Agent vestluse asemel: andmeanalüüs ilma copy-paste'ita
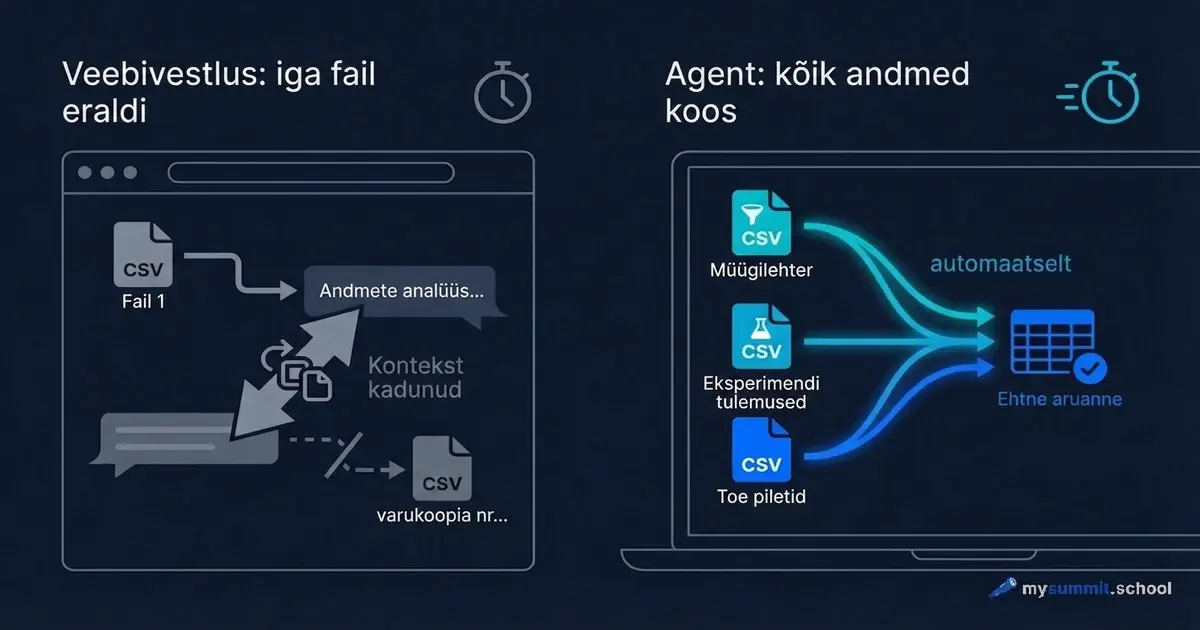
Sul on kolm andmefaili: aktiveerimise lehter, A/B-testi tulemused ja klienditoe piletid. Ülesanne – mõista, miks onboarding logiseb. Avad ChatGPT, laed esimese faili üles, esitad küsimuse. Saad vastuse. Laed teise faili. ChatGPT küsib: “Kas saaksid konteksti meelde tuletada?” Laed kolmanda. Esimese faili kontekst on juba välja tõrjutud.
Nelikümmend minutit hiljem on sul kolm eraldi vestlust, ja ükski neist ei vasta algsele küsimusele. Sest küsimus oli üks, aga andmed – kolmes eri kohas.
See ei ole ChatGPT probleem. See on lähenemise probleem.
Kaks viisi andmetega töötada
Erinevus “vestluse brauseris” ja “agendi sinu sülearvutis” vahel ei peitu mudeli võimsuses. See peitub selles, kes kelle juurde läheb.
Vestluses sina tood andmed mudeli juurde. Tükkhaaval, failide üleslaadimise kaudu, ühe vestluse piires. Mudel vastab sellele, mida ta näeb praegu. Järgmine sõnum – juba veidi teine kontekst.
Agentses režiimis tuleb mudel sinu andmete juurde. Agent installitakse sülearvutisse nagu tavaline rakendus, näeb kausta sinu failidega ja töötab nendega otse – nagu analüütik, kellele on antud ligipääs sinu arvutile. Sa kirjutad talle ülesande tavalise tekstina, nagu Slackis – ta loeb failid, arvutab, salvestab tulemuse. See on seesama BYOA idee – aga praktilises, mitte kontseptuaalses mõõtmes.
Erinevus tundub tehniline. Praktikas muudab see kõike.
Konkreetne ülesanne, kaks lahendamise viisi
Kujutame ette reaalset stsenaariumi. SaaS-teenuse tootejuht märkab: uute kasutajate konversioon aktiivseteks on jäänud neljaks kuuks järjest 38% peale. Laual on kolm tabelit andmetega.
