Los mejores AI para directivos sin VPN: datos de investigacion

Hemos completado un estudio a gran escala: 33 modelos de IA, 8 categorias de tareas de gestion. La pregunta era simple – cual AI funciona mejor para un directivo? Pero la respuesta resulto mas interesante de lo que esperabamos.
Especialmente cuando se trato de los modelos accesibles en Rusia sin VPN.
Que probamos y como
Antes de los numeros – una breve nota sobre la metodologia, porque sin este contexto los datos no significan nada.
33 modelos fueron probados en 32 escenarios reales de tareas de gestion: planificacion, comunicacion, analisis, gestion de equipos, busqueda de informacion, etc. Cada modelo recibio las mismas consultas en ruso – desde la perspectiva de un directivo comun, sin prompts especialmente optimizados. Asi es exactamente como la mayoria de las personas trabaja con IA.
La evaluacion fue realizada por dos jueces – Claude Opus 4.5 y Gemini 3 Pro. Realizamos una calibracion humana con 23 evaluaciones que revelo sesgos sistematicos: Opus subestimaba en 0,39 puntos, Gemini sobreestimaba en 0,53. Despues de la correccion, la puntuacion final se calcula como 70% Opus + 30% Gemini. Mas detalles en el articulo sobre metodologia.
La escala es de 1 a 5. Para contexto: 4,0 ya es un resultado solidamente bueno, 4,5+ es excelente.
La respuesta corta: que usar sin VPN
Si no quiere seguir leyendo – aqui esta la respuesta.
Primera opcion: DeepSeek V3.2. Puntuacion final 4,41 de 5,0. Chat gratuito en chat.deepseek.com, API cuesta ~$0,0007 por consulta – literalmente centavos. Mejor resultado entre todos los modelos accesibles en Rusia.
Segunda opcion: Grok 4.1 Fast de xAI. Puntuacion 4,37. Accesible directamente via x.ai, sin VPN. Desde marzo de 2026, xAI ha reducido radicalmente los precios – ahora ~$0,0007 por consulta, comparable a DeepSeek.
Tercera opcion: DeepSeek R1. Puntuacion 4,31 – una version con razonamiento extendido, especialmente fuerte en tareas analiticas. API ~$0,0028 por consulta.
Eso es todo. Para la mayoria de las tareas de gestion, estos tres modelos son suficientes.
El resto son detalles que importan segun sus tareas especificas y presupuesto.
El panorama completo: niveles de modelos accesibles
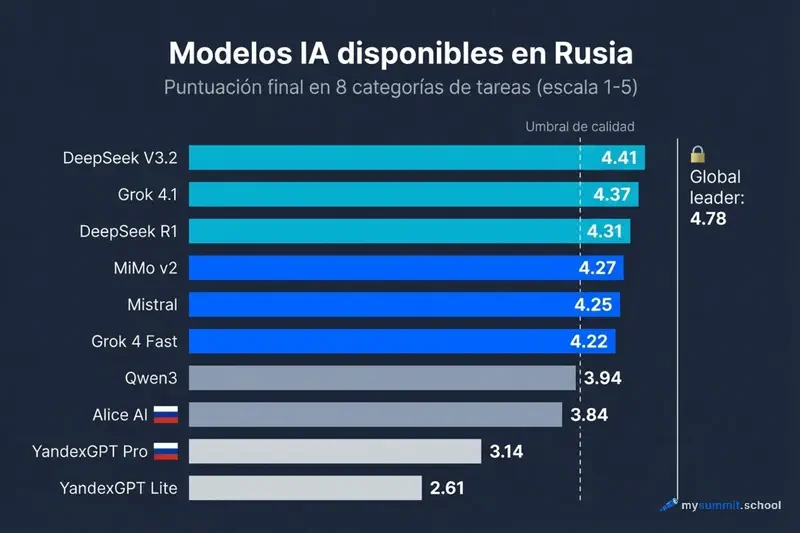
Agrupamos todos los modelos probados en tres niveles segun la puntuacion final.
