Kimi de Moonshot en 2026: K2.6, K2.7-Code y agentes para el manager

¿Puede un modelo chino open source competir con los buques insignia cerrados de OpenAI y Anthropic? Según nuestras pruebas independientes – sí. Kimi de Moonshot AI fue el primer modelo chino en entrar en el grupo de élite, a la par de los mejores del mundo, y compite directamente con GPT-5.4 y Claude Sonnet 4.5. Con un nivel de uso completamente gratuito.
A lo largo de 2026, Kimi pasó de ser un modelo a una familia entera: el buque insignia K2.6 para el trabajo diario, la especializada K2.7-Code para desarrollo y el agente de escritorio Kimi Work, que ejecuta tareas directamente en tu ordenador. Abajo: qué aporta esto a un manager, los resultados de nuestro benchmark y cómo usarlo.
Quién es Moonshot AI
Moonshot AI es una startup pekinesa fundada en 2023 por excolaboradores de ByteDance (la empresa detrás de TikTok). Cuenta con el respaldo de Alibaba y HongShan (anteriormente Sequoia China). Su fundador y CEO es Zhilin Yang, investigador especializado en NLP.
La startup apostó por dos cosas: contexto largo y capacidades agénticas. La primera versión de Kimi en 2024 llamó la atención por su ventana de contexto, récord en aquel momento. A principios de 2026, K2.5 llevó ambas líneas al grupo de élite, y para el verano la sucedieron K2.6 y la K2.7-Code para programación.
Qué puede hacer Kimi
Todos los modelos Kimi se basan en una arquitectura Mixture-of-Experts: 1 billón de parámetros, pero en cada momento solo están activos 32 mil millones. De ahí la combinación de potencia y eficiencia – las respuestas son rápidas y el coste a través de API es varias veces inferior al de Claude o GPT.
Características clave:
- Ventana de contexto de 256K tokens – aproximadamente 350–500 páginas de texto por consulta (varía según el idioma: la tokenización es menos eficiente en idiomas no ingleses)
- Multimodalidad nativa – comprende texto, imágenes y vídeo de serie
- Cuatro modos de trabajo: Instant (respuestas rápidas), Thinking (análisis profundo), Agent (tareas autónomas con herramientas) y Agent Swarm (trabajo en paralelo de subagentes – hasta 100 en K2.5 y 300 en K2.6)
- Código abierto – licencia MIT, pesos disponibles en HuggingFace
Agent Swarm: la función estrella
Este es un enfoque fundamentalmente nuevo. En lugar de resolver una tarea de forma secuencial, Kimi puede dividirla en subtareas y lanzar decenas y cientos de subagentes especializados en paralelo (hasta 300 en K2.6, con coordinación de hasta 4000 pasos). Cada subagente trabaja de forma independiente, y el agente principal coordina los resultados.
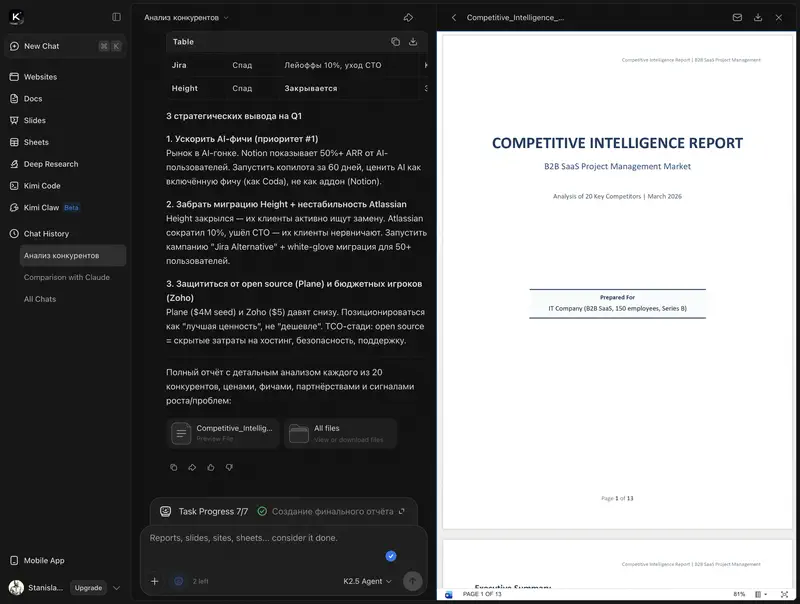
¿Para qué esperar 10 minutos si la tarea puede dividirse en 100 hilos? Kimi K2.5 en modo Swarm resuelve una consulta analítica compleja en 2–3 minutos en lugar de 10. En el test BrowseComp (navegación y búsqueda web) Agent Swarm obtuvo un 78,4% – el mejor resultado entre todos los modelos evaluados, incluyendo GPT-5.2.
