Los mejores AI para directivos en Rusia: 52 modelos, 3300+ evaluaciones

Realizamos un estudio a gran escala: 52 modelos, evaluaciones de dos jueces LLM independientes, en 8 categorias de tareas de gestion. Este es el ranking de IA en lengua rusa mas completo para directivos disponible hoy.
La pregunta sigue siendo la misma: que IA funciona realmente para un directivo en Rusia – sin VPN, sin rodeos?
Metodologia: resumen
52 modelos se evaluaron en 32 escenarios de tareas de gestion en ruso con una metodologia unificada. Los prompts se redactaron desde la perspectiva de un directivo comun, sin optimizacion especial de prompting.
Dos jueces evaluaron las respuestas – Claude Opus 4.5 y Gemini 3 Pro. La calibracion humana (23 evaluaciones) revelo sesgos: Opus puntuaba 0,39 puntos por debajo, Gemini 0,53 por encima. Puntuacion final: 70% Opus + 30% Gemini tras correccion. Escala: 1–5.
Que significan las puntuaciones en la practica:
- 4,5–5,0 – la respuesta se puede usar directamente: recomendaciones concretas, datos actualizados, estructura clara. Como recibir una respuesta de un colega competente.
- 4,0–4,4 – util pero necesita ajustes: algo superficial en partes, 1–2 imprecisiones, no siempre tiene en cuenta su contexto especifico.
- 3,0–3,9 – «en lineas generales correcto» pero con lagunas notables: frases genericas en vez de concreciones, datos desactualizados, poca adaptacion a su tarea. Habra que verificar y reescribir.
- Por debajo de 3,0 – mas perjudicial que util: errores facticos, consejos irrelevantes, riesgo de tomar una decision erronea si se confia en el modelo.
La respuesta corta: que usar sin VPN
Si no quieres seguir leyendo – aqui tienes la respuesta a marzo de 2026.
Primera opcion: Kimi K2.5. Puntuacion 4,74 sobre 5,0 – 6.o puesto mundial, 1.o entre los modelos accesibles desde Rusia. Chat web en kimi.com funciona sin VPN. Nivel gratuito disponible, planes de pago desde $19/mes. Caracteristica unica – Agent Swarm: 100 agentes paralelos para tareas de investigacion complejas. Debilidad – el ruso es notablemente mas debil que el ingles.
Segunda opcion: Qwen3.5 Plus. Puntuacion 4,56, 13.o a nivel mundial. Chat gratuito en chat.qwen.ai. API cuesta ~$0,0005 por peticion – practicamente gratis. El modelo de acceso directo mas fuerte para planificacion (4,83).
Tercera opcion: GLM-5 de Z.ai. Puntuacion 4,50, 15.o a nivel mundial. Chat gratuito en chat.z.ai, codigo abierto. 1.er puesto entre los 52 modelos en gestion de equipos (4,83). Debilidad – especificidades regionales (3,95).
Cuarta opcion: DeepSeek V3.2. Puntuacion 4,42, 19.o a nivel mundial. Chat gratuito en chat.deepseek.com. API ~$0,0004 por peticion. Mejor que GLM-5 y Kimi en comprension del contexto ruso (4,34 en la categoria regional).
Para la mayoria de las tareas diarias de gestion, estos cuatro modelos son mas que suficientes.