Nivel 1: el top 3 de Rusia (>= 4,30)
| Modelo | Puntuacion | Acceso | Costo / consulta |
|---|---|---|---|
| DeepSeek V3.2 | 4,41 | chat.deepseek.com + API directo | ~$0,0007 |
| Grok 4.1 Fast | 4,37 | x.ai (X Premium / SuperGrok) | ~$0,0007 |
| DeepSeek R1 | 4,31 | chat.deepseek.com + API directo | ~$0,0028 |
Nivel 2: alternativas solidas (4,00–4,29)
| Modelo | Puntuacion | Acceso | Costo / consulta |
|---|---|---|---|
| MiMo v2 Flash (Xiaomi) | 4,27 | solo API | ~$0,0004 |
| Mistral Large | 4,25 | chat.mistral.ai (Le Chat) + API | ~$0,0078 |
| Grok 4 Fast | 4,22 | x.ai | ~$0,0007 |
| MiniMax M1 | 4,12 | solo API | – |
| Grok 4 | 4,12 | x.ai | ~$0,0007 |
| Grok 3 | 4,11 | x.ai | ~$0,0007 |
Nivel 3: notablemente mas debiles (3,50–3,99)
| Modelo | Puntuacion | Acceso |
|---|---|---|
| Qwen3 235B | 3,94 | chat.qwen.ai |
| Alice AI LLM (Yandex) | 3,84 | alice.yandex.ru / Navegador Yandex |
| Gemma 3 27B | 3,73 | solo API |
| Qwen3 32B | 3,65 | chat.qwen.ai |
La brecha entre niveles es significativa. Si el Nivel 1 es un solido “B+”, el Nivel 3 es mas bien un “C+”. Suficiente para tareas rutinarias. Insuficiente para decisiones serias.
Lo que ocurre a nivel global
Probamos deliberadamente modelos bloqueados en Rusia tambien. De otro modo, no se puede entender la magnitud de la “brecha rusa”.
El top global se ve asi:
| Modelo | Puntuacion | Disponibilidad en Rusia |
|---|---|---|
| Claude Sonnet 4.5 (Anthropic) | 4,78 | VPN requerido |
| GPT-5.2 Pro (OpenAI) | 4,78 | VPN requerido |
| Claude Opus 4.5 (Anthropic) | 4,77 | VPN requerido |
Puntuacion media del top 3 global: 4,78. Puntuacion media del top 3 de Rusia: 4,36.
La brecha – 0,42 puntos.
En numeros abstractos parece poco. Pero en una escala de 1 a 5, es la diferencia entre “excelente” y “bien”. Aproximadamente como A–/B+ en el sistema de calificaciones occidental. Para la mayoria de las tareas diarias, la diferencia no es critica. Para trabajos analiticos o estrategicos complejos – puede notarse.
Lo interesante es que esta brecha no es uniforme entre las categorias de tareas.
Como los modelos accesibles en Rusia manejan diferentes tareas
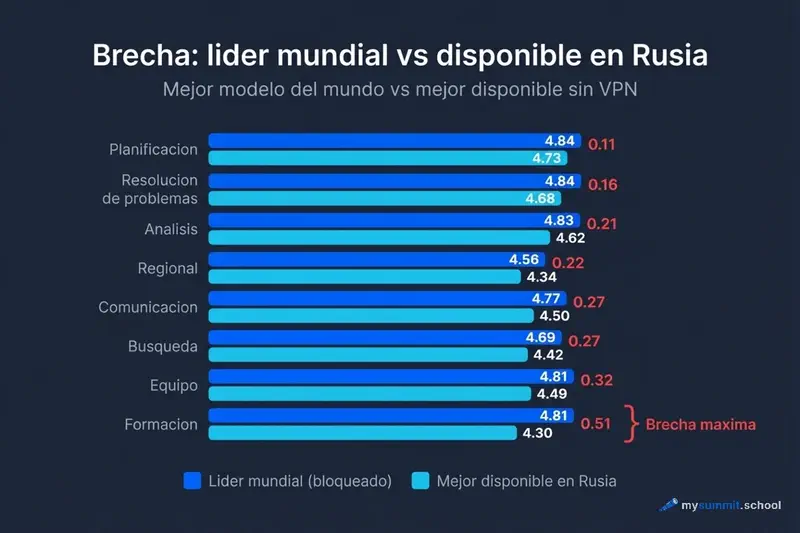
Que significan las categorias: Planificacion – elaboracion de planes, agendas de reuniones, priorizacion de tareas. Resolucion de problemas – analisis de fallos, identificacion de causas raiz, gestion de crisis. Analisis – interpretacion de datos, conclusiones de informes, evaluacion de riesgos. Regional – conocimiento de la legislacion rusa, particularidades culturales, practicas locales. Comunicacion – correos empresariales, retroalimentacion, mensajes al equipo. Investigacion – verificacion de hechos, recopilacion de informacion, comparacion de fuentes. Equipo – gestion de personas, conflictos, motivacion, evaluaciones de desempeno. Formacion – planes de desarrollo, conversaciones de carrera, materiales de capacitacion.
