LLMs locales para managers: qué se puede ejecutar en casa de verdad

Cualquiera que lleve el tiempo suficiente trabajando con ChatGPT o Claude termina haciéndose la misma pregunta: ¿se puede ejecutar algo parecido directamente en el portátil, sin suscripción, sin que los datos salgan de casa y sin depender de servidores remotos?
La respuesta, en 2026, es que sí – pero con matices que importan más que la propia respuesta.
Este artículo es para quienes ya usan LLMs en la nube y quieren entender qué aporta realmente ejecutar una modelo en local, qué hardware hace falta y dónde terminan las expectativas razonables. Sin inmersión técnica profunda, pero con cifras concretas.
¿Para qué ejecutar una modelo en local?
Antes de hablar de hardware, conviene responder a una pregunta más importante.
Los servicios en la nube tienen tres limitaciones reales que se notan en el día a día: la confidencialidad de los datos (nunca estás del todo seguro de que las conversaciones con clientes no se indexen en algún sitio), la dependencia de la disponibilidad del servicio (ChatGPT se cae en horas punta, y algunos proveedores tienen limitaciones regionales) y el coste cuando se usa de forma intensiva.
Una modelo local resuelve las tres cosas de golpe: los datos no salen de tu ordenador, funciona sin conexión y, una vez descargada, no cuesta nada. Ese es su valor real – no “un GPT-5 gratis en casa”, que sería mentira.
La única pregunta es a qué precio, tanto en hardware como en calidad de las respuestas.
¿Qué son estas modelos y qué significan sus tamaños?
El tamaño de una modelo de lenguaje se suele medir en miles de millones de parámetros – los números que la modelo ha “memorizado” durante el entrenamiento. Se indica con la letra B: 7B, 14B, 70B.
Para un manager esto no es un término técnico, sino una pista práctica: cuánta memoria RAM necesitas para que la modelo arranque.
Regla aproximada: la modelo ocupa alrededor de gigabyte y medio de memoria por cada mil millones de parámetros si se usa compresión a 4 bits. Es decir, una modelo 7B ocupa unos 5 GB, una 14B unos 9 GB, una 32B unos 20 GB, etc. En un portátil con 16 GB de RAM, cualquier cosa por encima de 14B no va a caber del todo en memoria rápida – la modelo empezará a “swappearse” y se notará bastante la lentitud.
La cuantización es precisamente esa compresión. La modelo original guarda los números con alta precisión; la cuantización reduce esa precisión para recortar el tamaño entre 2 y 4 veces. Una pequeña pérdida de calidad a cambio de poder ejecutarla siquiera.
Para que se vea la escala: los buques insignia en la nube como Claude Sonnet 4.6 o GPT-5.4 no publican oficialmente sus parámetros, pero las estimaciones del sector apuntan a cientos de miles de millones, o billones, de parámetros en arquitectura Mixture-of-Experts. Aunque en cada petición solo se active una parte (unos 30–50B), el peso total de la modelo se mide en terabytes y exige un datacenter con decenas de aceleradores especializados. Una modelo local de 8B en un portátil es aproximadamente el 1% del tamaño de un buque insignia en la nube. De ahí viene la brecha de calidad en tareas complejas: no porque los autores de las modelos locales sean peores, sino porque la escala está dos órdenes de magnitud por debajo. Abajo, un gráfico con el número de parámetros de modelos que se pueden ejecutar tanto en local como en la nube, cortesía de Epoch AI.
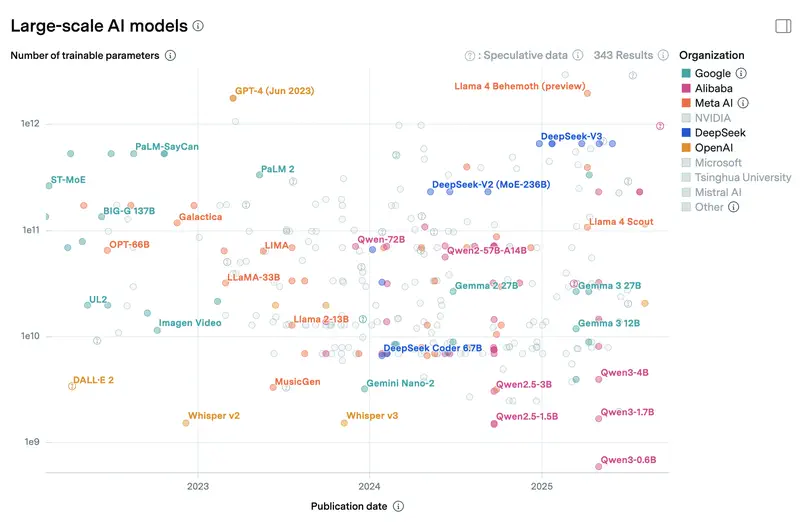
Qué modelos son relevantes en abril de 2026
El panorama de las modelos abiertas se actualiza más rápido que la mayoría de políticas corporativas. La foto de abril de 2026 resulta inesperada para quien solo haya seguido las noticias de IA a través de medios occidentales: en la frontera no están solo Meta y Google, sino un nutrido grupo de laboratorios chinos y una sorpresa de OpenAI.