El panorama completo: niveles de modelos accesibles
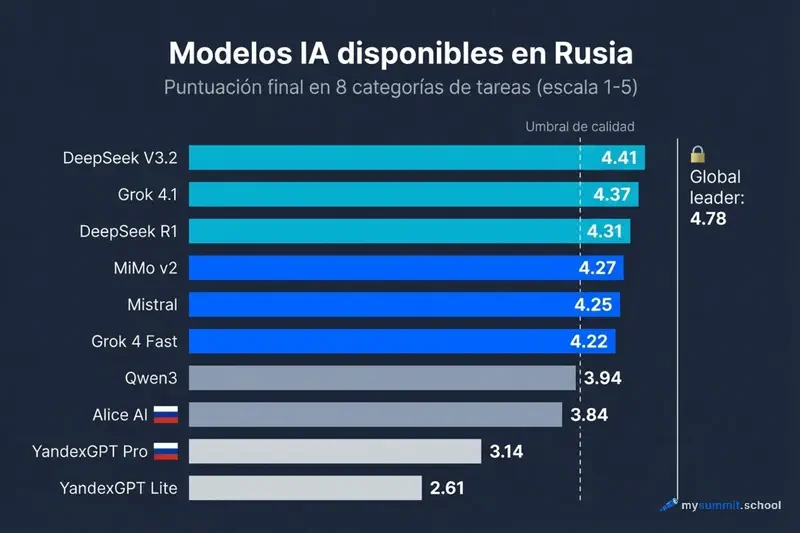
Todos los modelos accesibles desde Rusia – directamente o via OpenRouter – agrupados por puntuacion final.
Nivel 1: Elite (>= 4,50)
| Modelo | Puntuacion | Ranking global | Acceso | Coste / peticion |
|---|---|---|---|---|
| Kimi K2.5 | 4,74 | 6 | kimi.com (gratis/pago) | ~$0,0008 |
| MiniMax M2.7 | 4,69 | 7 | Solo API | ~$0,0005 |
| GPT-5.4 Mini (OpenRouter) | 4,63 | 10 | Solo API | ~$0,0016 |
| MiMo V2 Omni (Xiaomi) | 4,62 | 11 | Solo API | ~$0,0007 |
| Qwen3.5 Plus | 4,56 | 13 | chat.qwen.ai (gratis) | ~$0,0005 |
| Qwen3.5 397B | 4,55 | 14 | chat.qwen.ai (gratis) | ~$0,0008 |
| GLM-5 | 4,50 | 15 | chat.z.ai (gratis) | ~$0,0009 |
Siete modelos – el doble que hace tres meses. Los modelos chinos dominan: cinco de siete son de China.
Nivel 2: Modelos fuertes (4,20–4,49)
| Modelo | Puntuacion | Ranking global | Acceso | Coste / peticion |
|---|---|---|---|---|
| Nemotron 3 Super (NVIDIA) | 4,48 | 16 | API (gratis) | gratis |
| Qwen3 Max | 4,42 | 18 | chat.qwen.ai | ~$0,0014 |
| DeepSeek V3.2 | 4,42 | 19 | chat.deepseek.com (gratis) | ~$0,0004 |
| Qwen3 Max Thinking | 4,39 | 21 | chat.qwen.ai | ~$0,0014 |
| DeepSeek R1 | 4,33 | 22 | chat.deepseek.com (gratis) | ~$0,0008 |
| MiMo v2 Flash | 4,29 | 25 | Solo API | ~$0,0001 |
| Mistral Large | 4,28 | 26 | chat.mistral.ai (Le Chat) | ~$0,0024 |
| MiniMax M2.5 | 4,24 | 28 | Solo API | ~$0,0004 |
| Claude Sonnet 4.0 (OpenRouter) | 4,22 | 29 | Solo API | ~$0,0054 |
DeepSeek sigue siendo la mejor relacion precio-calidad entre los modelos con interfaz de chat gratuita.
