40 casos de GigaChat: contrastamos las cifras de Sber con un benchmark

AI-модели в этой статье
Sber, el mayor banco de Rusia y dueño del modelo GigaChat, lanzó un especial publicitario: cuarenta casos de empresas que adoptaron GigaChat y cuentan los resultados. EdTech, MedTech, HRTech, ciberseguridad, PropTech. Tarjetas bonitas, cifras concretas, startups reales.

En la imagen: la diapositiva «Un paso por delante» de la aceleradora Sber500×GigaChat – 40 startups en 9 sectores. Efectos declarados: procesos hasta x16 más rápidos, costes hasta un 90 % menores, automatización de tareas hasta el 95 %, ingresos hasta un 30 % mayores.
Nosotros tenemos un benchmark: 29 modelos, 4308 evaluaciones independientes sobre tareas de gestión. GigaChat ocupa el último puesto, el 29, tras la segunda ola de pruebas. Eso crea una situación interesante.
No porque Sber mienta. Los casos son reales, las startups existen, la automatización funciona. La pregunta es otra: ¿era el modelo óptimo para las tareas que estaban resolviendo?
De dónde salen estos casos
El material de Sber pertenece a un género con nombre propio: el vendor-sponsored case study. Una empresa cuenta sus éxitos con una herramienta concreta, el proveedor lo publica y lo promociona. Es una práctica normal – así trabajan todas las grandes empresas de IA, de Microsoft a Anthropic.
El problema es que un caso de proveedor responde a la pregunta «¿funciona la solución?» – pero no a la pregunta «¿es la solución óptima?». Una empresa que montó un chatbot sobre GigaChat y ahorró un 40 % del tiempo de sus operadores describe honestamente el resultado. Pero no hizo un test A/B contra Qwen 3.6 Flash – porque ninguna empresa real organiza una licitación completa entre todos los modelos antes de cada proyecto.
Justo por eso existen los benchmarks independientes.
Qué muestra nuestro benchmark
Probamos los modelos de IA en ocho categorías de tareas de gestión – desde el análisis de datos y la búsqueda de información hasta la planificación y el trabajo en equipo. Metodología: dos jueces LLM independientes con calibración humana. En detalle, cómo funcionan los benchmarks y por qué hay que confiar en ellos con matices.
Sber tiene ahora dos líneas principales: GigaChat 2 Max y GigaChat Ultra. No conviene confundirlas – son modelos distintos con niveles de calidad distintos.
El buque insignia es GigaChat Ultra. Su API está disponible para clientes corporativos mediante contrato aparte; para desarrolladores individuales, solo a través de la interfaz web gigachat.ru. En nuestro benchmark quedó en el puesto 28 de 29 con una nota de 4,83 – el mejor resultado entre todos los modelos rusos de nuestra prueba.
El modelo principal con API pública es GigaChat 2 Max, y es justamente el que usa la mayoría de las startups de los casos. Puesto 29 de 29, nota 4,20. En la primera ola ese mismo modelo sacaba 3,08 – el progreso en unos pocos meses es notable.
Esta distinción importa. La mayoría de las startups de los casos trabaja a través de la API pública – es decir, con GigaChat 2 Max. Quienes obtuvieron acceso corporativo a Ultra trabajan con un modelo más potente – pero también por otro precio. Veamos cómo se desenvuelve exactamente GigaChat 2 Max con las tareas de los casos.
| Categoría de tareas | GigaChat 2 Max | GigaChat Ultra |
|---|---|---|
| Búsqueda de información | 29 / 29 (3,87) | 28 / 29 (4,71) |
| Análisis y decisiones | 29 / 29 (4,39) | 28 / 29 (5,44) |
| Planificación | 29 / 29 (4,33) | 28 / 29 (5,92) |
| Resolución de problemas | 28 / 29 (4,27) | 29 / 29 (4,25) |
| Conocimiento regional | 29 / 29 (3,57) | 28 / 29 (3,98) |
| Comunicación | 28 / 29 (4,74) | 29 / 29 (4,74) |
| Trabajo en equipo | 29 / 29 (4,41) | 28 / 29 (5,16) |
| Formación y desarrollo | 29 / 29 (4,00) | 28 / 29 (4,48) |
Ambos modelos de Sber ocupan los dos últimos puestos del benchmark, pero la brecha de puntos entre ellos es perceptible: Ultra saca 5,92 en planificación, Max 4,33. Ultra solo está disponible vía API para clientes corporativos, y Max a través de la API pública. La mayoría de las startups de los casos trabaja con Max.