Esimene – onboardingu lehter: registreerimine, esimene tegevus, teine tegevus, kolleegi kutsumine.
Teine – uue onboardingu funktsiooni A/B-testi tulemused: kontroll- ja testgrupp, kummaski 500 ettevõtet.
Kolmas – 350 klienditoe piletit uutelt kasutajatelt viimase kvartali jooksul.
Küsimus: millisel sammul inimesed kaovad, miks, ja kas katse töötas?
Variant 1: ChatGPT, veebiliides
Laed lehtri üles. ChatGPT analüüsib seda ja leiab peamise langusekoha. Hea. Laed piletid üles – tahad mõista, mille üle kasutajad just sellel sammul kurdavad. ChatGPT ütleb: “Näen pileteid. Tuleta meelde, millisel sammul oli langus?” Sa selgitad. Ta analüüsib.
Laed üles testi tulemused. Uus fail. ChatGPT näeb neid, aga ei mäleta enam esimese faili täpseid lehtri numbreid – millises segmendis oli konversioon 55% ja millises 38%. Selleks, et neid kõrvutada, tuleb numbrid käsitsi esimesest vestlusest kopeerida ja kolmandasse kleepida.
Tulemus tunni pärast: kolm eraldi järeldust, mis tuleb käsitsi üheks kokku sulatada. Ja veel küsimus: mis siis, kui kuskil on ümardatud või read segi läinud? Seda kontrollida ei saa.
Variant 2: agent sülearvutis
Avad kausta, kus on kolm tabelit, ja kirjutad agendile ühe sõnumiga – nagu analüütikule Slackis:
“Vaata aktiveerimise lehtrit. Leia peamine langusekoht. Seejärel ava piletid ja vaata, millised kaebused on selle sammuga seotud. Lõpuks kontrolli testi tulemusi – kas katse töötas tervikuna ja põhikliendisegmendis.”
Agent avab kõik kolm faili. Loeb need läbi. Kirjutab lehtri analüüsimiseks programmikoodi, käivitab selle, saab numbrid. Läheb piletite juurde, grupeerib teemade kaupa, loeb sagedused kokku. Laeb testi andmed, võrdleb gruppe, kontrollib statistikat. Kõigi kolme faili tulemused on samaaegselt ühes kontekstis.
Kogu protsess võtab mõne minuti. Sa näed, kuidas agent täpselt arvutas – ja saad iga sammu kontrollida.
Agentne andmeanalüüs on üks kursuse teemadest. Proovi 9 juhi praktilist ülesannet avatud moodulis – tasuta, ilma registreerimiseta.
Makset ei nõuta • Teavitus käivitumisel
Mis põhimõtteliselt muutub
Mitu asja, mis tunduvad väikesed, aga määravad analüüsi kvaliteedi erinevuse.
Agent näeb üheaegselt, et kolmandal lehtri sammul on väljalangevus 45%, et 31% piletitest on kaebused just sellele sammule, ja et katses näitas sihtsegment +13,8 pp. Neid kolme fakti ei pea käsitsi kokku tooma – need on juba ühes väljundis.
Lisaks säilitab agent selle, kuidas ta täpselt arvutas. Homme saabuvad järgmise kuu andmed – sa käivitad sama analüüsi uuesti ilma lisapingutuseta. See pole enam ühekordne küsimus, vaid rutiin. Just siin peitub TI varjatud maks: 37% säästetud ajast kulub selleks, et tulemust kontrollida ja ümber teha. Kui sul on kood, saab kontrollida sekunditega.
Lõpuks viitab agent konkreetsetele ridadele tabelis. Sa saad avada algfaili ja kontrollida. Vestluses ütleb mudel “enamik keskmise suurusega ettevõtteid” – ja on võimatu aru saada, kas see on reaalne muster või hallutsinatsioon.
Millal agent ikkagi hallutsineerib
Aus lõik, sest agent ei ole maagia.
Agent hallutsineerib samas kohas, kus vestluski: siis, kui ta sõnastab tõlgendusi, mitte ei arvuta. Kui ta arvutab – sa näed konkreetse arvutuse tulemust. Aga kui agent ütleb “see viitab UX-probleemile” – see on tema tõlgendus ja see võib olla väär.
Hea võte: pärast iga järeldust palu agendil “näita, millistest tabeliridadest see järeldub”. Agent peaks vastama konkreetsete näidetega või näitama andmete lõiku. Kui ta hakkab sõnadega selgitama ilma andmetele viitamata – tähendab see, et ta tõlgendab, mitte ei loe.