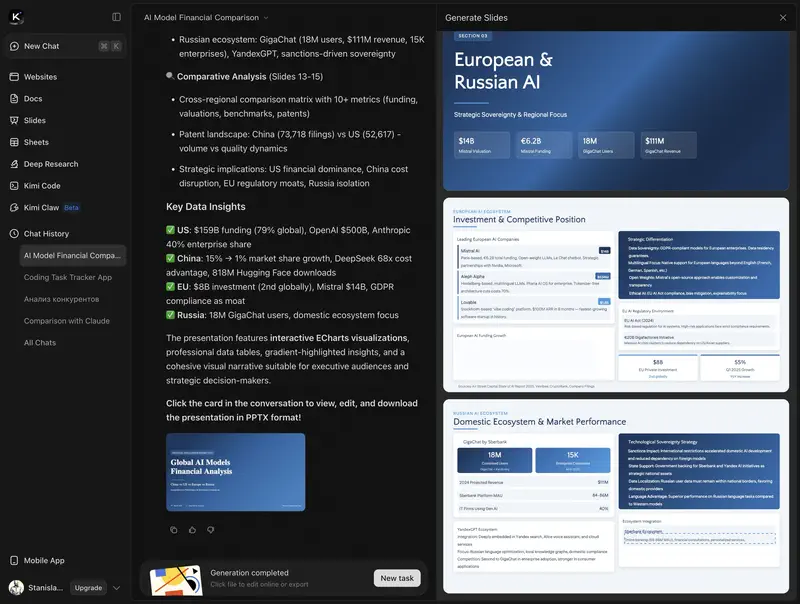
En cuanto a capacidades, Kimi puede competir incluso con Notebook LM de Google. En la parte de presentaciones interactivas – el resultado es bastante decente a primera vista. Eso sí, los datos son del año pasado.
Para un manager, esto es relevante en escenarios como «analiza 10 sitios web de competidores y elabora un resumen» o «prepara un informe basado en varias fuentes».
Qué muestran los tests
En los benchmarks estándar de la industria, Kimi K2.5 compite con solidez frente a los mejores modelos cerrados:
| Benchmark | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | DeepSeek V3.2 |
|---|---|---|---|---|
| HLE con herramientas | 50,2% | 45,5% | 43,2% | 40,8% |
| BrowseComp (Agent Swarm) | 78,4% | 54,9% | 24,1% | 67,6% |
| SWE-Bench Verified (código) | 76,8% | 80,0% | 80,9% | 73,1% |
| AIME 2025 (matemáticas) | 96,1% | 100,0% | 92,8% | 93,1% |
| VideoMMMU (vídeo) | 86,6% | 85,9% | 84,4% | – |
Kimi K2.5 lidera en tareas agénticas (búsqueda, navegación, trabajo autónomo) y comprensión de vídeo. En programación queda por detrás de Claude, en matemáticas – de GPT-5.2. Pero son diferencias de 3–4 puntos porcentuales, no un abismo.
Como siempre, los benchmarks y el uso real son cosas distintas. Pero la dirección es clara: Kimi K2.5 juega en la misma liga que los buques insignia.
La gama Kimi: K2.5, K2.6 y K2.7-Code
Hoy la gama Kimi son tres modelos. A la base K2.5 la sucedió la K2.6 incremental (la que ahora aparece en el selector de modelos de Perplexity), y el 12 de junio salió K2.7-Code. Conviene no confundirlas: K2.7-Code es un modelo especializado en programación; no está pensada para el chat cotidiano.