Cuarenta casos: qué tareas son
Leí las cuarenta tarjetas. Las tareas se agrupan en varias líneas.
Cerca de un tercio son chatbots y procesamiento de consultas entrantes. Una aseguradora automatizó las respuestas a sus clientes, un servicio médico creó un asistente para reservar citas, un banco implantó un ayudante de soporte. Es una tarea real y viable para cualquier LLM suficientemente capaz.
Otro grupo importante es la generación de texto y documentos: materiales de marketing, descripciones de inmuebles, documentación de RR. HH. Una empresa de HRTech automatizó la creación de descripciones de puestos, una startup de PropTech las descripciones de pisos, una plataforma de MarTech los textos publicitarios para distintos segmentos.
A partir de aquí empieza el terreno donde los datos del benchmark plantean preguntas. Análisis de documentos y datos – cribado de currículums, documentos médicos, clasificación de consultas. Varios casos sobre ciberseguridad: análisis de amenazas, clasificación de incidentes, generación de informes. Y, por separado, tareas sectoriales específicas como un asistente de IA para entrevistas de RR. HH. o sistemas de recomendación para EdTech.
Dónde los datos del benchmark contradicen al marketing
Tomemos tres casos de categorías distintas y mirémoslos a través de los datos.
Uno de los casos de EdTech es la automatización del análisis de casos clínicos para formar a estudiantes de medicina. La tarea exige precisión en los hechos, referencias correctas a las fuentes y ausencia de alucinaciones.
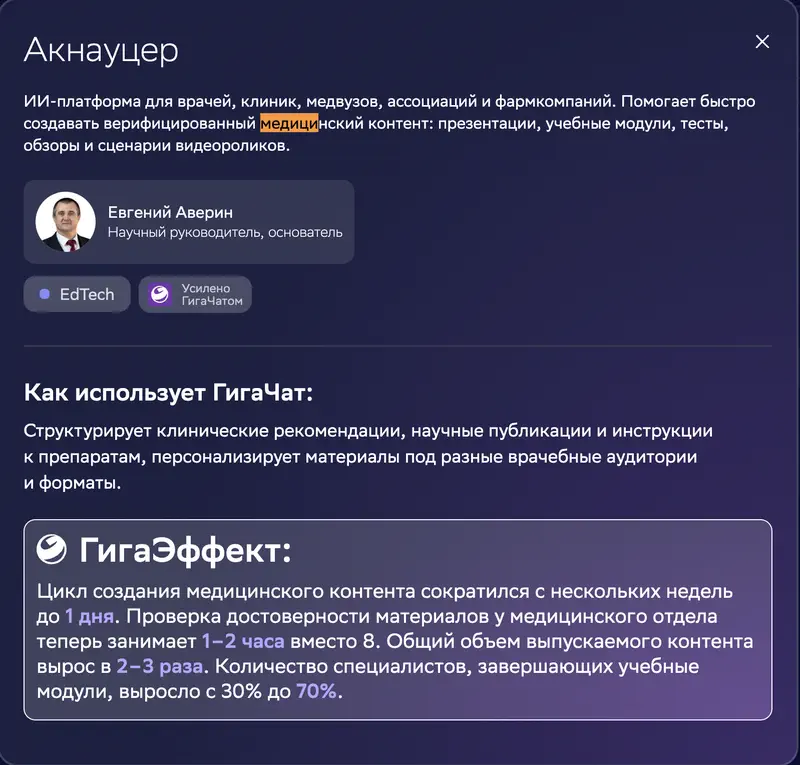
En la ficha del caso: Aknaucer, una plataforma de IA para medicina. «GigaEfecto» declarado: el ciclo de creación de contenido se redujo de varias semanas a 1 día, la verificación de datos de 8 horas a 1–2, el volumen producido se multiplicó por 2–3 y la proporción de especialistas que completan los módulos formativos subió del 30 % al 70 %.
Nuestro benchmark en la categoría «búsqueda de información»: GigaChat 2 Max en el último puesto, el 29 de 29. La debilidad concreta de la descripción: «da con la dirección correcta del análisis, pero se inventa precios de herramientas, referencias a estudios y normas jurídicas – usarlo sin verificar cada dato es peligroso».
El caso es perfectamente real. Pero una empresa que no verifica cada conclusión del modelo está trabajando con el modelo que ocupa el último puesto en precisión de los 29 disponibles.
Varias empresas de MarTech describen la automatización de la generación de materiales publicitarios. Comunicación – puesto 28 de 29, la categoría menos débil de GigaChat. Para textos sencillos de plantilla puede bastar.