Teine moment: agent ei tunne sinu ärikonteksti. Ta leiab, et testgrupis kasvas konversioon tervikuna 4 pp ja 51–200 töötajaga segmendis +13,8 pp. Aga järeldus “kas käivitada 100%-le või mitte” – see on sinu. Selleks tuleb teada, milline segment on siht, milline on turg, milline on arenduse maksumus.
Agent annab täpsed andmed. Otsuse teed sina.
Mida näitab reaalne kolme faili analüüs
Vaatame konkreetselt, mida agent sellise andmekomplekti juures leiab.
Aktiveerimise lehter (500 ettevõtet). Agent arvutab igal sammul konversiooni. Esimene samm – 77%, suhteliselt normaalne. Teine samm – 55%. See on probleem: 385 ettevõttest, kes sooritasid esimese tegevuse, lähevad järgmisele vaid 210. Siin kaob rohkem kui pool potentsiaalsetest aktiivsetest kasutajatest.
Agent sõnastab selle nii: “peamine langusekoht on üleminek sammult 2 sammule 3, 45% ei lähe edasi”. Mediaanaeg – 8 tundi, samas kui esimene samm võttis 2 tundi. See tähendab, et kasutajad tulevad tagasi, aga ei vii järgmist tegevust lõpuni.
Klienditoe piletid (350 tükki). Agent grupeerib teemade kaupa. Avastab: 31% piletitest – küsimus “kuidas objekti käsitsi lisada?”. Veel 27% – probleemid välise allika ühendamisel. 19% – failide üleslaadimine.
See kinnitab lehtri hüpoteesi: inimesed ei saa aru, kuidas sooritada teist tegevust. UX on ebaintuitiivne.
Agent teeb ka lisasammu, mida sa vestluses tõenäoliselt ei palukski: segmenteerib piletid ettevõtte suuruse järgi. Leiab, et keskmise suurusega ettevõtted (50–200 töötajat) küsivad käsitsi lisamise kohta kaks korda sagedamini kui väikesed. See on toote sihtsegment – mis teeb probleemi tähtsamaks.
Testi tulemused (1 000 ettevõtet, kaks gruppi). Topline: kontroll 38,4%, test 42,4%, juurdekasv +4 pp – tundub pettumust valmistav. Prognoosisid rohkemat, statistika piiri peal.
Agent segmenteerib ettevõtte suuruse järgi. Segmendis 51–200 töötajat: kontroll 39,2%, test 53,0%, juurdekasv +13,8 pp – tugev tulemus. Just sihtsegmendi jaoks katse töötas.
Just see muutus – “ebaõnnestunud katselt” “võiduks sihtsegmendis” – avastab agent, sest tal on kõik kolm faili samaaegselt kontekstis. Vestluses peaksid selle küsimuse eraldi esitama ja pole kindel, et see üldse tekiks.

Millal agenti EI ole vaja
Agentne režiim pole alati õigustatud.
Kui on vaja kiiresti vaadata keskmist väärtust väikeses 50-realises tabelis – ChatGPT saab sellega kiiremini hakkama. Lisatööriista avama ei pea.
Kui andmed on konfidentsiaalsed ja sa ei saa lõpuni aru, kuidas tööriist töötab – parem selgita see endale enne välja. Pilvepõhised mudelid (ChatGPT, Claude) töötlevad andmeid teenusepakkuja serverites. See võib NDA all olevate andmete puhul olla vastuvõetamatu. Agent, mis töötab sülearvutis lokaalse mudeliga, on teine stsenaarium, aga see nõuab eraldi ettevalmistust.
Kui ülesanne on teksti kirjutada, struktuuri välja mõelda, lahendust arutada – agent eeliseid ei anna. Tema väärtus on just failidega töötamises.
Kuidas alustada: tööriistad ja mudelid
Tööriistadest, millest kõige sagedamini räägitakse: Claude Code Anthropicult (nõuab tellimust 100 $ kuus), Kilo Code (VS Code’i laiendus, hea neile, kes juba koodiga töötavad), OpenCode (avatud lähtekood, töötab mis tahes mudeliga).
Kui tahad odavalt alustada, siis OpenCode koos hiina mudelitega tuleb kõige soodsamalt välja. Kimi K2 ja DeepSeek maksavad sendi murdosasid päringu kohta ning struktureeritud andmete analüüsil ei jää kvaliteedilt GPT-4o-le alla.
