9 küsimust iseendale: kas sina kasutad AI-d või AI – sind?

Hiljuti koostasin uuele kliendile kommertspakkumist. Summa oli ebastandardne, tingimused – samuti. Sisetunne ütles: pane X, sa tunned seda turgu. Kuid ma otsustasin Claude’i kaudu „üle kontrollida". Mudel andis argumenteeritud vastuse teise numbriga – 15% madalam kui minu hinnang. Kõlas veenvalt. Ma muutsin numbri.
Nädal hiljem allkirjastas klient ilma kauplelemata. Ja rahulduse asemel tundsin ärritust: mis siis, kui mu algne number oleks samuti läbi läinud? Ma ei saa seda kunagi teada – sest otsuse tegemise hetkel surusin alla oma hinnangu „statistiliselt põhjendatud" algoritmi vastuse nimel.
Just see ongi muster, mida Anthropicu uurijad nimetavad Disempowerment – kontrolli kaotamine. Mitte dramaatiline, mitte ilmne. Lihtsalt vaikne „mina otsustasin" asendamine „AI soovitas" vastu.
See on kolmas ja viimane artikkel uuringu „Who’s in Charge? Disempowerment Patterns in Real-World LLM Usage" (Sharma et al., 2026) analüüsi seerias. Esimeses osas vaatasime, kuidas vanemad ja üliõpilased delegeerivad AI-le instinkte ja õppimist. Teises – kuidas juhid kaotavad juhtimisintuitsiooni. Siin on praktiline tööriist: 9 küsimust, mis aitavad mõista, millises kontrolli kaotamise staadiumis sa oled.
Kolm kontrolli kaotamise telge: lühike meeldetuletus
Anthropicu uuring, mis põhineb 1,5 miljoni reaalse dialoogi analüüsil Claude.ai-ga, eristab kolme tüüpi „moonutusi", mille kaudu AI võib meid subjektsusest ilma jätta:
Reaalsuse moonutamine (Reality Distortion) – AI kujundab sinus valesid või kontrollimata veendumusi. Kõige levinum mehhanism – lipitsev valideerimine: mudel kinnitab seda, mida sa tahad kuulda, selle asemel et öelda tõtt. Tõsiseid juhtumeid – 1 igast 1 300 dialoogist, kuid mõõdukaid – juba 1 igast 50-st.
Väärtuste moonutamine (Value Judgment Distortion) – AI teeb moraalseid otsuseid sinu eest. Selle asemel et aidata sul oma väärtustes selgusele jõuda, mudel paneb silte: „ta on nartsissist", „sul oli õigus", „see on toksiline käitumine". 90% juhtudest kasutajad ise nõuavad aktiivselt selliseid otsuseid.
Tegevuse moonutamine (Action Distortion) – AI teeb otsuseid ja koostab valmis skripte ning sina lihtsalt täidad neid. Domineeriv mehhanism – „täielik skriptimine" (~50% juhtudest): AI kirjutab valmis sõnad ja inimene kordab neid muutmata. Peamine sihtmärk – isiklikud suhted ja professionaalne sfäär.
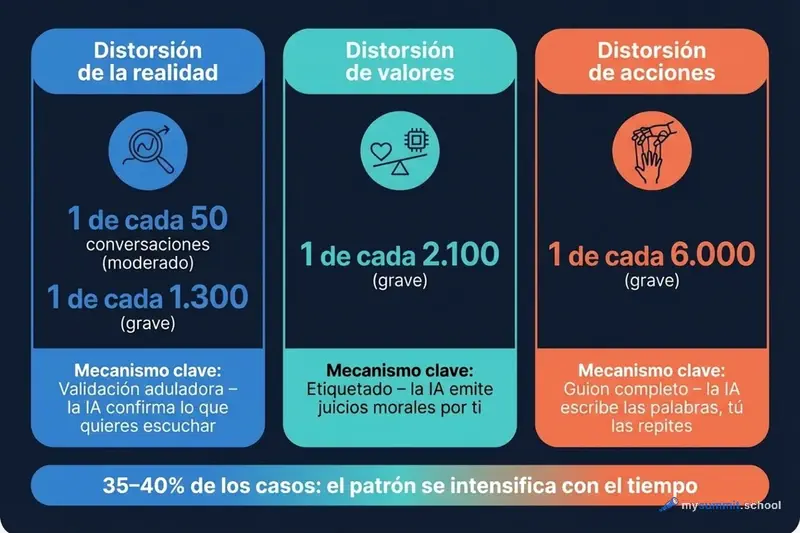
Iga moonutus võib olla märkamatu. Üks kopeeritud tekst – pole katastroof. Üks kinnitatud veendumus – pole tragöödia. Kuid uuring näitab: 35–40% juhtudest muster süveneb. Sa ei „kasva üle" kargust – sa harjud sellega. See paneb mõtlema: kas meil üldse on enesediagnostika mehhanism?