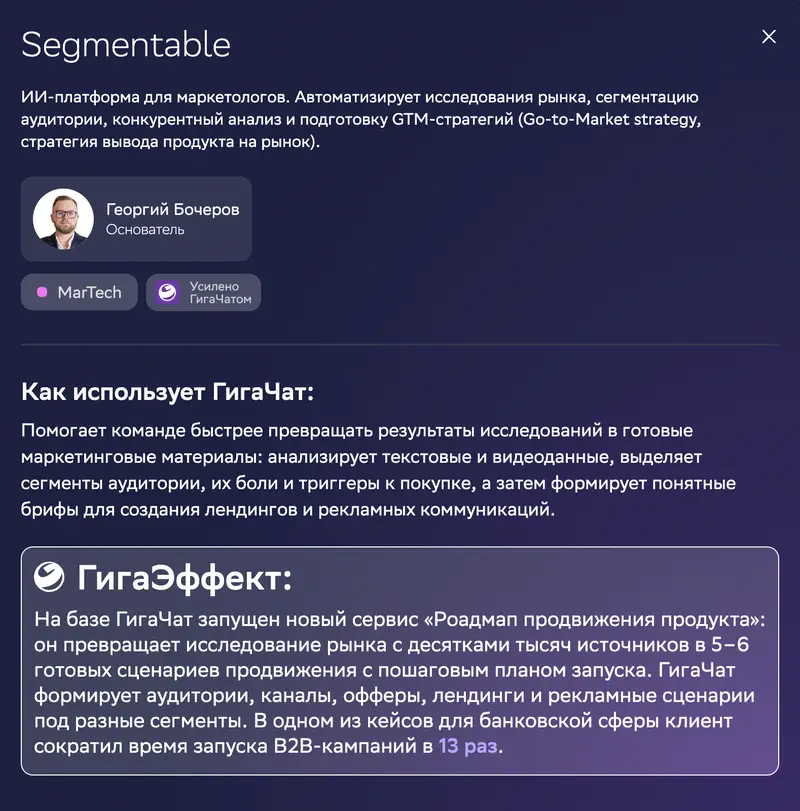
En la ficha del caso: Segmentable, una plataforma de IA para marketing. «GigaEfecto» declarado: su servicio «hoja de ruta de promoción de producto» convierte un estudio de mercado con decenas de miles de fuentes en 5–6 escenarios de lanzamiento listos, y en un caso bancario el cliente redujo el tiempo de lanzamiento de campañas B2B 13 veces.
Más interesante es el caso de la ciberseguridad. Uno de los ejemplos es un sistema para clasificar incidentes de seguridad de la información y generar informes de amenazas. La tarea supone un análisis preciso, conclusiones concretas y recomendaciones aplicables.
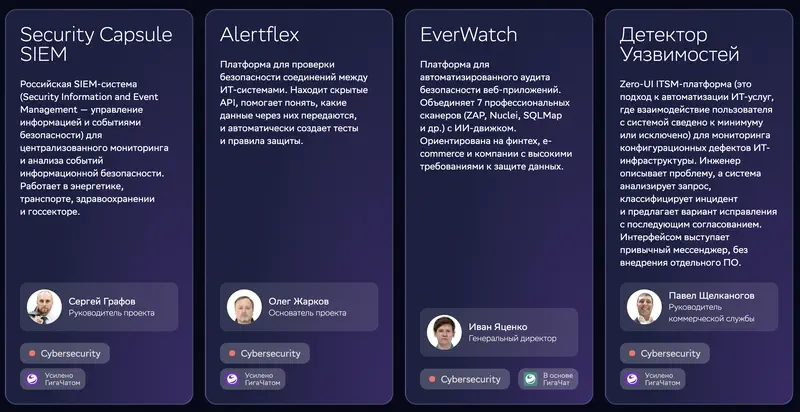
En la imagen: cuatro productos de ciberseguridad basados en GigaChat. Security Capsule SIEM – un SIEM ruso para la supervisión centralizada de la seguridad; Alertflex – revisa el intercambio de datos entre sistemas informáticos vía API y genera reglas de protección automáticamente; EverWatch – auditoría automatizada de aplicaciones web que combina 7 escáneres (ZAP, Nuclei, SQLMap) con un motor de IA; Detector de Vulnerabilidades – una plataforma ITSM Zero-UI donde el ingeniero describe un problema en un mensajero y el sistema clasifica el incidente y propone una corrección.
