Läbipaistvuse dilemma: kas öelda kliendile, et teksti kirjutas AI?
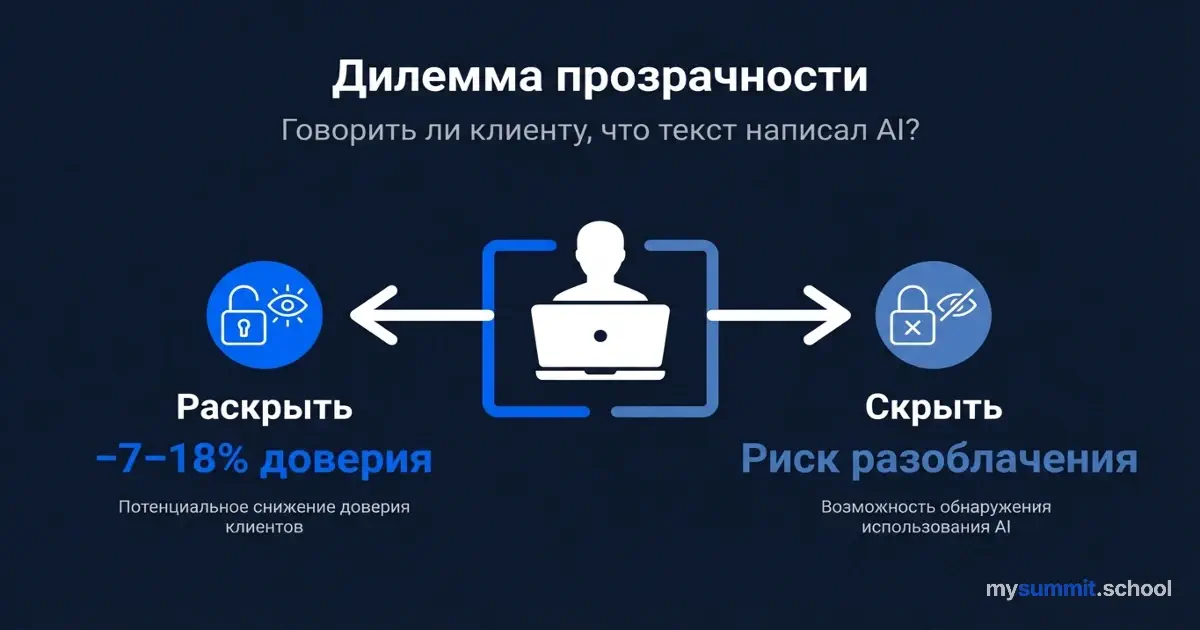
Kirjutasite kliendile ideaalse kirja. Toon on täpne, argumendid loogilised, isegi nali on tabav. Probleem on üks: te ei kirjutanud seda. Kirjutas Claude. Või ChatGPT. Või Gemini – vahet pole.
Nüüd küsimus: kas te ütlete seda kliendile?
Intuitsioon ütleb: „Muidugi mitte. Mis vahet, kuidas on kirjutatud, kui on hästi kirjutatud?". Ettevõtte eetika sosistab: „Peab olema läbipaistev". Aga teadus ütleb midagi ootamatut: mõlemad variandid hävitavad usalduse – kuid erineval viisil ja erinevate tagajärgedega.
Katse, mis kõike muutis
- aastal avaldasid teadlased Oliver Schilke ja Martin Reimann ajakirjas Organizational Behavior and Human Decision Processes 13 eelregistreeritud katse seeria, milles osales üle 5000 inimese. Stsenaariumide spekter oli ebatavaliselt lai: professorid, kes kirjutavad soovituskirju; analüütikud, kes koostavad investeerimisülevaateid; juhid, kes kirjutavad ettevõtte kirjavahetust; loovspetsialistid, kes töötavad välja kontseptsioone.
Metoodika oli oma lihtsuses elegantne. Osalejad said ühed ja samad tekstid. Ainus muutuja – kas nad teadsid AI osalusest teksti loomisel. Tehnoloogia kasutamise fakt jäi samaks; muutus ainult avalikustamine.