Por qué interesa K2.7-Code:
- Diseñada para desarrollo long-horizon: planifica, edita, ejecuta herramientas y depura código en muchos pasos dentro de un mismo ciclo. Para tareas de gestión normales, quédate con K2.5/K2.6.
- Arquitectura y contexto: 1 billón de parámetros, 32 mil millones activos (MoE), ventana de 256K tokens y pesos abiertos (MIT modificada) en Hugging Face, con acceso vía la API de Kimi y Kimi Code.
- ~30% menos «tokens de razonamiento» que K2.6: un ciclo agéntico que antes gastaba ~1000 tokens para pensar una edición ahora gasta ~700. A escala, es ahorro directo.
- Llamadas a herramientas fiables vía MCP: invoca herramientas externas por el protocolo de forma fiable – comprobaciones de CI, actualización de tickets y ediciones multiarchivo en una sola pasada.
Precio – $0,75 / $3,50 por millón de tokens de entrada/salida: barato para mantener un agente de código en marcha a diario.
Cuidado con las cifras: todos los resultados publicados de K2.7-Code son benchmarks propios de Moonshot (Kimi Code Bench v2: de 50,9 a 62,0; MCP Mark Verified 81,1 frente a 76,4 de Claude Opus 4.8). Sin resultados independientes en suites públicas en el lanzamiento; como en la historia de GLM-5.2, las victorias del proveedor conviene verificarlas.
Para los managers: si tu equipo escribe código, K2.7-Code merece una prueba como agente-desarrollador económico. Para texto, análisis y comunicación quedan K2.5/K2.6 – son las que evaluamos en el benchmark de abajo.
Kimi Work y OK Computer: Kimi como agente
Más allá de los modelos, Moonshot desarrolla productos agénticos – aquí Kimi compite directamente con Perplexity Computer y Claude Cowork.
- OK Computer – modo agente dentro del chat de Kimi. Desde un prompt construye sitios multipágina y diapositivas editables listas, procesa hasta 1 millón de filas de datos de una vez y produce texto, audio, imágenes y vídeo. Para un manager: un primer borrador de presentación, landing o informe de datos con un solo prompt.
- Kimi Work – app de escritorio (macOS Apple silicon y Windows) sobre K2.6 que actúa en tu propio ordenador. Fijas un objetivo con palabras; el agente investiga, lo convierte en un breve informe de mercado en diapositivas listas (las secciones se preparan en paralelo) y, mediante la extensión WebBridge, usa tu navegador como una persona: busca, desplaza, extrae datos, rellena formularios. Dentro, el mismo Agent Swarm, hasta 300 subagentes.
Para los managers: Kimi Work y OK Computer convierten a Kimi de un chat en un «empleado digital»: bríefalo por la noche y recibe un borrador de informe o presentación por la mañana. La salvedad principal – los datos los procesa un servicio chino, tenlo en cuenta para información sensible.
Resultados en nuestro benchmark
En nuestro benchmark independiente – donde evaluamos modelos con tareas reales de gestión en múltiples categorías – Kimi K2.5 se situó con firmeza en el grupo de élite, entre los mejores modelos disponibles. Compite directamente con GPT-5.4 y Claude Sonnet 4.5, algo notable para un modelo open source y gratuito. Evaluamos K2.5; el buque insignia actual K2.6 es su sucesora incremental directa, así que las conclusiones se trasladan a la versión vigente.
Kimi K2.5 es fuerte en prácticamente todas las categorías: comunicación, planificación, análisis, formación y desarrollo, resolución de problemas. No tiene un punto débil claro – ofrece una calidad alta y constante independientemente del tipo de tarea. Esa consistencia es, de hecho, uno de sus rasgos distintivos: mientras la mayoría de los modelos muestran altibajos entre categorías, Kimi se mantiene notablemente estable.
Para quienes buscan calidad de primer nivel sin pagar una suscripción, Kimi K2.5 es la opción gratuita más potente. Es un modelo genuinamente de élite que se puede usar en kimi.com sin gastar un céntimo – una alternativa notable a ChatGPT Plus y Claude Pro.