Nuestro benchmark en las categorías «análisis y decisiones» y «resolución de problemas»: puestos 29 y 28 de 29. Descripción: «identifica bien la dirección general de la solución, pero no aporta criterios ponderados, ni análisis de escenarios, ni recomendaciones concretas – en esencia, reformula el enunciado del problema».
Un informe de clasificación de incidentes escrito por el modelo que ocupa el puesto 29 en analítica de los 29 disponibles es automatización de la redacción de un documento. El análisis de amenazas sigue recayendo en el humano. La diferencia es significativa.
La paradoja de la evaluación absoluta y la competitiva
Aquí hay un matiz que conviene entender, porque es contraintuitivo.
GigaChat 2 Max saca 4,20 sobre 10 – por debajo de la mitad de la escala. Pero incluso la nota absoluta transmite mal la competitividad real. Nuestro experimento con técnicas de prompting demostró que ni las mejores técnicas cierran la brecha entre un modelo débil y uno fuerte. GigaChat y Alice con prompts óptimos seguían perdiendo frente a GPT-5.4 y Claude con consultas ingenuas. La versión v2 mejoró – pero el principio se mantiene: la nota absoluta infla la competitividad.
Analizamos este efecto en detalle en el artículo «Por qué mienten los benchmarks de IA». Las notas de la escala se acumulan cerca del valor medio, y una pequeña diferencia de puntos equivale a una gran diferencia en frecuencia de victoria. Cuando Qwen 3.6 Flash saca 7,60 en nuestro benchmark frente al 4,20 de GigaChat 2 Max – no se trata de «un 80 % mejor». Se trata de que, en comparación directa, Qwen gana la inmensa mayoría de las veces.
Por eso «funciona» y «óptimo» son cosas distintas.
Evaluar resultados en tareas reales, entender cuándo un resultado es bueno y cuándo solo lo parece – a eso está dedicado el módulo abierto del curso. Nueve escenarios de gestión, cada uno con una trampa nada evidente, sin registro.
En los 40 casos de Sber no hay ningún test A/B con modelos alternativos. En el módulo abierto hay 9 tareas donde tú mismo evalúas los resultados y aprendes a distinguir 'funciona' de 'óptimo'. Gratis.
Sin pago requerido • Notificación al lanzamiento
Un caso bajo el microscopio: ESME AI y la documentación de proyecto
Las notas abstractas del benchmark no muestran cómo se ve exactamente la diferencia entre modelos. Uno de los cuarenta casos permite verlo – y, de paso, analizar dónde los datos del benchmark se aplican directamente y dónde hay que leerlos con cuidado.
ESME AI es una herramienta para promotoras y contratistas generales. Una plataforma de captura 360° de obras con un asistente de IA integrado. GigaChat ayuda a trabajar con la documentación de proyecto y de obra: el usuario pregunta en lenguaje natural y el asistente encuentra la información en planos, especificaciones y normativa. Efecto declarado: «la búsqueda de información del proyecto pasó de decenas de minutos a unos pocos, y la toma de decisiones se aceleró un 30–50 %».
La tarea es real. Quien haya pisado una obra conoce ese dolor: un proyecto medio son cientos, a veces miles de hojas por disciplinas (arquitectura, estructura, climatización, fontanería, electricidad), más las especificaciones, las mediciones, los datos generales y la capa normativa (códigos técnicos, normas UNE). La pregunta «¿qué clase de hormigón lleva el forjado de la 3.ª planta?» son diez o cuarenta minutos pasando hojas. Recortar «de decenas de minutos a unos pocos» es verosímil – si la búsqueda funciona de verdad.
Por qué el benchmark aquí es un proxy débil
Aquí hay que ser honesto con los propios datos. Nuestro benchmark mide razonamiento de gestión: analizar una situación, planificar, concluir. La búsqueda en documentación funciona de otra manera. Es una tarea de tipo RAG (retrieval-augmented generation): el sistema extrae primero el fragmento relevante de un PDF real del proyecto, y el modelo saca la respuesta de ahí – no de la «memoria» acumulada durante el entrenamiento.
Eso cambia el panorama. La debilidad característica de GigaChat – «se inventa referencias a estudios y normas jurídicas» – es un fallo de generación a partir de datos aprendidos. Cuando el modelo responde estrictamente según el fragmento de plano adjunto, ese fallo se reprime. Por eso el puesto 29 en «búsqueda de información» es un proxy débil para la pregunta «¿encontrará el asistente la clase de hormigón correcta?». Sobre un RAG bien construido, incluso un modelo débil se comporta de forma más aceptable que en generación libre.
Qué rompe de verdad esta automatización
El problema es que, para la documentación de obra, los riesgos principales no están donde los mide el benchmark – y parte de ellos son más peligrosos que las alucinaciones habituales.
