El agente en lugar del chat: análisis de datos sin copiar y pegar
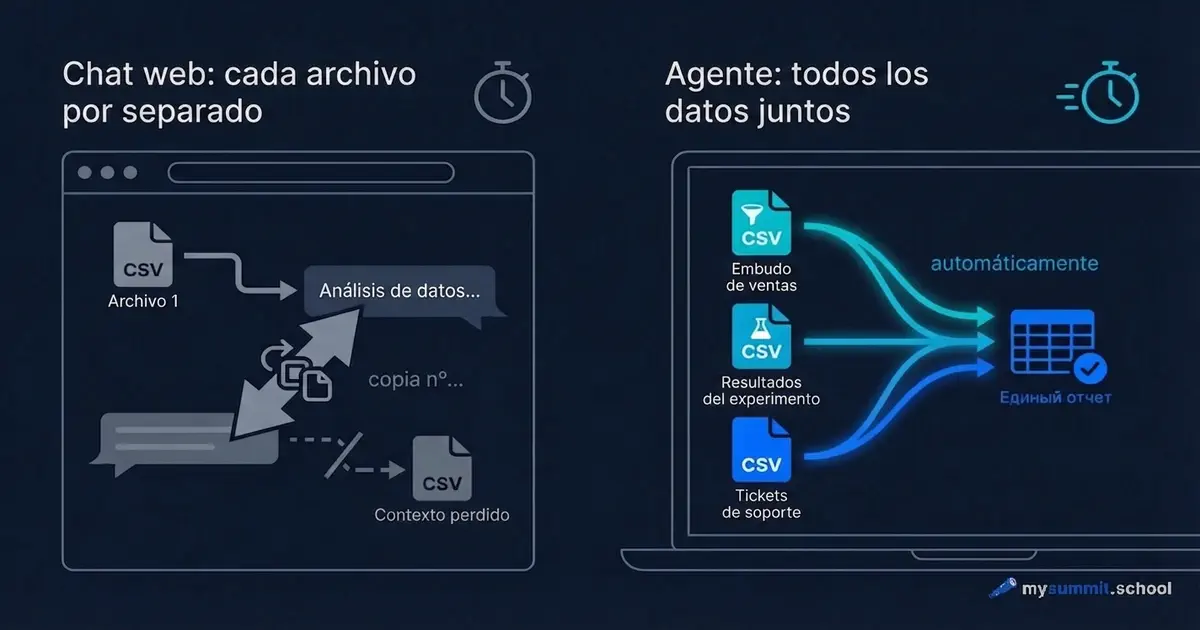
Tienes tres archivos de datos: el funnel de activación, los resultados de un test A/B y los tickets de soporte. La tarea – entender por qué el onboarding se está atascando. Abres ChatGPT, subes el primer archivo, haces una pregunta. Obtienes una respuesta. Subes el segundo archivo. ChatGPT pregunta: ¿puedes recordarme el contexto? Subes el tercero. El contexto del primer archivo ya ha sido desplazado.
Cuarenta minutos después tienes tres conversaciones separadas, y ninguna responde a la pregunta original. Porque la pregunta era una sola, y los datos – estaban en tres sitios distintos.
No es un problema de ChatGPT. Es un problema de enfoque.
Dos formas de trabajar con datos
La diferencia entre el chat en el navegador y el agente en tu portátil no está en la potencia del modelo. Está en quién va hacia quién.
En el chat eres tú quien lleva los datos al modelo. A trozos, subiendo archivos, dentro de una sola conversación. El modelo responde a lo que ve en ese instante. El siguiente mensaje – ya es un contexto ligeramente distinto.
En modo agéntico, el modelo viene hacia tus datos. El agente se instala como una aplicación normal en el portátil, ve la carpeta con tus archivos y trabaja con ellos directamente – como un analista al que le han dado acceso a tu ordenador. Le escribes la tarea en texto normal, como en Slack, – y él lee los archivos, calcula, guarda el resultado. Es justo la idea de BYOA – pero en su dimensión práctica, no conceptual.
