmark (web navigation and search), Agent Swarm scored 78.4% – the best result among all tested models, including GPT-5.2.
In terms of capabilities, Kimi can compete with Notebook LM from Google. The interactive presentations look quite solid at first glance – though the data is from last year.
For a manager, this is relevant in scenarios like “analyse 10 competitor websites and compile a summary” or “prepare a report based on multiple sources.”
What the Benchmarks Show
On standard industry benchmarks, Kimi K2.5 competes confidently with the best closed models:
| Benchmark | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | DeepSeek V3.2 |
|---|---|---|---|---|
| HLE with tools | 50.2% | 45.5% | 43.2% | 40.8% |
| BrowseComp (Agent Swarm) | 78.4% | 54.9% | 24.1% | 67.6% |
| SWE-Bench Verified (code) | 76.8% | 80.0% | 80.9% | 73.1% |
| AIME 2025 (maths) | 96.1% | 100.0% | 92.8% | 93.1% |
| VideoMMMU (video) | 86.6% | 85.9% | 84.4% | – |
Kimi K2.5 leads in agentic tasks (search, navigation, autonomous operation) and video comprehension. It trails Claude in coding and GPT-5.2 in maths. But these are gaps of 3–4 percentage points, not a chasm.
As always, benchmarks and real-world performance are different things. But the direction is clear: Kimi K2.5 is playing in the same league as the flagships.
Kimi model lineup: K2.5, K2.6 and K2.7-Code
Today the Kimi line is three models. The original K2.5 gave way to the incremental K2.6 (the one now in Perplexity’s model picker), and on June 12 Moonshot released K2.7-Code. Don’t mix them up: K2.7-Code is a coding specialist; it isn’t meant for everyday chat.
What makes K2.7-Code interesting:
- Built for long-horizon development: it plans, edits, runs tools, and debugs code across many steps in one loop. For ordinary management tasks, stick with K2.5/K2.6.
- Architecture and context – 1T parameters, 32B active (MoE), a 256K-token context window, open weights (Modified MIT) on Hugging Face, via the Kimi API and Kimi Code.
- ~30% fewer “reasoning tokens” than K2.6 – an agentic loop that used to burn ~1,000 tokens thinking through an edit now burns ~700. At scale, that’s direct savings.
- Reliable tool calls via MCP – it invokes external tools over the Model Context Protocol dependably: CI checks, ticket updates, and multi-file edits in a single pass.
Price – $0.75 / $3.50 per 1M input/output tokens: cheap enough to run a coding agent every day.
Be careful with the numbers: every published K2.7-Code result is Moonshot’s own benchmark (Kimi Code Bench v2: up from 50.9 to 62.0; MCP Mark Verified 81.1 vs 76.4 for Claude Opus 4.8). There are no independent public-suite results at launch – as with the GLM-5.2 story, vendor wins are worth re-checking.
For managers: if your team writes code, K2.7-Code is worth testing as a cheap developer-agent. For text, analysis, and communication, K2.5/K2.6 remain – those are what we tested in the benchmark below.
Kimi Work and OK Computer: Kimi as an agent
Beyond the models, Moonshot is building agent products – here Kimi competes directly with Perplexity Computer and Claude Cowork.
- OK Computer – an agent mode right inside Kimi chat. From a text prompt it builds multi-page sites and ready, editable slide decks, processes up to 1M rows of data at once, and outputs text, audio, images, and video. For a manager: a fast first draft of a presentation, landing page, or data report from a single prompt.
- Kimi Work – a desktop app (macOS on Apple silicon and Windows) running on K2.6 that acts on your own computer. You set a goal in plain language; the agent runs the research, turns it into a short market brief as ready slides (sections built in parallel), and through the WebBridge extension uses your browser like a person: searches, scrolls, extracts data, fills forms. Inside is the same Agent Swarm, up to 300 sub-agents.
For managers: Kimi Work and OK Computer turn Kimi from a chat into a “digital employee” – brief it overnight and get a draft brief or deck by morning. The main caveat: data is processed by a Chinese service, so weigh that for sensitive information.
Benchmark Results
In our independent benchmark – where we test models on real management tasks across multiple categories – Kimi K2.5 landed firmly in the elite group, among the very best models available today. It competes directly with GPT-5.4 and Claude Sonnet 4.5, which is remarkable for an open-source model that’s free to use. We tested K2.5; the current flagship K2.6 is its direct incremental successor, so the conclusions carry to today’s version.
Kimi K2.5 is strong across nearly all categories: communication, planning, analysis, learning and development, problem-solving. There’s no single weak spot – the model delivers consistently high quality regardless of task type. That consistency is actually one of its defining traits: while most models show noticeable ups and downs across categories, Kimi stays remarkably even.
For users who want frontier-level quality without paying for a subscription, Kimi K2.5 is the strongest free option available. It’s a genuinely elite-tier model that you can use at kimi.com without spending a cent – a remarkable alternative to ChatGPT Plus and Claude Pro.
How does it compare to other Chinese models? MiniMax M2.7 comes very close and leads in team management tasks. Xiaomi’s MiMo V2 Omni is strong in learning scenarios. Qwen3.5 Plus performs well and trails only slightly behind. But overall, Kimi K2.5 holds the top position among Chinese models – and significantly outperforms all Russian models (GigaChat, YandexGPT).
For full interactive results, see our comparison with DeepSeek and Qwen.