Nivel 3: Caballos de batalla (3,80–4,19)
| Modelo | Puntuacion | Ranking global | Acceso |
|---|---|---|---|
| MiniMax M1 | 4,14 | 30 | Solo API |
| Qwen3.5 9B | 4,11 | 33 | chat.qwen.ai |
| Mistral Small 4 | 4,05 | 34 | Le Chat / API |
| Perplexity Sonar | 4,00 | 36 | Solo API |
| Qwen3 235B | 3,97 | 37 | chat.qwen.ai |
| Alice AI LLM (Yandex) | 3,86 | 38 | alice.yandex.ru |
Nivel 4: Por debajo del umbral de utilidad (< 3,80)
| Modelo | Puntuacion | Ranking global |
|---|---|---|
| Gemma 3 27B | 3,75 | 39 |
| Qwen3 32B | 3,67 | 40 |
| Gemma 3 12B | 3,58 | 41 |
| Gemma 3 4B | 3,27 | 42 |
| GigaChat-2-Max (Sber) | 3,08 | 44 |
| GigaChat-Max-preview | 3,05 | 46 |
| Llama 4 Maverick | 2,95 | 47 |
| GigaChat-Pro-preview | 2,90 | 48 |
| YandexGPT Pro 5.1 | 3,13 | 43 |
| YandexGPT Pro 5 | 2,85 | 49 |
| GigaChat-2-Pro | 2,82 | 50 |
| YandexGPT Lite | 2,61 | 51 |
| Phi-4 | 2,27 | 52 |
La brecha entre niveles es significativa. El Nivel 1 es un solido “A–”. El Nivel 4 – modelos donde los errores y las respuestas superficiales aparecen con mas frecuencia que las utiles.
Contexto global: la brecha se reduce
El top 5 mundial esta formado por modelos bloqueados en Rusia:
| Modelo | Puntuacion | Acceso en Rusia |
|---|---|---|
| GPT-5.4 (OpenAI) | 4,80 | Requiere VPN |
| GPT-5.2 Pro (OpenAI) | 4,78 | Requiere VPN |
| Claude Sonnet 4.5 (Anthropic) | 4,78 | Requiere VPN |
| Claude Opus 4.5 (Anthropic) | 4,78 | Requiere VPN |
| Claude Sonnet 4.6 (Anthropic) | 4,77 | Requiere VPN |
Media del top 5 mundial: 4,78. Media del top 5 en Rusia (Kimi, MiniMax M2.7, Qwen3.5 Plus, Qwen3.5 397B, GLM-5): 4,61.
La brecha: 0,17 puntos. Hace tres meses, cuando publicamos este articulo por primera vez, la brecha era de 0,42. Se ha reducido a mas de la mitad – no porque el top mundial haya empeorado, sino porque modelos genuinamente fuertes se hicieron accesibles en Rusia.
Kimi K2.5 con 4,74 le pisa los talones a Claude Sonnet 4.6 (4,77). Esto ya no es “B+ contra A–”. Se parece mas a “A– contra A”.
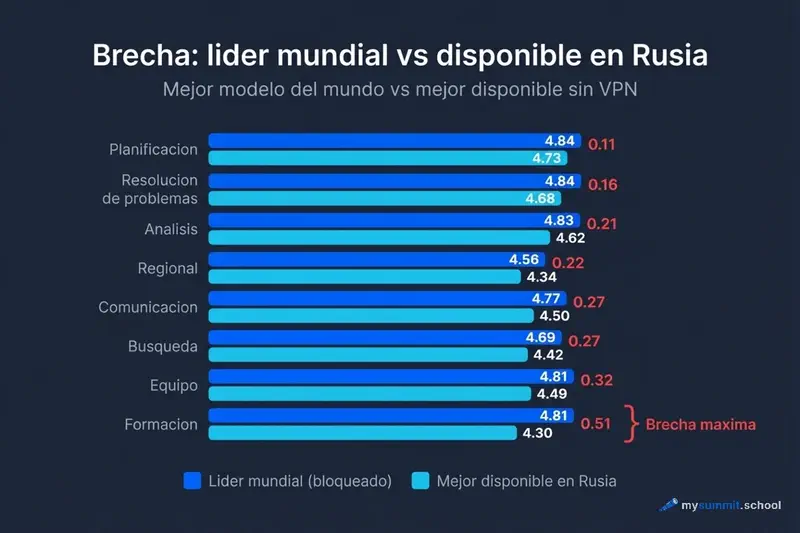
Como manejan las distintas tareas los modelos accesibles
Que significan las categorias: Investigacion – verificacion de datos, recopilacion de informacion, comparacion de fuentes. Comunicacion – correos empresariales, feedback, mensajeria de equipo. Analisis – interpretacion de datos, conclusiones de informes, evaluacion de riesgos. Planificacion – creacion de planes, agendas de reuniones, priorizacion de tareas. Resolucion de problemas – analisis de fallos, identificacion de causas raiz, gestion de crisis. Formacion – planes de desarrollo, conversaciones de carrera, materiales formativos. Equipo – gestion de personas, conflictos, motivacion, evaluaciones de desempeno. Regional – conocimiento de legislacion rusa, matices culturales, practicas locales.