Tulemus oli vastuintuitiivne: AI kasutamise selgesõnaline avalikustamine vähendas süstemaatiliselt usaldust sõnumi autori vastu. Mitte teksti kvaliteedi vastu – selle inimese vastu, kes selle saatis. Konkreetsed numbrid: usaldus professorite vastu, kes kasutasid AI-d soovituskirjade jaoks, langes ~16%. Investeerimisfondide puhul, kes avalikustasid AI osaluse analüütilistel ülevaadetel – ~18%. Lihtne märgistus „loodud AI abiga" võttis ära 7–14 protsendipunkti usaldust.
Teadlased testisid ka „pehmeid" sõnastusi: „AI-d kasutati ainult õigekirja kontrollimiseks", „AI aitas struktuuriga". Ei aidanud. Igasugune AI mainimine käivitas ühe ja sama väärtuse kahandamise mehhanismi.
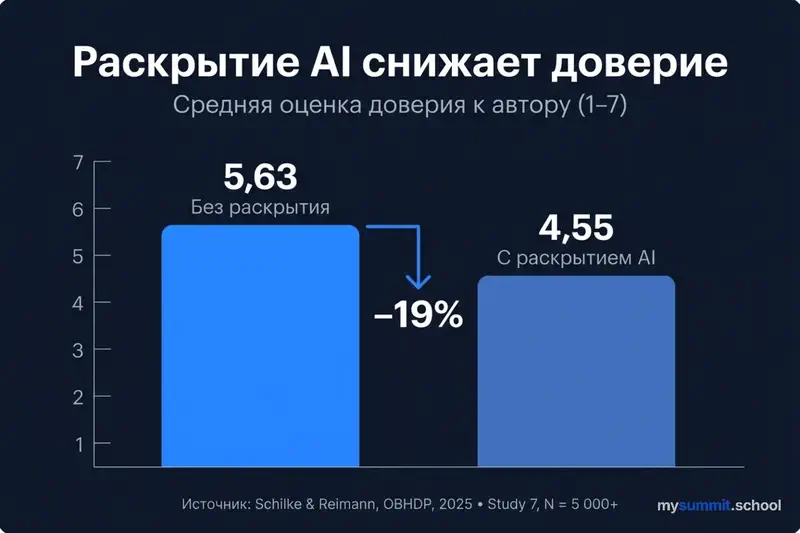
Autentsuse trahv
Põhjus on selles, mida teadlased nimetasid autentsuse trahviks (authenticity penalty). Schilke ja Reimann eristasid kolm komponenti, mis avalikustamisel järjekindlalt lagunevad: tüüpilisus (kas see on antud rolli jaoks normaalne käitumine?), pühendumus (kas autor pingutas?) ja autentsus (kas sõnade taga on elav inimene?).
Kui saaja saab teada, et tekst on loodud AI abiga, toimub kohene kognitiivne nihe. Ta hakkab kahtlema: kas need on teie mõtted või valis algoritm statistiliselt tõenäolised sõnastused? Kas hoolitsus kirjas on siiras või on see mall?
Lingvistiline analüüs kinnitab paradoksi: AI-tekstid saavad objektiivselt kõrgemaid hinnanguid emotsionaalse soojuse, struktuurilise keerukuse ja sõnavara mitmekesisuse osas. Kuid samas kaotavad järjekindlalt inimtekstidele autentsuse poolest – tunde poolest, et sõnade taga on elav inimene tõeliste kavatsustega.
Ja halvim stsenaarium ei ole mitte teie enda avalikustamine. Nagu teadlased sõnastavad: „Kui kolmas osapool teatab, et kasutasite AI-d – see on halvim võimalik tulemus". Sest autentsuse trahvile lisandub petmise trahv. Mehhanism on sama mis algoritmilises juhtimises: kontrolli kaotamise tunne käivitab usaldamatuse ahelreaktsiooni.
Pimetest: millal AI võidab – ja kaotab
Autentsuse trahvi ulatust näitab ilmekalt Gagan Jaini, Samridhi Pareeki ja Per Carlbringi uurimus (2024).