DeepSeek V3.2 – líder indiscutible entre las modelos abiertas. 671B MoE con 37B parámetros activos por petición, lanzada en diciembre de 2025, ventana de contexto de 163 mil tokens. Ya analizamos DeepSeek en detalle: en tareas de gestión cae sistemáticamente en el clúster superior. La V3.2 completa no sirve para ejecución local – no la vas a desplegar en hardware doméstico. Pero los destilados sobre su base (7B, 14B) funcionan con 8 GB de VRAM y son notablemente más potentes que las modelos locales habituales del mismo tamaño en análisis y tareas de lógica.
La familia Qwen de Alibaba – la segunda dirección clave entre las modelos ejecutables en local. Qwen 3.5 salió en febrero–marzo de 2026 y cubre un rango que va desde 0,8B hasta el buque insignia 397B MoE, que no está pensado para local. Para uso doméstico los tamaños relevantes son 27B dense (~16 GB VRAM Q4, funciona en una GPU de 8 GB), 9B y 4B. El 2 de abril salió Qwen 3.6-Plus en arquitectura MoE, con contexto de 1 millón de tokens. En nuestra review de Qwen la familia recibió puntuaciones altas y destaca especialmente en tareas multilingües más allá del inglés – un parámetro relevante para managers que trabajan en varios idiomas.
Los laboratorios chinos, en conjunto, se han convertido en una alternativa real a los buques insignia occidentales. Entre las modelos abiertas más visibles de este círculo:
- Xiaomi MiMo-V2-Pro (marzo de 2026) – modelo de razonamiento, contexto de 1 millón de tokens.
- MiniMax M2.5 y M2.7 (febrero–marzo de 2026) – grandes modelos MoE con contexto de 196 mil tokens.
- Z.ai GLM 5.1 (7 de abril de 2026) – el lanzamiento más fresco de la lista, contexto de 202 mil tokens.
- MoonshotAI Kimi K2.5 (enero de 2026) – contexto de 262 mil tokens.
- StepFun Step 3.5 Flash (enero de 2026) – más compacta que el resto, pero muy usada en pipelines.
Ninguna de ellas se puede ejecutar en un portátil – funcionan vía API o self-hosted sobre hardware serio (64+ GB de memoria, configuraciones multi-GPU). Pero dibujan dónde está realmente el mercado abierto de IA.
gpt-oss-120b de OpenAI (agosto de 2025) – un caso raro de OpenAI publicando pesos abiertos. Modelo 120B MoE con adopción sostenida ocho meses después del lanzamiento. Para ejecución local requiere un Mac Studio con 64+ GB o una estación de trabajo con dos tarjetas gráficas.
Gemma 4 26B A4B de Google – esta es la versión de Gemma que realmente se usa en la práctica. No la 31B ni la 12B, sino precisamente la 26B en arquitectura MoE con 4 mil millones de parámetros activos por petición – de ahí el “A4B” del nombre. Contexto de 262 mil tokens, se ejecuta vía Ollama en un portátil de 16 GB más rápido que los equivalentes dense de la misma clase. La versión 4B corre en el móvil a través de Google AI Edge Gallery.
NVIDIA Nemotron 3 Super – contexto de 262 mil tokens, disponible gratis en OpenRouter. Elección popular para experimentos con agentes y pipelines donde no se quiere pagar por cada petición.
Mistral Nemo – modelo compacta para inferencia en CPU. Más modesta de escala que los líderes, pero en la categoría “funciona sin tarjeta gráfica” es una auténtica mula de carga.
