Make Weak Model Great Again: cuando el prompting es tu única opción
No todos los managers tienen acceso a GPT-5.4 o Claude. En Rusia, un proyecto de ley sobre «modelos de confianza» podría restringir el uso de modelos extranjeros en organismos estatales e infraestructura crítica a partir de septiembre 2027 – dejando a GigaChat, Alice (YandexGPT) y pocos más como únicas opciones. Pero este no es solo un problema ruso. Cualquier organización que despliega un modelo local de Llama por privacidad de datos, usa Phi o Mistral por costes, o simplemente trabaja con un modelo más barato que el líder del mercado – se enfrenta a la misma pregunta.
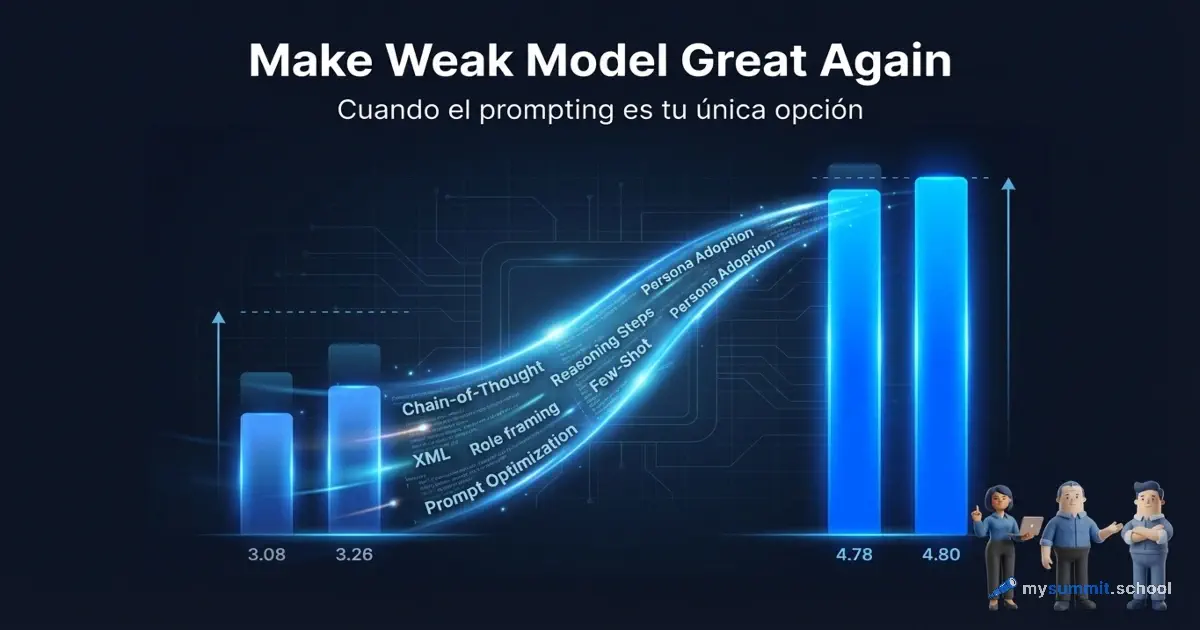
En nuestro estudio de 54 modelos, GigaChat obtuvo 3,26 de 5; GPT-5.4 – 4,80. Una brecha del 32%.
Si el modelo que tienes es lo mejor a lo que puedes acceder – por regulación, por presupuesto, por política de seguridad – ¿puede la ingeniería de prompts cerrar esa distancia?