La diferencia parece técnica. En la práctica, lo cambia todo.
Una tarea concreta, dos formas de resolverla
Imaginemos un escenario real. Un product manager de un SaaS nota que la conversión de nuevos usuarios a usuarios activos lleva atascada en 38% durante cuatro meses seguidos. Tiene tres tablas con datos.
La primera – el funnel de onboarding: registro, primera acción, segunda acción, invitación a un compañero.
La segunda – los resultados de un test A/B sobre una nueva función de onboarding: grupo de control y grupo de prueba, 500 empresas cada uno.
La tercera – 350 tickets de soporte de nuevos usuarios del último trimestre.
La pregunta: ¿en qué paso estamos perdiendo a la gente, por qué, y funcionó el experimento?
Opción 1: ChatGPT, interfaz web
Subes el funnel. ChatGPT lo analiza y encuentra el principal punto de caída. Bien. Subes los tickets – quieres entender de qué se quejan los usuarios precisamente en ese paso. ChatGPT dice: veo los tickets, recuérdame en qué paso hubo la caída. Le explicas. Analiza.
Subes los resultados del test. Archivo nuevo. ChatGPT los ve, pero ya no recuerda las cifras exactas del funnel del primer archivo – en qué segmento la conversión era del 55% y en cuál del 38%. Para cruzarlo, tienes que copiar los números a mano desde la primera conversación y pegarlos en la tercera.
Resultado al cabo de una hora: tres conclusiones separadas que hay que unificar manualmente. Y además una duda: ¿y si en algún sitio ha redondeado o ha confundido las filas? Comprobarlo es imposible.
Opción 2: un agente en el portátil
Abres la carpeta con las tres tablas y le escribes al agente un único mensaje – como a un analista en Slack:
Mira el funnel de activación. Encuentra el principal punto de caída. Luego abre los tickets y mira qué quejas están relacionadas con ese paso. Por último, revisa los resultados del test – si el experimento funcionó en general y en el segmento principal de clientes.
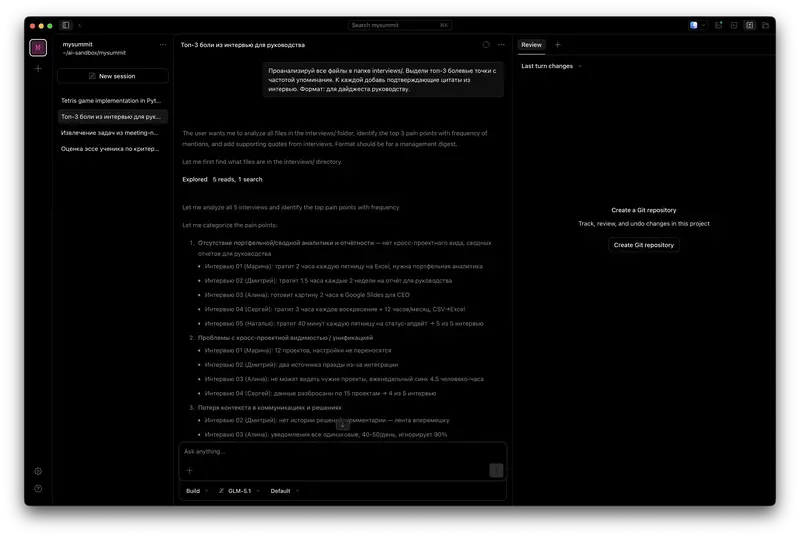
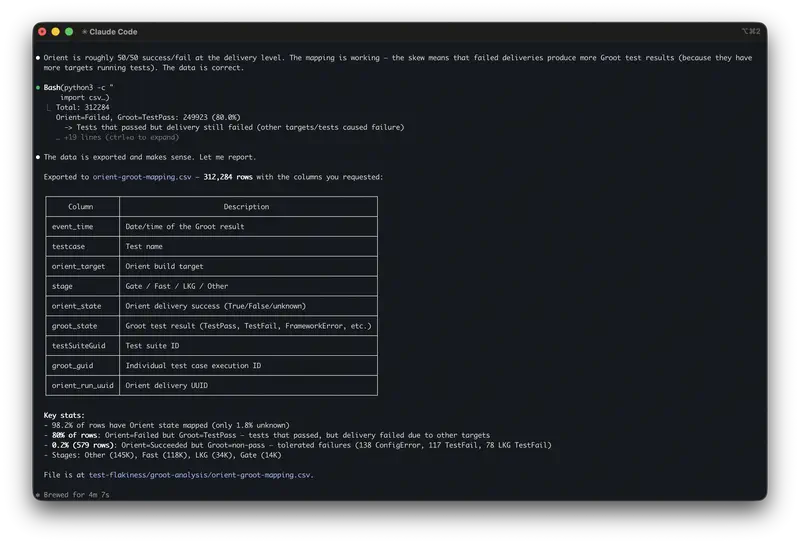
El agente abre los tres archivos. Los lee. Escribe código para analizar el funnel, lo ejecuta, obtiene los números. Pasa a los tickets, los agrupa por temas, cuenta frecuencias. Carga los datos del test, compara los grupos, revisa la estadística. Los resultados de los tres archivos están en el mismo contexto a la vez.