Kimi K2.5 vs Other Chinese Models
For a manager choosing between available tools, the comparison within the ‘Chinese group’ matters more than an abstract race against Claude.
| Model | Key strength | Chat access | Cost |
|---|---|---|---|
| Kimi K2.5 | Versatility, search | kimi.com | Free / $19–199/mo |
| MiniMax M2.7 | Team management | minimaxi.com | Free |
| Qwen3.5 Plus | Planning | chat.qwen.ai | Free (API only) |
| MiMo V2 Omni (Xiaomi) | Learning scenarios | mimo.xiaomi.com | Free |
| GLM-5 (Z.ai) | Team management | chat.z.ai | Free (API only) |
| DeepSeek V3.2 | Cost efficiency | chat.deepseek.com | Free (API only) |
| Qwen3 Max | Reasoning | chat.qwen.ai | Free (API only) |
Takeaways from the table:
Kimi K2.5 is the best Chinese AI overall. It leads across the widest range of management task categories, with no significant weak spots.
But it’s not the best in every category. MiniMax M2.7 edges ahead in team management. DeepSeek V3.2 offers the lowest cost per token. Qwen3.5 Plus is stronger in planning.
On accessibility, Kimi stands out. It’s one of the few elite-tier models with a completely free chat interface. Kimi’s paid plans ($19–199/mo) unlock agentic capabilities that competitors simply don’t offer in a chat interface.
How to Access Kimi K2.5
Web Interface: kimi.com
The website kimi.com is accessible globally. Sign in with a Google account – it takes about 10 seconds.
The interface is available in English and Chinese. The model understands and responds in many languages, though quality is noticeably higher in English and Chinese than in other languages – a pattern common to all Chinese models.
Three main modes of operation:
- Instant – quick answers for everyday tasks: drafting messages, answering questions, working with documents
- Thinking – deep analysis with chain-of-thought reasoning, the model shows its thinking process
- Agent – autonomous task execution: document generation (.docx, .pdf, .xlsx), web search, multi-step operations. If you’re asking it to prepare a report with tables – this is the mode
Mobile Apps
Kimi is available for iOS and Android. The functionality mirrors the web version, including all operating modes.
Pricing
Free Tier (Adagio)
- Unlimited text queries in Instant and Thinking modes
- Up to 3 agent requests per month (documents, spreadsheets, presentations)
- 1 Deep Research request per month
- Queue during peak hours
The free tier is enough to test the model and determine whether it suits your tasks. For daily work – it won’t be sufficient.
Paid Plans
| Plan | Price | What You Get |
|---|---|---|
| Moderato | $19/mo | More agent requests, priority, presentation generation |
| Allegretto | $39/mo | Higher limits, multi-agent tasking, access to Kimi Claw |
| Vivace | $199/mo | Unlimited agents, maximum speed, extended context |
API Pricing
| Option | Input tokens | Output tokens | ~Cost of analysing a 100-page report |
|---|---|---|---|
| Moonshot API (direct) | $0.60 / 1M | $3.00 / 1M | ~$0.50 |
| OpenRouter | $0.45 / 1M | $2.20 / 1M | ~$0.35 |
For comparison: Claude Opus 4.5 for a similar task costs around $3, GPT-5.2 – $1.50. Kimi K2.5 is 6–8x cheaper than Claude.
But among Chinese models, Kimi isn’t the most budget-friendly. DeepSeek V3.2 costs 3x less, Qwen3.5 Plus – 1.5x less.
Limitations and Risks
Non-English languages – a predictable weakness. Like GLM-5, Kimi K2.5 performs noticeably better in English and Chinese. In other languages, the model manages but loses nuance. If your task allows it – write your prompts in English.
Response speed – Agent Swarm is fast for complex tasks, but the standard Thinking mode is slower than Claude and GPT. In an independent test, Kimi K2.5’s median response time was 29.2 seconds versus 4.6 for Claude Sonnet 4.6. This raises a question: if Agent Swarm promises speed through parallelism, why is the standard mode 6x slower than competitors? For one-off queries it’s tolerable; for intensive work – it’s noticeable.
Chinese censorship works the same way as with other Chinese models: politically sensitive topics are blocked. For management tasks, this rarely becomes an issue.
Model size – 1 trillion parameters means running Kimi K2.5 on your own servers is unrealistic for a typical company. This isn’t Qwen3.5 9B, which you can deploy on a single GPU.
Should You Try It?
Kimi is objectively the strongest Chinese model line of 2026. Elite-tier performance, the unique Agent Swarm technology, and completely free basic access – all of it confirmed by independent testing.
For a manager, the recommendation depends on context. If you need a versatile tool with strong search, analysis, and agentic capabilities – Kimi K2.5 is worth trying. Especially if your tasks involve working with multiple sources, preparing reports, or multi-step research.
If cost is the primary concern – DeepSeek V3.2 remains the best value. It costs 3x less and delivers solid performance across most categories. If your focus is team management, HR tasks, and feedback – GLM-5 is still #1 in that category.
The surprising thing is that the strongest Chinese model of 2026 isn’t the one that got the most press at the start of the year. Kimi K2.5 surpassed both DeepSeek and Qwen without loud proclamations. Which raises a question worth sitting with: how reliable is media hype as a guide when choosing a working tool?
Head to kimi.com, sign in with Google, and spend an hour testing. The free tier is enough to form your own opinion.
We analyse Kimi K2.5 and other AI tools in practice
9 diagnostic lessons: try applying Kimi K2.5 and other models to real tasks – and discover what mistakes most managers make. No registration required.
Continue learning
Open the textbook and pick up where you left off











Stanislav Belyaev
Engineering Leader at Microsoft18 years leading engineering teams. Founder of mysummit.school. 700+ graduates at Yandex Practicum and Stratoplan.