Mención aparte para modelos que aparecen mucho en publicaciones técnicas pero menos en uso masivo: Llama 4 Scout, Llama 3.3 70B, Phi-4, Mistral Small 3.1. En instalaciones self-hosted aparecen con frecuencia – allí la elección responde más a integraciones y costumbre que a popularidad.
Qué hardware hace falta y qué vas a obtener
Aquí empieza la zona donde expectativas y realidad se separan más.
Opción mínima: cualquier portátil moderno con 16 GB de RAM
Un portátil con 16 GB de RAM y sin tarjeta gráfica dedicada arranca modelos de hasta 8–10B vía llama.cpp u Ollama usando únicamente el procesador. Funciona – pero lento.
La velocidad de generación en CPU va de 3 a 8 tokens por segundo. ChatGPT escupe texto a unos 40–80 tokens por segundo (eso que percibes como “escribe rápido”). 8 tokens por segundo son aproximadamente una o dos palabras cada dos segundos. Para respuestas largas se parece a una cámara lenta. Se puede usar, pero no siempre resulta cómodo.
Para tareas simples – resumir un texto corto, responder a una pregunta concreta – es perfectamente tolerable. Para un diálogo iterativo, cansa enseguida.
Opción buena: Mac serie M o RTX 3060 12 GB
Este es el umbral a partir del cual un LLM local empieza a sentirse como una herramienta real, no como una demo tecnológica.
Un Mac con chip M3, M4 o M5 y 16–32 GB de memoria unificada es, probablemente, la mejor plataforma para LLMs locales hoy. El motivo: la arquitectura unificada, donde CPU y GPU comparten la misma memoria, permite ejecutar modelos rápido sin tarjeta gráfica adicional. El framework MLX de Apple está optimizado para estos chips y rinde un 20–30% más rápido que el llama.cpp estándar sobre el mismo hardware.
Qwen 3.5 9B en un M3 Pro entrega unos 25–35 tokens por segundo. Gemma 4 26B A4B (MoE con 4B activos) en un M4 Max, 30–45 tokens por segundo y con una capacidad efectiva bastante mayor. Un Mac con 32 GB aguanta sin problema 15–30 tokens por segundo en modelos de clase 13B; con 64 GB, 25–50 tokens en modelos de 27–32B. Eso ya se siente como velocidad normal de chat. Desde marzo de 2026, Ollama adoptó oficialmente MLX como backend principal en Apple Silicon – es decir, con solo instalar Ollama en un Mac moderno ya obtienes rendimiento optimizado.
RTX 3060 12 GB – para usuarios de Windows, la vía más asequible para entrar a esta misma liga. La tarjeta de segunda mano cuesta alrededor de 200–250 EUR, y los 12 GB de VRAM bastan para ejecutar cómodamente modelos 7B y 14B. Gemma 4 26B A4B también cabe en 12 GB gracias a la arquitectura MoE. Qwen 3.5 27B dense no entra entero en 12 GB, pero Qwen 3.5 9B en una RTX 3060 da unos 20–40 tokens por segundo. En velocidad – más o menos como un buen Mac.
Un matiz terminológico importante. Inferencia es el proceso por el cual una modelo ya entrenada responde a tu petición (frente al entrenamiento, cuando se ajusta con datos). Inferencia en GPU significa que la modelo corre en la tarjeta gráfica, no en el procesador. La GPU multiplica matrices en paralelo decenas de veces más rápido que la CPU, y para modelos de lenguaje eso es la diferencia entre “un segundo de latencia” y “un minuto esperando”.
Para inferencia en GPU hace falta específicamente memoria de vídeo (VRAM), no RAM normal. Los 12 GB de VRAM de la RTX 3060 son 12 GB dedicados a la modelo. Si la modelo no cabe en VRAM, una parte se vuelca a la RAM y la velocidad cae varias veces.
Para entender qué obtienes con distintos tamaños de modelo, compara tres ejecuciones sobre la misma tarea: Gemma 4 26B A4B (la Gemma más popular en OpenRouter, realmente ejecutable en un portátil gracias al MoE), gpt-oss-120b (pesos abiertos de OpenAI, requiere Mac Studio o dos tarjetas) y DeepSeek V3.2 (buque insignia de la ecosistema abierta en la nube, ~37B activos en MoE):
En la práctica, Gemma 4 26B A4B dará una respuesta estructurada con separación de casos – mejor que una 8B típica, pero con una conclusión sistémica previsible. gpt-oss-120b propondrá una estrategia más matizada y planteará preguntas de aclaración relevantes, aunque la profundidad depende del prompt concreto. DeepSeek V3.2, a la altura de un buque insignia de la nube, devolverá una estructura con priorización, plazos realistas y una observación no trivial sobre los cuatro restantes. Esa es exactamente la diferencia por la que se paga en la nube.
