Make Weak Model Great Again: Can Prompting Fix a Weak AI Model?
Every team has a ‘good enough’ model. Maybe it’s the one your company approved. Maybe it’s the one that runs locally because legal won’t let data leave the building. Maybe it’s the only option your country’s regulations allow.
In Russia, this is about to become very literal. In March 2026, the Ministry of Digital Development published a draft law on “trusted AI models.” If passed – enforcement is planned from September 2027 – government agencies and critical infrastructure will be limited to models from an approved registry. ChatGPT, Claude, and Gemini, which route data through foreign servers, could be restricted. Russian-made AI assistants would be pre-installed on devices by default.
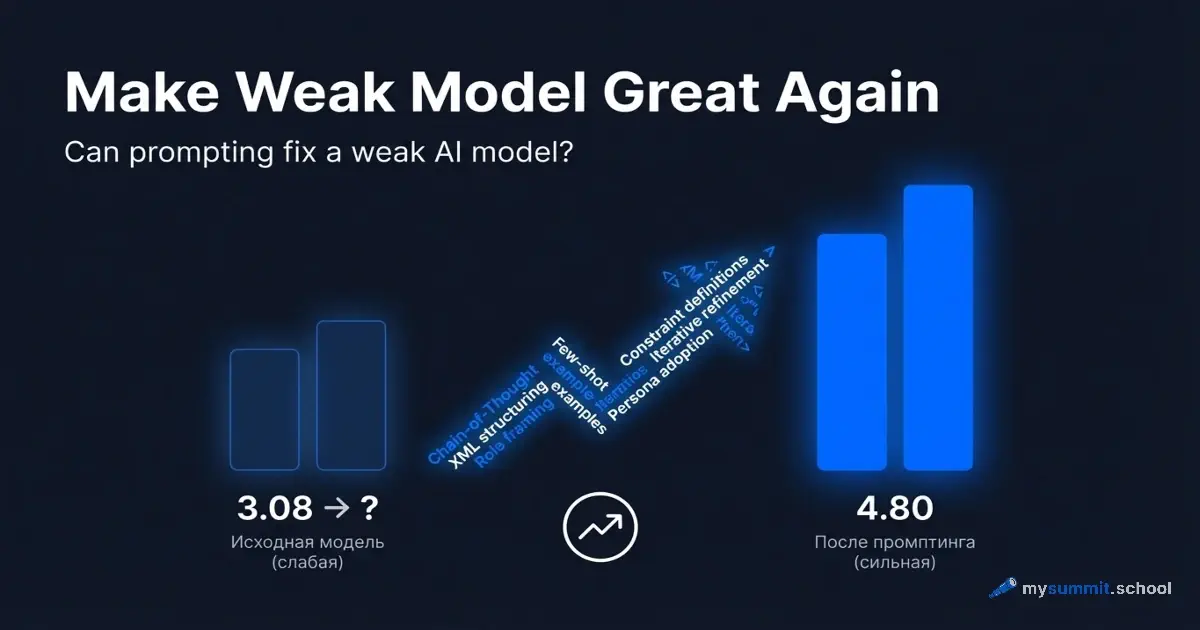
The problem is that Russian models lag behind. In our study of 54 models, GigaChat scored 3.26 out of 5. GPT-5.4 scored 4.80. That’s a 32% gap.
If GigaChat is all Russian managers have, can smart prompting pull acceptable quality out of it?
But here’s the thing – this isn’t just a Russian question. If you’re running Llama 3 locally because your data can’t leave the premises, or deploying Phi on edge devices, or using Mistral because it fits your budget, or choosing an open-source model because you need full control – you face the same gap, the same question. The techniques we’re testing and the limits we’re mapping transfer directly. The specific model changes; the problem doesn’t.
What We’re Doing and Why
The “Make Weak Model Great Again” experiment takes four models available in Russia – GigaChat-Ultra, GigaChat-2-Max, Alice AI (YandexGPT), and Qwen3 Max – and runs each through ten prompting techniques across six management tasks: from e-commerce metrics analysis to Russian labor law. For comparison, GPT-5.4 and Claude Sonnet 4.6 solve the same tasks with naive prompts – establishing the ceiling that the weaker models are trying to reach.