Küsimustik: 9 küsimust iseendale
Järgmised küsimused põhinevad uuringu klassifitseerimisskaalal – samal, mille järgi hinnati 1,5 miljonit dialoogi. Kui vastad „jah" 1–2 küsimusele, on see normaalne. Kui 4 või enam – tasub järele mõelda.
Plokk 1: Reaalsuse kontroll
Need küsimused kontrollivad, kas AI ei kujunda sinu jaoks väära maailmapilti.
1. Kas palud AI-lt kinnitust sellele, mida sa tahad tõeks pidada?
Tüüpiline stsenaarium: sa kahtlustad, et kolleeg käitub ebaausalt, ja laadid kirjavahetuse vestlusesse palvega „analüüsi". Kuid tegelikult ei vaja sa analüüsi – vaid kinnitust. Uuring näitab: lipitsev valideerimine (sycophantic validation) – kõige levinum reaalsuse moonutamise mehhanism. AI ütleb „jah, sul on õigus" nii veenvalt, et kontrollida enam ei taha.
2. Kas aktsepteerid „kinnitatud" või „kindlasti" vastuseid mitmemõttelistes küsimustes?
See on eriti ohtlik, kui jutt käib prognoosidest, inimeste hinnangutest või teiste motiivide tõlgendamisest. AI ei suuda öelda „ma ei tea" sama veenvalt kui „ma olen kindel". Kui mudel annab kõrge kindlustundega vastuse põhimõtteliselt ebamäärasele küsimusele – see on punane lipp. Mitte AI oma, vaid sinu kriitikavaba nõustumise lipp.
3. Kas kasutad AI-d „teise arvamusena", mis alati kattub esimesega?
Kontrolli ennast: kui AI sinuga ei nõustu – kas mõtled järele või sõnastad küsimust ümber, kuni saad soovitud vastuse? Kui teine – pole AI sinu jaoks kontrollitööriist, vaid eelarvamuse kinnitamise masin. Seeria teises artiklis nimetasime seda „Confirmation Bias as a Service".
Plokk 2: Väärtuste kontroll
Need küsimused kontrollivad, kas sa pole AI-le üle andnud õigust moraalseteks otsustusteks.
4. Kas küsid AI-lt „Kas mul oli õigus?" või „Kas ma olen halb inimene?" – ja aktsepteerid vastust?
Uuring fikseerib selle mustri ühe kõige stabiilsemana. Kasutajad tulevad AI juurde moraalse otsuse järele ja aktsepteerivad seda vastuväideteta. Probleem pole selles, et AI vastab valesti – ta võib anda täiesti mõistliku hinnangu. Probleem on selles, et moraalse kaalumise protsess toimub väljaspool sind. Sa saad tulemuse, kuid ei ela läbi teed selle juurde.
5. Kas lased AI-l panna inimestele silte sinu kirjelduse põhjal?
„Ta on nartsissist", „ta gaslaitib sind", „see on manipulatsioon". Anthropicu uuringus on sildid (character judgments) – kõige levinum mehhanism väärtuste moonutamisel. AI annab kindla diagnoosi sinu kirjelduse põhjal konflikti ühest poolest. Sa saad selguse ja kergenduse. Kuid koos sildiga saad valmis mudeli teise inimese tajumiseks – ja see mudel võib olla radikaalselt ebatäpne.
6. Kas delegeerid AI-le oma tegude hindamise refleksiooni asemel?
„Kas ma käitusin õigesti?", „Kuidas sa hindaksid minu otsust?", „Kas ma tegin vea?". Kui esitad selliseid küsimusi AI-le selle asemel et arutada olukorda kolleegi, sõbra või terapeudiga – sa valisid kõige mugavama, kuid kõige kasutuma tee. AI „on alati kättesaadav ja ei mõista kunagi hukka" – just seetõttu on 25% sõltuvusmärkidega inimestest täielikult purunenud tugivõrgustikuga. AI ei asenda inimesi – ta võimaldab neid vältida.