| Categoria | Lider mundial | Punt. | Mejor en Rusia | Punt. | Brecha |
|---|---|---|---|---|---|
| Investigacion de informacion | GPT-5.2 Pro | 4,69 | Kimi K2.5 | 4,64 | 0,05 |
| Comunicacion | GPT-5 Mini | 4,78 | MiniMax M2.7 | 4,67 | 0,11 |
| Analisis y decisiones | Claude Sonnet 4.5 | 4,83 | Qwen3.5 397B | 4,78 | 0,05 |
| Planificacion | Claude Sonnet 4.5 | 4,84 | Qwen3.5 Plus | 4,83 | 0,01 |
| Resolucion de problemas | Claude Sonnet 4.5 | 4,84 | MiMo V2 Omni | 4,81 | 0,03 |
| Formacion y desarrollo | Claude Sonnet 4.6 | 4,83 | MiMo V2 Omni | 4,83 | 0,00 |
| Gestion de equipos | GPT-5.4 | 4,84 | MiMo V2 Omni | 4,84 | 0,00 |
| Especificidades regionales | GPT-5.4 | 4,61 | MiniMax M2.7 | 4,50 | 0,11 |
Hace tres meses, la brecha maxima era de 0,51 puntos (formacion). Ahora ninguna categoria tiene una brecha superior a 0,11. En tres categorias – resolucion de problemas, formacion, gestion de equipos – los modelos accesibles desde Rusia han igualado al top mundial.
Este es un cambio cualitativo. Antes la pregunta era “cuanto vamos por detras?” Ahora, para muchas tareas, la respuesta es “no vamos por detras”.
Como usar estos modelos de forma sistematica? Consulte el programa del curso
10 уроков: встраиваете ИИ в планирование, отчётность и кризисное реагирование. Результат – не промпты, а рабочая система.
Kimi K2.5: el lider inesperado
Kimi K2.5 de Moonshot AI es el gran descubrimiento del ranking actualizado. 6.o a nivel mundial con una puntuacion de 4,74, superando a GPT-5.2 (4,69), GPT-5 Mini (4,69) y Claude Haiku 4.5 (4,57).
Fortalezas de Kimi:
- Investigacion de informacion (4,64) – 2.o a nivel mundial tras GPT-5.2 Pro. Agent Swarm lanza decenas de sub-tareas paralelas para la recopilacion de datos
- Resolucion de problemas (4,78) – a la par con Claude Sonnet 4.5
- Consistencia – ninguna categoria por debajo de 4,38
Debilidades:
- El idioma ruso es notablemente mas debil que el ingles – Kimi a veces cambia al ingles o da respuestas menos estructuradas con prompts en ruso
- Velocidad en modo Thinking – 29 segundos por respuesta frente a 5 segundos de Claude Sonnet 4.6
- Se requiere tarjeta de credito extranjera para el nivel de pago
Resena completa – en la resena de Kimi K2.5.
Qwen3.5: la revolucion silenciosa de Alibaba
Qwen3.5 Plus (13.o, 4,56) y Qwen3.5 397B (14.o, 4,55) – dos variantes de la misma familia, ambas con acceso directo desde Rusia via chat.qwen.ai.