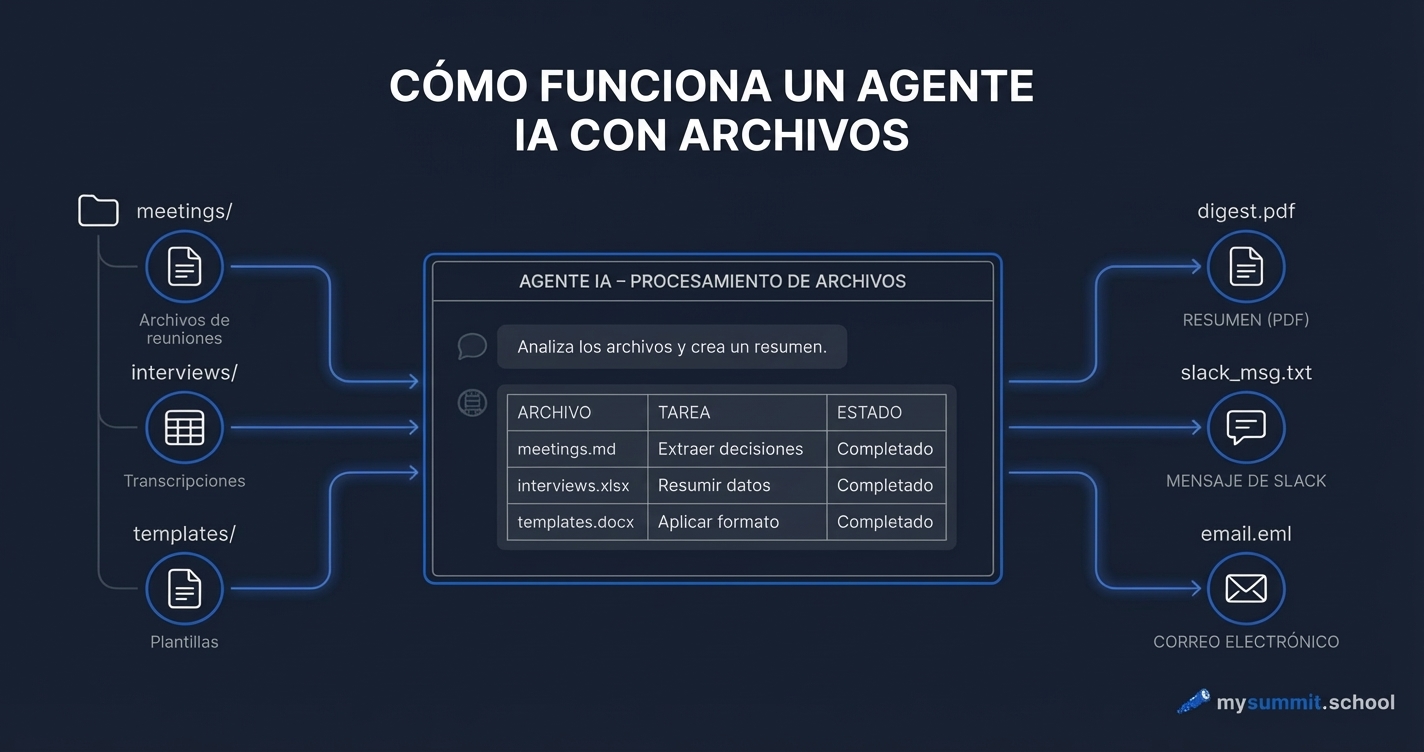
Qué hacemos y por qué
El experimento «Make Weak Model Great Again» toma cuatro modelos accesibles en Rusia – GigaChat-Ultra, GigaChat-2-Max, Alice AI (YandexGPT) y Qwen3 Max – y los somete a diez técnicas de prompting en seis tareas de gestión: desde el análisis de métricas de e-commerce hasta derecho laboral ruso. Como referencia, las mismas tareas se resuelven con GPT-5.4 y Claude Sonnet 4.6 usando prompts ingenuos – para fijar el techo al que aspiran los modelos débiles.
Pero aquí viene lo relevante para un público global: GigaChat y Alice son simplemente ejemplos concretos de modelos débiles. Los resultados se aplican a cualquier modelo que se quede corto frente a la frontera – ya sea un Llama 3.3 ejecutado localmente, un Mistral fine-tuneado para tu dominio, o un Phi desplegado en un servidor corporativo. La pregunta subyacente es universal: ¿cuánto rendimiento extra puede extraer un buen prompt de un modelo limitado?
Las técnicas van desde las más sencillas, que cualquier manager puede aprender en un minuto (asignación de rol, plantilla estructurada), hasta diálogos en múltiples pasos donde el modelo primero analiza, luego se autocritica, luego revisa su respuesta. Entre ambos extremos – Chain-of-Thought («piensa paso a paso»), ejemplos Few-Shot (mostrar un modelo de respuesta buena) y estructura XML del prompt, que normalmente usan desarrolladores, no managers.
Pero dos técnicas hacen este experimento realmente inusual: CAPS EMPHASIS y tono agresivo. Internet está lleno de consejos tipo «escribe en MAYÚSCULAS y el modelo obedecerá» o «insúltalo, dará mejores respuestas». Algunos citan un estudio de Microsoft de 2024, otros – simplemente experiencia personal. Base científica detrás de esto casi no hay, y menos aún para modelos no anglófonos. Incluimos ambas técnicas para verificar de una vez por todas: ¿funciona – o es una leyenda urbana del prompt engineering?
Por qué la respuesta no es obvia de antemano
Parecería que mejor prompt -> mejor resultado. Pero con modelos pequeños todo es más complejo, y la investigación existente lo confirma.
Wei et al. (Google Brain, 2022) demostraron que Chain-of-Thought – la técnica que fuerza al modelo a «pensar paso a paso» – funciona excelente en modelos grandes. Pero en modelos pequeños provoca razonamientos «seguros pero incorrectos». El modelo produce cinco pasos que parecen lógicos – y llega a una conclusión errónea. Peor que si hubiera respondido directamente. ¿Cae GigaChat en esta trampa? No lo sabemos. ¿Y tu Llama local? Tampoco.