Examinamos 8 categorias. En algunas, la brecha con el top global es minima – en otras, es sustancial.
| Categoria de tarea | Lider global | Puntuacion | Mejor en Rusia | Puntuacion | Brecha |
|---|---|---|---|---|---|
| Planificacion | Sonnet | 4,84 | DeepSeek V3.2 | 4,73 | 0,11 |
| Resolucion de problemas | Sonnet | 4,84 | DeepSeek V3.2 | 4,68 | 0,16 |
| Analisis y decisiones | Sonnet | 4,83 | DeepSeek R1 | 4,62 | 0,21 |
| Comunicacion | GPT-5 Mini | 4,77 | Grok 4.1 | 4,50 | 0,27 |
| Busqueda de informacion | GPT-5.2 Pro | 4,69 | DeepSeek R1 | 4,42 | 0,27 |
| Gestion de equipo | GPT-5.2 Pro | 4,81 | DeepSeek V3.2 | 4,49 | 0,32 |
| Especificidades regionales | GPT-5.2 | 4,56 | DeepSeek V3.2 | 4,34 | 0,22 |
| Formacion y desarrollo | Opus | 4,81 | DeepSeek V3.2 | 4,30 | 0,51 |
Dos conclusiones saltan a la vista.
Primera: en planificacion y resolucion de problemas, los modelos accesibles en Rusia casi alcanzan al top global. Una brecha de 0,11–0,16 puntos es practicamente invisible en el trabajo real.
Segunda: en tareas de formacion y desarrollo de empleados, la brecha es maxima – 0,51 puntos. Esto ya se nota. Si utiliza frecuentemente la IA para escribir planes de desarrollo, retroalimentacion por competencias o conversaciones de carrera – aqui es donde los modelos accesibles en Rusia quedan mas rezagados.
9 lecciones sobre IA para directivos – sin registro ni pago
Sin pago requerido • Notificación al lanzamiento
La paradoja de YandexGPT: por que el modelo “propio” pierde
Este es el resultado que mas nos sorprendio.
Alice (el asistente de IA para consumidores de Yandex, impulsado por YandexGPT – el modelo de lenguaje domestico mas grande de Rusia) obtuvo 3,84 – eso es Nivel 3. Por debajo de DeepSeek, Grok, Mistral e incluso MiMo v2 Flash de Xiaomi, del que la mayoria de los directivos jamas ha oido hablar.
Especialmente reveladora es la categoria “especificidades regionales” – tareas que involucran leyes, regulaciones y contexto cultural rusos. Seria logico que Yandex fuera imbatible aqui. Pero no: Alice obtiene 3,68, mientras que GPT-5.2 obtiene 4,56.
Esto hace reflexionar. Por que un modelo entrenado en lengua rusa y contexto ruso pierde ante un modelo estadounidense en tareas especificas de Rusia?
Curiosamente, el propio Yandex afirma que Alice AI vence a DeepSeek V3.1 y Qwen3-235B en el 60% de las tareas empresariales. Mirando los detalles – Alice es mas fuerte en edicion de textos (68% de victorias sobre DeepSeek) y resumen (65%). Pero en generacion de textos, Alice ya pierde ante Qwen (62% a favor de Qwen), y en preguntas abiertas – tambien (61% a favor de Qwen).
