Parimad AI-d juhile ilma VPN-ita: uuringu andmed

Me lopetasime mahuka uuringu: 33 AI mudelit, 8 kategooriat juhtimisülesandeid. Küsimus oli lihtne – milline AI töötab juhi jaoks kõige paremini? Kuid vastus osutus huvitavamaks, kui ootasime.
Eriti kui jutt läks mudelite juurde, mis on Venemaal kättesaadavad ilma VPN-ita.
Mida ja kuidas me testisime
Enne numbreid – lühidalt metoodikast, sest ilma selleta andmed ei tähenda midagi.
33 mudelit testiti 32 reaalse juhtimisstsenaariumi peal: planeerimine, suhtlus, analüüs, meeskonnatöö, info otsimine jpm. Iga mudel sai identsed päringud vene keeles – tavalise juhi vaatenurgast, ilma spetsiaalselt lihvitud promptideta. Täpselt nii töötab enamik inimesi AI-ga.
Hindamise viisid läbi kaks kohtunikku – Claude Opus 4.5 ja Gemini 3 Pro. Tegime inimkalibreerimise 23 hindega, mis paljastas süstemaatilised nihked: Opus alandas hindeid 0,39 punkti võrra, Gemini tõstis 0,53. Pärast korrigeerimist arvutatakse lõpphindeks valemiga 70% Opus + 30% Gemini. Rohkem selle kohta metoodika artiklis.
Skaala on 1-st 5-ni. Kontekstiks: 4,0 on juba kindlalt hea tulemus, 4,5+ on suurepärane.
Lühike vastus: mida kasutada ilma VPN-ita
Kui ei taha edasi lugeda – siin on vastus.
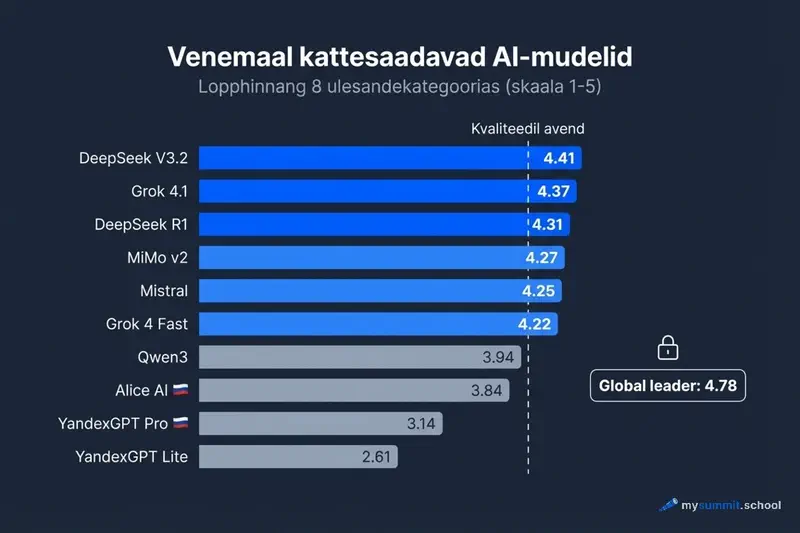
Esimene valik: DeepSeek V3.2. Lõpphindeks 4,41 / 5,0. Tasuta vestlus aadressil chat.deepseek.com, API hind ~$0,0007 päringu kohta – sisuliselt sendid. Parim tulemus kõigi Venemaal kättesaadavate mudelite seas.
Teine valik: Grok 4.1 Fast xAI-lt. Hindeks 4,37. Kättesaadav otse x.ai kaudu, ilma VPN-ita. Alates 2026. aasta märtsist on xAI hindu radikaalselt langetanud – nüüd ~$0,0007 päringu kohta, võrreldav DeepSeekiga.
Kolmas valik: DeepSeek R1. Hindeks 4,31 – laiendatud mõtlemisega versioon, eriti tugev analüütiliste ülesannete puhul. API ~$0,0028 päringu kohta.
Kõik. Enamiku juhtimisülesannete jaoks piisab neist kolmest mudelist.
Ülejäänu on detailid, mis on olulised sõltuvalt teie konkreetsetest ülesannetest ja eelarvest.
Täielik pilt: kättesaadavate mudelite tasemed
Jagasime kõik testitud mudelid lõpphindeksi järgi kolme tasemesse.
