KazLLM e IA soberana: guía para el funcionario público de Kazajistán

El 11 de febrero de 2026, en una sesión del gobierno, el presidente Tokáyev criticó públicamente KazLLM. El modelo, lanzado con gran pompa en diciembre de 2024, tiene apenas 600 mil usuarios – el 3% de la población del país. A modo de comparación: ChatGPT en Kazajistán cuenta con 2,6 millones de usuarios. El presidente fue directo: KazLLM «no puede competir con ChatGPT».
Esta declaración plantea la cuestión de forma tajante. ¿Para qué necesita Kazajistán su propio modelo lingüístico si las soluciones globales funcionan mejor? Y si la IA soberana es necesaria – ¿por qué está perdiendo?
La respuesta es más compleja de lo que parece. Porque KazLLM no es «el ChatGPT kazajo». Es una herramienta completamente diferente con una misión diferente. Y compararlos es como comparar una central eléctrica nacional con un electrodoméstico importado.
Por qué un país necesita su propio modelo lingüístico
Cuando un funcionario público procesa solicitudes ciudadanas a través de ChatGPT, ocurren tres cosas simultáneamente. Los datos personales de los ciudadanos se envían a los servidores de OpenAI en Estados Unidos. El contexto del idioma kazajo – morfología aglutinante, alternancia de código entre kazajo y ruso – se interpreta con pérdidas. Y el Estado no controla ni la disponibilidad del servicio, ni su coste, ni la política de tratamiento de datos.
No se trata de un riesgo teórico. Cuando Italia bloqueó ChatGPT en 2023 por violaciones del RGPD, los procesos gubernamentales que dependían de él se paralizaron. Cuando OpenAI introduce restricciones para determinadas regiones – las consecuencias son impredecibles. La cuestión de la responsabilidad por las decisiones tomadas con ayuda de la IA va mucho más allá de la tecnología.
Un modelo soberano resuelve este problema a nivel arquitectónico. Los datos no abandonan la infraestructura nacional. El modelo está entrenado en kazajo teniendo en cuenta los dialectos regionales. Y el Estado controla cada elemento del stack – desde la capacidad de cómputo hasta los algoritmos.
Kazajistán no está solo en esto. Los Emiratos Árabes Unidos construyeron Falcon, Japón – Fugaku-LLM, Taiwán – TAIDE, Singapur – SEA-LION. Cada uno de estos países llegó a la misma conclusión: la dependencia de modelos ajenos es una vulnerabilidad estratégica.
Qué es realmente KazLLM
KazLLM – oficialmente ISSAI KAZ-LLM – fue desarrollado por el Instituto de Sistemas Inteligentes e Inteligencia Artificial (ISSAI) de la Universidad Nazarbáyev en colaboración con QazCode (división de VEON/Beeline Kazakhstan). El apoyo internacional fue proporcionado por el Barcelona Supercomputing Center y GSMA Foundry. En marzo de 2025, el modelo recibió el GSMA Foundry Excellence Award y fue presentado en el Mobile World Congress de Barcelona.
Sorprendentemente, a pesar de semejante reconocimiento internacional – 600 mil usuarios frente a los 2,6 millones de ChatGPT. El premio impresiona, pero las cifras cuentan otra historia.
Técnicamente, el modelo está construido sobre la arquitectura Meta Llama 3.1 – un framework open-source probado. El equipo no creó la arquitectura desde cero, sino que adaptó una existente, reentrenando los pesos neuronales para priorizar el idioma kazajo. Hay dos versiones disponibles: una compacta de 8 mil millones de parámetros para tareas rápidas y una completa de 70 mil millones para análisis complejos. Ambos modelos están publicados abiertamente en Hugging Face – se pueden descargar, probar y desplegar en infraestructura propia.
La ventaja clave son los datos. Un equipo especial llamado «Token Factory» del ISSAI recopiló y curó durante nueve meses un corpus de entrenamiento de más de 150 mil millones de tokens. Las fuentes incluyen recursos web kazajos, archivos estatales y literatura académica. El modelo fue entrenado en cuatro idiomas – kazajo, ruso, inglés y turco – con soporte para alternancia de código, cuando una persona cambia de idioma dentro de la misma oración. Esto es precisamente lo que distingue a KazLLM de los modelos globales: una comprensión profunda de la realidad multilingüe de la región.