¿Cómo se compara con otros modelos chinos? MiniMax M2.7 está muy cerca y lidera en gestión de equipos. MiMo V2 Omni de Xiaomi destaca en escenarios de aprendizaje. Qwen3.5 Plus rinde bien, quedando solo ligeramente por detrás. Pero en conjunto, Kimi K2.5 mantiene la primera posición entre los modelos chinos – y supera con amplio margen a todos los modelos rusos (GigaChat, YandexGPT).
Consulta los resultados interactivos completos con las comparaciones de DeepSeek y Qwen.
Resultados interactivos completos →
Kimi K2.5 frente a otros modelos chinos
Para un manager que elige entre herramientas disponibles, la comparación dentro del «grupo chino» es más relevante que la competición abstracta con Claude.
| Modelo | Punto fuerte | Acceso por chat | Coste |
|---|---|---|---|
| Kimi K2.5 | Versatilidad, búsqueda | kimi.com | Gratis / $19–199/mes |
| MiniMax M2.7 | Gestión de equipos | minimaxi.com | Gratis |
| Qwen3.5 Plus | Planificación | chat.qwen.ai | Gratis (solo API) |
| MiMo V2 Omni (Xiaomi) | Escenarios de aprendizaje | mimo.xiaomi.com | Gratis |
| GLM-5 (Z.ai) | Gestión de equipos | chat.z.ai | Gratis (solo API) |
| DeepSeek V3.2 | Relación calidad-precio | chat.deepseek.com | Gratis (solo API) |
| Qwen3 Max | Razonamiento | chat.qwen.ai | Gratis (solo API) |
Conclusiones de la tabla:
Kimi K2.5 es el mejor modelo chino en conjunto. Lidera en la mayor variedad de categorías de tareas de gestión, sin puntos débiles significativos.
Pero no es el mejor en cada categoría. MiniMax M2.7 le supera en gestión de equipos. DeepSeek V3.2 ofrece la mejor relación calidad-precio. Qwen3.5 Plus es más fuerte en planificación.
En cuanto a accesibilidad, Kimi destaca. Es uno de los pocos modelos de nivel élite con una interfaz de chat completamente gratuita. Los planes de pago de Kimi ($19–199/mes) desbloquean capacidades agénticas que los competidores simplemente no ofrecen en interfaz de chat.
Cómo acceder a Kimi K2.5
Interfaz web: kimi.com
El sitio kimi.com es accesible globalmente sin restricciones en la mayoría de los países de habla hispana, tanto en España como en Latinoamérica. El inicio de sesión se realiza con una cuenta de Google – es el método más rápido y sencillo, basta con 10 segundos.
La interfaz está disponible solo en inglés y chino; no hay UI en español. El modelo entiende español y responde en él, pero – como con todos los modelos chinos – la calidad de las respuestas en español es notablemente inferior a la del inglés. Para tareas complejas, la recomendación práctica es formular los prompts en inglés y obtener mejores resultados.
Tres modos principales de trabajo:
- Instant – respuestas rápidas para tareas cotidianas: correspondencia, preguntas, trabajo con documentos
- Thinking – análisis profundo con «cadena de razonamiento», el modelo muestra su proceso de pensamiento
- Agent – ejecución autónoma de tareas: generación de documentos (.docx, .pdf, .xlsx), búsqueda web, operaciones de múltiples pasos. Si pides preparar un informe con tablas – este es el modo indicado
Aplicaciones móviles
Kimi está disponible para iOS y Android. La funcionalidad es similar a la versión web, incluyendo todos los modos de trabajo.
Precios y tarifas
Nivel gratuito (Adagio)
- Consultas de texto ilimitadas en modos Instant y Thinking
- Hasta 3 consultas al mes a agentes (documentos, hojas de cálculo, presentaciones)
- 1 consulta Deep Research al mes
- Cola de espera en horas punta
El nivel gratuito es suficiente para probar el modelo y determinar si es adecuado para tus tareas. Para trabajo diario – se queda corto.
Planes de pago
| Plan | Precio | Qué ofrece |
|---|---|---|
| Moderato | $19/mes | Más consultas agénticas, prioridad, generación de presentaciones |
| Allegretto | $39/mes | Más límites, multitarea de agentes, acceso a Kimi Claw |
| Vivace | $199/mes | Agentes ilimitados, máxima velocidad, contexto ampliado |
Los precios están en dólares estadounidenses y se pagan con Visa o Mastercard internacional. El proceso de suscripción es directo, sin complicaciones adicionales.