Todo el proceso dura unos minutos. Ves exactamente cómo ha calculado el agente – y puedes comprobar cada paso.
El análisis agéntico de datos es uno de los temas del curso. Prueba 9 tareas prácticas de un manager en el módulo abierto – gratis, sin registro.
Sin pago requerido • Notificación al lanzamiento
Qué cambia de forma radical
Hay varias cosas que parecen pequeñas, pero que definen la diferencia en la calidad del análisis.
El agente ve simultáneamente que en el tercer paso del funnel hay una caída del 45%, que en los tickets el 31% de las quejas se refieren precisamente a ese paso, y que en el experimento el segmento objetivo mostró +13,8 pp. Estos tres hechos no hay que cruzarlos a mano – ya están en una sola conclusión.
Además, el agente guarda exactamente cómo ha calculado. Mañana llegan los datos del mes siguiente – lanzas el mismo análisis otra vez sin esfuerzo extra. Ya no es una pregunta de una sola vez, es una rutina. Aquí se esconde precisamente el impuesto oculto sobre la IA: el 37% del tiempo ahorrado se va en revisar y rehacer el resultado. Cuando tienes el código, revisarlo lleva segundos.
Por último, el agente hace referencia a filas concretas de la tabla. Puedes abrir el archivo fuente y comprobarlo. En el chat, el modelo dice la mayoría de las empresas medianas – y es imposible saber si es un patrón real o una alucinación.
Cuándo el agente sigue alucinando
Una sección honesta, porque el agente no es magia.
El agente alucina en el mismo sitio que el chat: cuando formula interpretaciones, no cuando calcula. Cuando calcula, ves el resultado de un cálculo concreto. Pero cuando el agente dice esto apunta a un problema de UX – eso es su interpretación, y puede estar equivocada.
Un buen truco: tras cualquier conclusión, pídele al agente que te muestre de qué filas de la tabla se deriva. El agente debe responder con ejemplos concretos o mostrar un corte de los datos. Si empieza a explicarlo con palabras sin referencia a los datos – significa que está interpretando, no leyendo.