Esimeses etapis (pimetest) hindasid 140 osalejat vastuseid 10 psühholoogilise toe stsenaariumile – inimestevahelistest konfliktidest stressijuhtimiseni. Allikas oli varjatud. AI vastused (ChatGPT) said hindeid samal tasemel või kõrgemalt kui kliinilise psühholoogia magistrantide vastused kõigi kolme parameetri osas – autentsus, professionaalsus ja praktilisus. Erinevused ei olnud statistiliselt olulised.
Teises etapis (6 kuud hiljem, avalikustamisega) hindasid 111 osalejat samast grupist täpselt samu vastuseid, kuid nüüd teadsid, kes on autor. Tulemus: inimvastuste autentsuse hinnangud tõusid (36,33-lt 37,66-le), samas AI hinnangud jäid samaks (34,85 mõlemas etapis).
Uuringud näitavad veel üht huvitavat nüanssi: üldine usaldus AI vastu korreleerus ainult praktilisusega. Autentsuse ega professionaalsusega seost ei leitud.
Inimesed on valmis tunnistama, et AI on kasulik. Kuid ei ole valmis tunnistama, et AI võib olla siiras. Utilitaarne usaldus ja emotsionaalne usaldus on kaks eri ringlust ning avalikustamine hävitab just teise.
Catch-22: varjamine on veelgi hullem
Näiliselt on lahendus ilmne – lihtsalt mitte öelda. Ja tõepoolest, Salesforce’i andmed (14 000 töötaja uuring) näitavad: 64% esitab AI-genereeritud sisu enda omana. WalkMe andmetel 78% kasutab tööl heakskiitmata AI-tööriistu. C-taseme juhtide seas on number veelgi kõrgem – 93% tunnistavad „vari-AI" kasutamist.
Kuid teadlased Schilke ja Reimann hoiatavad: kolmanda osapoole avalikustamine – kolleegi, juhusliku avastamise, tehnilise rikke kaudu – annab katastroofilise ja sageli pöördumatu löögi mainele.
See ei ole enam „ta kasutas tööriista". See on „ta pettis mind teadlikult".
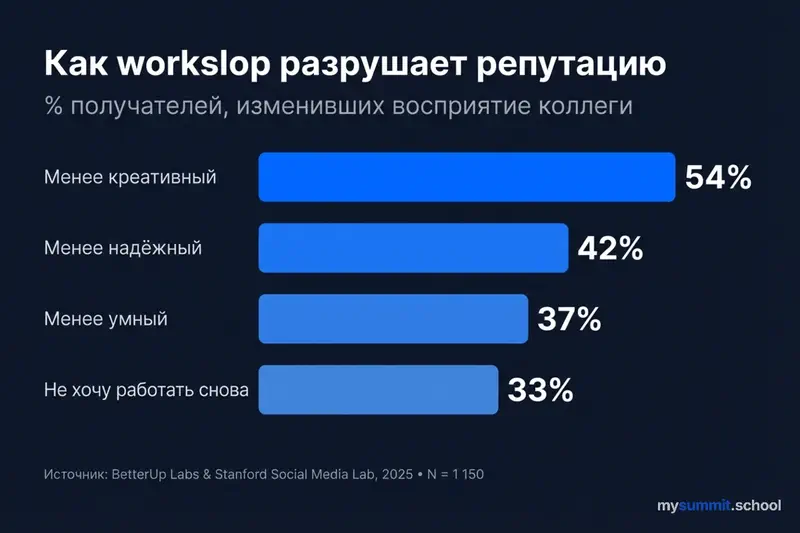
BetterUp Labsi (Kate Niederhoffer) ja Stanford Social Media Labi (Jeff Hancock) ühisuuringu andmed, 1150 täiskohaga töötaja uuring USA-s, kirjeldavad seda efekti kvantitatiivselt. Kui saajad avastavad, et kolleegi töö on AI-genereeritud „workslop" (väliselt lihvitud, kuid sisulise sügavuseta sisu):
- 54% peab saatjat vähem loovaks
- 42% – vähem usaldusväärseks
- 37% – vähem intelligentseks
- 33% ei tahaks selle inimesega enam koos töötada
Üks paljastatud AI-kiri võib nullida kuid üles ehitatud professionaalset mainet. See paneb mõtlema: kui habras osutus see, mida oleme harjunud nimetama „professionaalseks usalduseks".