¿Por qué entonces la comparación con ChatGPT es incorrecta? El presidente del consejo de administración de Kazajtelecóm, Bagdat Mussin, lo explicó mediante una analogía: un modelo lingüístico fundamental es una central eléctrica nacional. Genera «energía intelectual». Mientras que ChatGPT y servicios similares son electrodomésticos: útiles, cómodos, pero que funcionan conectados a un enchufe ajeno.
El propio ISSAI publicó un análisis detallado de la situación tras las críticas de Tokáyev. La escala de recursos habla por sí sola: para crear Llama, Meta empleó más de 16 000 nodos NVIDIA DGX H100 y más de 400 investigadores. El equipo de ISSAI trabajó con 8 nodos DGX H100 proporcionados por una empresa privada de telecomunicaciones.
Al mismo tiempo, el instituto reconoce: «La IA es una carrera. Aparecen nuevos modelos aproximadamente cada seis meses, y KazLLM necesita seguir evolucionando». Sin embargo, tras la transferencia del modelo a Astana Hub en diciembre de 2024, «no se le pidió a ISSAI que continuara su desarrollo». El modelo se quedó sin actualizaciones mientras los competidores lanzaban nuevas versiones cada trimestre.
Alem LLM y el supercomputador Alem.Cloud
En paralelo con KazLLM, el Estado desplegó un proyecto de infraestructura de otra escala. Alem.Cloud – el supercomputador nacional y el clúster de computación más potente de Asia Central. Sus características: 2 exaflops de rendimiento (FP8), 512 GPUs NVIDIA H200.
Obtener estos chips fue en sí mismo una maniobra geopolítica – se necesitaron negociaciones con Estados Unidos para conseguir licencias de exportación en medio de las restricciones globales sobre el suministro de GPUs avanzadas.
Alem LLM – el segundo modelo soberano, que funciona sobre esta infraestructura. Al igual que KazLLM, es multilingüe (kazajo, ruso, inglés, turco) y está diseñado para servicios gubernamentales. La diferencia clave es su profunda integración con el recurso computacional nacional: los datos se procesan en territorio de Kazajistán, en equipos estatales.
Sobre esta infraestructura se está construyendo la Plataforma Nacional de Inteligencia Artificial – un entorno protegido donde los desarrolladores gubernamentales y las universidades asociadas acceden a capacidad de cómputo, conjuntos de datos depurados y modelos preentrenados. En el foro de Davos en enero de 2026 se anunciaron alianzas con NVIDIA, OpenAI y Scale AI – en las áreas de supercomputación, infraestructura educativa y preparación de datos con RLHF.
Agentes de IA para la administración pública: planes vs realidad
Los modelos abstractos adquieren valor cuando se convierten en herramientas concretas. Kazajistán anunció el despliegue de más de diez agentes de IA especializados para procesos gubernamentales. Pero es importante distinguir entre planes y realidad.
Lo que ya funciona:
- AI Therapist – el único agente con un piloto confirmado. Lanzado en 30 clínicas de la región de Akmola. Analiza las conversaciones entre médico y paciente en tiempo real, emite diagnósticos preliminares con una precisión del 80% y reduce el tiempo de documentación hasta en un 40%. Se planea escalar a todos los centros sanitarios del país.
Lo que se ha anunciado, pero aún está en desarrollo:
- AlemGPT / eGov AI – asistente de IA para el portal de servicios gubernamentales. El Ministerio de Desarrollo Digital está probando un prototipo. Para finales de 2026 se planea lanzar 50 agentes de IA para atender a aproximadamente 7 millones de usuarios.
- Tax Helper – asesor fiscal virtual. Anunciado como parte de la digitalización del sistema tributario, pero aún sin datos sobre su lanzamiento.
- QQazaq Law – asistente jurídico para verificar que los actos municipales cumplan la legislación. Se menciona en documentos estratégicos, pero no hay confirmaciones de despliegue real.
- e-Otinish AI – sistema de procesamiento de peticiones y solicitudes ciudadanas. Descrito en materiales conceptuales, no se han encontrado datos de lanzamiento.
Esto invita a reflexionar. La brecha entre los anuncios y la implementación real es otra faceta del problema del que hablaba Tokáyev. La infraestructura se construye, pero el camino desde el modelo hasta un producto funcional en manos del funcionario resulta más largo de lo previsto.
Los agentes son inútiles sin datos de calidad. La plataforma Smart Data Ukimet resuelve esta tarea – a mediados de 2025 integraba 124 sistemas de información gubernamentales, soportaba 80 casos analíticos y atendía a más de 8 500 funcionarios. Para un director de departamento, esto significa la transición de la gestión reactiva a la predictiva – anticipar fallos de infraestructura y distribuir recursos basándose en insights algorítmicos en vez de apagar incendios.