Tase 1: Venemaa top 3 (>= 4,30)
| Mudel | Hindeks | Juurdepääs | Hind / päring |
|---|---|---|---|
| DeepSeek V3.2 | 4,41 | chat.deepseek.com + otse-API | ~$0,0007 |
| Grok 4.1 Fast | 4,37 | x.ai (X Premium / SuperGrok) | ~$0,0007 |
| DeepSeek R1 | 4,31 | chat.deepseek.com + otse-API | ~$0,0028 |
Tase 2: tugevad alternatiivid (4,00–4,29)
| Mudel | Hindeks | Juurdepääs | Hind / päring |
|---|---|---|---|
| MiMo v2 Flash (Xiaomi) | 4,27 | ainult API | ~$0,0004 |
| Mistral Large | 4,25 | chat.mistral.ai (Le Chat) + API | ~$0,0078 |
| Grok 4 Fast | 4,22 | x.ai | ~$0,0007 |
| MiniMax M1 | 4,12 | ainult API | – |
| Grok 4 | 4,12 | x.ai | ~$0,0007 |
| Grok 3 | 4,11 | x.ai | ~$0,0007 |
Tase 3: märgatavalt nõrgemad (3,50–3,99)
| Mudel | Hindeks | Juurdepääs |
|---|---|---|
| Qwen3 235B | 3,94 | chat.qwen.ai |
| Alice AI LLM (Yandex) | 3,84 | alice.yandex.ru / Yandexi brauser |
| Gemma 3 27B | 3,73 | ainult API |
| Qwen3 32B | 3,65 | chat.qwen.ai |
Vahe tasemete vahel on märkimisväärne. Kui Tase 1 on kindel „B+", siis Tase 3 on pigem „C+". Rutiinsete ülesannete jaoks sobib. Tõsiste otsuste jaoks – enam mitte.
Mis toimub globaalselt
Testisime teadlikult ka Venemaal blokeeritud mudeleid. Muidu poleks võimalik mõista „Venemaa vahe" ulatust.
Globaalne top näeb välja nii:
| Mudel | Hindeks | Kättesaadavus Venemaal |
|---|---|---|
| Claude Sonnet 4.5 (Anthropic) | 4,78 | VPN vajalik |
| GPT-5.2 Pro (OpenAI) | 4,78 | VPN vajalik |
| Claude Opus 4.5 (Anthropic) | 4,77 | VPN vajalik |
Globaalse top 3 keskmine hindeks: 4,78. Venemaa top 3 keskmine hindeks: 4,36.
Vahe – 0,42 punkti.
Abstraktsete numbrite poolest tundub see väike. Kuid skaalal 1-st 5-ni on see vahe „suurepärase" ja „hea" vahel. Umbes nagu A–/B+ lääne hindamissüsteemis. Enamiku igapäevaste ülesannete puhul pole vahe kriitiline. Keerukate analüütiliste või strateegiliste tööde puhul – see võib olla tuntav.
Huvitav on see, et vahe ei ole ülesannete kategooriate lõikes ühtlane.
Kuidas Venemaal kättesaadavad mudelid tulevad toime erinevate ülesannetega
Mida kategooriad tähendavad: Planeerimine – plaanide koostamine, koosolekute päevakorrad, ülesannete prioritiseerimine. Probleemide lahendamine – rikete analüüs, juurpõhjuste tuvastamine, kriisijuhtimine. Analüüs – andmete tõlgendamine, aruannetest järeldused, riskihindamine. Regionaalne – Venemaa seadusandluse, kultuuriliste eripärade, kohalike tavade tundmine. Suhtlus – ärikirjad, tagasiside, meeskonnale sõnumid. Uurimine – faktikontroll, info kogumine, allikate võrdlus. Meeskond – inimeste juhtimine, konfliktid, motivatsioon, tulemuslikkuse hindamine. Koolitus – arengukavad, karjäärivestlused, koolitusmaterjal.