Varjatud maks: pingutuse heuristika ja 9 miljonit dollarit aastas
Reaktsiooni sügavuse mõistmiseks tuleb pöörduda pingutuse heuristika poole – see on kognitiivne kallutatus. Aastakümnete uuringud näitavad: inimesed seostavad instinktiivselt nähtavat pingutust tulemuse kvaliteediga. Luuletust, mille peale „kulus kolm aastat", hinnatakse kõrgemalt kui identset, mis kirjutati „poole tunniga". Käsitööna valmistatud ülikond on kallim tehaseomast, isegi kui nad on eristamatult sarnased.
AI lõhkus selle seose. Laitmatu tekst luuakse nüüd sekunditega – ja see ei ole enam kompetentsuse signaal. Kui juht saab teada, et alluva hiilgav aruanne on ühe prompti tulemus, tekib petmise tunne. Mitte sellepärast, et aruanne on halb, vaid sellepärast, et eeldatav pingutus osutus illusiooniks. Microsoft Researchi süntees (~50 uuringut) kinnitab: kasutajad, kes said valesid AI soovitusi, töötavad aeglasemalt kui need, kes tegid ülesannet üldse ilma AI-ta.
Ja workslop’i rahaline kahju on konkreetne. BetterUp’i ja Stanfordi andmetel:
| Näitaja | Väärtus |
|---|---|
| Töötajate osakaal, kes said workslop’i viimase kuu jooksul | 40% |
| Keskmine aeg ühe juhtumi lahendamiseks | 1 tund 56 minutit |
| Kaotatud aja maksumus töötaja kohta kuus | $186 |
| Varjatud kahju 10 000 inimesega organisatsioonile | >$9 miljonit / aastas |

Workslop’i saaja kulutab peaaegu kaks tundi konteksti taastamisele, faktide kontrollimisele ja vigade parandamisele. AI säästis saatjale 30 minutit – ja lükkas kaks tundi tööd kolleegi õlule. Ühe inimese „tootlikkus" toob kahju kõigile.
Kuid BetterUp leidis ka vastupidise mustri. 28% töötajatest kasutab AI-d kui „piloodid" – redigeerivad aktiivselt, kontrollivad, täiendavad oma kontekstiga. Ülejäänud 72% on „reisijad", kes delegeerivad AI-le ja saadavad tulemuse ilma parandamata. Tulemuste vahe: „piloodid" näitavad 3,6 korda kõrgemat tootlikkust ja 3,1 korda kõrgemat lojaalsust ettevõttele. Sarnast mustrit – töö intensiivistumine AI kaudu – kirjeldab Töö Tuleviku Instituudi uuring.
Miks selgitused ei aita (aga sotsiaalne heakskiit – aitab)
Intuitiivne lahendus – muuta AI läbipaistvamaks: selgitada, kuidas see töötab, näidata soovituste loogikat. Kuid Harvardi Innovatsiooniteaduste Labori (LISH) uuring avastas vastupidise efekti.
Katse ulatus: 17 245 otsust varude jaotamise kohta 425 tooteartikli lõikes 186 poes. Kui juhid nägid algoritmi loogikat – milliseid muutujaid see arvesse võttis, millised kaalud määras – hakkasid nad seda sagedamini ignoreerima. Teadlased nimetasid seda mehhanismi „liigselt enesekindel veaotsing" (overconfident troubleshooting): läbipaistvus tekitas mõistmise illusiooni. „Ma näen, mida see arvesse võtab, ja ma tean paremini". Isiklik kogemus ja intuitsioon võitsid andmeid.
Samas „must kast" – nähtava loogiketa algoritm – sai märkimisväärselt rohkem usaldust. Ühe tingimusega: töötajad teadsid, et nende kolleegid osalesid süsteemi arendamises ja testimises. Teadlased nimetasid seda „sotsiaalseks heakskiiduks" (social proofing) – usaldus tehnoloogia vastu inimeste usaldamise kaudu, kes selle taga seisavad.