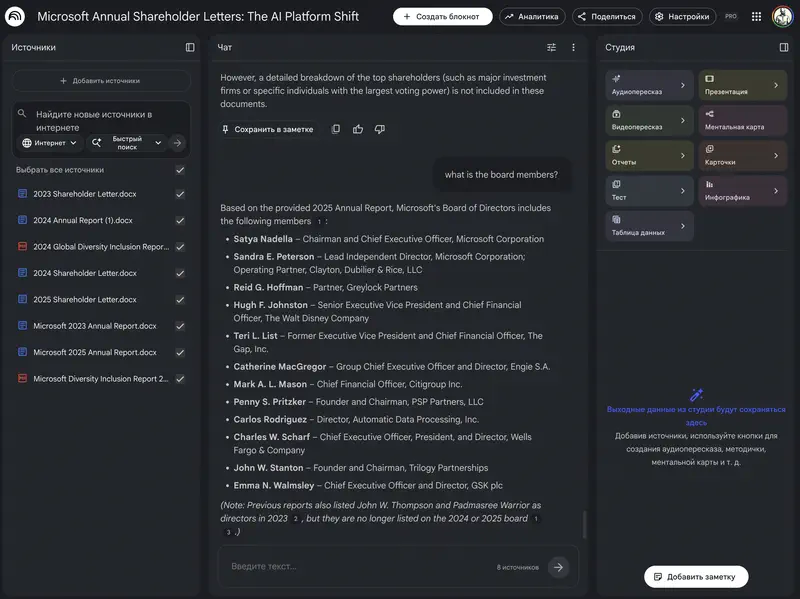
Segundo punto: el agente no conoce tu contexto de negocio. Descubre que en el grupo de prueba la conversión subió 4 pp en general y +13,8 pp en el segmento de 51–200 empleados. Pero la decisión de lanzarlo al 100% o no – es tuya. Para eso hay que saber cuál es el segmento objetivo, cómo es el mercado y cuánto cuesta desarrollarlo.
El agente da datos precisos. La decisión la tomas tú.
Qué muestra el análisis real de los tres archivos
Veamos en concreto qué encuentra el agente en este conjunto de datos.
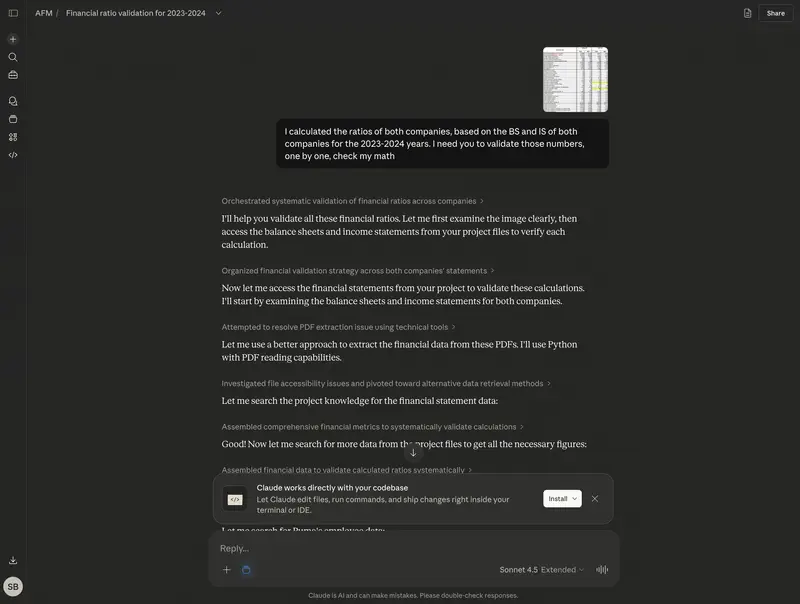
Funnel de activación (500 empresas). El agente calcula la conversión en cada paso. Primer paso – 77%, relativamente normal. Segundo paso – 55%. Ahí hay un problema: de las 385 empresas que hicieron la primera acción, solo 210 pasan al siguiente paso. Aquí se pierde más de la mitad de los potenciales usuarios activos.
El agente lo formula así: el principal punto de caída es la transición entre el paso 2 y el paso 3, el 45% no pasa. Tiempo mediano – 8 horas, mientras que el primer paso tardaba 2 horas. Significa que los usuarios vuelven, pero no completan la siguiente acción.
Tickets de soporte (350 en total). El agente los agrupa por temas. Descubre que el 31% de los tickets son la pregunta cómo añadir un objeto manualmente. Otro 27% – problemas con la conexión de una fuente externa. El 19% – subida de archivos.
