99% kvaliteedist 1,4% hinnaga: mis on TI-mudelite turul valesti
Enamik juhte valib TI-mudeli nii: võtab kõige kallima saadaoleva. Loogika on arusaadav – kallim tähendab paremat. Nii on ettevõttetarkvara puhul viimased kakskümmend aastat toiminud.
TI-mudelite turg 2026. aastal on teisiti korraldatud. Ühe päringu maksumus varieerub $0,0001 kuni $0,17 – kolm suurusjärku. Aga tegelik kvaliteedierinevus kümne parima mudeli vahel? 0,24 punkti viiepallisel skaalal. Samal ajal Wharton / GBK Collective fikseerib: kolmandik ettevõtete TI-projektidest ei jõua piloodist kaugemale. Ja Epoch AI näitab, et vaid 5,6% kasutajatest rakendab TI-d tõeliselt süvitsi.
Võib-olla pole küsimus selles, milline mudel on parem, vaid selles, kas preemiumile üle maksmine annab tüüpiliste juhtimisülesannete puhul proportsionaalselt parema tulemuse.
Me kontrollisime. Vastus osutus oodatust karmimaks.
Andmed
Jaanuarist märtsini 2026 testisime 54 TI-mudelit kaheksas juhtimisülesannete kategoorias – alates kirjade koostamisest kuni andmeanalüüsi ja otsuste tegemiseni puuduliku info tingimustes. Täielikud tulemused on avaldatud platvormil. Eraldi eksperiment – kas promptidega saab nõrka mudelit kompenseerida – näitas, et struktureeritud promptid vähendavad vahet, kuid ei kata seda täielikult. Metoodika: kaks TI-hindajat (Claude Opus 4.5 ja Gemini 3 Pro) pluss inimese kalibratsioon, 2 121 individuaalset hindamist. Iga mudel saab komposiitskoori 1-st 5-ni ja päringu maksumuse dollarites.
Hinnad on hetktõmmis 2026. aasta aprillist OpenRouter.ai andmete põhjal – ainsa ühtse formaadiga agregaatori. Hoiatus: API-hinnad muutuvad kiiresti. GPT-5.4 odavnes uuringu jooksul $0,0585-lt $0,0158-ni päringu kohta. GPT-5.2 Pro, vastupidi, kallines $0,039-lt $0,1659-ni.
Lõplikus tabelis on 53 mudelit (üks jäeti välja läbipaistmatu hinnakujunduse tõttu).
Äärmiselt kahanev tootlikkus
Seos “hind – kvaliteet” TI-mudelite puhul järgib logaritmilist kõverat. Üleminek hinnaklassist $0,0001 hinnaklassi $0,002 päringu kohta annab kvaliteedihüppe umbes 1,5 punkti. Üleminek $0,002-lt $0,17-ni – hinna kasv 85 korda – annab lisaks umbes 0,1 punkti.
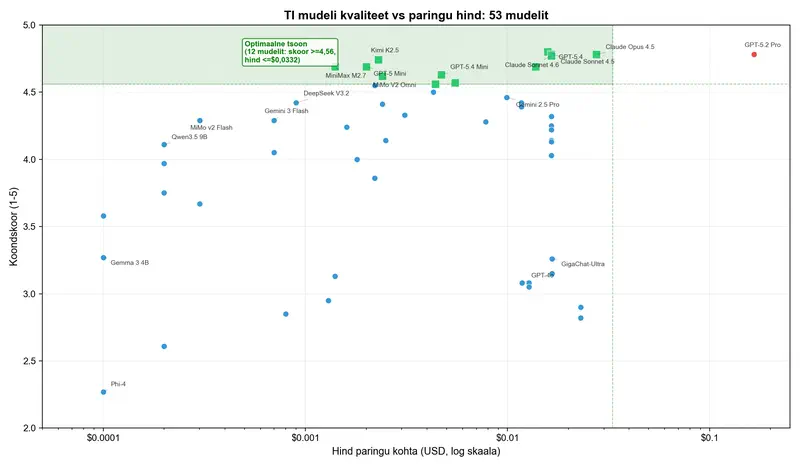
Siin on konkreetne näide. Claude Sonnet 4.5 saab 4,78 punkti $0,0165 päringu kohta. GPT-5.2 Pro – samuti 4,78 punkti. Aga maksab $0,1659. Kümme korda kallim. Identne tulemus. Me kontrollisime kolm korda üle – arvasime, et tabelis on viga. Ei, turg on lihtsalt nii korraldatud.
Ja siis vaatasime Kimi K2.5. Skoor 4,74 hinnaga $0,0023 päringu kohta. See on 99% GPT-5.4 kvaliteedist 1,4% GPT-5.2 Pro hinnaga.
Strateegia 80/20
Abstraktsed võrdlused on huvitavad, aga mida see tähendab reaalse eelarve jaoks?
Me modelleerisime kolm strateegiat juhtide meeskonnale, kes teeb 1 000 päringut kuus.
