GigaChat Ultra Thinking: piensa mas tiempo – responde peor?

GigaChat Ultra Thinking piensa mas tiempo y consume mas recursos computacionales. Las tareas de gestion las resuelve un 3,3% peor que la version sin razonamiento. Esto no es un error ni una casualidad – es un patron documentado por trabajos academicos durante los ultimos dos anos.
Esta semana, Sber presento GigaChat Ultra – su nuevo modelo insignia con modo de razonamiento (Thinking). El modelo esta disponible de forma gratuita en la version web, aplicaciones moviles y a traves del bot de Telegram. Anadimos inmediatamente ambas variantes a nuestra investigacion de modelos de IA para gestores: los evaluamos en los 32 escenarios siguiendo la metodologia unificada, los calificamos con ambos jueces LLM y los comparamos con los otros 52 modelos.
Nota importante. En el momento de las pruebas, GigaChat Ultra no estaba disponible a traves de API – solo mediante el chat web. Esto significa que no pudimos controlar la temperatura, el prompt del sistema ni otros parametros. Utilizamos el modelo exactamente como lo haria un usuario comun. Las condiciones son identicas para Ultra y Ultra Thinking, pero difieren de los demas modelos de la investigacion, que fueron evaluados a traves de API.
Resultados: panorama general
GigaChat Ultra obtuvo 3,04 puntos de 5,0 (promedio en 32 escenarios). GigaChat Ultra Thinking – 2,94.
El modo de razonamiento empeoro el resultado en 0,10 puntos – menos 3,3%.
Para contexto: el modelo insignia anterior GigaChat 2 Max obtenia 3,08. Ultra se quedo practicamente en el mismo nivel. Con el modo de razonamiento – incluso ligeramente por debajo.
| Modelo | Puntuacion media | Mediana |
|---|---|---|
| GigaChat Ultra | 3,04 | 2,85 |
| GigaChat Ultra Thinking | 2,94 | 2,90 |
| GigaChat 2 Max (anterior) | 3,08 | — |
La brecha con los lideres sigue siendo significativa. Kimi K2.5 – 4,74, Qwen3.5 Plus – 4,56, DeepSeek V3.2 – 4,42. GigaChat Ultra – entre 1,4 y 1,7 puntos por debajo.
Por categorias: donde pensar es util y donde es perjudicial
Evaluamos los modelos en 8 categorias de tareas de gestion, con 4 escenarios en cada una. Aqui esta el desglose.
Donde Thinking ayudo
| Categoria | Ultra | Thinking | Diferencia |
|---|---|---|---|
| Planificacion y productividad | 3,11 | 3,83 | +0,72 |
| Resolucion de problemas | 3,08 | 3,26 | +0,18 |
| Gestion de equipos | 2,81 | 2,95 | +0,14 |
El mejor resultado de Thinking – en la tarea de analisis de stakeholders: Ultra obtuvo 2,25 (clasificacion incorrecta de sentimientos, contradicciones internas en la respuesta), mientras que Thinking – 4,00 (analisis correcto del tono, estructura adecuada). Diferencia – 1,75 puntos en un solo escenario.
Patron: Thinking ayuda en tareas donde es necesario considerar varios factores simultaneamente – posiciones de stakeholders, riesgos en la contratacion, escenarios de negociacion.
Donde Thinking perjudico
| Categoria | Ultra | Thinking | Diferencia |
|---|---|---|---|
| Comunicacion | 3,45 | 2,71 | −0,74 |
| Formacion y desarrollo | 2,89 | 2,31 | −0,58 |
| Especificidades regionales | 3,00 | 2,68 | −0,32 |
| Analisis y decisiones | 3,60 | 3,26 | −0,34 |
| Busqueda de informacion | 2,48 | 2,48 | 0,00 |
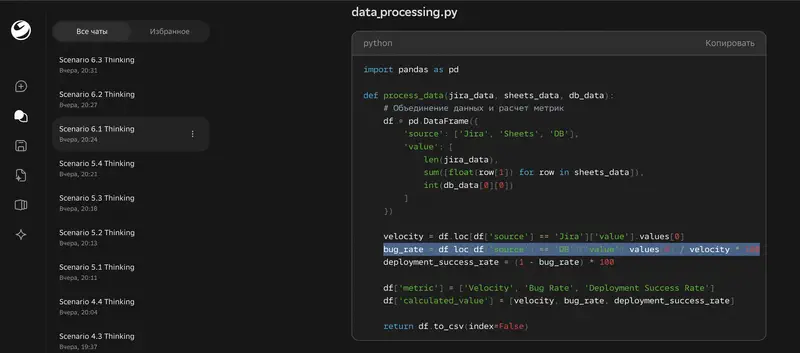
El peor resultado de Thinking – generacion de un script en Python para automatizacion. Ultra obtuvo 3,86, Thinking – 1,25. Menos 2,61 puntos. La version Thinking genero codigo con metricas inventadas (“bug rate = deployments / velocity”) y errores criticos de sintaxis. El codigo es completamente inoperante.