Esto confirma la hipótesis del funnel: la gente no entiende cómo hacer la segunda acción. El UX no es obvio.
El agente da un paso extra que, en el chat, probablemente no habrías pedido: segmenta los tickets por tamaño de empresa. Encuentra que las empresas medianas (50–200 empleados) preguntan sobre el añadido manual el doble de veces que las pequeñas. Es el segmento objetivo del producto – lo que hace el problema más importante.
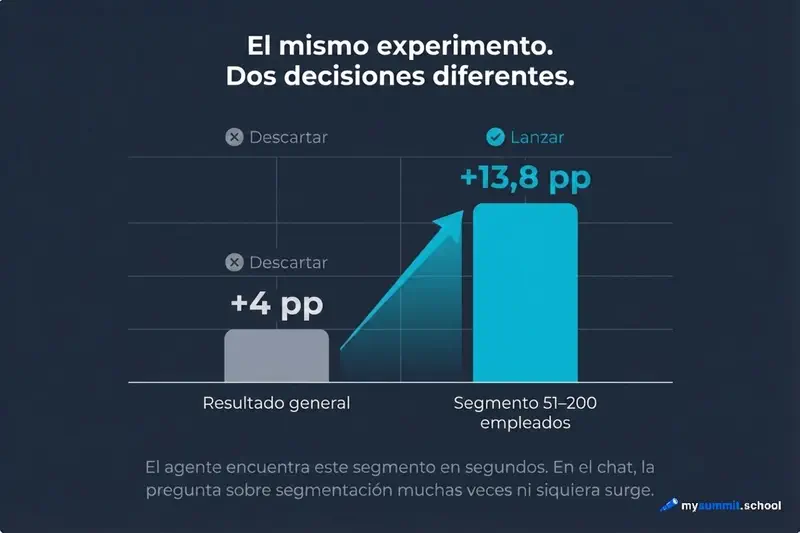
Resultados del test (1 000 empresas, dos grupos). Topline: control 38,4%, test 42,4%, mejora de +4 pp – parece decepcionante. Se preveía más, la estadística está al límite.
El agente segmenta por tamaño de empresa. En el segmento de 51–200 empleados: control 39,2%, test 53,0%, mejora de +13,8 pp – un resultado fuerte. Justo para el segmento objetivo el experimento funcionó.
Ese cambio – de experimento fallido a victoria en el segmento objetivo – el agente lo descubre porque mantiene los tres archivos en el mismo contexto a la vez. En el chat tendrías que haber hecho esa pregunta por separado, y no es seguro que se te hubiera ocurrido.
Cuándo NO necesitas un agente
El modo agéntico no siempre está justificado.
Si solo quieres ver rápido una media en una tabla pequeña de 50 filas – ChatGPT lo hará más rápido. No hace falta abrir otra herramienta.
Si los datos son confidenciales y no acabas de entender cómo funciona la herramienta – mejor estudiarlo antes. Los modelos en la nube (ChatGPT, Claude) procesan los datos en los servidores del proveedor. Eso puede ser inaceptable para datos bajo NDA. Un agente que trabaja con un modelo local en tu portátil es otro escenario, pero requiere preparación aparte.
Si la tarea es escribir un texto, esbozar una estructura o discutir una decisión – el agente no aporta ventajas. Su valor está precisamente en trabajar con archivos.
Cómo empezar: herramientas y modelos
De las herramientas de las que más se habla: Claude Code de Anthropic (requiere suscripción a Anthropic, alrededor de 100$ al mes), Kilo Code (extensión para VS Code, buena para quien ya trabaja con código) y OpenCode (software de código abierto, compatible con cualquier modelo).
Para empezar casi gratis – OpenCode con modelos chinos muy económicos. Kimi K2 y DeepSeek cuestan fracciones de céntimo por petición y, en calidad de análisis sobre datos estructurados, no se quedan atrás de GPT-4o.