Rahaline efekt oli mõõdetav: algoritmi soovituste järgimine tõi +$36,95 lisatulu iga jaotamisotsuse kohta neljandas kvintiiilis ja +$104,96 – ülemises kvintiilis. Juhid, kes ignoreerisid algoritmi „läbipaistva loogika" tõttu, kaotasid reaalset raha.
Microsoft Researchi töö kinnitab seda paradoksi: selgitused ei vähenda liigset usaldust AI vastu, vaid mõnel juhul tugevdavad seda. Kasutajad tõlgendavad selgituste olemasolu kui süsteemi kontrollituse signaali – isegi kui selgitused ei ole informatiivsed. Vasconcelose ja kolleegide uurimus Stanfordist näitas: selgitused vähendavad liigset usaldust ainult siis, kui need on ülesandest lihtsamad. Kui selgitus on sama keeruline kui ülesanne, jätab kasutaja ratsionaalselt verifitseerimise vahele (märkus: uuring avaldati juba 2023. aastal, kuid puudutas tundlikku teemat – vaktsineerimine).
Lõhe juhtkonna ja meeskonna vahel
Olukorda muudab keerulisemaks radikaalne lahknevus AI tajumises organisatsiooni eri tasanditel – muster, mis on hästi nähtav AI ettevõttesisese juurutamise puhul üldiselt.
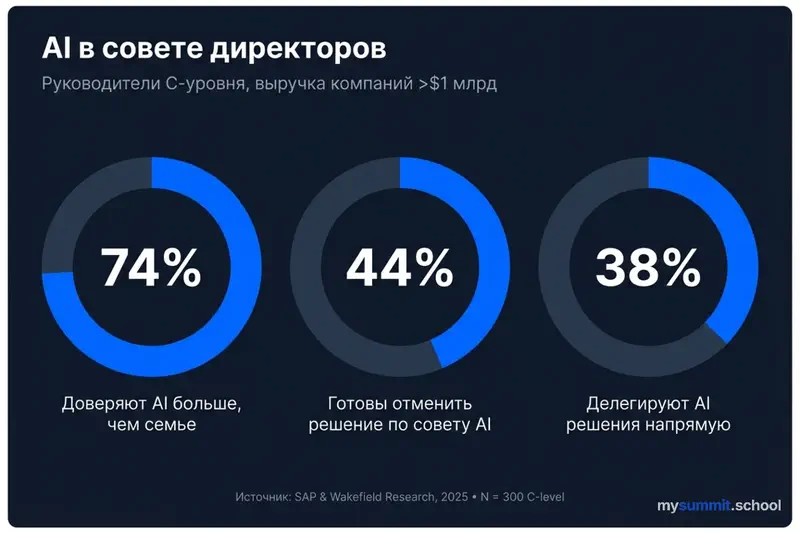
SAP-i ja Wakefield Researchi uuring („AI Has a Seat in the C-Suite", märts 2025) küsitles 300 C-taseme juhti ettevõtetest käibega üle $1 miljardi. Numbrid on hämmastava:
- 74% usaldab AI-d strateegiliste soovituste osas rohkem kui perekonda ja sõpru
- 44% on valmis laskma AI-l tühistada juba vastu võetud äriotsuse
- 38% delegeerib AI-le otsuste tegemise otse
- Ettevõtetes, kus AI juba asendab traditsioonilisi otsustusprotsesse, ulatub see osakaal 55%-ni
Liinitasandil – vastupidine dünaamika. BCG „AI at Work 2025" andmetel (10 600+ töötajat, 11 riiki) kasutab 72% töötajatest regulaarselt AI-d – kuid see on keskmine temperatuur. 78% juhtidest ja 85%+ tippjuhtidest töötab AI-ga iganädalaselt, samas eesliinitasandil kasutamine on kinni jäänud 51% juurde – number ei ole muutunud alates 2023. aastast. Ainult 25% liinitöötajatest saab juhtidelt mingisugust juhendamist AI kasutamise osas ja vaid 36% peab oma koolitust piisavaks.