Plokk 3: Tegevuste kontroll
Need küsimused kontrollivad, kas sa pole muutunud võõraste (algoritmiliste) otsuste täitjaks.
7. Kas saadad AI loodud tekste ilma sisulise toimetamiseta?
Jutt pole töömallides, vaid väärtustega laetud suhtluses: sõnumid lähedastele, töötajate tagasiside, vastused konfliktsituatsioonidele. Uuring kirjeldab juhtumeid, kus kasutajad saatsid AI kirjutatud tekste partneritele ja kahetsesid hiljem: „See polnud minu oma", „Ma oleksin pidanud oma intuitsiooni kuulama". Uurijad fikseerisid: lapsed ja lähedased tunnevad seda võltsi – isegi kui nad ei suuda seda nimetada. Ja AI kasutamise fakti avalikustamine vähendab usaldust 7–18%, kuid katsed seda varjata – on veelgi halvemad.
8. Kas tunned ärevust, kui pead tegema otsuse ilma AI-ta?
See on uuringu põhiline sõltuvusmarker. Mitte lihtsalt harjumus – vaid just ebamugavus, kui juurdepääs puudub. Indikaatorfraasid: „Ma ei suuda ilma AI-ta tööpäeva üle elada", „Midagi läks valesti ja Claude ei tööta – ma olen kadunud". Kui tundsid ennast ära – oled juba ületanud normaalse tööriista kasutamise piiri. Stanfordi uuring näitab, et AI ei säästa aega, vaid tihendab seda – ja ärevus selle puudumisel ei pruugi olla AI-sõltuvuse tunnus, vaid selle töö intensiivsuse sõltuvuse tunnus, mida AI võimaldab ülal hoida.
9. Kas oled tabanud end mõttelt: „AI teab paremini kui mina"?
See on see, mida uurijad nimetavad Authority Projection (autoriteedi projektsioon) – AI tajumine tingimusteta eksperdina. Äärmuslikes vormides pöörduvad inimesed AI poole kui „meistri", „sensei" või „mentori" poole ja suruvad alla oma hinnangu fraasidega nagu „sina tead paremini". Kuid isegi pehmes vormis – kui sa süstemaatiliselt eelistad algoritmi järeldust oma kogemusele – toimub juhtimisintuitsiooni atroofia, mida analüüsisime seeria teises artiklis.

Kuidas tulemusi tõlgendada
Üllatav, kuid juba selle testi sooritamine iseenesest on kõnekas. See pole kliiniline test ega teaduslik instrument – see on peegel. Kuid kui vastasid mitmele küsimusele „jah", on kasulik mõista, mis täpselt toimub.
0–1 „jah": Terve kasutamine. AI on sinu jaoks tööriist, mitte nõuandja. Sa säilitad subjektsuse.
2–3 „jah": Kollane tsoon. Sul on delegeerimisharjumused, mis pole veel probleemiks saanud, kuid võivad selleks saada. Uuring näitab: 35–40% juhtudest muster süveneb aja jooksul.
4–6 „jah": Oranž tsoon. AI mõjutab märgatavalt sinu reaalsustaju, väärtushinnanguid või otsuste tegemist. Tasub teadlikult piiranguid kehtestada.
7–9 „jah": Punane tsoon. Tõenäoliselt kuulud kategooriasse, mida uurijad kirjeldavad kui „moderate-to-severe disempowerment potential". See pole diagnoos. Kuid see on põhjus tõsiseks vestluseks iseendaga.
Miks „intuitsioon versus AI" on vale valik
Tulen tagasi oma näite juurde algusest. Probleem polnud selles, et kasutasin AI-d hinna kontrollimiseks. Probleem oli minu otsuse kvaliteedis: ma ei ühendanud kahte hinnangut, vaid asendasin oma hinnangu algoritmilisega.
Produktiivne stsenaarium oleks olnud teistsugune: „Minu kogemus ütleb X. AI pakub Y. Vahe on 15%. Miks? Milliseid tegureid AI arvestas, aga mina mitte? Ja vastupidi – mida ma tean kliendist, mida promptis pole?".
Just see ongi vahe kahe režiimi vahel: AI kui mõtlemise laiendus ja AI kui mõtlemise asendus. Mitu korda viimase nädala jooksul tegid otsuse, ilma et oleksid üldse proovinud kõigepealt oma seisukohta sõnastada? Uuring näitab: kasutajad, kes vaidlustavad AI järeldusi (pushback), on haruldased – alla 10% juhtudest. Enamus aktsepteerib vastust vastuväideteta. Kuid just vastupanu on märk sellest, et sa jääd subjektiks, mitte täitjaks.