OpenCode installitakse tavalise rakendusena ja käivitub kaustast sinu failidega. Esimene analüüs – 15 minutit pärast paigaldust. Täpsemalt sellest, kuidas see praktikas töötab, loe OpenCode’i artiklist. Sealsamas kolm ülesannet, mida tasub esimesel päeval proovida.
Agent loeb faile, arvutab, segmenteerib andmeid. Kontrolli oma analüüsi lähenemist 9 reaalse juhi ülesandega – tasuta, ilma registreerimiseta.
Makset ei nõuta • Teavitus käivitumisel
Mis töös muutub
Agentne analüüs pole analüütiku asendaja. See on viis eemaldada hõõrdumine küsimuse ja vastuse vahelt.
Varem oli “tahan aru saada, miks meetrika logiseb” ja “siin on kolme faili analüüs segmenteerituna” vahel mitu tundi tööd või päring analüütikule, mille vastuseaeg oli mitu päeva. Nüüd – mõni minut.
See muudab, milliseid küsimusi üldse esitatakse. Kui analüüs on kallis, esitatakse ainult olulisi küsimusi. Kui odav – hakatakse kontrollima hüpoteese, mis varem tundusid päringu jaoks liiga ebaolulised.
Meie kolme faili näites juhtuski täpselt nii. Testi topline nägi kehv välja – +4 pp, statistika piiri peal. Tavaline järeldus: itereerida või tappa. Aga agent segmenteeris andmed mõne sekundiga – ja selgus, et sihtsegmendi jaoks on tulemus tugev (+13,8 pp). See on otsus “käivitada” “tapmise” asemel.
Üllatuslikult pole kõige olulisem siin kiirus. Olulisem on teine asi: analüüs muutub korratavaks. Kuu pärast, kui saabuvad uued andmed, käivitad sama analüüsi uuesti. See pole enam ühekordne vastus – see on analüütiline rutiin.
Võib-olla tasub eristada kahte andmetega töötamise liiki: ühekordsed küsimused (neile sobib vestlus hästi) ja regulaarsed analüütilised rutiinid (nende jaoks muudab agent olukorda põhimõtteliselt). Enamik PM-ülesandeid, mis reaalselt otsustele mõju avaldavad – lehtrid, kohordid, katsed – on teist tüüpi.
Mis edasi: agent sinu andmetel
See artikkel näitas üht tüüpi ülesannet – kolme tabeli ühekordset analüüsi. Aga agendi tegelik väärtus ilmneb hiljem: kui analüüs lakkab olemast ühekordne ja muutub rutiiniks.
See pole enam “agendi kasutamine”, vaid “isikliku agendi ehitamine” – oma rutiinidega, ühendatud sinu reaalsete andmetega.
Just sellele ongi pühendatud kursus “Isiklik agent juhtidele”, mille me käivitame. Mõned konkreetsed asjad selle artikli kõrvale:
- Sa alustad reaalsete andmetega esimesest päevast – juba kolmandaks päevaks töötab agent sinu päris postkastiga. Sa laadid selle sülearvutisse tavalise failina, ilma IT-osakonna osaluseta.
- Kursuse jooksul kogud valmisstsenaariumide komplekti oma ülesannete jaoks – need jäävad sulle pärast kursust alles.
- Iga bloki järel laed töö tulemuse üles ja saad personaalse tagasiside – mitte enesehinnangu, vaid reaalse feedbacki.
- Elav Q&A autoriga, kursusekaaslaste Telegrami kanal, juhtumite lahtimõtestamine.
- Kursus on üles ehitatud tööriistadele, mis on saadaval kõigile. Kogu kursuse maksumus – mõni dollar mudeli päringute eest.
Kursus valmistub käivitamiseks. Kui tahad esimesse kohordi pääseda – registreerimisvorm on veidi eespool.
Tööriist on olemas. Nüüd on vaja oskust
Kuni kursus 'Isiklik agent' valmistub käivituseks, alusta alustest: kursuse vundament katab promptide inseneeria ja kriitilise mõtlemise – ilma nendeta annab agent numbreid, aga mitte insighte. Spetsialiseerumine 'Tootejuhtimine' käsitleb TI-andmeanalüüsi ja agentidega töötamist PM-ülesannetel.



Stanislav Belyaev
Engineering Leader Microsoftis18 aastat insenerimeeskondade juhtimist. mysummit.school asutaja. 700+ lopetajat Yandex Practicumis ja Stratoplanis.