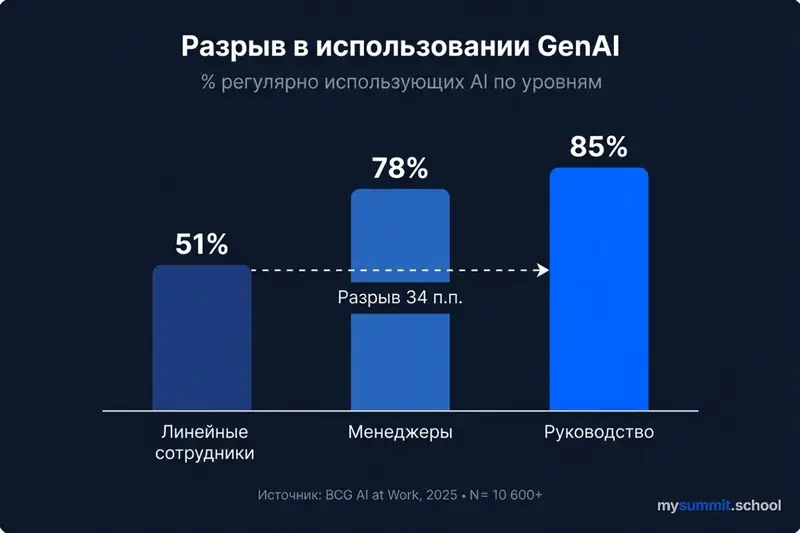

Seejuures on 54% töötajatest valmis kasutama AI-tööriistu isegi ilma ettevõtte loata – „vari-AI" kasvab. Ja 41% küsitletutest kardab kaotada tööd AI tõttu lähima kümne aasta jooksul, kusjuures juhid muretsevad rohkem (43%) kui liinitöötajad (36%).
Madal AI-kirjaoskus süvendab lõhet. HR Brew ja Censuswide’i andmetel (2024) kogevad madala AI-kirjaoskusega töötajad 6 korda rohkem ärevust, 7 korda rohkem hirmu ja 8 korda rohkem masendust – võrreldes AI-kirjaoskajate kolleegidega. Ja Jacobsi ja kolleegide katse (2021. aasta, 220 arsti, antidepressantide määramine) näitas: madala AI-kirjaoskusega arstid järgisid 7 korda sagedamini algoritmi valesid soovitusi.
See on läbipaistvuse dilemma peegelpilt: juhtkond surub peale AI-d „efektiivsuse nimel", töötajad vastavad vari-AI-ga „ellujäämise nimel". Läbipaistvus ülalt sünnitab läbipaistmatust alt.
Paradoksist protokollini: mida teadus pakub
Uuringud ei diagnosi ainult probleemi – need pakuvad konkreetseid mehhanisme ummikseisust välja pääsemiseks. Neli strateegiat, igaüks tõenduspõhine.
1. Normaliseerimine avalikustamise asemel
Schilke ja Reimann osutavad olulisele nüansile: autentsuse trahv käivitub, kui AI kasutamist tajutakse antud rolli jaoks ebatüüpilisena. Professor, kes kasutab AI-d hindamiseks – ebatüüpiline. Analüütik, kes kasutab AI-d ülevaate jaoks – juba lähemal normile.
Järeldus: selle asemel, et otsustada, kas avalikustada või varjata – tasub muuta AI kasutamine normatiivselt oodatuks. Kui kõik meeskonnas kasutavad avalikult AI-d, lakkab tüüpilisuse komponent lagunemast. See ei ole enam „ta asendas töö algoritmiga", vaid „ta kasutas standardset tööriista, nagu kõik".