Lo primero que rompe un sistema así en la práctica es la propia lectura del plano. Los planos son PDF vectoriales o DWG: texto en cajetines, llamadas, líneas de cota, rayados y tablas embebidas. Los sistemas de reconocimiento genéricos tropiezan aquí, y si el parseo falla – el modelo responde con aplomo sobre un texto corrupto. Las especificaciones y mediciones son tablas de varias páginas con celdas combinadas, y la mayoría de los errores de «valor equivocado» nacen justo aquí, no en las alucinaciones.
Además, la respuesta rara vez está en una sola hoja. «La clase de hormigón del forjado de la 3.ª planta» es un encadenamiento: planta -> sección -> especificación -> instrucciones generales en las hojas de estructura, a veces una hoja aparte. Para componer la respuesta hay que recorrer documentos heterogéneos. Justo aquí el asistente devuelve en silencio un valor verosímil pero incorrecto.
Hay otro riesgo menos evidente – el versionado. La documentación cambia: revisiones, modificaciones, sellos de «apto para construcción», líneas rojas. Si en el índice entró una revisión obsoleta, el asistente soltará con aplomo un valor anulado – con referencia a una hoja real, pero antigua. Eso es más peligroso que una alucinación: parece autorizado y verificable.
Por último, el coste del error y la trazabilidad. Un ingeniero no puede actuar sobre la respuesta «B25» sin la referencia al tomo, la hoja y la posición de la especificación. Un error en la clase del hormigón o de la armadura significa un defecto estructural. Y si el asistente no convierte la verificación en una mirada de tres segundos a la fuente, el ahorro de tiempo se evapora: para fiarte de la respuesta tendrás que encontrar igualmente la fuente primaria a mano.
Dónde el benchmark sí es relevante
La tarea de ESME tiene dos capas. La primera es la extracción del dato: eso depende de la calidad del pipeline, ver arriba. La segunda es el análisis y la síntesis: «evalúa los riesgos de este nudo», «compara dos variantes de solución». Aquí la diferencia entre clases de modelo se ve directamente, y el benchmark la captura.
No tenemos acceso a los prompts concretos de ESME AI, pero la capa analítica de una tarea así es exactamente lo que probamos en el experimento con técnicas de prompting. Tomemos un escenario comparable – análisis de negocio a partir de datos concretos.
La tarea del experimento:
Una tienda online de electrónica, 45 empleados. En el último trimestre los ingresos cayeron un 18 %, mientras que el tráfico al sitio subió un 12 %. El ticket medio bajó de 8700 a 6200 rublos. Las devoluciones pasaron del 4 % al 11 %. El presupuesto de publicidad se aumentó un 30 %. ¿Qué está pasando y qué hacer?
Todos los modelos recibieron el mismo prompt, sin ninguna técnica.
GigaChat 2 Max (puesto 29, nota 3,02) soltó 53 líneas de texto. Seis «causas posibles», seis bloques de recomendaciones: «realizar un análisis de la calidad del producto», «mejorar la logística y la entrega», «elevar la cualificación de los empleados». No hay ni una sola cifra del enunciado en el análisis. No hay priorización. Conclusión: «es necesario abordar el problema de forma integral».
Para ESME AI esto significa: en la capa analítica, el modelo dirá «hay que revisar la especificación», pero difícilmente jerarquizará prioridades ni sacará una conclusión sustancial de lo encontrado.
Alice AI LLM (YandexGPT, nota 3,85) lo hizo claramente mejor: apareció estructura – «análisis ABC del surtido», «monitorización de precios», «test de usabilidad del embudo», un bloque de «prioridades a corto plazo para 2 semanas». Pero la priorización es plana y el cronograma de crisis no está desarrollado.
GPT-5.4 (1.er puesto, nota 4,38) empezó distinto – con un cálculo: «el ticket medio cayó alrededor de un 29 %». El modelo calculó, no reformuló el enunciado. Después: un plan de crisis a 10 días con roles para cada una de las 45 personas, hipótesis ordenadas y una lista de acciones «para mañana por la mañana».
