Cómo se evalúa la calidad de los LLM en 2026: guía de benchmarks para managers

Imagina que estás eligiendo un coche de empresa para tu equipo. Un concesionario dice: «Nuestro coche es el más rápido». Otro: «Tenemos el mejor consumo de combustible». Un tercero: «Somos líderes en seguridad». Todos tienen razón, pero cada uno mide algo diferente. Sin entender qué se mide exactamente y cómo, no puedes comparar las opciones de forma objetiva.
Con los modelos de lenguaje a principios de 2026, la situación es aún más compleja. GPT-5.3, Claude 4.6, Gemini 3, Perplexity, DeepSeek V4 – cada empresa afirma ser la líder. Pero ¿cómo puede un manager entender concretamente en qué es mejor una herramienta que otra para una tarea empresarial?
Aquí es donde entran los benchmarks – pruebas estandarizadas. En 2026, los test antiguos (como MMLU) se han vuelto menos útiles, ya que todos los modelos top aprendieron a superarlos casi a la perfección. Analicemos qué indicadores realmente vale la pena observar hoy.
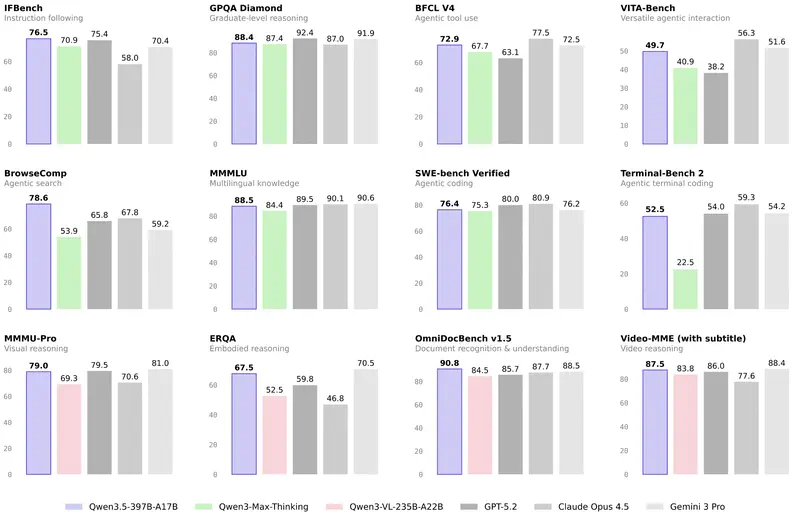
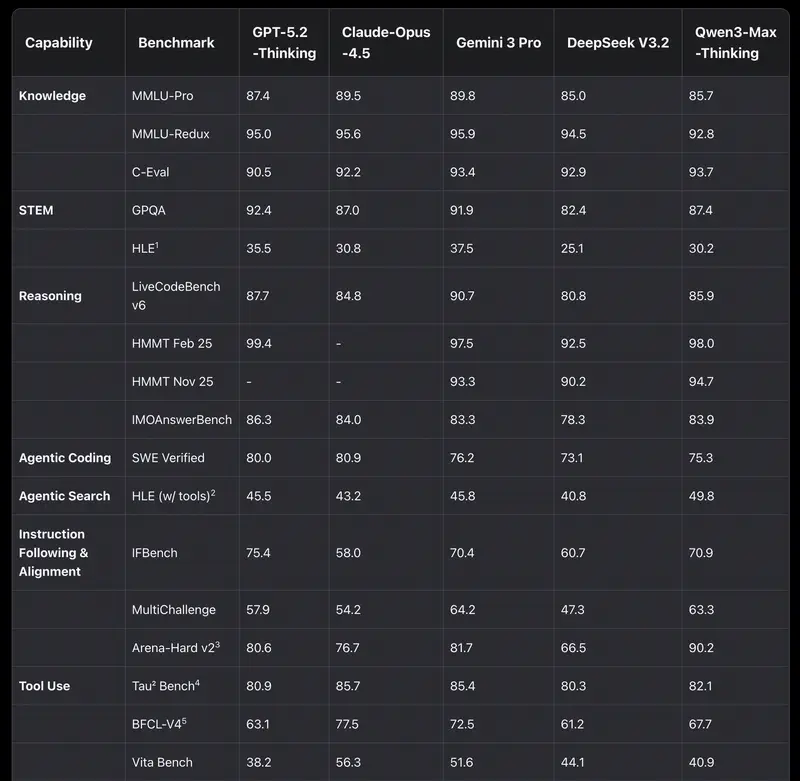