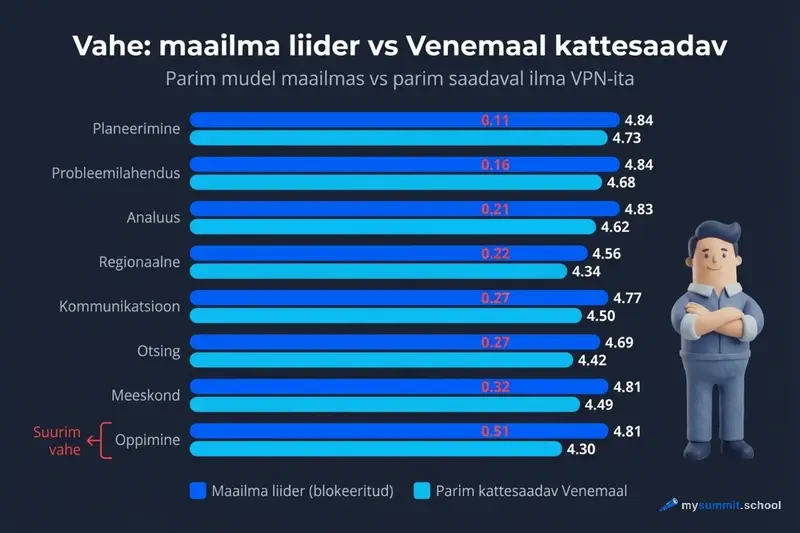
Uurisime 8 kategooriat. Mõnes on vahe globaalse tipuga minimaalne – teistes märkimisväärne.
| Ülesande kategooria | Globaalne liider | Hindeks | Parim Venemaal | Hindeks | Vahe |
|---|---|---|---|---|---|
| Planeerimine | Sonnet | 4,84 | DeepSeek V3.2 | 4,73 | 0,11 |
| Probleemide lahendamine | Sonnet | 4,84 | DeepSeek V3.2 | 4,68 | 0,16 |
| Analüüs ja otsused | Sonnet | 4,83 | DeepSeek R1 | 4,62 | 0,21 |
| Suhtlus | GPT-5 Mini | 4,77 | Grok 4.1 | 4,50 | 0,27 |
| Info otsimine | GPT-5.2 Pro | 4,69 | DeepSeek R1 | 4,42 | 0,27 |
| Meeskonna juhtimine | GPT-5.2 Pro | 4,81 | DeepSeek V3.2 | 4,49 | 0,32 |
| Regionaalne eripära | GPT-5.2 | 4,56 | DeepSeek V3.2 | 4,34 | 0,22 |
| Koolitus ja areng | Opus | 4,81 | DeepSeek V3.2 | 4,30 | 0,51 |
Kaks järeldust torkavad silma.
Esiteks: planeerimises ja probleemide lahendamises jõuavad Venemaal kättesaadavad mudelid globaalsele tipule peaaegu järele. 0,11–0,16 punkti vahe on reaalses töös praktiliselt nähtamatu.
Teiseks: töötajate koolituse ja arengu ülesannetes on vahe maksimaalne – 0,51 punkti. See on juba tuntav. Kui kasutate AI-d sageli arengukavade kirjutamiseks, kompetentsipõhise tagasiside jaoks või karjäärivestlusteks – siin jäävad Venemaal kättesaadavad mudelid kõige rohkem maha.
9 õppetundi AI-st juhtidele – ilma registreerimise ja tasuta
Makset ei nõuta • Teavitus käivitumisel
YandexGPT paradoks: miks „kodumaine" mudel kaotab
Siin on tulemus, mis meid kõige rohkem üllatas.
Alice (Yandexi tarbija-AI assistent, mida juhib YandexGPT – Venemaa suurim kohalik keelemudel) sai hindeks 3,84 – see on Tase 3. Madalam kui DeepSeek, Grok, Mistral ja isegi MiMo v2 Flash Xiaomilt, millest enamik juhte pole kunagi kuulnud.
Eriti kõnekas on kategooria „regionaalne eripära" – ülesanded, mis hõlmavad Venemaa seadusi, regulatsioone ja kultuurilist konteksti. Oleks loogiline, et Yandex on siin võitmatu. Kuid ei: Alice saab 3,68, samas kui GPT-5.2 saab 4,56.
See paneb mõtlema. Miks kaotab vene keelel ja Venemaa kontekstil treenitud mudel Ameerika mudelile Venemaa-spetsiifiliste ülesannete puhul?
Huvitav, et Yandex ise väidab, et Alice AI võidab DeepSeek V3.1 ja Qwen3-235B 60% äriülesannetes. Detailid vaadates – Alice on tugevaim teksti redigeerimisel (68% võite DeepSeeki üle) ja kokkuvõtete tegemisel (65%). Kuid teksti genereerimisel kaotab Alice juba Qwenile (62% Qweni kasuks) ja avatud küsimustes – samuti (61% Qweni kasuks).
Oluline detail: Yandex võrdles DeepSeek V3.1-ga, aga meie testisime juba välja antud V3.2 – oluliselt uuendatud versiooni. Meie uuring näitab teistsugust pilti: Alice (3,84) jääb maha DeepSeek V3.2-st (4,41) kõigis kaheksas juhtimisülesannete kategoorias. Lahknevus tuleneb erinevatest mudeliversioonidest, erinevatest metoodikatest ja erinevatest ülesannete komplektidest. Kuid praktikas on tulemus juhi jaoks sama: DeepSeek V3.2 annab kasulikumaid ja täpsemaid vastuseid.