Opción avanzada: 70B y superior
La clase 70B en compresión a 4 bits ocupa unos 48 GB de memoria (se necesitan 40 GB+ para calidad plena). Hace falta un Mac Studio con 64 GB, un servidor con varias tarjetas gráficas o una estación de trabajo con RTX 4090 de 24 GB más memoria adicional. La RTX 4090 lidia con Gemma 4 26B A4B y modelos dense de hasta 31B, dando 50–85+ tokens por segundo. gpt-oss-120b no entra en esta categoría – 120B MoE requiere 64+ GB de memoria unificada o dos tarjetas.
Velocidad en este tramo: 8–15 tokens por segundo. Calidad aproximándose a GPT-5 Mini. Pero el coste de entrada parte de los 2.000–3.000 EUR de hardware. Ya no es “probar en casa”, sino una inversión meditada con una justificación concreta.
¿20 tokens por segundo – es rápido o lento?
Esta es una pregunta que rara vez se explica de forma explícita.
Un token equivale aproximadamente a 3/4 de palabra en inglés, un poco menos en lenguas con palabras más largas. Veinte tokens por segundo son unas 15 palabras por segundo, o unas 900 palabras por minuto. Para comparar: una persona media lee entre 200 y 300 palabras por minuto.
Veinte tokens por segundo es rápido. Leerás más despacio de lo que escribe la modelo. Experiencia agradable.
Ocho tokens por segundo son, de media, 6 palabras por segundo. Sigue siendo legible, pero se nota la pausa en frases largas. Sirve para tareas sin prisa.
Tres tokens por segundo es prácticamente salida línea a línea. Una respuesta larga tarda lo suyo. Se puede trabajar, pero no hay diálogo fluido.
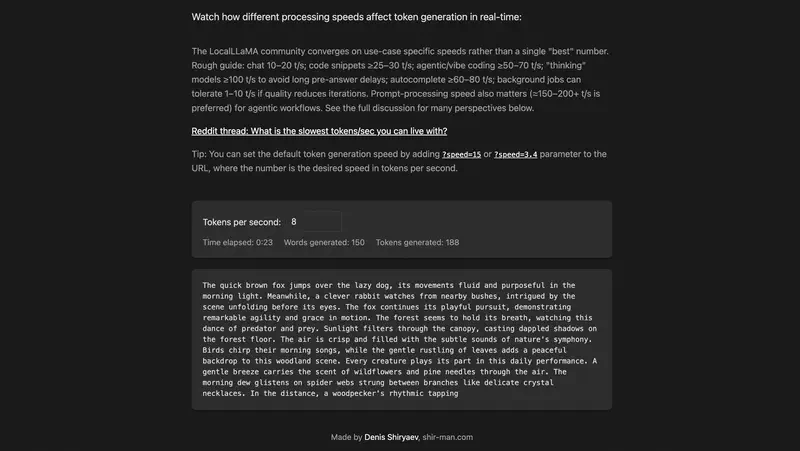
Cada una de las cifras anteriores es un enlace clicable al simulador shir-man.com/tokens-per-second, donde el texto aparece en tiempo real a la velocidad indicada. Un minuto de prueba explica la diferencia mejor que cualquier descripción.
Para referencia: GPT-5 entrega 40–80 tokens por segundo según la carga de los servidores. Con poca carga, más rápido; en hora punta, más lento. Una buena instalación local es perfectamente comparable en velocidad percibida.
Hay un matiz importante del que se habla poco: en las modelos de razonamiento (reasoning), la velocidad visible de escritura es solo la mitad de la historia. Antes de empezar a responder, una modelo así puede pasar varios minutos “pensando” por dentro – generando una cadena oculta de razonamiento que tú no ves. Una modelo de razonamiento local en un portátil puede gastar 5–10 minutos en análisis interno, y luego otro minuto escribiendo la respuesta a 20 tokens por segundo. En pantalla esto se ve así: has hecho la pregunta, el cursor parpadea, no ocurre nada – la modelo está trabajando. Es normal en modo reasoning, pero hay que estar preparado. En la nube lo mismo sucede en 10–30 segundos gracias a la potencia del datacenter. Para diálogo iterativo la diferencia es crítica; para una tarea de fondo (“piénsalo mientras me tomo un café”), no tanto.