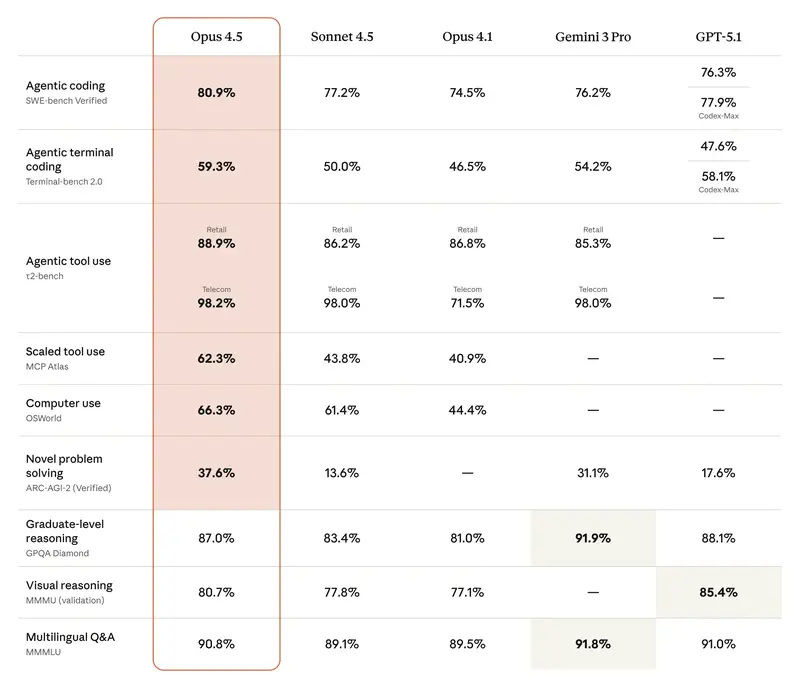
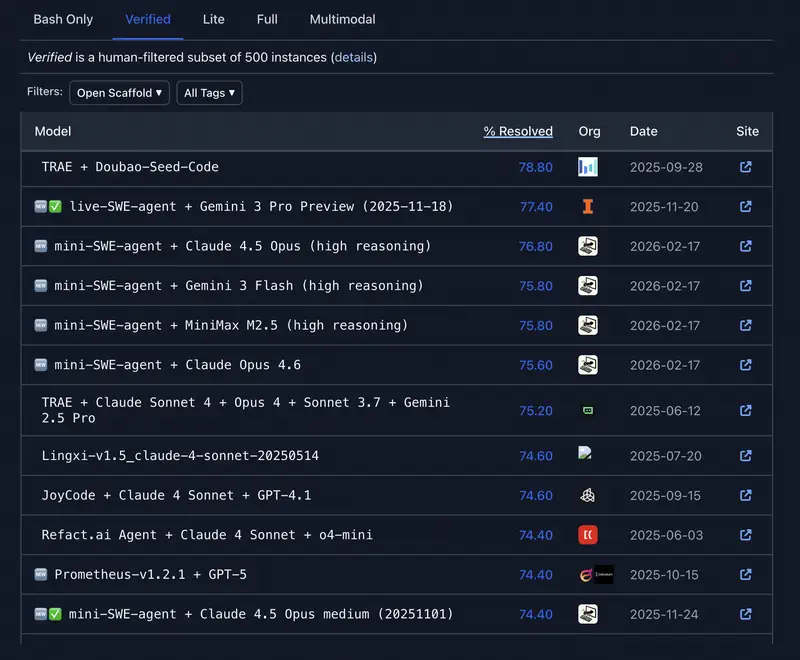
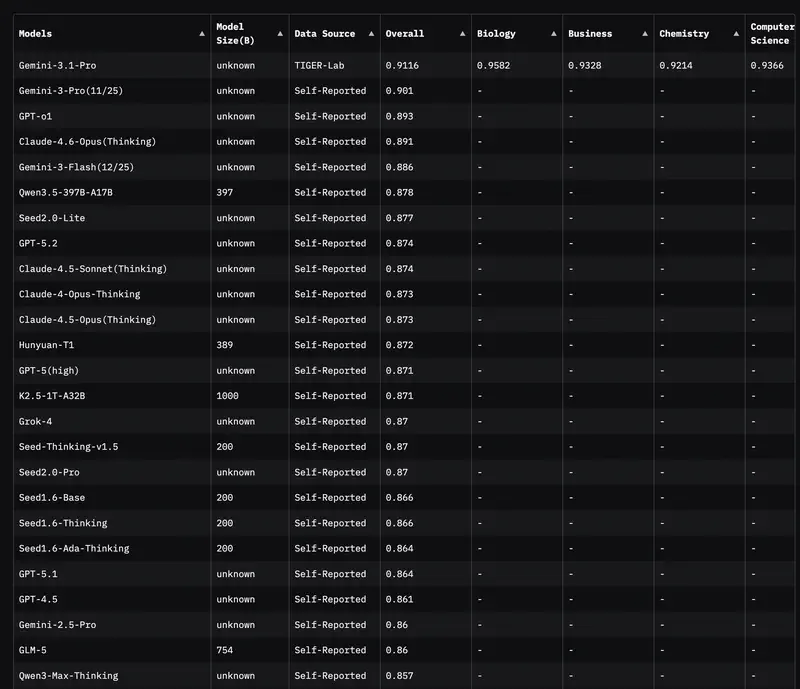
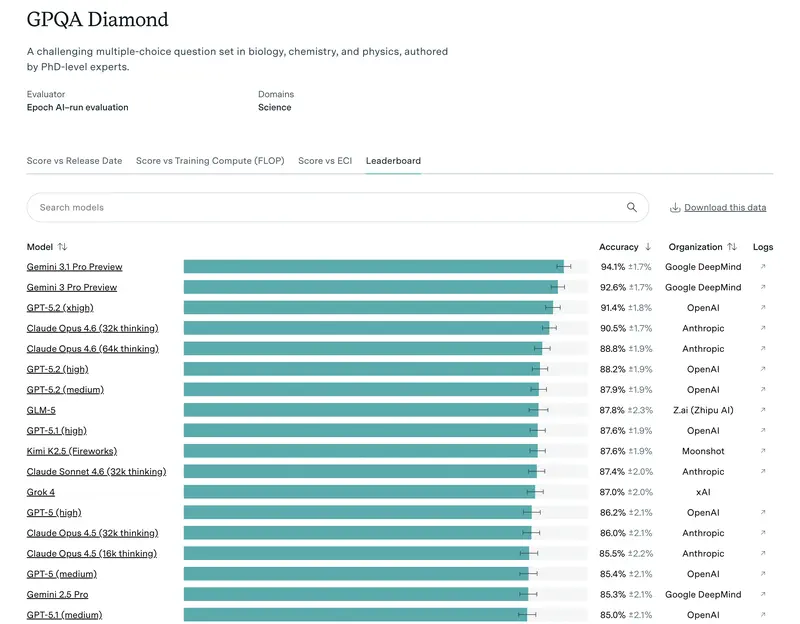
Intuición frente a datos. Los directivos a menudo tienen un modelo «favorito». Pero la intuición falla en los casos límite. Cuando necesitas justificar un presupuesto o elegir un modelo para automatizar todo un departamento, necesitas criterios objetivos.
Principales tipos de evaluación en 2026
La evaluación moderna de LLM no es un número único – se trata de entender en qué «liga» juega el modelo.