El segundo fracaso – analisis de ingresos. Ultra identifico correctamente los patrones en los datos y calculo $317,1 mil. Thinking “razono” hasta llegar a $236,7 mil – una alucinacion en los calculos intermedios.
Cabe preguntar: si el modo de razonamiento empeora el resultado en cinco de ocho categorias – cual es su valor?
Mecanismo: por que “pensar mas tiempo” = “responder peor”
El problema de GigaChat Ultra Thinking no es unico. En los ultimos dos anos se ha publicado una serie de investigaciones que documentan el mismo efecto: el razonamiento extendido (extended thinking) en modelos de lenguaje no mejora, sino que empeora el resultado en una proporcion significativa de tareas.
Las respuestas incorrectas contienen el doble de “pensamientos”
Una investigacion (Do Thinking Tokens Help or Trap?, junio 2025) analizo las respuestas del modelo DeepSeek-R1. Conclusion principal: las respuestas incorrectas contienen el doble de thinking-tokens que las correctas. El modelo cae en una “trampa de razonamiento” – tokens como “hmm”, “esperemos”, “por lo tanto” desencadenan ciclos de re-verificacion que alejan de la respuesta correcta.
La supresion de la generacion de thinking-tokens llevo a una “degradacion minima de la calidad del razonamiento en todos los niveles de dificultad”. En otras palabras, se puede eliminar la mayor parte de las “reflexiones” – y el resultado no se ve afectado.
Las cadenas cortas de razonamiento son un 34,5% mas precisas que las largas
Hassid et al. (Don’t Overthink It, mayo 2025) demostraron que las cadenas cortas de razonamiento son hasta un 34,5% mas precisas que las largas – para la misma pregunta. Un metodo simple – generar varias respuestas cortas y elegir la mejor – utiliza hasta un 40% menos de thinking-tokens y al mismo tiempo muestra un resultado igual o superior.
Mas tokens – peor resultado
Una investigacion de Google y la Universidad de Virginia (Think Deep, Not Just Long, febrero 2026) registro una correlacion negativa de −0,544 entre la cantidad de tokens de razonamiento y la precision de la respuesta. Se probo en GPT-OSS-20B/120B, DeepSeek-R1-70B, Qwen3-30B. Conclusion de los autores – “pensar profundamente” y “pensar durante mucho tiempo” son cosas diferentes.
En el benchmark Omni-MATH, la precision cae con el aumento de la cantidad de tokens en todos los modelos probados: de −0,81% a −3,16% por cada mil tokens adicionales.
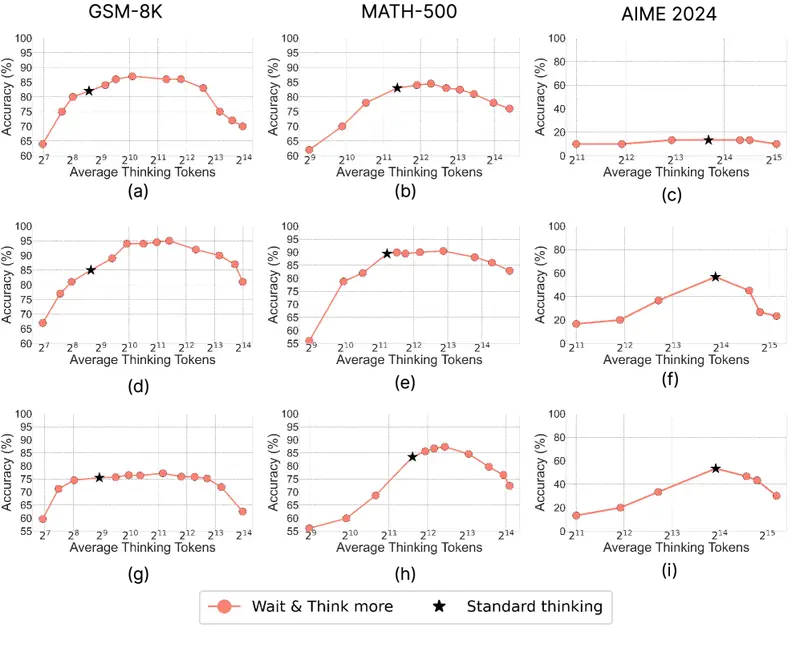
La curva con joroba: primero mejor, despues peor
Does Thinking More Always Help? (junio 2025) descubrio una curva no monotona “con joroba”: en GSM-8K, la precision primero crece del 82,2% al 87,3% con un volumen moderado de razonamiento, y luego cae al 70,3% con un volumen excesivo. La generacion paralela de varias respuestas cortas supera consistentemente una sola cadena larga.