Un detalle importante: Yandex comparo contra DeepSeek V3.1, mientras que nosotros probamos la ya publicada V3.2 – una version sustancialmente actualizada. Nuestra investigacion muestra un panorama diferente: Alice (3,84) queda por detras de DeepSeek V3.2 (4,41) en las ocho categorias de tareas de gestion. La divergencia se debe a diferentes versiones de modelos, diferentes metodologias y diferentes conjuntos de tareas. Pero en la practica, para un directivo el resultado es el mismo: DeepSeek V3.2 produce respuestas mas utiles y precisas.
Nuestra interpretacion: las capacidades analiticas de un modelo importan mas que su “idioma nativo”. DeepSeek habla ruso con excelencia y al mismo tiempo es analiticamente mas fuerte.
Si esta usando YandexGPT a traves de Alice en el navegador Yandex como su herramienta de trabajo principal – nuestros datos sugieren que esta dejando un potencial significativo sin aprovechar. El analisis detallado de YandexGPT describe en que es fuerte y donde queda corto.
Mas sobre los modelos de Yandex
Cuatro modelos de Yandex participaron en el estudio. Asi se desempenaron por categoria:
| Categoria | Alice AI LLM | YandexGPT Pro 5.1 | YandexGPT Pro 5 | YandexGPT Lite |
|---|---|---|---|---|
| Analisis y decisiones | 4,42 | 3,66 | 3,20 | 3,13 |
| Resolucion de problemas | 4,33 | 3,62 | 3,08 | 2,64 |
| Comunicacion | 4,19 | 3,43 | 3,06 | 2,66 |
| Planificacion | 4,15 | 3,47 | 3,19 | 2,86 |
| Busqueda de informacion | 3,95 | 2,18 | 2,53 | 2,38 |
| Especificidades regionales | 3,68 | 2,95 | 2,50 | 2,37 |
| Equipo | 3,50 | 3,11 | 2,84 | 2,65 |
| Formacion y desarrollo | 2,70 | 2,70 | 2,40 | 2,24 |
| Promedio | 3,86 | 3,14 | 2,85 | 2,61 |
Observaciones clave:
- Alice AI LLM es el unico modelo competitivo de Yandex. En analisis (4,42) y resolucion de problemas (4,33), alcanza el nivel del Nivel 2. Los otros tres modelos son notablemente mas debiles. La API de Alice cuesta 0,50 RUB/1K tokens de entrada y 2,00 RUB/1K tokens de salida (con el descuento vigente del 50%).
- Formacion y desarrollo es el punto debil de todos los modelos de Yandex. Incluso Alice obtiene solo 2,70 aqui – su resultado mas bajo en todas las categorias. A modo de comparacion: DeepSeek V3.2 obtiene 4,30 en la misma categoria.
- YandexGPT Pro 5.1, Pro 5 y Lite promedian 2,6–3,1. A este nivel, las respuestas del modelo perjudican mas de lo que ayudan – demasiadas inexactitudes y recomendaciones superficiales.
- Las especificidades regionales – supuestamente la carta fuerte de Yandex – dan solo 3,68 para Alice. DeepSeek V3.2 obtiene 4,34 en la misma categoria.
Mas detalles sobre las capacidades y limitaciones de todos los modelos de Yandex en el analisis de YandexGPT.
Chat vs. API: que esta disponible sin habilidades tecnicas
Una aclaracion importante: el estudio se realizo a traves de API. Pero la mayoria de los directivos usan interfaces de chat, no codigo. Esto es lo que realmente esta disponible “con un clic”:
Interfaces de chat:
- DeepSeek – chat gratuito en chat.deepseek.com. Funciona sin VPN, sin necesidad de registrarse con un numero de telefono ruso. Simplemente abralo y empiece a trabajar.
- Grok – via X Premium ($8/mes) o SuperGrok ($30/mes) en x.ai. Requiere suscripcion, pero acceso directo.
- Qwen – chat gratuito en chat.qwen.ai. Modelos de Nivel 3, pero sirve para tareas simples.
- YandexGPT/Alice – via alice.yandex.ru o el navegador Yandex. Gratuito y comodo, pero la calidad es la que mostro el estudio.
- Mistral – Le Chat gratuito en chat.mistral.ai. Buena alternativa, especialmente para contexto europeo.
Solo API:
- MiMo v2 Flash – sin interfaz de chat, solo para desarrolladores. Pero ~$0,0004 por consulta.