Que distingue a Qwen3.5:
- Planificacion – 4,83 para Plus, 4,82 para 397B. El mejor resultado entre todos los modelos accesibles y 3.o a nivel mundial
- Analisis – 4,78 para 397B. 2.o a nivel mundial tras Claude Sonnet 4.5
- Precios de API – $0,26 por millon de tokens de entrada para Plus. Eso es 10 veces mas barato que Kimi y 60 veces mas barato que Claude
Debilidad – formacion y desarrollo (4,22–4,30). Para tareas de RRHH, Kimi o MiMo V2 Omni son mejores opciones.
La paradoja de los modelos rusos: Yandex y Sber
YandexGPT
Alice AI LLM obtuvo 3,86 – puesto 38 de 52. Eso es Nivel 3. Por debajo de Kimi, Qwen, GLM-5, DeepSeek, Mistral, MiniMax e incluso MiMo v2 Flash de Xiaomi.
La categoria de “especificidades regionales” es reveladora – tareas que involucran leyes rusas, regulaciones y contexto cultural. Alice obtiene 3,68. Kimi K2.5 – 4,38. DeepSeek V3.2 – 4,34.
El punto mas debil de Alice es formacion y desarrollo: 2,70. Para comparar: DeepSeek V3.2 en la misma categoria – 4,30. MiMo V2 Omni – 4,83.
Los demas modelos de Yandex – YandexGPT Pro 5.1 (3,13), Pro 5 (2,85), Lite (2,61) – estan por debajo del umbral de utilidad practica.
Mas detalles en la resena de YandexGPT.
GigaChat
En el estudio actualizado, anadimos cuatro modelos de Sber. Los resultados son decepcionantes:
| Modelo | Puntuacion | Ranking | Coste API ($/1M tokens) |
|---|---|---|---|
| GigaChat-2-Max | 3,08 | 44 | $7,22 / $7,22 |
| GigaChat-Max-preview | 3,05 | 46 | $7,22 / $7,22 |
| GigaChat-Pro-preview | 2,90 | 48 | $5,56 / $5,56 |
| GigaChat-2-Pro | 2,82 | 50 | $5,56 / $5,56 |
Los modelos de GigaChat son los mas caros del estudio con las puntuaciones mas bajas. DeepSeek V3.2 a $0,27/$1,10 por millon de tokens obtiene 4,42 – 1,4 veces mas alto a un coste 20 veces menor. Mas en la resena de GigaChat.
Chat vs. API: que esta disponible sin conocimientos tecnicos
La mayoria de los directivos usan interfaces de chat, no APIs. Esto es lo que esta disponible “con un clic”:
Interfaces de chat gratuitas:
- Kimi K2.5 – kimi.com. Mejor resultado global entre los modelos accesibles. Nivel gratuito con limites
- Qwen3.5 – chat.qwen.ai. Mejor modelo para planificacion y analitica
- GLM-5 – chat.z.ai. Mejor modelo para gestion de equipos
- DeepSeek – chat.deepseek.com. Mejor modelo para contexto ruso entre los chats gratuitos
- Mistral – chat.mistral.ai. Buena alternativa para contexto europeo
- YandexGPT/Alice – alice.yandex.ru. Gratuito y comodo, pero puesto 38 de 52
Solo API (para desarrolladores):
- MiniMax M2.7 (7.o a nivel mundial) – sin chat, pero excelentes resultados
- MiMo V2 Omni (11.o) – lider en formacion y gestion de equipos
- Nemotron 3 Super (16.o) – API gratuita de NVIDIA
Estrategia de uso: que modelo para que tarea
Ningun modelo lidera en todas las categorias. La estrategia optima es usar diferentes modelos para diferentes tareas:
| Tarea | Mejor modelo accesible | Punt. |
|---|---|---|
| Planificacion de proyectos | Qwen3.5 Plus | 4,83 |
| Analisis de datos e informes | Qwen3.5 397B | 4,78 |
| Resolucion de problemas | MiMo V2 Omni | 4,81 |
| Correos y comunicacion | MiniMax M2.7 | 4,67 |
| Investigacion de informacion | Kimi K2.5 | 4,64 |
| Formacion y desarrollo de empleados | MiMo V2 Omni | 4,83 |
| Gestion de equipos | MiMo V2 Omni | 4,84 |
| Especificidades regionales rusas | MiniMax M2.7 | 4,50 |
Si hay que elegir un solo modelo para todo – Kimi K2.5. Tiene el perfil mas equilibrado: puntuacion minima 4,38 (regional), maxima 4,78 (analisis). Una variacion de solo 0,40 – la mejor metrica de consistencia.