Herramientas multimodales: más allá del texto
El ecosistema de IA soberana de Kazajistán va más allá de los modelos de texto. ISSAI ha desarrollado una línea de herramientas multimodales – todas disponibles como demos en el sitio web del instituto:
Oylan – modelo multimodal (idioma + audio + vídeo). Potencialmente aplicable para monitoreo de medios, análisis de grabaciones de vídeo y transcripción de archivos gubernamentales. El modelo es cerrado – a diferencia de KazLLM, Oylan no está publicado en Hugging Face, y su arquitectura, según el soporte de ISSAI, es «confidencial».
Un detalle curioso: usuarios en la comunidad de Telegram descubrieron que Oylan se identifica como Qwen de Alibaba Cloud. El soporte de ISSAI calificó esto como «un fenómeno ampliamente conocido en los LLM» – pero la pregunta sobre la base real del modelo quedó sin respuesta directa. Por indicios indirectos – multimodalidad (texto + imágenes + vídeo) y coincidencia de versiones – la base es muy probablemente Qwen2.5-VL o una variante posterior de la familia Qwen.
Esto se confirma también en una publicación académica: en el artículo de investigación del equipo de ISSAI, el modelo Qolda se describe como construido sobre Qwen3-4B, integrado en la arquitectura InternVL3.5 – la familia Qwen es claramente la base de los proyectos multimodales del instituto. Durante las pruebas también se detectaron errores factuales – el modelo confundía la autoría de obras de Abái y utilizaba datos geopolíticos obsoletos.
MangiSoz – motor de reconocimiento y síntesis de voz con traducción. Concebido como herramienta para correspondencia diplomática y comunicación interinstitucional en regiones multilingües. Y de nuevo la historia familiar: al probarlo, el modelo de traducción reveló su identidad – Google Gemma. Esto no es solo un indicio indirecto: en el sitio oficial de ISSAI (mayo de 2025) se indica directamente que el instituto «explora una posible colaboración con Google para el ajuste fino del modelo Gemma para el idioma kazajo». Así pues, en la base de MangiSoz hay un modelo open-source de Google, afinado para el idioma kazajo.
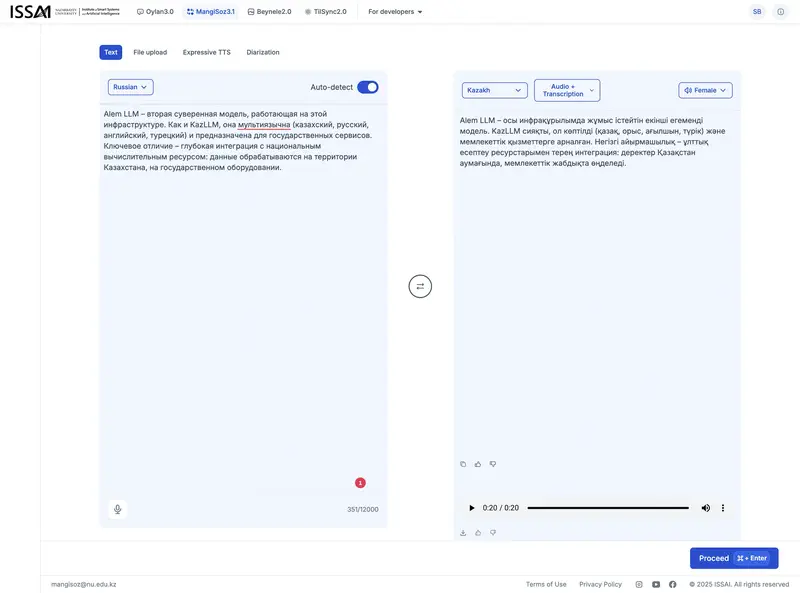
A modo de ejemplo, tradujimos un fragmento de este artículo del ruso al kazajo y locutamos el resultado – con voz masculina y femenina:
Voz masculina de MangiSoz
Voz femenina de MangiSoz
Demo de MangiSoz con traducción entre varios idiomas:
En la comunidad se observa una demanda real de MangiSoz: los usuarios solicitan acceso a la API y posibilidad de despliegue on-premise (sin internet) – lo cual es críticamente importante para estructuras gubernamentales con circuito cerrado. Según el soporte, la API pública con servicios independientes (TTS, STT, traducción) se encuentra en la fase final de preparación.
