40 GigaChat juhtumit: kontrollime Sberi võrdlusuuringut andmetega
AI-модели в этой статье
Sber – Venemaa suurim pank ja üks selle riigi juhtivaid tehisintellekti arendajaid – andis välja reklaami-eriprojekti: nelikümmend ärijuhtumit ettevõtetest, kes võtsid kasutusele GigaChati (Sberi enda vestlusmudeli) ja räägivad selle mõjust. EdTech, MedTech, HRTech, küberturve, PropTech. Ilusad kaardid, konkreetsed numbrid, päris idufirmad.

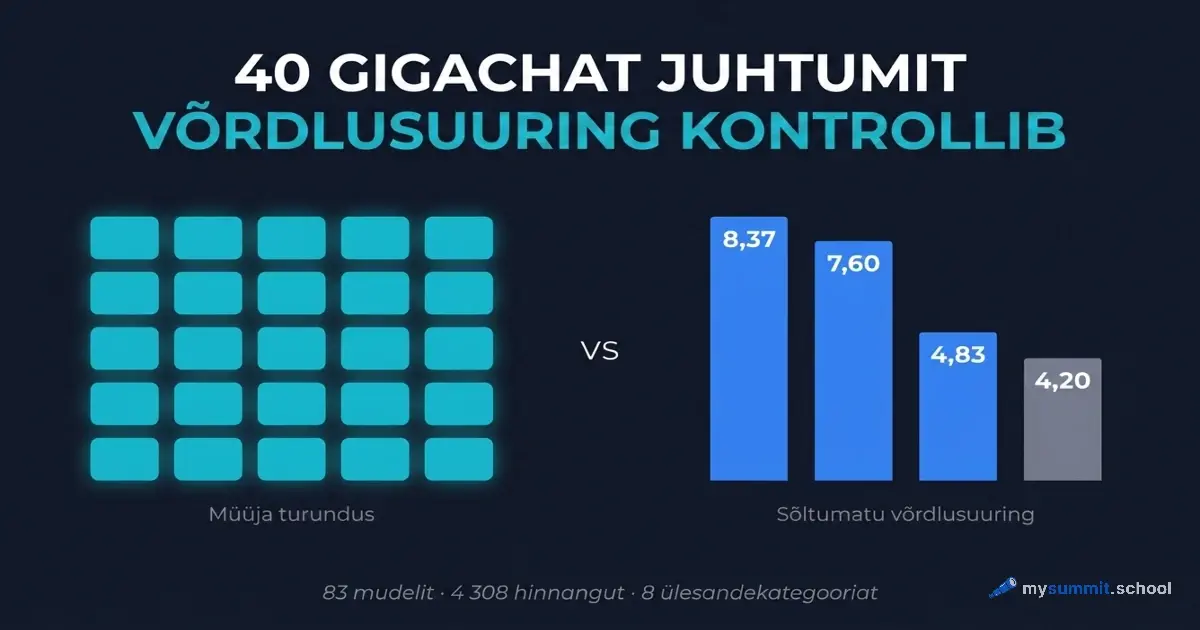
Pildil: kiirendi Sber500×GigaChat reklaamslaid „Sammu võrra ees" – 40 idufirmat 9 valdkonnast. Lubatud efektid: äriprotsessid kuni x16 kiiremad, kulud kuni 90% väiksemad, ülesannete automatiseerimine kuni 95%, käive kuni 30% suurem.
Meil on võrdlusuuring: 29 mudelit, 4 308 sõltumatut hinnangut juhtimisülesannetel. GigaChat on selles teise testlaine järel viimasel, 29. kohal. See loob huvitava olukorra.
Mitte sellepärast, et Sber valetaks. Juhtumid on päris, idufirmad olemas, automaatika töötab. Küsimus on muus: kas see oli optimaalne mudel ülesannete jaoks, mida nad lahendasid?
Kust sellised juhtumid tulevad
Sberi reklaammaterjal kuulub žanrisse, millel on kindel nimi: vendor-sponsored case study ehk müüja rahastatud edulugu. Ettevõtted räägivad oma edust konkreetse tööriistaga, müüja avaldab ja edendab. See on tavaline praktika – nii toimivad kõik suured TI-ettevõtted, alates Microsoftist kuni Anthropicuni.
Probleem on selles, et müüja edulugu vastab küsimusele „kas lahendus töötab" – aga mitte küsimusele „kas see on optimaalne lahendus". Ettevõte, kes võttis GigaChatil põhineva vestlusroboti kasutusele ja säästis 40% operaatorite ajast, kirjeldab tulemust ausalt. Aga ta ei teinud A/B-testi Qwen 3.6 Flashiga – sest ükski päris ettevõte ei korralda enne iga projekti täielikku hanget kõikide mudelite seas.