Si necesitas un chat gratuito con acceso directo – Qwen3.5 Plus. El modelo mas potente a coste cero.
Este enfoque – usar la IA como copiloto con diferentes niveles de herramientas – se cubre en detalle en nuestra comparativa completa de herramientas GenAI.
Coste: la cuestion es basicamente irrelevante
Calculo aproximado para 1000 peticiones API al mes:
| Estrategia | Coste/mes |
|---|---|
| Solo DeepSeek V3.2 | ~$0,40 |
| Solo Qwen3.5 Plus | ~$0,50 |
| 80% MiMo v2 Flash + 20% Kimi K2.5 | ~$0,24 |
| Solo Kimi K2.5 | ~$0,80 |
| Nemotron 3 Super (NVIDIA) | gratis |
Menos de un dolar al mes por IA en el top 15 mundial. El coste ya no es un factor de seleccion – elige por calidad.
Advertencias importantes
Los modelos se actualizan rapido. Desde que comenzo el estudio (enero de 2026), se han anadido Qwen3.5, Kimi K2.5, MiniMax M2.7, GigaChat-2 y otros. Anadimos nuevos modelos a medida que se lanzan, pero cualquier instantanea siempre va unas semanas por detras de la realidad.
API != chat. El estudio se realizo via API con prompts estandar. La experiencia real del chat puede diferir – diferentes system prompts, contexto, modos de funcionamiento.
Usuario ingenuo. Todos los prompts se compusieron sin optimizacion. Si sabes trabajar con IA – tus resultados seran mejores en todos los modelos.
OpenRouter – zona gris. Los modelos accesibles via OpenRouter (Kimi, MiniMax, GPT-5.4 Mini, Claude Sonnet 4.0) tecnicamente funcionan desde Rusia, pero no es acceso directo al proveedor. La estabilidad y las condiciones pueden cambiar.
Conclusion
En tres meses, el panorama ha cambiado radicalmente. La brecha entre el top mundial y los mejores modelos accesibles desde Rusia se ha reducido de 0,42 a 0,17 puntos. En tres de ocho categorias, no hay brecha alguna.
Kimi K2.5 es el nuevo lider entre los modelos accesibles. Qwen3.5 es la mejor solucion gratuita con acceso directo. DeepSeek V3.2 sigue siendo la mejor opcion para tareas que implican contexto ruso.
Mientras tanto, YandexGPT y GigaChat se situan en la parte baja del ranking. La paradoja: la mejor IA para un directivo de habla rusa en 2026 es un modelo chino. Las soluciones rusas no van por detras por porcentajes, sino por multiplos en la relacion precio-calidad.
Domine la IA de forma sistematica
Que herramienta para que tarea, como evitar alucinaciones, como construir un flujo de trabajo eficaz – todo esta en el programa del curso.

Stanislav Belyaev
Engineering Leader en Microsoft18 anos liderando equipos de ingenieria. Fundador de mysummit.school. 700+ graduados en Yandex Practicum y Stratoplan.