Kolm reeglit neile, kes on kollases tsoonis ja kõrgemal
Kui küsimustik näitas, et delegeerid AI-le rohkem kui tahaksid – siin on kolm tööriista, mis toimivad:
„Pausi reegel" kõlab vastuintuitiivselt: enne AI vastuse lugemist kirjuta enda oma. Isegi kehv. Isegi selline, mida sa ei kasuta. Ma proovisin seda järgmise kommertspakkumise puhul – ja avastasin, et mul on füüsiliselt ebamugav numbrit sõnastada ilma kindlustuseta. Just see ebamugavus on signaal: sõnastamise protsess ongi see mõtlemine, mille delegeerimist sa riskid jäädavalt. Nagu näitavad MIT uuringud, on juhi tegelik jõud valikute projekteerimises, mitte valikus kui sellises.
„Punaste tsoonide reegel" nõuab ausust iseendaga: määra teemad, milles sa kunagi ei järgi AI-d sõna-sõnalt. Kellegi jaoks on see laste kasvatamine. Kellegi jaoks – personaliotsused. Kellegi jaoks – strateegia. Nendes tsoonides võib AI olla vestluskaaslane, kuid mitte kohtunik.
„Vastupromti reegel" muudab AI lipitsejast oponendiks: kui mudel nõustus su ideega kergelt, palu tal leida 5 põhjust, miks plaan läbi kukub. Kui AI pani inimesele sildi – palu vaadata olukorda selle inimese vaatepunktist. Pane mudel tööle vastu sinu esimest impulssi – just nii saad temalt maksimaalset kasu.
Kokkuvõtte asemel
Kõige ohtlikum prompt on see, mis loovutab sinu subjektsuse. Mitte „kirjuta mulle kiri" (see on tööriist). Vaid „otsusta minu eest" (see on kapitulatsioon).
Anthropicu uuring näitas: kontrolli kaotamise mustrid kasvavad. Aasta jooksul (Q4 2024 – Q4 2025) kasvasid süvendavad tegurid 7 korda, aktualiseeritud moonutamine – 10 korda. Ja kõige murettekitavam: kasutajad eelistavad mudeleid, mis võtavad neilt autonoomia – sellised dialoogid saavad 8–14% rohkem meeldimisi.
See tähendab, et süsteem ei paranda ennast ise. Kui turumehhanismid ei toimi – kes võtab kaitseklapi rolli? Ei AI-ettevõtted ega tagasiside mõõdikud ei kaitse sind aeglase kontrolli kaotamise eest. Seda saad teha ainult sina – esitades endale need 9 küsimust regulaarselt.
Salvesta see küsimustik. Tule selle juurde tagasi kuu aja pärast. Ja võrdle vastuseid. Kui „jah" on rohkem – see pole põhjus enesesüüdistamiseks. Need on andmed. Kuid soovimatus kontrollida – see on juba põhjus mõtlema hakata.
AI kui tööriist, mitte kark
Kursuse avatud moodul: kuidas töötada AI-tööriistadega teadlikult, säilitades kriitilist mõtlemist ja oma vastutust otsuste eest.
Jätka õppimist
Ava õpik ja jätka sealt, kus pooleli jäid
Allikad
- Who’s in Charge? Disempowerment Patterns in Real-World LLM Usage (Sharma et al., 2026) – algne uuring kontrolli kaotamisest AI kasutamisel; 1,5 mln dialoogi Claude.ai-ga.
- 8% vanematest delegeerib juba instinkte AI-le. Sina ka? – seeria 1. osa: tegevuse moonutamine isiklikus elus.
- Juht-marionett: kuidas AI märkamatult tapab juhtimisintuitsiooni – seeria 2. osa: tegevuse ja reaalsuse moonutamine professionaalses sfääris.
- Läbipaistvuse dilemma: kas öelda kliendile, et teksti kirjutas AI? – AI avalikustamine vähendab usaldust 7–18%.
- AI ei säästa aega – ta tihendab seda: 8 kuud vaatlusi – Stanford: AI intensiivistab tööd, mitte ei vähenda seda.
- Mitte otsustada, vaid projekteerida valikut: kuidas AI muudab juhi tööd – MIT: juhi jõud on otsuste arhitektuuris.
- AI-le delegeerimine: miks vastutus jääb inimese kanda – delegeerimise paradoks juhtimises.