Just sellepärast sõltumatud võrdlusuuringud üldse olemas on.
Mida meie võrdlusuuring näitab
Me testisime TI-mudeleid kaheksa juhtimisülesannete kategooria järgi – andmeanalüüsist ja teabeotsingust kuni planeerimise ja meeskonnatööni. Metoodika: kaks sõltumatut LLM-kohtunikku inimese kalibreerimisega. Põhjalikult sellest, kuidas võrdlusuuringud on üles ehitatud ja miks neid tasub usaldada teatud reservatsioonidega.
Sberil on praegu kaks põhilist tooteliini: GigaChat 2 Max ja GigaChat Ultra. Oluline on neid mitte segi ajada – need on erineva kvaliteeditasemega mudelid.
Liini lipulaev on GigaChat Ultra. API on saadaval ärikliendile eraldi lepingu alusel, üksikarendajale ainult veebiliides gigachat.ru. Meie võrdlusuuringus saavutas see koha 28 / 29 hindega 4,83 – parim tulemus kõigi Venemaa mudelite seas meie testis.
Põhimudel avaliku API-ga on GigaChat 2 Max, just seda kasutab enamik juhtumites mainitud idufirmadest. Koht 29 / 29, hinne 4,20. Esimeses testlaines kogus sama mudel 3,08 – paari kuuga märkimisväärne edasiminek.
See on oluline vahe. Enamik juhtumites mainitud idufirmadest töötab avaliku API kaudu – ehk GigaChat 2 Maxiga. Need, kes said ärilise juurdepääsu Ultrale, töötavad tugevama mudeliga – aga ka teise hinnaga. Vaatame, kuidas GigaChat 2 Max juhtumite ülesannetega täpsemalt hakkama saab.
| Ülesandekategooria | GigaChat 2 Max | GigaChat Ultra |
|---|---|---|
| Teabeotsing | 29 / 29 (3,87) | 28 / 29 (4,71) |
| Analüüs ja otsused | 29 / 29 (4,39) | 28 / 29 (5,44) |
| Planeerimine | 29 / 29 (4,33) | 28 / 29 (5,92) |
| Probleemilahendus | 28 / 29 (4,27) | 29 / 29 (4,25) |
| Piirkondlik teadlikkus | 29 / 29 (3,57) | 28 / 29 (3,98) |
| Kommunikatsioon | 28 / 29 (4,74) | 29 / 29 (4,74) |
| Meeskonnatöö | 29 / 29 (4,41) | 28 / 29 (5,16) |
| Õpe ja areng | 29 / 29 (4,00) | 28 / 29 (4,48) |
Mõlemad Sberi mudelid hõivavad võrdlusuuringus kaks viimast kohta, kuid punktide vahe nende vahel on märgatav: Ultra kogub planeerimisel 5,92, Max – 4,33. Ultra on API kaudu kättesaadav ainult äriklientidele, Max aga avaliku API kaudu. Enamik juhtumite idufirmadest töötab Maxiga.
Nelikümmend juhtumit: mis ülesanded need on
Lugesin kõik nelikümmend kaarti läbi. Ülesanded jagunevad mõnda suunda.
Umbes kolmandik – vestlusrobotid ja sissetulevate päringute töötlus. Kindlustusfirma automatiseeris klientide päringutele vastamise, meditsiiniteenus tegi visiidile registreerimise abilise, pank võttis kasutusele klienditoe abilise. See on päris ja töötav ülesanne iga piisavalt tugeva LLM-i jaoks.
Veel üks suur rühm – teksti ja dokumentide genereerimine: turundusmaterjalid, kinnisvaraobjektide kirjeldused, personalidokumentatsioon. HRTech-ettevõte automatiseeris ametijuhendite koostamise, PropTech-idufirma – korterite kirjeldused, MarTech-platvorm – reklaamtekstid eri segmentidele.
Edasi algab territoorium, kus võrdlusuuringu andmed tõstatavad küsimusi. Dokumentide ja andmete analüüs – CV-de, meditsiinidokumentide läbivaatus, päringute klassifitseerimine. Mõni juhtum küberturbe vallast: ohuanalüüs, intsidentide klassifitseerimine, raportite genereerimine. Ja eraldi – spetsiifilised valdkonnaülesanded, näiteks TI-abiline personaliintervjuude jaoks või soovitussüsteemid EdTechile.