Tres niveles – tres clases de resultado:
| Modelo | ¿Calcula las cifras del enunciado? | ¿Prioriza hipótesis? | ¿Da un plan operativo? | Precisión factual |
|---|---|---|---|---|
| GigaChat 2 Max | No | No | Consejos genéricos | 58,9 % |
| Alice AI LLM | En parte | No | Prioridades, pero sin cronograma | 75,0 % |
| GPT-5.4 | Sí (caída del 29 % en el ticket) | Sí (por probabilidad) | Plan a 10 días con roles | 83,9 % |
La precisión factual de la tabla viene del experimento de análisis de negocio, donde el modelo genera la respuesta por sí mismo, sin documentos adjuntos. Eso no significa que el asistente de ESME vaya a fallar en el 41 % de las consultas a los planos: en una búsqueda grounded con citas el panorama es distinto. Pero la cifra indica la clase. Allí donde «análisis de documentación» significa no solo encontrar una línea, sino calcular, priorizar y componer una conclusión, GigaChat 2 Max se queda en el nivel de los consejos genéricos.
En comparación directa dentro del experimento, GigaChat 2 Max con la mejor técnica de prompting ganaba a GPT-5.4 solo en el 4 % de los casos. Alice AI LLM – en el 28–36 %. Con un 4 % de victorias, la brecha ya no está en los matices, sino en la clase de tareas que el modelo es capaz de resolver.
Cambiar de modelo aquí merece la pena: ambas alternativas rusas – Alice AI LLM y DeepSeek V4 Flash – están disponibles en Yandex Cloud para empresas rusas. DeepSeek V4 Flash ocupa el puesto 12 en nuestro benchmark (7,34 puntos) y cuesta 0,20 / 0,60 $ por millón de tokens – 12 veces más barato que GigaChat y con una calidad notablemente superior. Pero seamos honestos: cambiar de modelo arregla la capa analítica y reduce las alucinaciones, pero los riesgos principales de la construcción – parseo de planos, versionado, trazabilidad – viven en el pipeline, y ningún modelo los va a cerrar.
Cómo hacer fiable un asistente así
Si se construye este producto en serio, el orden de prioridades es más o menos este.
El mayor salto de fiabilidad es estructurar los datos en lugar de buscar en el PDF. Parsear una sola vez las especificaciones y mediciones a una base verificada por humanos (elemento -> material -> clase -> hoja -> revisión). Entonces «la clase de hormigón del forjado de la 3.ª planta» se convierte en una consulta puntual a los datos, no en una búsqueda difusa por el texto.
Cada respuesta debe contener una cita: tomo, hoja, posición – y el fragmento de plano mostrado. La verificación se reduce a una mirada, y solo entonces el ahorro de tiempo es real.
Conviene separar la búsqueda de la generación. La extracción de fragmentos – con embeddings y un reranker; el modelo – solo en la extracción final de la respuesta, con una instrucción estricta: «responde estrictamente según el contexto; si no, di ’no encontrado’». Justo eso es lo que da sentido a elegir un modelo más potente.
Hace falta una capa de versiones: el asistente responde «según la revisión tal» y avisa si para esa hoja existe una más reciente.
Para consultas críticas – clase de hormigón, armadura, resistencia al fuego – el asistente debe tener derecho a decir «no lo sé»: o una cita exacta, o un rechazo. «No encontrado» es una feature, no un bug.
El activo único de ESME es la combinación de la captura 360° con la documentación. El paso de «buscar en los documentos» a «comparar el hecho (captura 360°) con el proyecto»: desviaciones, porcentaje de avance, defectos. Justo ese paso resuelve la tarea real del control de obra y va más allá de acelerar la búsqueda.
Y por último – probar con tus propios documentos. Cien consultas reales con respuestas contrastadas y la medición de tres métricas: exhaustividad de la búsqueda, precisión de las citas y proporción de revisiones obsoletas. Un benchmark genérico no le dirá a ESME si su pipeline es seguro – solo lo mostrará una prueba así.
Si no tienes elección: cómo mejorar el resultado de GigaChat
Supongamos que trabajas en una organización donde GigaChat es la única herramienta permitida. On-premise, contrato corporativo, requisitos de seguridad. ¿Qué se puede hacer?
Nuestro experimento con técnicas de prompting probó diez enfoques sobre GigaChat 2 Max – desde el encuadre por rol hasta el marcado XML y la cadena de razonamiento.
El mejor resultado lo dio la técnica n.º 4 – few-shot: 89 % de victorias sobre el prompt ingenuo. Tomas un ejemplo de respuesta de calidad a una tarea parecida (pero distinta) y lo añades al prompt antes de tu pregunta. El modelo se calibra con el ejemplo – y devuelve una respuesta estructurada y concreta en vez de frases genéricas.
En la misma tarea de la tienda online, GigaChat 2 Max con un ejemplo few-shot dio otro resultado: en lugar de enumerar seis categorías generales – un diagnóstico estructurado con referencias a las cifras concretas del enunciado («caída del ticket medio de 8700 a 6200 ₽»), un cronograma de recomendaciones (esta semana / 2–3 semanas / hasta un mes) y una sección de «Lo que aún no sabemos».