- TilSync – sistema de subtitulado en tiempo real. Diseñado para garantizar la accesibilidad de las transmisiones gubernamentales en kazajo, ruso e inglés.
- Beynele – generador de imágenes entrenado con cultura visual centroasiática. Permite crear contenido visual sin depender de generadores occidentales.
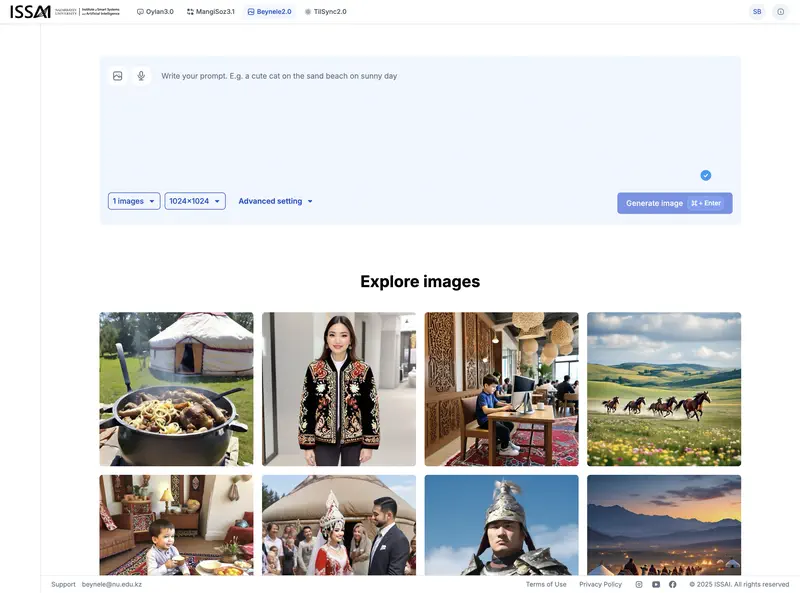
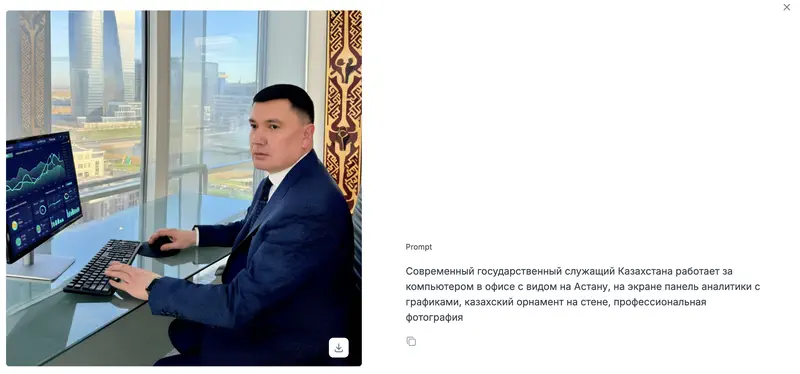
La misma historia que con Oylan: ante la pregunta «what model(AI) are you», Beynele generó una imagen con el logotipo de Qwen – modelo de Alibaba Cloud. Qwen en sí es un modelo de texto, no un generador de imágenes. Pero en el ecosistema de Alibaba Cloud existe el modelo text-to-image Tongyi Wanxiang (通义万相, serie Wan), disponible a través de la misma API. Lo más probable es que Beynele sea una versión de Tongyi Wanxiang con ajuste fino para la especificidad cultural kazaja, funcionando bajo la marca general Qwen/Tongyi.
ISSAI cuenta con una comunidad en Telegram donde se pueden seguir las actualizaciones y hacer preguntas a los desarrolladores.
Una advertencia importante: las cuatro herramientas se encuentran en fase de demos de investigación. No se han encontrado reseñas o comparativas independientes con análogos (Google Translate, Whisper, Midjourney) al momento de escribir este artículo. En la comunidad de Telegram los usuarios reportan problemas técnicos – tokens nulos en cuentas nuevas, funcionamiento inestable de la API. El soporte responde, pero estos son signos característicos de una etapa temprana del producto. Para un funcionario que planifique la implementación, esto significa: vale la pena probarlo, pero aún es pronto para contar con explotación industrial.
Ley de Inteligencia Artificial: un marco para todos
El 18 de enero de 2026 entró en vigor la Ley de la República de Kazajistán sobre Inteligencia Artificial (N 230-VIII) – la primera ley integral sobre IA en Asia Central. Firmada el 17 de noviembre de 2025, fue elaborada con la coordinación de 13 organismos estatales con la participación de sociólogos, filósofos y juristas.