Kus võrdlusuuringu andmed turundusele vastu räägivad
Võtame kolm juhtumit eri kategooriatest ja vaatame neid läbi andmete.
Üks EdTech-juhtumitest – kliiniliste juhtumite läbivaatuse automatiseerimine arstitudengite õppeks. Ülesanne nõuab faktitäpsust, õigeid viiteid allikatele ja hallutsinatsioonide puudumist.
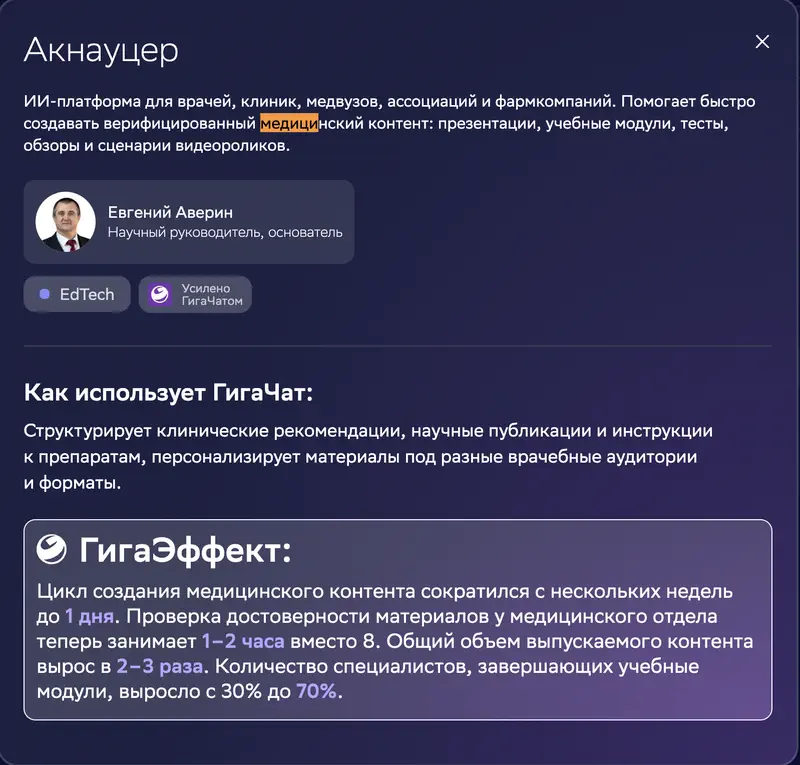
Juhtumikaardil: Aknautser, TI-platvorm meditsiinile. Lubatud „GigaEfekt": sisuloome tsükkel lühenes mitmelt nädalalt 1 päevani, faktikontroll 8 tunnilt 1–2 tunnini, toodetud sisu maht kasvas 2–3 korda ja õppemoodulid lõpetavate spetsialistide osakaal kasvas 30%-lt 70%-ni.
Meie võrdlusuuringu kategoorias „teabeotsing": GigaChat 2 Max on viimasel, 29. kohal 29-st. Konkreetne nõrkus kirjelduses: „leiab analüüsi õige suuna, kuid mõtleb välja tööriistade hinnad, viited uuringutele ja juriidilised normid – ilma iga fakti ülekontrollimiseta on ohtlik kasutada".
Juhtum on täiesti reaalne. Aga ettevõte, kes ei kontrolli üle iga mudeli järeldust, töötab mudeliga, mis on täpsuselt viimasel kohal 29 saadaolevast.
Mitu MarTech-ettevõtet kirjeldab reklaammaterjalide genereerimise automatiseerimist. Kommunikatsioon – 28. koht 29-st, GigaChati kõige vähem nõrk kategooria. Lihtsate mallipõhiste tekstide jaoks võib sellest piisata.