Datos de GigaChat 2 Max del experimento:
| Técnica | Nota (sobre 5) | Subida desde la base | Victorias vs prompt ingenuo |
|---|---|---|---|
| T0 (sin técnicas) | 3,02 | – | – |
| T4 (few-shot) | 3,63 | +20 % | 89 % |
| T2 (salida estructurada) | 3,43 | +14 % | 82 % |
| T10 (XML + Markdown) | 3,59 | +19 % | 78 % |
| T3 (cadena de razonamiento) | 3,55 | +18 % | 79 % |
Pero aquí va un matiz importante: GigaChat 2 Max con la mejor técnica (3,63) sigue por debajo de Qwen 3.6 Flash (7,60) o DeepSeek V4 Pro (7,75) sin ninguna técnica. El prompt engineering no cierra la brecha arquitectónica – hace que un modelo débil sea tolerable, pero no competitivo.
Queda la cuestión de la fuente del ejemplo. La vía más práctica: pasar una vez la tarea por un modelo fuerte (DeepSeek V4 Flash es gratuito en su interfaz web, Kimi K2.6 está disponible sin VPN), guardar el resultado y usarlo como ejemplo para GigaChat en tareas parecidas. Esto no es «copiar» – es calibrar.
Alternativas disponibles en el mercado ruso
Esta es quizá la parte más concreta del artículo. Si una empresa de los casos de Sber resuelve tareas de nuestra lista, ¿qué otros modelos tiene a su alcance – y qué dice el benchmark? La comparación detallada de herramientas por tareas está en la revisión de herramientas de GenAI para managers.
Todos los modelos de la lista funcionan sin VPN, están disponibles vía API y existen en el mercado ruso.
| Modelo | Puesto (de 29) | Nota | Coste (entrada/salida, $/M tokens) |
|---|---|---|---|
| MiMo v2.5 Pro | 3 | 8,37 | 1 / 3 $ |
| Kimi K2.6 | 5 | 8,27 | 0,74 / 3,49 $ |
| Qwen 3.6 Plus | 7 | 7,94 | 0,33 / 1,95 $ |
| MiMo v2.5 | 8 | 7,82 | 0,40 / 2 $ |
| DeepSeek V4 Pro | 10 | 7,75 | 0,43 / 0,87 $ |
| Qwen 3.6 Flash | 14 | 7,60 | 0,25 / 1,50 $ |
| MiniMax M2.7 | 15 | 7,58 | 0,30 / 1,20 $ |
| GigaChat 2 Max | 29 | 4,20 | 7,22 / 7,22 $ |
La diferencia de coste es un punto importante, y lo analizamos en el estudio sobre la ‘prima premium’ de los modelos de IA. GigaChat 2 Max cuesta 7,22 $ por millón de tokens tanto de entrada como de salida. Qwen 3.6 Flash – 0,25 $ de entrada y 1,50 $ de salida. Si una empresa tiene una carga punta de 10 millones de tokens de entrada y otros tantos de salida: GigaChat le costará unos 144 $, Qwen 3.6 Flash unos 17,50 $. Y eso que Qwen ocupa el puesto 14 frente al 29.
Lo barato por sí solo no es un argumento. GigaChat tiene una ventaja real – el despliegue on-premise. Para bancos, organismos públicos o empresas de defensa, donde los datos no pueden salir del perímetro – es la única opción. De ello hablamos en la guía práctica de GigaChat. Pero para las startups de los casos, que trabajan en la nube – la ventaja es irrelevante.
Cinco preguntas para cualquier proveedor de IA
Esto no va solo de Sber. Microsoft publica casos de Copilot, Anthropic casos de Claude, Google casos de Gemini. El formato es el mismo. Las preguntas también deberían serlo.
Empieza por lo más sencillo: ¿qué tarea exacta se automatizó – y pertenece a los puntos fuertes del modelo? Un chatbot para preguntas simples funciona en cualquier modelo. El análisis de documentos médicos o de riesgos jurídicos – ya no.
La segunda pregunta es sobre las métricas. «Reducimos el tiempo un 40 %» suena bien. Pero ¿un 40 % de qué? Si un operador tardaba 20 minutos en responder y ahora tarda 12 – el ahorro es real. Si el modelo entrega un borrador en 30 segundos pero el editor invierte 15 minutos en correcciones – la eficiencia es otra. ¿Y qué habría pasado sin IA?