Calidad: comparación honesta
Aquí hay que calibrar bien las expectativas.
Una modelo local de 8B no es lo mismo que GPT-5 o Claude Sonnet. Importa entenderlo antes, no después, de la descarga. En nuestro ranking de 54 modelos sobre tareas de gestión, GPT-5.4 sacó 4,8 sobre 5; Claude Sonnet 4.5, 4,78; Gemini 2.5 Pro, 4,46. Una modelo local típica de 8B caería en el rango de 2,8–3,3 – por ahí donde, en ese mismo ranking, están GigaChat-Ultra (3,26) y Llama 4 Maverick (2,95). No porque sean malas – simplemente otra categoría de tareas.
Las modelos concretas que sí se pueden ejecutar localmente, en nuestro benchmark se ven así: Gemma 3 12B sacó 3,58 (clúster 3), Qwen3 32B 3,67, Gemma 3 27B 3,75. Esto ya resulta más interesante: aproximadamente el nivel de Alice AI de Yandex (3,86), o un poco por debajo. Phi-4, la 3,8B de Microsoft que tanto se recomienda por su “inteligencia” en tests sintéticos, sacó apenas 2,27 – último puesto entre las 54 modelos. Buen recordatorio de que los benchmarks sintéticos y las tareas de gestión son cosas distintas. Consulta nuestro benchmark antes de elegir modelo.
Para 70B y superior la foto cambia. Modelos de esa clase no se probaron directamente en el benchmark, pero por parámetros se acercan al clúster 3 – orientativamente en la zona 3,5–3,8, es decir, al nivel de Qwen3 32B o un poco por encima. Ya es una herramienta seria para la mayoría de tareas cotidianas. La brecha con Claude Sonnet o GPT-5 se mantiene en tareas que requieren comprensión contextual profunda o razonamientos multi-paso – pero para resumir documentos, preparar borradores y consultas estructuradas es sustancialmente menor.
Para ver la brecha con tus propios ojos – aquí va un GPT-5.4 Nano de bajo coste contra el buque insignia GPT-5.4 sobre una tarea típica de gestión. GPT-5.4 Nano cuesta un orden de magnitud menos y en velocidad de respuesta es comparable a una modelo local 70B decente. Mira qué se pierde al elegir una modelo más débil:
La diferencia no está en la belleza de las frases, sino en la profundidad del análisis: la mini-modelo suele tratar las tres causas como equivalentes y dar recomendaciones genéricas; el buque insignia distingue síntomas de causa raíz y pregunta al grano. Una 70B local se comporta más cerca de la mini-modelo; una 8B local, bastante peor.
Escenarios concretos donde una 8B local funciona bien:
- Resumir documentos y transcripciones de reuniones
- Generar borradores de correos e informes por plantilla
- Preguntas-respuestas simples sobre un documento cargado
- Formatear y estructurar texto
Escenarios donde conviene volver a la nube:
- Análisis complejos con conclusiones no evidentes
- Trabajo con hipótesis en competencia
- Tareas donde importa la precisión factual
- Instrucciones largas multi-paso con condiciones
Saber qué IA usar y cuándo es exactamente lo que trabajan las 9 tareas prácticas del módulo abierto. Pruébalo gratis, sin registro.
Sin pago requerido • Notificación al lanzamiento
El smartphone como plataforma local
Tema aparte: hace un año era un experimento, ahora es un escenario perfectamente funcional.
Gemma 4 4B de Google (salió el 2 de abril de 2026) es una de las opciones móviles clave. Corre vía Google AI Edge Gallery para iOS y Android, se descarga una vez y funciona totalmente offline. En un iPhone 16 Pro con chip A18 Pro y 8 GB de memoria (1.100 EUR) o en un Samsung Galaxy S24/S25 Ultra (900 EUR) – unos 15–20 tokens por segundo. Phi-4 3,8B de Microsoft da velocidad similar en los mismos dispositivos. Llama 3.2 3B y Qwen 3.5 4B también se pueden ejecutar vía PocketPal o MLC LLM.