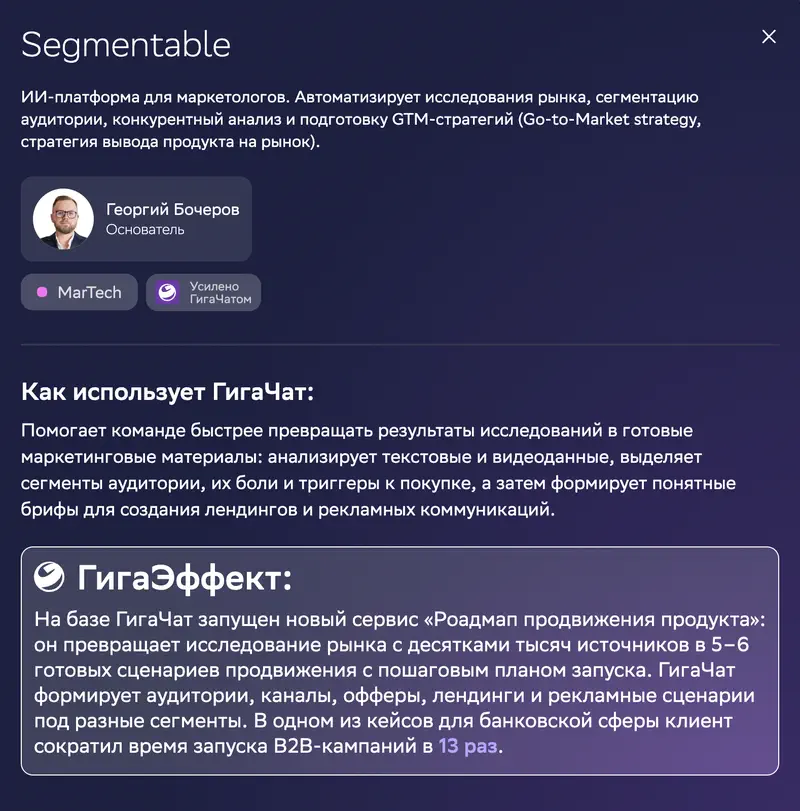
Juhtumikaardil: Segmentable, TI-platvorm turundajatele. Lubatud „GigaEfekt": teenus „toote edenduse teekaart" muudab kümnete tuhandete allikatega turu-uuringu 5–6 valmis käivitusstsenaariumiks ning ühes pangandusjuhtumis lühendas klient B2B-kampaaniate käivitusaega 13 korda.
Huvitavam on olukord küberturbega. Üks juhtumitest – süsteem infoturbe intsidentide klassifitseerimiseks ja ohuraportite genereerimiseks. Ülesanne eeldab täpset analüüsi, konkreetseid järeldusi ja rakendatavaid soovitusi.
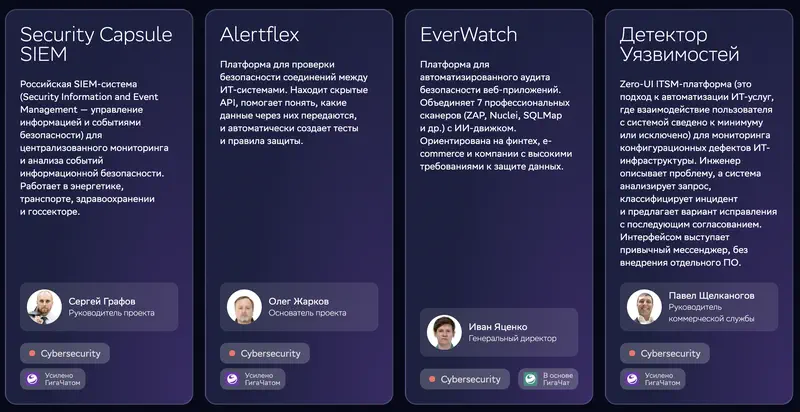
Pildil: neli GigaChatil põhinevat küberturbetoodet. Security Capsule SIEM – Venemaa SIEM-süsteem infoturbe tsentraliseeritud jälgimiseks; Alertflex – kontrollib andmevahetust IT-süsteemide vahel API kaudu ja loob ise kaitsereeglid; EverWatch – veebirakenduste automaatne audit, mis ühendab 7 skannerit (ZAP, Nuclei, SQLMap) TI-mootoriga; Haavatavuste detektor – Zero-UI ITSM-platvorm, kus insener kirjeldab probleemi sõnumirakenduses ning süsteem liigitab intsidendi ja pakub paranduse.
Meie võrdlusuuring kategooriates „analüüs ja otsused" ning „probleemilahendus": 29. ja 28. koht 29-st. Kirjeldus: „määrab õigesti lahenduse üldsuuna, aga ei anna ei kaalukriteeriume, stsenaariumianalüüsi ega konkreetseid soovitusi – sisuliselt jutustab ülesande tingimuse ümber".
Intsidentide klassifitseerimise raport, mille on kirjutanud analüütikas 29. kohal olev mudel 29 saadaolevast – see on dokumendi koostamise automatiseerimine. Ohuanalüüs jääb inimese kanda. Vahe on oluline.
Absoluutse ja konkurentsihinnangu paradoks
Siin on nüanss, mida on oluline mõista, sest see on vastuintuitiivne.