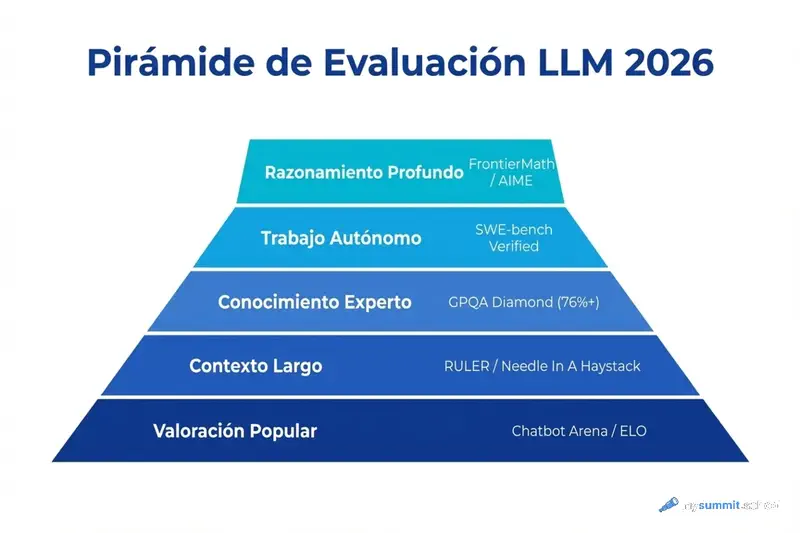
Tabla resumen de categorías actuales
| Categoría | Benchmark clave | Qué significa para el manager |
|---|---|---|
| Conocimiento experto | GPQA Diamond | Qué tan competente es el modelo en preguntas de nivel doctoral. Importante para auditoría y estrategia. |
| Trabajo autónomo | SWE-bench Verified | Capacidad del modelo para resolver tareas en código y repositorios de forma independiente. Indicador de «agencia». |
| Contexto largo | RULER / Needle In A Haystack | ¿Pierde el modelo información en documentos de más de 1.000 páginas? |
| Razonamiento profundo | FrontierMath / AIME | Capacidad de razonamiento en múltiples pasos sin fallos lógicos. |
| Valoración popular | Chatbot Arena (LMSYS) | Cómo evalúan el modelo personas reales en un test ciego y anónimo. |
1. Amplitud académica (MMLU y GPQA Diamond)
Antes todos miraban MMLU (pruebas en 57 disciplinas). Pero en 2026, este test se ha convertido en el «mínimo higiénico básico». Si un modelo puntúa por debajo del 85–90%, simplemente no está entre los de primera línea.
Hoy el estándar de oro es GPQA Diamond. Son preguntas tan difíciles que incluso expertos humanos con acceso a internet fallan en el 60% de los casos. Si un modelo obtiene un 75%+ aquí, significa que puedes confiarle la revisión de los documentos jurídicos o financieros más complejos.
2. Eficiencia agéntica (SWE-bench y GAIA)
Para los managers, esta es la métrica más importante en 2026. Mide no la «belleza del discurso», sino la capacidad de completar el trabajo.
- SWE-bench Verified – muestra cuántos bugs reales de software pudo encontrar y corregir el modelo por sí solo.
- GAIA – prueba al modelo en tareas que requieren uso del navegador, búsqueda de archivos y manejo de herramientas.
3. Valoraciones de usuarios: Chatbot Arena
El ranking «popular» más autorizado. En la plataforma lmarena.ai las personas comparan respuestas de modelos a ciegas.
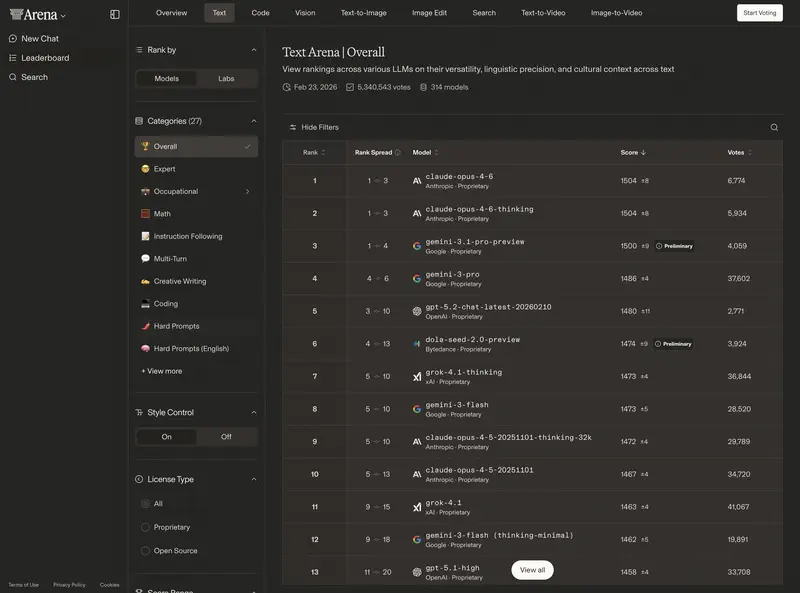
ELO 2026 (referencias):
- 1400–1500+: modelos de «superinteligencia» (GPT-5.3, Claude 4.6 Opus, Gemini 3 Ultra).
- 1300–1400: excelentes caballos de trabajo (GPT-5-mini, Sonnet 4.6, DeepSeek V4).
- Por debajo de 1200: modelos obsoletos o especializados.