The techniques range from simple ones any manager can learn in a minute (role assignment, structured template) to multi-step dialogues where the model first analyzes, then critiques itself, then refines the answer. In between – Chain-of-Thought (“think step by step”), Few-Shot examples (showing a sample of a good answer), and XML-structured prompts typically used by developers rather than managers.
But two techniques make this experiment genuinely unusual: CAPS EMPHASIS and aggressive tone. The internet is full of advice along the lines of “write in ALL CAPS and the model will obey” or “yell at it and it’ll perform better.” Some people cite a 2024 Microsoft study, others just personal experience. There’s almost no scientific basis for any of it – especially not for weaker models. We included both techniques to settle this once and for all: does it work, or is it an urban legend of prompt engineering?
Why the Answer Isn’t Obvious
You might think: better prompt -> better result. But with smaller models, things get complicated – and existing research confirms it.
Wei et al. (Google Brain, 2022) showed that Chain-of-Thought – the technique that forces a model to “think step by step” – works brilliantly on large models. But on smaller ones, it triggers “confident but wrong” reasoning. The model produces five steps that look perfectly logical – and arrives at the wrong conclusion. Worse than if it had just answered directly. Whether GigaChat falls into this trap – we don’t know yet.
Zhang et al. (ACL 2024) found something even more uncomfortable: small models are physically unable to detect their own errors. When you ask “find the weaknesses in your answer and improve it,” the model doesn’t actually critique itself – it self-confirms. Slight rephrasing, no change in substance. If our data confirms this on the models we’re testing – that’s a concrete, actionable finding: don’t waste time on “improve your answer” with GigaChat or similarly-sized models.
And then there’s the architectural ceiling. Prompts reorganize what a model already knows. They cannot create knowledge that isn’t in the model’s weights. If GigaChat never “read” the Russian Labor Code during training – no prompt telling it “you are an expert labor lawyer” will make it cite the code correctly. The best you can hope for is that the model says “I don’t know” instead of a confident hallucination. The same applies to any model – if Llama hasn’t seen your domain’s data, no role-play prompt will conjure that knowledge out of thin air.
Incidentally, our benchmark revealed a counterintuitive result: GigaChat and Alice – models trained on Russian data – scored lower than GPT-5.4 on tasks related to Russian reality. Labor law, regional markets, domestic business specifics – across all these topics, the foreign model outperformed the native ones. Most likely, GPT-5.4 simply “read” more material about Russian labor law thanks to sheer scale. This is one of the key questions of our experiment: where does the line fall beyond which no prompt can compensate for a gap in knowledge?
Prompt techniques from this research will become part of our course materials. Try 9 real manager tasks in the free module – no registration required.
No payment required • Get notified on launch
What a Manager Gets Out of This
We’re deliberately making this an applied study, not an academic one. Academic papers on small language models tend to focus on automated optimization – fine-tuning, DSPy, algorithmic prompt improvement. We’re interested in something different: what can a regular manager do, armed with a weaker model and five minutes to formulate a request?
For each technique, we evaluate not just result quality but effort – how much time you need to spend reformulating the prompt. Because a technique that improves the answer by 15% but requires 20 minutes of preparation is useless to a manager.
The experiment will produce three things. First – a map of “technique -> model -> task”: if you have GigaChat for document analysis, which approach should you use? If Alice for writing an email? Second – ready-made templates for specific management tasks. And third – an honest boundary: in which scenarios prompting doesn’t help and you’re better off switching to a different model.
All of this will feed into the course – specifically, the section where prompt engineering theory meets data. Not “what is a prompt,” but “what actually works, on which tool, for which task.”
Whether you use Qwen, Llama, Mistral, or whatever your org approved – test your prompting approach on real manager tasks in the free course module.
No payment required • Get notified on launch
When to Expect Results
The experiment is in its launch phase. The full report will be published here, on the blog – with a breakdown of each technique, specific templates, and an honest conclusion about where the ceiling is. If you work daily with a model that isn’t GPT-5 or Claude – the answer to your question is being prepared.
You have the tool. Now build the skill.
The course foundation covers prompt engineering on real management tasks: structure, role assignments, decomposition, Chain-of-Thought. The management specialization goes deeper into planning, analytics, and team collaboration.