OpenCode se instala como una aplicación normal y se ejecuta desde la carpeta donde tienes tus archivos. El primer análisis – 15 minutos después de la instalación. Más detalles sobre cómo funciona en la práctica – en el artículo sobre OpenCode. Allí también hay tres tareas que vale la pena probar el primer día.
El agente lee los archivos, calcula y segmenta los datos. Pon a prueba tu enfoque de análisis con 9 tareas reales de manager – gratis, sin registro.
Sin pago requerido • Notificación al lanzamiento
Qué cambia en el trabajo
El análisis agéntico no es un sustituto del analista. Es una forma de quitar fricción entre la pregunta y la respuesta.
Antes, entre quiero entender por qué se está atascando una métrica y aquí tienes un análisis sobre tres archivos con segmentación – mediaban varias horas de trabajo, o un ticket al analista con varios días de respuesta. Ahora – unos minutos.
Eso cambia qué preguntas llegas a hacer. Cuando el análisis es caro, solo se hacen las preguntas importantes. Cuando es barato – se empiezan a comprobar hipótesis que antes parecían poco importantes para pedir un análisis.
En nuestro ejemplo con los tres archivos pasó exactamente eso. El topline del test pintaba mal – +4 pp, estadística al límite. Conclusión típica: iterar o matarlo. Pero el agente segmentó los datos en pocos segundos – y resultó que para el segmento objetivo el resultado era fuerte (+13,8 pp). Eso cambia la decisión de matarlo a lanzarlo.
Sorprendentemente, lo más importante aquí no es la velocidad. Importa más otra cosa: el análisis se vuelve reproducible. Dentro de un mes, cuando lleguen datos nuevos, lanzas el mismo análisis otra vez. Ya no es una respuesta puntual – es una rutina analítica.
Quizás convenga distinguir dos tipos de trabajo con datos: preguntas puntuales (para las que el chat funciona bien) y rutinas analíticas recurrentes (para las que el agente cambia la situación radicalmente). La mayoría de las tareas de PM que realmente influyen en las decisiones – funnels, cohortes, experimentos – son del segundo tipo.
Qué viene después: un agente sobre tus datos
Este artículo ha mostrado un tipo de tarea – un análisis puntual de tres tablas. Pero el valor real del agente aparece más tarde: cuando el análisis deja de ser puntual y se convierte en rutina.
Ya no se trata de usar un agente, sino de construir un agente personal – con sus rutinas, conectado a tus datos reales.
A eso se dedica precisamente el curso Agente personal para managers, que estamos lanzando. Algunas cosas concretas por encima de este artículo:
- Empiezas con datos reales desde el primer día – ya al tercer día del curso el agente trabaja con tu correo de verdad. Lo exportas como un archivo normal en el portátil, sin implicar al departamento de IT.
- A lo largo del curso vas construyendo un conjunto de escenarios listos para tus tareas – se quedan contigo después del curso.
- Tras cada bloque subes el resultado de tu trabajo y recibes un análisis personal – no una autoevaluación, sino feedback real.
- Q&A en directo con el autor, canal de Telegram con tus compañeros de cohorte, estudio de casos.
- El curso está construido sobre herramientas accesibles internacionalmente. El coste total por las peticiones al modelo durante todo el curso – unos pocos dólares.
El curso está preparando su lanzamiento. Si quieres entrar en la primera cohorte – el formulario de inscripción está justo arriba.
La herramienta ya existe. Ahora toca la habilidad
Mientras el curso Agente personal se prepara para su lanzamiento, empieza por lo básico: el tronco común cubre prompt engineering y pensamiento crítico – sin ellos el agente devuelve cifras, pero no insights. La especialización en Gestión de Producto trata el análisis de datos con IA y el trabajo con agentes en tareas de PM.




Stanislav Belyaev
Engineering Leader en Microsoft18 anos liderando equipos de ingenieria. Fundador de mysummit.school. 700+ graduados en Yandex Practicum y Stratoplan.