Qwen 3.5 en versiones 0,8B y 4B también corre en teléfonos vía PocketPal. Velocidad en móviles flagship (iPhone 17 Pro, Pixel 9 Pro, Samsung S24/S25) – 5–20 tokens por segundo. En gama media con 6 GB de RAM el resultado es más modesto; para una ejecución cómoda hacen falta al menos 8 GB de memoria.
El valor práctico del móvil está limitado a unos pocos escenarios: analizar un documento confidencial donde no hay internet, un borrador rápido sin nube, una demo de concepto. Para trabajo regular, la pantalla y el interfaz del teléfono no son el mejor entorno. Pero como posibilidad – es real.
Herramientas: qué instalar
Ollama – la forma más sencilla de empezar. Se instala como un programa normal, las modelos se descargan con un solo comando (ollama pull qwen3.5:9b) y funciona vía navegador o cualquier aplicación con API compatible con OpenAI. Desde marzo de 2026 usa MLX en Apple Silicon. Recomendado para la mayoría.
LM Studio – es Ollama con interfaz gráfica. Si la línea de comandos te incomoda, LM Studio te deja hacer lo mismo por interfaz visual: elegir modelo, descargar, arrancar chat. Un poco más pesado en recursos.
Jan – opción open-source con énfasis en privacidad. Funciona totalmente offline y no envía telemetría. Si la confidencialidad es la motivación principal, merece la pena mirarlo.
llama.cpp – el motor base sobre el que se apoyan las tres herramientas anteriores. Herramienta de consola para quien quiera control máximo. Para un manager sin background técnico – probablemente no.
MLX de Apple – librería directa de Apple para ejecutar modelos en Silicon. Se usa dentro de Ollama, pero también se puede usar directamente. Da un 20–30% de mejora de velocidad frente a llama.cpp.
La IA local es solo uno de los formatos de trabajo. En el módulo abierto hay 9 tareas de manager con distintas herramientas, tanto en nube como en local. Pruébalo gratis.
Sin pago requerido • Notificación al lanzamiento
Modo agente: modelo local con acceso a tus archivos
Si has leído sobre OpenCode o sobre análisis agéntico de datos, te surge una pregunta lógica: ¿se puede ejecutar un agente en local, sin mandar los datos a la nube?
Sí, y es probablemente el escenario más interesante para managers que trabajan con documentos confidenciales.
OpenCode, que ya analizamos en detalle, soporta conectar modelos locales vía Ollama. El esquema: Ollama arranca la modelo en local y abre una API en el puerto 11434. OpenCode se conecta a esa API en lugar de al Claude de la nube. Los datos no salen del equipo. El agente lee tus archivos, los analiza, escribe resultados – todo localmente.
Limitación previsible: una 8B local en modo agente lidia con tareas más simples que Claude o GPT-5. Para analizar uno o dos documentos con preguntas concretas – sirve. Para una investigación compleja multi-archivo con conclusiones no triviales – la brecha se va a notar. Como mostramos con un ejemplo concreto, la calidad del análisis agéntico la define, en primer lugar, la modelo, no el framework.
Con una modelo 32B o superior, la brecha se reduce bastante. Si tienes un Mac Studio con 64 GB o una estación con dos tarjetas gráficas, el modo agente local con 32B se convierte en un sustituto real de la nube para la mayoría de tareas.
Punto mínimo de entrada: qué comprar
En corto:
Para empezar – un Mac con chip M3 o M4 y 16 GB de memoria. Si ya tienes ese Mac, ya tienes el hardware. Ollama se instala en 5 minutos y puedes arrancar Qwen 3.5 9B o Gemma 4 26B A4B hoy mismo.
Para trabajar cómodo con modelos de 14–32B – un Mac con 32 GB o un PC con RTX 3060/4060 de 12 GB. La RTX 3060 de 12 GB en el mercado de segunda mano cuesta unos 200–250 EUR – la vía más barata para una experiencia decente en Windows.
Para sustituir la nube sin concesiones – un Mac Studio con 64 GB (ya una inversión seria) o una estación de trabajo con dos tarjetas gráficas (unos 3.000 USD).
Hay que decirlo con honestidad: para la mayoría de managers la respuesta óptima no es “pasarse a modelos locales”, sino usarlas como complemento a la nube. La nube para tareas complejas donde importa la calidad. En local, para datos confidenciales, trabajo offline y los casos en los que no tiene sentido pagar a la nube por operaciones simples.
Lo que normalmente no queda claro
Hay varias cosas que suelen descubrirse después de instalar, no antes.
