99% de calidad por 1,4% del precio: qué falla en el mercado de modelos de IA
La mayoría de los managers eligen un modelo de IA así: cogen el más caro disponible. La lógica es comprensible – más caro significa mejor. Así ha funcionado con el software empresarial durante los últimos veinte años.
El mercado de modelos de IA en 2026 funciona de otra manera. El coste de una sola consulta varía de $0,0001 a $0,17 – tres órdenes de magnitud. ¿Y la diferencia real de calidad entre los diez mejores modelos? 0,24 puntos en una escala de cinco. Mientras tanto, Wharton / GBK Collective constata que un tercio de los proyectos corporativos de IA no pasan de la fase piloto. Y Epoch AI muestra que solo el 5,6% de los usuarios aplica la IA de forma realmente profunda.
Quizás la pregunta no es qué modelo es mejor, sino si pagar de más por el premium produce un resultado proporcionalmente mejor en tareas de gestión típicas.
Lo comprobamos. La respuesta fue más dura de lo esperado.
Los datos
Entre enero y marzo de 2026, probamos 54 modelos de IA en ocho categorías de tareas de gestión – desde redactar emails hasta análisis de datos y toma de decisiones con información incompleta. Los resultados completos están publicados en la plataforma. Un experimento aparte – si se puede compensar un modelo débil con prompting – demostró que los prompts estructurados reducen la brecha, pero no la cierran del todo. Metodología: dos evaluadores IA (Claude Opus 4.5 y Gemini 3 Pro) más calibración humana, 2.121 evaluaciones individuales. Cada modelo recibe una puntuación compuesta de 1 a 5 y un coste por consulta en dólares.
Los precios corresponden a abril de 2026 según datos de OpenRouter.ai, el único agregador con formato uniforme. Advertencia: los precios de las API cambian rápido. GPT-5.4 bajó durante el estudio de $0,0585 a $0,0158 por consulta. GPT-5.2 Pro, al contrario, subió de $0,039 a $0,1659.
La tabla final incluye 53 modelos (uno fue excluido por precios no transparentes).
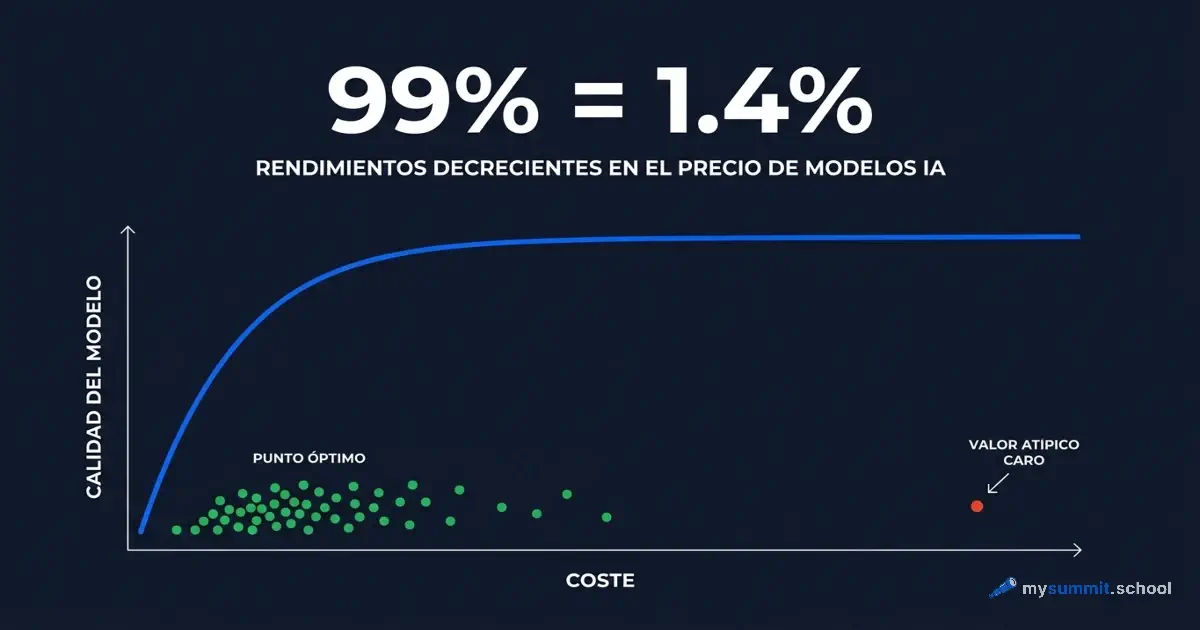
Rendimientos extremadamente decrecientes
La relación precio-calidad de los modelos de IA sigue una curva logarítmica. Pasar del rango de $0,0001 a $0,002 por consulta produce un salto de calidad de aproximadamente 1,5 puntos. Pasar de $0,002 a $0,17 – un aumento de precio de 85 veces – aporta unos 0,1 puntos más.