Zhang et al. (ACL 2024) descubrieron algo aún más incómodo: los modelos pequeños son físicamente incapaces de detectar sus propios errores. Cuando les pides «encuentra los puntos débiles de tu respuesta y mejórala», el modelo no se autocritica – se «autoconfirma». Reformula ligeramente sin cambiar la esencia. Si nuestros datos confirman esto – es una conclusión concreta: no pierdas tiempo con «mejora tu respuesta» en un modelo débil.
Y luego está el techo arquitectónico. Los prompts reorganizan lo que el modelo ya sabe. No pueden crear conocimiento que no existe en los pesos del modelo. Si GigaChat no «leyó» el Código Laboral ruso durante el entrenamiento – ningún prompt «eres un abogado experto en derecho laboral ruso» lo hará citar el código correctamente. Lo mejor que se puede lograr es que diga «no lo sé» en lugar de una alucinación confiada. Lo mismo aplica a un Llama local que nunca vio datos de tu industria específica.
Un dato contraintuitivo de nuestro benchmark: GigaChat y Alice – modelos entrenados en ruso – mostraron resultados más bajos que GPT-5.4 en tareas vinculadas a la realidad rusa. Derecho laboral, mercados regionales, especificidades del negocio local – en todos estos temas el modelo extranjero resultó más fuerte que los nativos. Probablemente GPT-5.4 simplemente «leyó» más material gracias a su escala. Esta es una de las preguntas clave del experimento: ¿dónde está el límite a partir del cual ningún prompt compensa la brecha de conocimiento?
Las técnicas de prompting de este estudio se integrarán en los materiales del curso. Prueba 9 tareas prácticas de gestión en el módulo abierto – gratis, sin registro.
Sin pago requerido • Notificación al lanzamiento
Aplicabilidad global: no solo un problema ruso
Hemos usado GigaChat y Alice como sujetos de prueba porque el contexto regulatorio ruso ofrece un caso extremo y muy concreto: managers que literalmente podrían perder acceso a los modelos líderes. Pero la situación es más universal de lo que parece.
Un manager europeo que despliega Llama 3.3 en servidores propios por cumplimiento de GDPR se enfrenta exactamente al mismo dilema. Una startup que usa Mistral o Phi para mantener costes bajo control – también. Una empresa china que opera con modelos locales por restricciones similares – igual. En todos estos casos la pregunta es idéntica: dado que no puedo (o no quiero) pagar por el modelo frontera, ¿puede el prompting cerrar la brecha?
Nuestro experimento mide exactamente eso. Los modelos específicos son rusos; la pregunta es global.
Qué obtiene el manager al final
Hacemos esto intencionalmente como investigación aplicada, no académica. Los trabajos científicos sobre modelos pequeños suelen enfocarse en optimización automatizada – fine-tuning, DSPy, mejora algorítmica de prompts. A nosotros nos interesa otra cosa: ¿qué puede hacer un manager cualquiera que tiene un modelo débil y cinco minutos para formular su consulta?
Para cada técnica evaluamos no solo la calidad del resultado, sino el esfuerzo – cuánto tiempo lleva reformular el prompt. Porque una técnica que mejora la respuesta un 15% pero requiere 20 minutos de preparación, al manager no le sirve.
Al final se publicarán tres cosas. Primera – un mapa «técnica -> modelo -> tarea»: si tienes GigaChat para análisis de documentos, ¿qué enfoque usar? ¿Y si es Alice para redactar un email? ¿O un Llama local para resumir informes internos? Segunda – plantillas listas en ruso para tareas específicas de gestión (con la lógica transferible a cualquier idioma). Y tercera – un límite honesto: en qué escenarios el prompting no ayuda y es mejor cambiar de modelo.
Todo esto se integrará en el curso – en la sección donde la teoría de prompt engineering se encuentra con los datos. No «qué es un prompt», sino «qué funciona realmente, en qué herramienta, para qué tarea».
Qwen3 Max, Alice, GigaChat – accesibles sin VPN. Pon a prueba tu enfoque de prompting con tareas reales de gestión en el módulo gratuito del curso.
Sin pago requerido • Notificación al lanzamiento
Cuándo esperar los resultados
El experimento está en fase de lanzamiento. El informe completo se publicará aquí, en el blog – con el análisis de cada técnica, plantillas concretas y una conclusión honesta sobre dónde está el techo. Si trabajas a diario con un modelo que no es el mejor del mercado – ya sea GigaChat, un Llama local o cualquier otra alternativa al líder – la respuesta a tu pregunta está en preparación.
La herramienta ya la tienes. Ahora – la habilidad
La base del curso desglosa el prompt engineering con tareas reales de gestión: estructura, asignación de roles, descomposición, CoT. La especialización para managers profundiza su aplicación en planificación, analítica y trabajo en equipo.