Meie tõlgendus: mudeli analüütilised võimed on olulisemad kui „emakeel". DeepSeek räägib suurepäraselt vene keelt ja on samal ajal analüütiliselt tugevam.
Kui kasutate YandexGPT-d Alice’i kaudu Yandexi brauseris peamise töövahendina – meie andmed viitavad, et jätate märkimisväärse potentsiaali kasutamata. Üksikasjalik YandexGPT ülevaade kirjeldab, milles see tugev on ja kus jääb alla.
Rohkem Yandexi mudelitest
Uuringus osales neli Yandexi mudelit. Nende tulemused kategooriate kaupa:
| Kategooria | Alice AI LLM | YandexGPT Pro 5.1 | YandexGPT Pro 5 | YandexGPT Lite |
|---|---|---|---|---|
| Analüüs ja otsused | 4,42 | 3,66 | 3,20 | 3,13 |
| Probleemide lahendamine | 4,33 | 3,62 | 3,08 | 2,64 |
| Suhtlus | 4,19 | 3,43 | 3,06 | 2,66 |
| Planeerimine | 4,15 | 3,47 | 3,19 | 2,86 |
| Info otsimine | 3,95 | 2,18 | 2,53 | 2,38 |
| Regionaalne eripära | 3,68 | 2,95 | 2,50 | 2,37 |
| Meeskond | 3,50 | 3,11 | 2,84 | 2,65 |
| Koolitus ja areng | 2,70 | 2,70 | 2,40 | 2,24 |
| Keskmine | 3,86 | 3,14 | 2,85 | 2,61 |
Põhilised tähelepanekud:
- Alice AI LLM on Yandexi ainus konkurentsivõimeline mudel. Analüüsis (4,42) ja probleemide lahendamises (4,33) ulatub see Taseme 2 tasemele. Ülejäänud kolm mudelit on märgatavalt nõrgemad. Alice API maksab 0,50 RUB/1K sisendtokenit ja 2,00 RUB/1K väljundtokenit (kehtiva 50% allahindlusega).
- Koolitus ja areng on kõigi Yandexi mudelite nõrk koht. Isegi Alice saab siin ainult 2,70 – tema madalaim kategooria tulemus. Võrdluseks: DeepSeek V3.2 saab samas kategoorias 4,30.
- YandexGPT Pro 5.1, Pro 5 ja Lite keskmine on 2,6–3,1. Sellel tasemel mudeli vastused pigem kahjustavad kui aitavad – liiga palju ebatäpsusi ja pealiskaudseid soovitusi.
- Regionaalne eripära – peaks olema Yandexi trump – annab Alice’ile ainult 3,68. DeepSeek V3.2 saab samas kategoorias 4,34.
Rohkem Yandexi mudelite võimaluste ja piirangute kohta YandexGPT ülevaates.
Vestlus vs. API: mis on kättesaadav ilma tehniliste oskusteta
Oluline täpsustus: uuring viidi läbi API kaudu. Kuid enamik juhte kasutab vestlusliideseid, mitte koodi. Siin on see, mis on reaalselt kättesaadav „ühe klikiga":
Vestlusliidesed:
- DeepSeek – tasuta vestlus aadressil chat.deepseek.com. Töötab ilma VPN-ita, pole vaja Vene telefoninumbriga registreeruda. Lihtsalt avage ja töötage.
- Grok – X Premium ($8/kuus) või SuperGrok ($30/kuus) kaudu aadressil x.ai. Vajab tellimust, kuid juurdepääs on otsene.
- Qwen – tasuta vestlus aadressil chat.qwen.ai. Taseme 3 mudelid, kuid lihtsate ülesannete jaoks sobib.
- YandexGPT/Alice – alice.yandex.ru või Yandexi brauseri kaudu. Tasuta ja mugav, kuid kvaliteet on selline, nagu uuring näitas.
- Mistral – tasuta Le Chat aadressil chat.mistral.ai. Hea alternatiiv, eriti Euroopa konteksti jaoks.
Ainult API:
- MiMo v2 Flash – vestlusliidest pole, ainult arendajatele. Kuid ~$0,0004 päringu kohta.
- MiniMax M1 – sama olukord.
Kui te ei taha API-ga tegeleda – teie valik on DeepSeek igapäevatööks ja Grok kallima, kuid kvaliteetsema alternatiivina.