Coste a través de API
| Opción | Tokens de entrada | Tokens de salida | ~Precio análisis informe 100 págs. |
|---|---|---|---|
| Moonshot API (directo) | $0,60 / 1M | $3,00 / 1M | ~$0,50 |
| OpenRouter | $0,45 / 1M | $2,20 / 1M | ~$0,35 |
Para comparar: Claude Opus 4.5 para una tarea similar cuesta unos $3, GPT-5.2 – $1,50. Kimi K2.5 es 6–8 veces más barato que Claude.
Pero entre los modelos chinos, Kimi no es el más económico. DeepSeek V3.2 cuesta 3 veces menos, Qwen3.5 Plus – 1,5 veces menos.
Limitaciones y riesgos
Idioma español – una debilidad predecible. Al igual que GLM-5, Kimi K2.5 funciona notablemente mejor en inglés y chino. En español el modelo se desenvuelve, pero con pérdida de matices. Dicho esto, el soporte del español en los modelos chinos es mejor que el de idiomas más pequeños – pero si la tarea lo permite, formula los prompts en inglés para obtener la máxima calidad.
Velocidad de respuesta – Agent Swarm es rápido para tareas complejas, pero el modo Thinking normal es más lento que Claude y GPT. En una prueba independiente, el tiempo mediano de respuesta de Kimi K2.5 fue de 29,2 segundos frente a 4,6 de Claude Sonnet 4.6. Esto invita a reflexionar: si Agent Swarm promete velocidad a través del paralelismo, ¿por qué el modo normal es 6 veces más lento que los competidores? Para consultas puntuales es tolerable; en sesiones de trabajo intensivas – se nota.
La censura china funciona igual que en los demás modelos chinos: los temas políticamente sensibles se bloquean. Para tareas de gestión, esto rara vez supone un problema.
Tamaño del modelo – 1 billón de parámetros significa que ejecutar Kimi K2.5 en servidores propios es poco realista para una empresa convencional. No es un Qwen3.5 9B que se puede desplegar en una sola GPU.
¿Merece la pena probarlo?
Kimi es, objetivamente, la línea de modelos china más fuerte de 2026. Rendimiento de nivel élite, la tecnología única de Agent Swarm y acceso básico completamente gratuito – todo ello respaldado por pruebas independientes.
Para un manager, la recomendación depende del contexto. Si necesitas una herramienta versátil con búsqueda potente, análisis y capacidades agénticas – Kimi K2.5 merece que lo pruebes. Especialmente si tus tareas incluyen trabajar con múltiples fuentes, preparar informes o investigaciones de múltiples pasos.
Si tu prioridad es la relación calidad-precio y necesitas un modelo asequible para tareas cotidianas – DeepSeek V3.2 sigue siendo una excelente opción, a un tercio del precio. Si el foco está en gestión de equipos, tareas de HR y feedback – GLM-5 sigue siendo el n.º 1 en esa categoría.
Es sorprendente que el modelo chino más potente de 2026 no sea aquel del que más se habló a principios de año. Kimi superó tanto a DeepSeek como a Qwen sin grandes declaraciones. Esto invita a preguntarse: ¿hasta qué punto el hype mediático es un indicador fiable a la hora de elegir una herramienta de trabajo?
Entra en kimi.com, inicia sesión con Google y dedica una hora a probarlo. El nivel gratuito es suficiente para formarte tu propia opinión.
Analizamos Kimi K2.5 y otras herramientas de IA en la práctica
9 lecciones de diagnóstico: prueba Kimi K2.5 y otros modelos en tareas reales – y descubre qué errores cometen la mayoría de los managers. Sin registro.
Continúa aprendiendo
Abre el libro de texto y continúa donde lo dejaste











Stanislav Belyaev
Engineering Leader en Microsoft18 anos liderando equipos de ingenieria. Fundador de mysummit.school. 700+ graduados en Yandex Practicum y Stratoplan.