- MiniMax M1 – misma situacion.
Si no quiere lidiar con APIs – su eleccion es DeepSeek para el trabajo diario y Grok como alternativa mas cara pero de alta calidad.
La estrategia 80/20: como optimizar costos
Si esta dispuesto a trabajar a traves de la API – existe una estrategia inteligente.
No todas las tareas son iguales. Redactar un borrador de carta a un socio es una cosa. Analizar un informe financiero antes de una reunion del consejo directivo es otra.
Para el 80% de las tareas, un modelo economico es suficiente: MiMo v2 Flash ($0,0004/consulta) o DeepSeek V3.2 ($0,0007/consulta). Para el 20% de tareas complejas – DeepSeek R1 ($0,0028/consulta) o Grok 4.1 Fast ($0,0007/consulta).
Calculo aproximado para 1.000 consultas por mes:
- Estrategia 80/20 con MiMo + DeepSeek R1: ~$0,85/mes
- Solo DeepSeek V3.2 para todo: ~$0,73/mes
- Solo Grok 4.1 Fast para todo: ~$0,70/mes
Si, leyo bien – menos de un dolar al mes. Con los nuevos precios de marzo 2026, el acceso por API a los mejores modelos accesibles en Rusia cuesta menos que una taza de cafe. La cuestion del costo esta esencialmente resuelta – elija por calidad.
Este enfoque – usar la IA como copiloto con diferentes niveles de herramientas – lo cubrimos en detalle en nuestra comparativa completa de herramientas GenAI.
Advertencias importantes
Algunos puntos a considerar antes de tomar decisiones basadas en estos datos.
Los modelos se actualizan. Desde las pruebas (enero 2026), GPT-5.2 ya se convirtio en GPT-5.4, Qwen ha lanzado nuevas versiones. GPT-4o, que ocupo el puesto 29, fue oficialmente retirado en febrero de 2026 – pero esto no afecta las conclusiones ya que de todos modos tenia un rendimiento inferior. Los demas modelos del estudio siguen disponibles. No esperamos cambios importantes en el ranking para tareas de gestion – los grandes modelos mejoran gradualmente. Pero si esta probando una version especifica – verifique que siga vigente.
GigaChat no fue probado. GigaChat es un modelo de lenguaje de Sberbank, el banco mas grande de Rusia. Lo excluimos deliberadamente de este estudio – es una historia aparte con acuerdos de acceso empresarial y un contexto regulatorio especifico. Quizas en el proximo estudio. Si le interesa el estado actual del modelo – el analisis de GigaChat ofrece un panorama actualizado.
API != interfaz de chat. Probamos via API con consultas estandar. La experiencia real en chat puede diferir – prompts de sistema diferentes, contexto variable, modos de operacion distintos.
Usuario ingenuo. Todas las consultas fueron compuestas sin optimizacion especial de prompts. Si sabe trabajar con IA – sus resultados seran mejores en todos los modelos. Las brechas entre ellos pueden cambiar.
Conclusion
La buena noticia: una brecha de 0,42 puntos con el top global no es una catastrofe. Los usuarios de IA en Rusia tienen acceso a herramientas de nivel “B+”, mientras que el top global es “A–”. Para la mayoria de las tareas de gestion diarias, esto es perfectamente aceptable.
DeepSeek V3.2 es la primera opcion obvia. Chat gratuito, API economica, mejor puntuacion entre los modelos accesibles. El analisis detallado de DeepSeek le ayudara a entender exactamente como usarlo.
Grok es una alternativa solida con acceso directo via x.ai. El analisis de Grok describe sus fortalezas y escenarios donde supera a DeepSeek.
En cuanto a apostar por YandexGPT como herramienta de trabajo principal – los datos no lo respaldan.
Paradojicamente, en 2026, el mejor AI para un directivo de habla rusa es un modelo chino. Como sucedio esto y que dice sobre el desarrollo de la industria – es una buena pregunta para un analisis aparte.
Domine la IA de forma sistematica – sin adivinar
9 lecciones sobre el uso de IA para directivos: que herramienta para que tarea, como evitar alucinaciones, como construir un flujo de trabajo eficaz. Sin registro ni pago.