80/20 strateegia: kuidas kulusid optimeerida
Kui olete valmis API kaudu töötama – on olemas nutikas strateegia.
Kõik ülesanded pole võrdsed. Partnerile kirja mustand on üks asi. Finantsaruande analüüs enne juhatuse koosolekut on teine.
80% ülesannete jaoks piisab odavamast mudelist: MiMo v2 Flash ($0,0004/päring) või DeepSeek V3.2 ($0,0007/päring). 20% keerukate ülesannete jaoks – DeepSeek R1 ($0,0028/päring) või Grok 4.1 Fast ($0,0007/päring).
Ligikaudne arvutus 1000 päringu kohta kuus:
- 80/20 strateegia MiMo + DeepSeek R1-ga: ~$0,85/kuus
- Ainult DeepSeek V3.2 kõige jaoks: ~$0,73/kuus
- Ainult Grok 4.1 Fast kõige jaoks: ~$0,70/kuus
Jah, lugesite õigesti – alla dollari kuus. 2026. aasta märtsi uute hindadega maksab API-juurdepääs parimatele Venemaal kättesaadavatele mudelitele vähem kui tass kohvi. Kulude küsimus on sisuliselt lahendatud – valige kvaliteedi järgi.
See lähenemine – AI kasutamine kaaspiloonna erinevate tööriistade tasemetega – on üksikasjalikult kaetud meie GenAI tööriistade põhjalikus võrdluses.
Olulised hoiatused
Mõned asjad, mida tuleb arvestada enne nende andmete põhjal otsuste tegemist.
Mudeleid uuendatakse. Alates testimisest (jaanuar 2026) on GPT-5.2 juba saanud GPT-5.4-ks, Qwen on välja andnud uusi versioone. GPT-4o, mis oli 29. kohal, lõpetati ametlikult 2026. aasta veebruaris – kuid see ei mõjuta järeldusi, kuna see oli juba nõrk. Ülejäänud uuringu mudelid on endiselt saadaval. Me ei oota juhtimisülesannete reitingus suuri muutusi – suured mudelid arenevad järk-järgult. Kuid kui testite konkreetset versiooni – kontrollige selle hetkeseisu.
GigaChati ei testitud. GigaChat on Sberbanki (Venemaa suurima panga) suur keelemudel. Jätsime selle teadlikult sellest uuringust välja – see on eraldi lugu ettevõtte juurdepääsulepingute ja spetsiifilise regulatiivse kontekstiga. Võib-olla järgmises uuringus. Kui tunnete huvi mudeli praeguse seisukorra vastu – GigaChati ülevaade annab ajakohase pildi.
API != vestlusliides. Testisime API kaudu standardpäringutega. Tegelik vestluskogemus võib erineda – erinevad süsteemipromptid, erinev kontekst, erinevad töörežiimid.
Naiivne kasutaja. Kõik päringud koostati ilma spetsiaalse promptide optimeerimiseta. Kui oskate AI-ga töötada – teie tulemused on kõigi mudelite puhul paremad. Lõhed nende vahel võivad muutuda.
Kokkuvõte
Hea uudis: 0,42-punktiline vahe globaalse tipuga pole katastroof. Venemaa AI kasutajatel on juurdepääs „B+" taseme tööriistadele, samas kui globaalne tipp on „A–". Enamiku igapäevaste juhtimisülesannete jaoks on see täiesti vastuvõetav.
DeepSeek V3.2 on ilmne esimene valik. Tasuta vestlus, odav API, parim hindeks kättesaadavate mudelite seas. Üksikasjalik DeepSeeki ülevaade aitab teil mõista, kuidas seda täpselt kasutada.
Grok on tugev alternatiiv otsese juurdepääsuga x.ai kaudu. Groki ülevaade kirjeldab selle tugevusi ja stsenaariumeid, kus see DeepSeeki ületab.
Aga panustada YandexGPT-le kui peamisele töövahendile – andmed seda ei toeta.
Paradoksaalselt on 2026. aastal parim AI venekeelse juhi jaoks Hiina mudel. Kuidas see juhtus ja mida see ütleb tööstuse arengu kohta – see on hea küsimus eraldi analüüsiks.
Õppige AI-d süsteemselt – ilma oletamata
9 õppetundi AI-ga töötamiseks juhtidele: milline tööriist millise ülesande jaoks, kuidas vältida hallutsinatsioone, kuidas luua tõhus töövoog. Ilma registreerimise ja tasuta.