El tamaño de descarga es el tamaño final en disco. Una 8B en Q4 pesa unos 5 GB. Una 32B, unos 20 GB. Ollama guarda las modelos descargadas en una carpeta del sistema; a veces te quedas sin espacio en un disco pequeño sin darte cuenta.
El primer arranque tarda. Ollama carga la modelo en memoria en la primera petición – pueden ser 30–60 segundos para una modelo grande. Después se queda residente y las siguientes consultas van rápidas.
Un prompt de sistema en el idioma objetivo funciona mejor que su ausencia. La mayoría de modelos se entrenan con datos mixtos, pero responden en el idioma en el que les hablas. Indicar explícitamente “responde en español” al comienzo de la sesión ayuda.
Para comparar la calidad de modelos locales y en nube en tareas de gestión, tenemos nuestro benchmark público – ahí puedes ver exactamente dónde pierden calidad determinadas modelos respecto a las top de la nube.
Por último, que se pueda ejecutar una modelo en local no significa que haya que hacerlo siempre. Es una herramienta más con condiciones de uso bien definidas. De ese mismo skill – saber cuándo cada herramienta es pertinente – va nuestro programa formativo.
Curiosamente, la lógica de elegir herramienta – nube o local, 8B o 70B, agente o chat – es exactamente el mismo tipo de skill que formular bien las tareas para la IA. Las herramientas cambian cada pocos meses; la capacidad de calibrar expectativas y elegir enfoque según el problema, se queda.

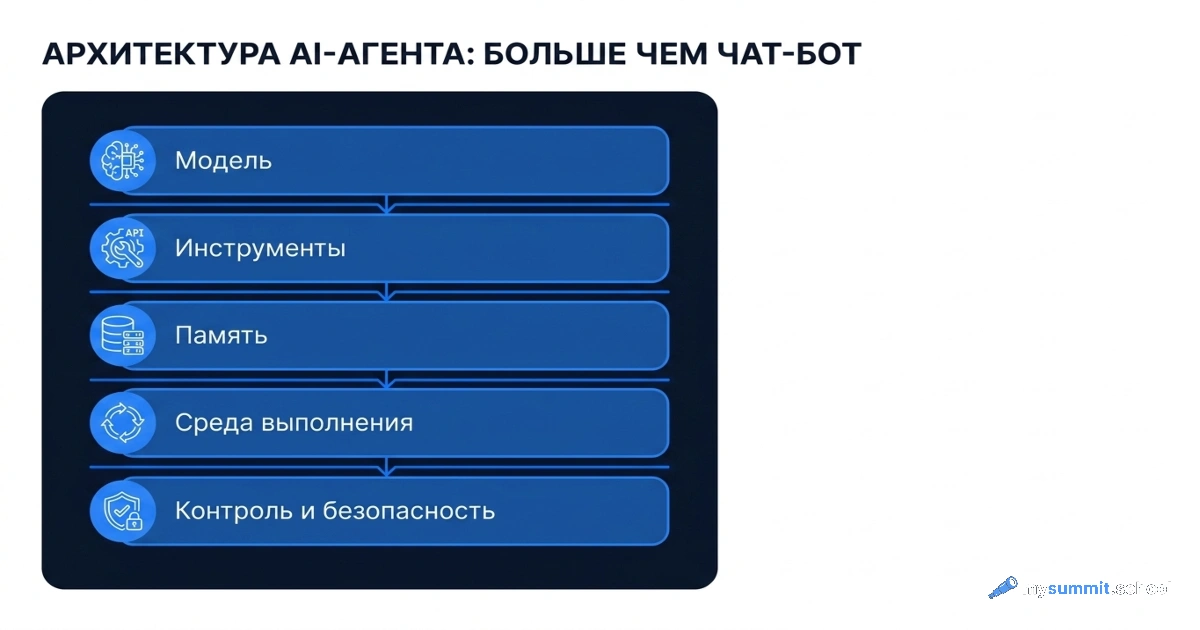


De la herramienta al sistema
El Fundamento enseña a trabajar con cualquier IA – en nube, local, agéntica. La especialización 'Project Manager' añade escenarios concretos para tareas de gestión. Mira la estructura completa del programa.

Stanislav Belyaev
Engineering Leader en Microsoft18 anos liderando equipos de ingenieria. Fundador de mysummit.school. 700+ graduados en Yandex Practicum y Stratoplan.