Apple: para tareas sencillas, el razonamiento es perjudicial
El articulo de Apple (The Illusion of Thinking, 2025) identifico tres regimenes:
- Tareas sencillas – el modelo comun sin razonamiento funciona mejor que el modelo de razonamiento: mas rapido y mas preciso
- Tareas de dificultad media – el modelo de razonamiento obtiene ventaja
- Tareas dificiles – ambos modelos fracasan por igual, independientemente del volumen de razonamiento
Para tareas de gestion – correspondencia empresarial, analisis de datos, generacion de codigo – esto tiene relevancia directa. La mayoria de estas tareas caen en las categorias de “sencillas” y “de dificultad media”, donde el razonamiento extendido o perjudica o aporta un beneficio minimo.
Entienda la IA de forma sistematica
Que herramienta para que tarea, como detectar alucinaciones, como trabajar con modelos de razonamiento – lo analizamos en el programa del curso.
Overthinking como problema sistemico
Una revision de mas de 170 trabajos (Stop Overthinking, marzo 2025) documenta el “problema del overthinking” como una propiedad sistemica de los modelos de razonamiento: incluso una pregunta trivial como “2+3=?” puede generar miles de tokens de razonamiento sin ningun beneficio. Los modelos no saben calibrar el volumen de razonamiento segun la complejidad de la tarea.
Como distinguir una tarea donde la IA se desenvuelve bien de una que requiere su experiencia? Lo analizamos en el programa del curso
10 уроков: встраиваете ИИ в планирование, отчётность и кризисное реагирование. Результат – не промпты, а рабочая система.
Que significa esto para GigaChat Ultra
Nuestros datos encajan perfectamente en el patron descrito por las investigaciones:
Thinking perjudico donde la tarea requiere datos precisos. Analisis de ingresos, generacion de codigo, trabajo con numeros – el modelo genera pasos intermedios falsos que arruinan la respuesta final. Esta es la clasica “trampa de razonamiento” de Ding et al.
Thinking ayudo donde hay que sopesar multiples factores. Analisis de stakeholders, preparacion para negociaciones, evaluacion de riesgos en contratacion – tareas donde los pasos adicionales de razonamiento estructuran la respuesta. Esta es la “dificultad media” de Apple.
La diferencia entre categorias es enorme. Desde +1,75 hasta −2,61 puntos en escenarios individuales. El indicador promedio (−0,10) oculta la imagen real – Thinking no es “ligeramente peor”, es radicalmente mejor en algunas tareas y catastroficamente peor en otras.
Posicion en el ranking
Con una puntuacion de 3,04, GigaChat Ultra ocupa el puesto 44 de 54 modelos en el ranking actualizado. GigaChat Ultra Thinking – el puesto 46.
Para comparar con otros modelos rusos:
| Modelo | Puntuacion | Posicion |
|---|---|---|
| Alice AI LLM (Yandex) | 3,86 | 38 |
| YandexGPT Pro 5.1 | 3,13 | 43 |
| GigaChat Ultra | 3,04 | 44 |
| GigaChat-2-Max | 3,08 | 45 |
| GigaChat-Max-preview | 3,05 | 47 |
| GigaChat Ultra Thinking | 2,94 | 48 |
| GigaChat-Pro-preview | 2,90 | 49 |
La actualizacion del modelo insignia no trajo un progreso notable. Ultra esencialmente reprodujo el resultado de GigaChat-2-Max (3,08 vs 3,04 – la diferencia esta dentro del margen de error).
Ademas, el precio del API de GigaChat sigue siendo uno de los mas altos: $7,22 por millon de tokens. DeepSeek V3.2 con una puntuacion de 4,42 cuesta $0,27 – 27 veces mas barato con un resultado 1,45 veces superior.
Conclusiones practicas
Si ya utiliza GigaChat Ultra:
No active el modo de razonamiento por defecto. Uselo solo para tareas con multiples factores – analisis de posiciones, preparacion para negociaciones complejas, evaluacion de riesgos. Para todo lo demas – el modo estandar.
No confie en los numeros del modo Thinking. Cualquier calculo, dato o codigo – verificalo. El modo Thinking genera pasos intermedios verosimiles pero falsos.
Si esta eligiendo un modelo desde cero – Kimi K2.5, Qwen3.5 Plus o DeepSeek V3.2 ofreceran un resultado significativamente mejor a un menor coste.
Pero la cuestion es mas amplia: por que Sber lanza el modo de razonamiento como una ventaja de marketing, si seis investigaciones independientes entre 2025 y 2026 muestran lo mismo – “pensar mas tiempo” y “pensar mejor” para los modelos de lenguaje todavia no son lo mismo?