Una diferencia de 30–50 puntos ELO es prácticamente imperceptible en la correspondencia diaria. Una diferencia de 100+ puntos significa un salto cualitativo en inteligencia y comprensión de instrucciones.
4. Contexto largo: RULER y el problema del «perdido en el centro»
Los modelos de 2026 afirman tener ventanas de contexto de 1–2 millones de tokens. Pero el tamaño de la ventana ≠ la calidad de trabajo con ella. El benchmark RULER y el test Needle In A Haystack comprueban si el modelo puede encontrar y usar correctamente información escondida en distintas partes de un documento largo.
En 2026, ambas pruebas se han convertido más en un mínimo básico. Los modelos top han aprendido a localizar hechos aislados en textos largos. Sin embargo, investigaciones de 2025 mostraron que una ventana de contexto grande no garantiza un razonamiento fiable – el modelo puede encontrar el fragmento correcto de forma aislada, pero falla cuando necesita integrarlo con un contexto circundante complejo. Por eso los nuevos tests (RULERv2, Sequential-NIAH, MMNeedle) comprueban no solo la búsqueda simple, sino la agregación de información en múltiples pasos desde diferentes partes del documento.
La trampa principal se llama Lost in the Middle – los modelos trabajan con confianza con el principio y el final del documento, pero alucinan u omiten hechos del centro. Esto es crítico si cargas en el modelo un contrato de 200 páginas o un informe anual.
Consejo práctico: Tras cargar un documento largo, haz al modelo una pregunta específica sobre información de la parte central del texto. Si la respuesta es inexacta o inventada, el modelo no puede manejar tu volumen de datos.
Evaluación de modelos de «pensamiento profundo» (Reasoning)
Con la llegada de modelos como o3 (OpenAI), R2 (DeepSeek) y Opus Thinking (Anthropic), surgió un nuevo problema de evaluación. Estos modelos pueden «pensar» la respuesta entre 10 segundos y 5 minutos.
¿Cómo evaluar su calidad como manager?
- Precisión del resultado – si la tarea es estratégica (por ejemplo, calcular riesgos de fusión), el tiempo de espera no importa – solo la exactitud.
- Transparencia (CoT) – un buen modelo de razonamiento debe mostrar el proceso paso a paso (Chain-of-Thought). Esto te permite auditar su lógica.
Guía práctica: cómo elegir un modelo
Elegir un LLM para el negocio en 2026 sigue un algoritmo de tres pasos.
Paso 1 – Define el rol
¿Qué hará la IA el 80% del tiempo?
| Rol | Métrica principal |
|---|---|
| Estratega / Analista | GPQA Diamond, FrontierMath |
| Empleado digital (Agente) | SWE-bench, GAIA |
| Comunicador (Correos, chats) | Chatbot Arena ELO (Overall) |
| Auditor de documentos | Long Context Benchmarks (RULER) |
Paso 2 – Consulta los benchmarks
Encuentra 2–3 líderes en la categoría elegida. No mires los gráficos publicitarios de los proveedores (siempre eligen los tests donde quedan primeros) – usa recursos independientes:
- LMSYS Chatbot Arena – para la evaluación general de «humanidad» y calidad del diálogo.
- Vectara Hallucination Leaderboard 2026 – si la precisión factual es crítica para ti.
- LiveCodeBench / SWE-bench Verified – si buscas un programador IA o un agente.
Paso 3 – «Test drive» con tus propios datos
Toma 5 de los casos reales más complejos de tu trabajo de la última semana. Pásalos por los modelos seleccionados. Evalúa no la «belleza», sino la precisión de las conclusiones y la exhaustividad en el seguimiento de instrucciones.
La trampa del «entrenamiento para el examen». En 2026 está extendida la práctica de «contaminación de datos» – cuando los modelos se entrenan específicamente con las preguntas de los benchmarks populares. Por eso tus propios datos privados son el mejor y único benchmark verdaderamente honesto.
Tarea offline: entra en Chatbot Arena, elige la categoría «Hard Prompts» y observa los 3 modelos del top. Esos son tus principales candidatos para resolver las tareas laborales más complejas este trimestre.
Enlaces útiles
- LMSYS Chatbot Arena
- GPQA Diamond
- SWE-bench Verified
- GAIA Benchmark
- Vectara Hallucination Leaderboard
- RULER (contexto largo)
Este artículo forma parte de la serie “Revisión de herramientas GenAI 2026”. Todas las herramientas se abordan con ejercicios prácticos en el curso mysummit.school.