Strateegia “kõik maksimumile”: kõik päringud GPT-5.4 kaudu. Maksumus: $15,80/kuus. Kvaliteet: 4,80.
Strateegia 80/20: 80% rutiinsetest ülesannetest (kirjad, lühikokkuvõtted, koosolekute protokollid) eelarvelise mudeli kaudu nagu Qwen3.5 9B, 20% keerukatest ülesannetest (strateegia analüüs, juhtkonna aruanded) GPT-5.4 kaudu. Maksumus: $3,32/kuus. Kvaliteet: 4,25.
Vahe: miinus 79% kulutustes 11% kvaliteedi kaoga. 80% ülesannete puhul – kirja mustand, dokumendi kokkuvõte, päevakorra ettevalmistamine – erinevus $0,0002 ja $0,016 mudeli vahel on sõna otseses mõttes eristamatult väike.
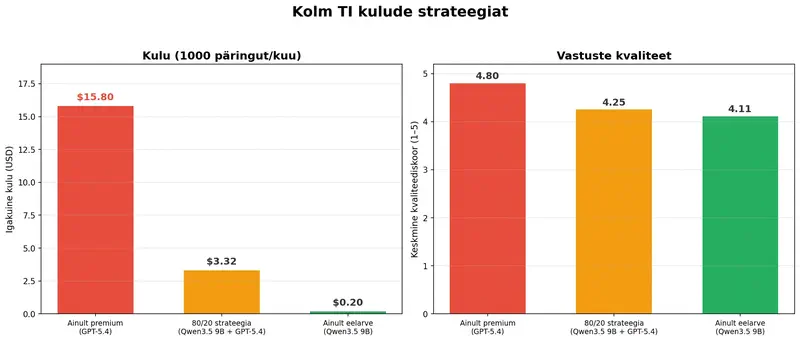
See ei ole teoreetiline harjutus. 10 juhi meeskonna puhul 100 päringuga kuus säästab strateegia 80/20 umbes $125 kuus võrreldes lähenemisega “kõigile preemium”. Summa ei ole transformatiivne, aga ka mitte nullilähedane. Ja peamine – kvaliteet 80% ülesannete puhul jääb eristamatuks.
Aritmeetika tundub lihtne. Keerukus algab siis, kui tuleb konkreetselt otsustada: siin on ülesanne, siin kolm mudelit – milline valida ja miks. Vahe “tundub, et sobib” ja “tean, miks valisin” vahel on oskus, mida arendatakse reaalsete ülesannete peal.
Millised ülesanded anda eelarvemudeli kasutusse ja millised preemiumi kasutusse? Proovige 9 juhtimisülesannet erinevatel mudelitel – tasuta, ilma registreerimiseta.
Makset ei nõuta • Teavitus käivitumisel
Varjatud tšempionid: näitaja “kvaliteet dollari kohta”
Me kehtestasime meetrika PPD (Performance Per Dollar) – kvaliteediskoor jagatuna päringu maksumusega. Mida kõrgem PPD, seda rohkem kvaliteeti saate iga kulutatud dollari eest.
Tulemused pööravad tavapärase pildi pea peale.
| Mudel | Skoor | Hind/päring | PPD |
|---|---|---|---|
| GPT-5.2 Pro | 4,78 | $0,1659 | 28 |
| GPT-5.4 | 4,80 | $0,0158 | 304 |
| Kimi K2.5 | 4,74 | $0,0023 | 2 097 |
| DeepSeek V3.2 | 4,42 | $0,0009 | 4 825 |
| Gemini 3 Flash | 4,29 | $0,0007 | 6 085 |
| MiMo v2 Flash | 4,29 | $0,0003 | 12 434 |
| Qwen3.5 9B | 4,11 | $0,0002 | 21 076 |
Eelarvemudelid annavad 40 kuni 1 700 korda rohkem kvaliteeti dollari kohta kui GPT-5.2 Pro. See ei ole ümardamisviga. See on turu struktuurne ebatõhusus, mida saab ära kasutada.
“TI-maks” – ja kes seda maksab
Miks see üldse probleem on? Kas kõik ei kasuta TI-d ühtemoodi?
Ei. Epoch AI / Ipsos’i uuring näitas, et 62% TI-kasutajatest täidab lihtsaid ülesandeid – kiired päringud, lühikesed mustandid. Vaid 5,6% kasutab TI-d süvitsi. Nende 62% jaoks on vahe $0,002 ja $0,17 päringu vahel sõna otseses mõttes nähtamatu.
Aga kulud on nähtavad. Workday tutvustab 2026. aasta aruandes mõistet “TI-maks” – 37% TI abil “säästetud” ajast kulub selle vigade parandamisele. Aga on ka teine maks – rahaline: ülemaksmine preemiummudeli eest ülesannete puhul, kus eelarvelisega oleks sama hästi hakkama saadud.