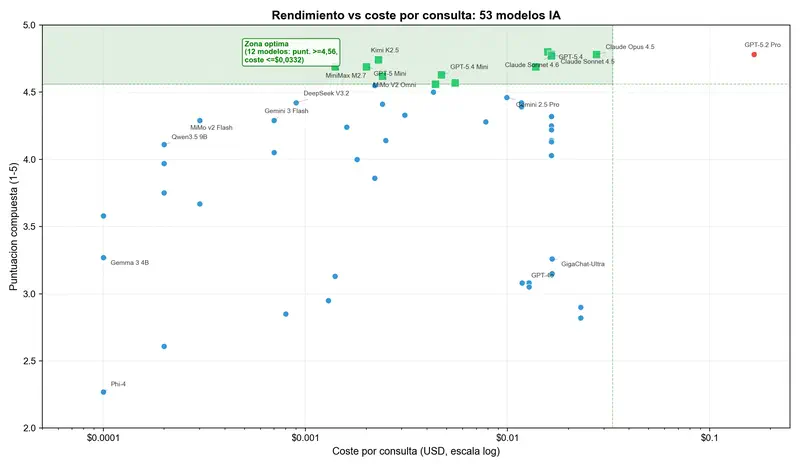
Un ejemplo concreto. Claude Sonnet 4.5 obtiene 4,78 puntos a $0,0165 por consulta. GPT-5.2 Pro – también 4,78 puntos. Pero cuesta $0,1659. Diez veces más caro. Mismo resultado. Lo verificamos tres veces – pensamos que había un error en la tabla. No, simplemente así funciona el mercado.
Y luego miramos Kimi K2.5. Puntuación de 4,74 a $0,0023 por consulta. Eso es el 99% de la calidad de GPT-5.4 por el 1,4% del coste de GPT-5.2 Pro.
La estrategia 80/20
Las comparaciones abstractas son interesantes, pero ¿qué significan para un presupuesto real?
Modelamos tres estrategias para un equipo de managers que realiza 1.000 consultas al mes.
Estrategia “todo al máximo”: todas las consultas a través de GPT-5.4. Coste: $15,80/mes. Calidad: 4,80.
Estrategia 80/20: el 80% de tareas rutinarias (emails, resúmenes breves, actas de reuniones) a través de un modelo económico como Qwen3.5 9B, el 20% de tareas complejas (análisis estratégico, informes para dirección) a través de GPT-5.4. Coste: $3,32/mes. Calidad: 4,25.
La diferencia: menos 79% de gasto con una pérdida del 11% de calidad. Para el 80% de las tareas – un borrador de email, resumir un documento, preparar un orden del día – la diferencia entre modelos a $0,0002 y a $0,016 es literalmente imperceptible.