¿Se hizo una prueba con modelos alternativos? Casi nunca. Es comprensible: la empresa resuelve un problema de negocio, no se dedica a comparar modelos. Pero la ausencia de test A/B significa que «GigaChat nos permitió» se lee con más rigor como «con GigaChat lo conseguimos» – sin afirmar que otros modelos lo habrían hecho peor.
Un tema aparte es la verificación. Si la tarea exige datos precisos (información factual, referencias jurídicas, conclusiones médicas) y no hay una revisión sistemática de cada conclusión – es un riesgo. La pregunta no es si el modelo alucina alguna vez. La pregunta es cuántos errores pasarán inadvertidos y cuál es su coste.
Y por último: ¿qué pasa en los casos límite? La mayoría de los productos de IA funcionan bien en consultas típicas. Lo interesante es el comportamiento en las atípicas – una región rara, una situación no estándar, un supuesto legal fronterizo. Justo aquí la brecha entre el puesto 3 y el 29 se manifiesta con más fuerza.
Pulsa «Ejecutar» y compara las respuestas. Fíjate en la concreción: ¿menciona el modelo estándares y métricas reales de seguridad, o se queda en frases genéricas? Justo aquí se ve la diferencia entre el puesto 5 y el 29 del benchmark.
Reconocimiento honesto: el progreso es real
GigaChat 2 Max en el último puesto – pero hay que entenderlo en perspectiva. En la primera ola de pruebas, la nota de esa misma línea era 3,08. Ahora – 4,20. Un crecimiento del 36 % en unos pocos meses es un progreso significativo en calidad, aunque la posición en el ranking siga siendo la última.
El trabajo de ingeniería de Sber se nota. Si el ritmo se mantiene – en uno o dos años GigaChat podría situarse en la mitad superior de la tabla. Es una pregunta abierta, y a los usuarios rusos les interesa que la respuesta sea afirmativa.
Las cuarenta startups de los casos también hacen un trabajo real. La automatización sobre GigaChat funciona para muchas de ellas. Para parte de las tareas – sobre todo las ligadas a la correspondencia comercial y a chatbots simples – la elección es razonable. Para otras, los datos del benchmark plantean la cuestión de la optimalidad.
Es posible que algunas eligieran GigaChat por razones no técnicas: ya tienen un contrato corporativo con Sber, requisitos de seguridad, presión de la dirección. También son consideraciones reales que el benchmark no recoge.
La pregunta es otra: al tomar la decisión técnica de elegir un modelo – ¿qué es lo que compruebas?
Distinguir «el modelo dio un resultado verosímil» de «el modelo dio un resultado correcto» es una destreza que solo se entrena sobre tareas concretas. Eso es justo lo que se trabaja en el módulo abierto del curso: nueve escenarios de gestión donde la brecha entre «suena convincente» y «es correcto» no es evidente.
Cuarenta casos sin test A/B son la norma del marketing de proveedor. En el módulo abierto entrenas la destreza de evaluar resultados sobre 9 tareas de gestión. Gratis, sin registro.
Sin pago requerido • Notificación al lanzamiento
Qué hacer con esta información
Si usas GigaChat – sobre todo en formato on-premise o Enterprise – esto no es un argumento para cambiar ahora mismo. Hay tareas donde el modelo funciona de forma aceptable. Hay situaciones donde no hay elección.
Lo útil es entender en qué tareas te apoyas en la precisión de GigaChat y qué nivel de verificación tienes incorporado. Nuestra revisión detallada de GigaChat y la prueba de GigaChat Ultra en modo Thinking muestran las situaciones concretas donde el modelo más se equivoca: búsqueda de información, normas jurídicas, datos regionales.
Si estás decidiendo qué modelo elegir para un proyecto nuevo – los datos del benchmark y las cinco preguntas de arriba te dan una estructura. El ranking completo de 29 modelos con desglose por categorías está en la página de nuestra investigación.
Si estás leyendo el siguiente caso de proveedor – da igual si es de Sber, Microsoft o Anthropic – hazle las mismas cinco preguntas. Sus respuestas no suelen estar en el texto del caso.
De los casos a la evaluación propia
El tercer capítulo del curso analiza ocho herramientas de IA con datos: qué sabe hacer cada una, dónde alucina y para qué tareas es óptima. Resultados de pruebas sobre tareas de gestión, no el resumen del marketing.


Stanislav Belyaev
Engineering Leader en Microsoft18 anos liderando equipos de ingenieria. Fundador de mysummit.school. 700+ graduados en Yandex Practicum y Stratoplan.