SAP SuccessFactorsi kogemus kinnitab: kui AI on integreeritud rutiinsetesse abiprotsessidesse – eesmärkide seadmisse, kolleegide tagasisidesse – lakkab see olemast erand:
| Mõõdik | Muutus |
|---|---|
| Tagasiside kvaliteet (töötajate hinnangu järgi) | 80% positiivne konsensus |
| Tagasiside sagedus (4+ korda aastas) | +47% |
| Rahulolu eesmärkide seadmise protsessiga | +30% |
2. Sotsiaalne heakskiit tehnilise läbipaistvuse asemel
Harvardi uuring Tapestrys annab konkreetse retsepti: kaasake lõppkasutajad AI-tööriistade valimisse, testimisse ja valideerimisse. Kui töötajad teavad, et nende sarnase kogemusega kolleegid osalesid süsteemi arendamises, on usaldus „musta kasti" vastu kõrgem kui läbipaistva algoritmi vastu.
See skaleerub: ei ole vaja igaühele selgitada, kuidas mudel töötab. Piisab sellest, et inimesed, keda meeskond usaldab, ütlevad: „Me kontrollisime – töötab". BetterUp’i andmed täiendavad: suhtlemisoskuste koolitus (oskus kuulata, küsimusi esitada, konteksti anda) suurendab töötajate koostööd AI-ga 30% ja tõstab tulemuste kvaliteeti.
3. Kognitiivsed hõõrdepunktid automaatse aktsepteerimise asemel
Bucinca ja kolleegid (2021, 199 vastajat, Harvard) näitasid: kui paluda inimesel esmalt ise mõelda ja alles siis näidata AI vastust – usaldab ta mudelit vähem pimedalt. Microsoft Research toob välja kolm konkreetset mehhanismi:
- Ebakindluse signaalid: AI, mis ütleb „ma ei ole selles vastuses kindel", vähendab liigset tuginemist tõhusamalt kui numbrilised näitajad nagu „kindlus 73%". Esimene käivitab kriitilise mõtlemise, teine tekitab täpsuse illusiooni.
- AI-enesekriitika: mudel, mis argumenteerib oma järelduse vastu, aitab kasutajal näha nõrku kohti. See on üks paljutõotavamaid mustreid 2025. aasta sünteesist.
- Eelnev otsustus: kasutaja sõnastab oma vastuse enne, kui näeb AI soovitust. Lihtne tegevuste järjekord muudab kõik.
Kuid on oluline mööndus: kasutajad hindasid neid liideseid kõige vähem mugavateks. Tõhususe ja mugavuse vahel on pöördvõrdeline seos. See, mis töötab – ärritab. See, mis meeldib – ei aita. Selliste mehhanismide juurutamisel tuleb anda selged selgitused – miks te seda teete.
4. „Piloodid", mitte „reisijad"
BetterUp ja Stanford pakuvad selge raamistiku. 28% töötajatest-„pilootidest" – neist, kes aktiivselt redigeerivad, kontrollivad ja täiendavad AI tulemust kontekstiga – näitavad 3,6 korda kõrgemat tootlikkust ja 3,1 korda kõrgemat lojaalsust. Ülejäänud 72% on „reisijad", kes delegeerivad AI-le ilma parandusteta.
Vahe ei ole tööriistas, vaid hoiakus. Ja seda hoiakut saab treenida: suhtlemisoskuste koolituse läbinud töötajad suhtlevad AI-ga 30% aktiivsemalt ja loovad kvaliteetsemat sisu. Organisatsioonid, mis kehtestavad selged AI kasutamise reeglid, määratlevad konkreetsed stsenaariumid ja toetavad inimlikku otsustusvõimet – puutuvad workslop’iga oluliselt harvem kokku.
Mida sellega teha: tegevuskava
Andmed osutavad konkreetsetele sammudele juhile, kes kasutab AI-d ja juhib AI-d kasutavat meeskonda.
Isikliku suhtluse jaoks:
- Selle asemel, et öelda „Selle kirjutas AI", öelge „Valmistasin selle ette AI abiga ja kohandasin meie konteksti järgi". Fookus teie panusel, mitte tööriistal – nii väldite nii autentsuse trahvi kui ka petmise trahvi.
- Lisage inimliku mõtlemise jälgi: isiklik kogemus, konkreetsed näited koostööst, viited varasematele aruteludele – kõik, mida AI ei saa teada.
- Sõnastage oma seisukoht enne AI käivitamist. See muudab teid „reisijast" „piloodiks" – ja vähendab AI vastuse pimeda aktsepteerimise riski.