Brookings fikseerib: TI-d kasutavate ameeriklaste seas arvab vaid 19%, et see teeb nad tööl produktiivsemaks. 4% – et oluliselt produktiivsemaks. Google Cloud näitab ROI aruandes teist külge: ettevõtted, kes näevad reaalset tulemust, saavutavad selle mitte kalli mudeli ostmisega, vaid täpse tööriista valikuga ülesande jaoks. Võib-olla pole asi tööriistas, vaid selles, kuidas seda valitakse ja millele kulutatakse?
Tabel 'ülesanne -> tööriist -> hind' on avatud mooduli 8. tunnis. 9 praktilist juhtimisülesannet TI-ga, tasuta.
Makset ei nõuta • Teavitus käivitumisel
Praktiline soovitus
Kui haldate meeskonna TI-eelarvet – siin on, mida saab sellel nädalal teha.
Klassifitseerige ülesanded: kirjade mustandid, dokumentide kokkuvõtted, regulatsiooniviited, koosolekute protokollid – see on rutiin, 70–80% päringutest. Strateegiline analüüs, juhtkonna materjalid, töö mitmeti tõlgendatavate andmetega – keerukad ülesanded, 20–30%.
Seadistage marsruutimine: rutiin – eelarvemudeli peale (Kimi K2.5, Qwen3.5 Plus, DeepSeek V3.2), keerukad ülesanded – preemiumile (GPT-5.4, Claude Sonnet 4.5). Tehniliselt võib see olla API-lüüs, sõnumirakenduse bot kahe nupuga või lihtsalt meeskonna kokkulepe “kirjade jaoks kasutame X-i, analüütika jaoks Y-d”.
Mõõtke: kuu pärast võrrelge – kas rutiinsete ülesannete kvaliteet muutus? Kui ei – olete just vähendanud TI-kulusid 70–80% ilma tulemust kaotamata.
Konkreetse mudeli valikuks: Kimi K2.5 (4,74 punkti, parim hinna-kvaliteedi suhtega), Qwen3.5 Plus (4,56 punkti, odavam), DeepSeek V3.2 (4,42 punkti, veelgi odavam). Üksikasjalik ülevaade kättesaadavusest ja kohalikest mudelitest on eraldi teema. Tööriistad mitme mudeliga töötamiseks – artiklis OpenCode’i kohta.
Möönded
Meie võrdlustest testib konkreetseid ülesannete kategooriaid. Võimalik, et preemiummudelid on tõesti tugevamad keerukate mitmeastmeliste arutluste või ülesannete puhul, mida me ei testinud. GPT-5.2 Pro näitab kogu oma kallimuse juures hämmastavat stabiilsust (standardhälve 0,082) – mõnel eelarvemudelil on hajuvus suurem. Lähenemine “TI hindab TI-d” tekitab oma moonutusi, kuigi inimese kalibratsioon neid pehmendab.
Ja peamine: need arvud on turu hetktõmmis 2026. aasta aprillis. Hinnad muutuvad igal nädalal. Aga struktuurne pilt – äärmiselt kahanev tootlikkus ülemises hinnasegmendis – vaevalt muutub: liiga palju konkureerivaid mudeleid, liiga kiiresti odavnevad.
Kokkuvõte
Hüpotees “kallim – proportsionaalselt parem” on andmetega ümber lükatud. TI-mudelite turg 2026. aastal demonstreerib äärmiselt kahanevat tootlikkust: preemiumlisa on reaalne ja mõõdetav. See ei tähenda, et preemiummudelid on kasutud – 20% ülesannete puhul, kus kvaliteet on kriitiline, võib vahe hinda õigustada. Aga GPT-5.4 kasutamine koosoleku protokolli kokkuvõtteks on umbes sama nagu helikopteriga tööle lennata: tehniliselt suurepärane, majanduslikult mõttetu.
Lõhe hinna ja kvaliteedi vahel TI-mudelite turul on praegu suurem kui kunagi varem – ja vaevalt kitseneb lähima aasta jooksul. Aga huvitavam on teine küsimus: kui Kimi K2.5 annab 99% GPT-5.4 kvaliteedist 1,4% hinnaga, siis mida täpselt ostab juht, kes valib preemiumi? Teenusepakkuja mainet? Harjumust? Või kindlustunnet, et “me kasutame kõige paremat” – isegi kui see “parim” ei kajastu tulemustes?
Täielikud andmed – meie 53 mudeli uuringus.
Eksperimendist süsteemini
Mudeli valik on üks kursuse ülesandeks. Aluskursus katab promptide inseneriat ja kriitilist mõtlemist TI-ga. Spetsialiseerumine 'Projektijuhtimine' analüüsib, kuidas integreerida TI juhi operatiivsesse ritmi – mustanditest analüütikani.



Stanislav Belyaev
Engineering Leader Microsoftis18 aastat insenerimeeskondade juhtimist. mysummit.school asutaja. 700+ lopetajat Yandex Practicumis ja Stratoplanis.