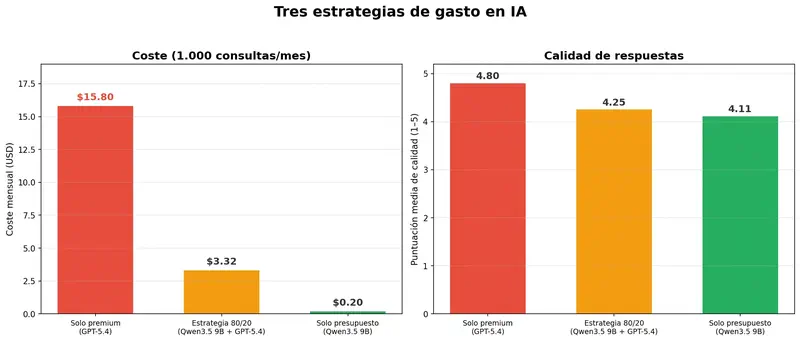
No es un ejercicio teórico. Para un equipo de 10 managers con 100 consultas al mes, la estrategia 80/20 ahorra unos $125 mensuales frente al enfoque “premium para todos”. La cifra no es transformadora, pero tampoco es cero. Y lo más importante – la calidad en el 80% de las tareas sigue siendo indistinguible.
La aritmética parece sencilla. La complejidad empieza cuando hay que decidir en concreto: aquí hay una tarea, aquí tres modelos – ¿cuál elegir y por qué? La diferencia entre “parece que servirá” y “sé por qué lo elegí” es una habilidad que se desarrolla con tareas reales.
Que tareas asignar al modelo economico y cuales al premium? Prueba 9 tareas de gestion con diferentes modelos -- gratis, sin registro.
Sin pago requerido • Notificación al lanzamiento
Campeones ocultos: el indicador “calidad por dólar”
Introdujimos la métrica PPD (Performance Per Dollar) – puntuación de calidad dividida por el coste de la consulta. Cuanto mayor es el PPD, más calidad se obtiene por cada dólar gastado.
Los resultados invierten la imagen habitual.
| Modelo | Puntuación | Coste/consulta | PPD |
|---|---|---|---|
| GPT-5.2 Pro | 4,78 | $0,1659 | 28 |
| GPT-5.4 | 4,80 | $0,0158 | 304 |
| Kimi K2.5 | 4,74 | $0,0023 | 2.097 |
| DeepSeek V3.2 | 4,42 | $0,0009 | 4.825 |
| Gemini 3 Flash | 4,29 | $0,0007 | 6.085 |
| MiMo v2 Flash | 4,29 | $0,0003 | 12.434 |
| Qwen3.5 9B | 4,11 | $0,0002 | 21.076 |
Los modelos económicos ofrecen entre 40 y 1.700 veces más calidad por dólar que GPT-5.2 Pro. No es un error de redondeo. Es una ineficiencia estructural del mercado que se puede aprovechar.
El “impuesto de la IA” – y quién lo paga
¿Por qué esto es un problema? ¿No usa todo el mundo la IA de la misma forma?
No. El estudio de Epoch AI / Ipsos reveló que el 62% de los usuarios de IA realizan tareas sencillas – consultas rápidas, borradores cortos. Solo el 5,6% usa la IA de forma profunda. Para ese 62%, la diferencia entre una consulta a $0,002 y una a $0,17 es literalmente invisible.
Pero los costes sí se ven. Workday, en su informe de 2026, introduce el término “impuesto de la IA” – el 37% del tiempo “ahorrado” con IA se dedica a corregir sus errores. Pero hay otro impuesto – financiero: pagar de más por un modelo premium en tareas donde uno económico habría funcionado igual de bien.
Brookings constata: entre los estadounidenses que usan IA, solo el 19% considera que les hace más productivos en el trabajo. El 4% – que les hace significativamente más productivos. Google Cloud, en su informe sobre ROI, muestra la otra cara: las empresas que ven resultados reales los consiguen no comprando el modelo más caro, sino eligiendo con precisión la herramienta adecuada para cada tarea. Quizás el problema no está en la herramienta, sino en cómo se elige y en qué se gasta.