Meeskonna juhtimise jaoks:
- Tasub juurutada protsessiaudit: hinnata mitte lihvitud tulemust, vaid teed sinna – mustandid, iteratsioonid, punktid, kus töötaja AI-ga ei nõustunud.
- AI kasutamine tasub meeskonnas normaliseerida: kui kõik töötavad avalikult AI-ga, lakkab tüüpilisuse komponent lagunemast.
- Ehitage sotsiaalset usaldust: kaasake meeskond AI-tööriistade valimisse ja testimisse. Harvardi uuring Tapestrys tõestas: usaldus süsteemi vastu kasvab kolleegide usaldamise kaudu, kes selle heaks kiitsid.
- Andke AI kätte, mitte pähe. SAP-i kogemus: AI töötaja abistamiseks tekitab usaldust, AI kontrollimiseks – hävitab selle.
- Kaotage lõhe AI-kirjaoskuses. Madala AI-kirjaoskusega arstid järgisid 7 korda sagedamini valesid soovitusi. Koolitus ei ole valikaine, vaid usalduse infrastruktuur.
Läbipaistvuse dilemmal ei ole ideaalset lahendust. Avalikustamine vähendab usaldust 7–18%. Varjamine hävitab selle, kui tõde ilmneb. Kuid nende pooluste vahel on töötsoon: kasutada AI-d kui tööriista, mitte kui autorit. Lisada oma hääl, mitte delegeerida seda.
Võib-olla tasub eristada kahte küsimust: „Kas selle kirjutas AI?" ja „Kas selle teksti taga seisab inimene, kellele ei ole ükskõik?". Esimene küsimus on tehnoloogiast. Teine – suhetest. Ja just vastus teisele küsimusele määrab, kas te säilitate usalduse.
AI kirjutab – teie otsustate, kuidas esitada
Kursuse avatud moodul: kuidas kasutada AI-d professionaalses suhtluses, säilitades klientide ja kolleegide usaldust.
Jätka õppimist
Ava õpik ja jätka sealt, kus pooleli jäid
Kuidas AI aitas selle artikli loomisel (järgides enda soovitusi – avalikustame):
- Teema uurimine. AI aitas leida ja süstematiseerida uuringuid, artikleid ja juhtumiuuringuid teema kohta. Kuid iga allikat luges inimene, andmed kontrolliti originaalpublikatsioonide järgi ja artikli mustand kirjutati käsitsi.
- Infograafika. Kõik pildid on AI-genereeritud. Kuid promptid – andmete, kompositsiooni ja allikate kirjeldused – kirjutas inimene loetud uuringute põhjal.
- Toimetamine. AI kontrollis artikli struktuuri vastavust toimetamise standarditele ja sihtrühmale fokuseeritust. Kuid standardid ise, brändi hääl ja toimetamispoliitika – on meie välja töötatud.
Me oleme „piloodid", mitte „reisijad".




Allikad
- Schilke, O. & Reimann, M. (2025). The authenticity penalty of AI disclosure. Organizational Behavior and Human Decision Processes, 188. DOI
- Niederhoffer, K. & Hancock, J. (2025). AI-generated workslop is destroying productivity. Harvard Business Review. HBR
- Jain, G., Pareek, S. & Carlbring, P. (2024). Perception of AI-generated mental health responses. Internet Interventions, 38. DOI
- BCG (2025). AI at Work 2025: Momentum Builds, but Gaps Remain. BCG
- SAP & Wakefield Research (2025). AI Has a Seat in the C-Suite. SAP
- Bucinca, Z. et al. (2021). To trust or to think: Cognitive forcing functions. Proceedings of the ACM on Human-Computer Interaction, 5(CSCW1). DOI
- Vasconcelos, H. et al. (2023). Explanations can reduce overreliance on AI systems during decision-making. Proceedings of the ACM on Human-Computer Interaction, 7(CSCW1). DOI
- Jacobs, M. et al. (2021). How machine-learning recommendations influence clinician treatment selections. Translational Psychiatry, 11, 108. DOI
- Microsoft Research (2024). Appropriate Reliance on GenAI. PDF