Disposiciones clave de la ley:
- Sistema de clasificación de sistemas de IA por nivel de riesgo (similar al EU AI Act).
- Requisitos de transparencia en el uso de IA en decisiones gubernamentales.
- Las obras generadas por IA se protegen por derechos de autor solo si existe una contribución creativa humana (prompting, edición). Se contempla el derecho a negarse al uso de datos para el entrenamiento.
- Prohibiciones explícitas del uso de IA para la manipulación psicológica de los ciudadanos.
Para los funcionarios esto significa: cualquier implementación de IA en un organismo debe pasar auditorías periódicas de cumplimiento con estándares éticos y derechos ciudadanos.
El problema número uno: la brecha de competencias
La infraestructura existe. Los modelos existen. La ley existe. Los agentes de IA están desplegados. Pero la crítica de Tokáyev apunta al problema principal – la brecha entre la tecnología y su uso.
600 mil usuarios de KazLLM frente a 2,6 millones de usuarios de ChatGPT – esto no es una sentencia sobre la calidad del modelo. Es un indicador de que las personas no saben para qué ni cómo utilizar las herramientas soberanas. Un modelo que no se comprende ni se aplica es inútil – por potente que sea. Esto no es algo exclusivo de Kazajistán – una brecha análoga se ha documentado en todo el mundo.
El programa AI Qyzmet – certificación obligatoria de funcionarios en el área de IA – está diseñado para cerrar esta brecha. El programa AI Sana se dirige a la formación de 650 000 estudiantes. El centro Alem.ai en Astaná planea graduar 10 000 especialistas en IA al año para 2029.
Pero la escala del desafío es enorme. Los programas educativos apenas están comenzando a desplegarse, mientras los funcionarios ya trabajan hoy con ChatGPT – usándolo para tareas en las que las herramientas soberanas serían más seguras y precisas. Las investigaciones confirman: sin formación sistemática, la tecnología no arraiga.
Esto invita a reflexionar: el Estado invierte miles de millones en tecnología que permanece inactiva porque los usuarios no están formados para trabajar con ella.
Qué significa esto para el funcionario público
Probamos Oylan, MangiSoz y Beynele – y vimos un panorama familiar. Los modelos funcionan, pero con matices. Oylan confundía la autoría de obras de Abái y nombraba a Biden como presidente en funciones de EE. UU. a finales de 2025. MangiSoz ofrece una traducción aceptable, pero tras la fachada está Google Gemma. Como muestran las investigaciones de Anthropic, los sistemas de IA no se equivocan de forma consistente, sino caótica – y esto aplica a cualquier modelo, soberano o global.
La IA soberana ya no es el futuro. La plataforma, los modelos y los agentes existen. La cuestión no es si su organismo usará IA, sino si usted gestionará ese proceso – o si ocurrirá de forma espontánea, a través de las cuentas personales de ChatGPT de los empleados. Al mismo tiempo, los modelos globales no van a desaparecer: ChatGPT, Claude, Gemini siguen siendo herramientas potentes para tareas no relacionadas con datos personales de los ciudadanos.
Las investigaciones muestran que la IA no reduce el trabajo, sino que lo intensifica – creando nuevas exigencias de competencias. Cuando AI Qyzmet se vuelva obligatorio, los funcionarios con habilidades prácticas estarán en posición de liderazgo.
El principal desafío de la IA soberana de Kazajistán no es tecnológico. El Estado ha construido una infraestructura de nivel mundial y hasta ahora no ha logrado convencer a sus propios funcionarios de que la utilicen. 16 000 nodos DGX H100 en Meta, 8 nodos en ISSAI, cero actualizaciones tras la transferencia del modelo – y un presidente que pregunta por qué esto no funciona como ChatGPT. Quizás la pregunta debería plantearse de otra forma: no «por qué KazLLM es peor que ChatGPT», sino «quién exactamente debería haberse encargado de su desarrollo después de diciembre de 2024».
La IA soberana se implementa. Quien sepa trabajar con ella irá por delante
Curso de IA generativa para funcionarios y directivos: ChatGPT, Claude, prompting, evaluación crítica – práctica sin registro.
Fuentes
Todos los enlaces y datos son actuales a febrero de 2026. El ecosistema de IA soberana de Kazajistán evoluciona activamente – recomendamos verificar la vigencia de la información.