La tabla tarea -> herramienta -> precio esta en la leccion 8 del modulo abierto. 9 tareas practicas de gestion con IA, gratis.
Sin pago requerido • Notificación al lanzamiento
Recomendación práctica
Si gestionas el presupuesto de IA de un equipo – esto es lo que puedes hacer esta semana.
Clasificar las tareas: borradores de emails, resúmenes de documentos, consultas de procedimientos, actas de reuniones – esto es rutina, el 70–80% de las consultas. Análisis estratégico, materiales para dirección, trabajo con datos ambiguos – tareas complejas, 20–30%.
Configurar el enrutamiento: la rutina al modelo económico (Kimi K2.5, Qwen3.5 Plus, DeepSeek V3.2), las tareas complejas al premium (GPT-5.4, Claude Sonnet 4.5). Técnicamente puede ser una pasarela API, un bot en el messenger con dos botones, o simplemente un acuerdo en el equipo: “para emails usamos X, para analítica Y”.
Medir: al cabo de un mes, comparar – ¿cambió la calidad en las tareas rutinarias? Si no – acabas de reducir los costes de IA en un 70–80% sin perder resultado.
Para elegir un modelo concreto, los candidatos destacados son Kimi K2.5 (4,74 puntos, el mejor en relación calidad-precio), Qwen3.5 Plus (4,56 puntos, más barato) y DeepSeek V3.2 (4,42 puntos, aún más barato). Un análisis detallado de disponibilidad y modelos locales es un tema aparte. Herramientas para trabajar con varios modelos – en el artículo sobre OpenCode.
Advertencias
Nuestro benchmark prueba categorías específicas de tareas. Es posible que los modelos premium sean realmente superiores en razonamientos complejos de varios pasos o en tareas que no probamos. GPT-5.2 Pro, pese a su alto precio, muestra una estabilidad asombrosa (desviación estándar de 0,082) – en algunos modelos económicos la dispersión es mayor. El enfoque “IA evalúa IA” tiene sus sesgos, aunque la calibración humana los mitiga.
Y lo más importante: estos números son una instantánea del mercado en abril de 2026. Los precios cambian semanalmente. Pero la imagen estructural – rendimientos extremadamente decrecientes en el segmento de precio alto – difícilmente cambiará: hay demasiados modelos compitiendo y abaratan demasiado rápido.
Conclusión
La hipótesis “más caro = proporcionalmente mejor” queda refutada por los datos. El mercado de modelos de IA en 2026 muestra rendimientos extremadamente decrecientes: la prima por el premium es real y medible. Eso no significa que los modelos premium sean inútiles – para el 20% de las tareas donde la calidad es crítica, la diferencia puede justificar el precio. Pero usar GPT-5.4 para resumir un acta de reunión es como ir al trabajo en helicóptero: técnicamente superior, económicamente absurdo.
La brecha entre precio y calidad en el mercado de modelos de IA es ahora mayor que nunca – y difícilmente se reducirá en el próximo año. Pero la pregunta más interesante es otra: si Kimi K2.5 ofrece el 99% de la calidad de GPT-5.4 por el 1,4% del precio, ¿qué compra exactamente un manager al elegir premium? ¿La reputación del proveedor? ¿La costumbre? ¿O la seguridad de que “estamos usando lo mejor” – aunque ese “mejor” no se note en el resultado?
Datos completos – en nuestro estudio de 53 modelos.
Del experimento al sistema
Elegir el modelo adecuado es una de las tareas del curso. El modulo de Fundamentos cubre prompt engineering y pensamiento critico con IA. La especializacion en Gestion de Proyectos analiza como integrar la IA en el ritmo operativo del manager -- desde borradores hasta analitica.




Stanislav Belyaev
Engineering Leader en Microsoft18 anos liderando equipos de ingenieria. Fundador de mysummit.school. 700+ graduados en Yandex Practicum y Stratoplan.