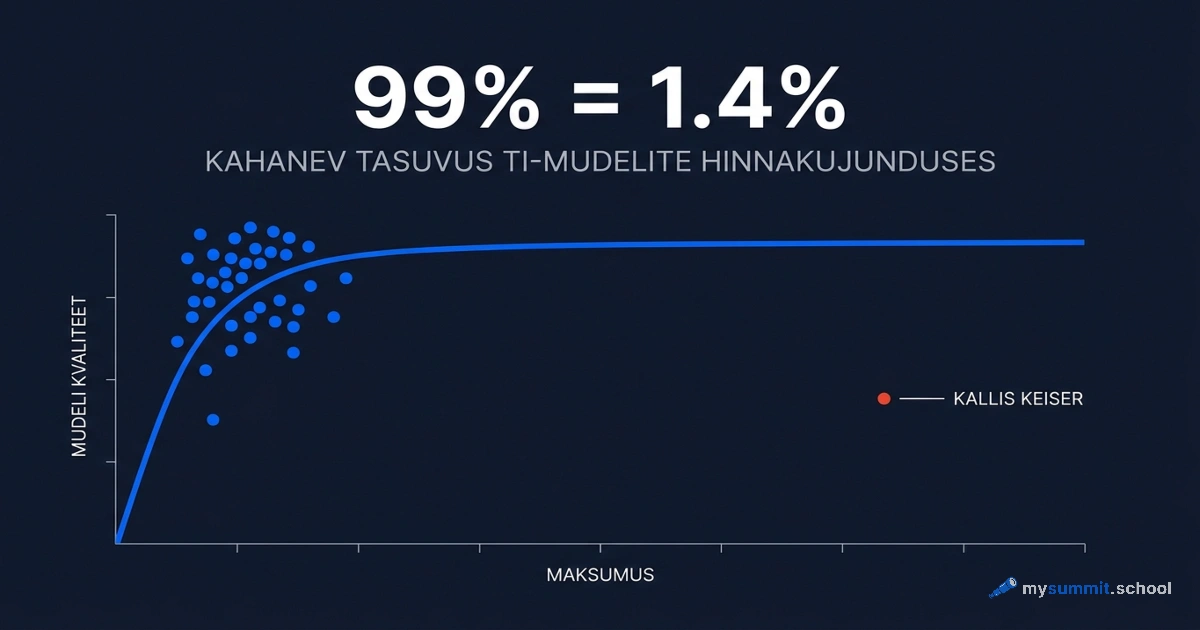
GigaChat 2 Max kogub 4,20 punkti 10-st – alla skaala keskpaiga. Aga isegi absoluutne hinne annab reaalsest konkurentsivõimest halva pildi. Meie eksperiment promptimistehnikatega näitas: isegi parimad promptimistehnikad ei sulge nõrga ja tugeva mudeli vahet. GigaChat ja Alice optimaalsete promptidega kaotasid endiselt GPT-5.4-le ja Claude’ile naiivsete päringutega. Versioon v2 muutus tugevamaks – aga põhimõte jääb: absoluutne hinne ülehindab konkurentsivõimet.
Lahkasime seda efekti põhjalikult artiklis „Miks TI-võrdlusuuringud valetavad". Hinnangud skaalal kogunevad keskmise väärtuse lähedale ja väike punktivahe vastab suurele võitude sageduse erinevusele. Kui Qwen 3.6 Flash kogub meie võrdlusuuringus 7,60 GigaChat 2 Maxi 4,20 vastu – jutt ei ole sellest, et „80% parem". Jutt on sellest, et otseses võrdluses võidab Qwen valdava enamiku kordadest.
Just sellepärast on „töötab" ja „optimaalne" eri asjad.
Teha hindamine päris ülesannetel, mõista, millal tulemus on hea ja millal ainult tundub hea – sellele on pühendatud kursuse avatud moodul. Üheksa juhtimisstsenaariumi, igaühel ootamatu konks, ilma registreerimiseta.
Sberi 40 juhtumis puudub A/B-test alternatiivsete mudelitega. Avatud moodulis on 9 ülesannet, kus hindate tulemusi ise ja õpite eristama töötavat optimaalsest. Tasuta.
Makset ei nõuta • Teavitus käivitumisel
Üks juhtum mikroskoobi all: ESME AI ja projektidokumentatsioon
Võrdlusuuringu abstraktsed punktid ei näita, kuidas mudelite vahe täpselt välja näeb. Üks neljakümnest juhtumist annab võimaluse seda näha – ja samal ajal lahata, kus võrdlusuuringu andmed töötavad otse ja kus neid tuleb lugeda ettevaatlikult.
ESME AI – tööriist arendajatele ja peatöövõtjatele. 360° objektivõtte platvorm, sisseehitatud TI-abiline. GigaChat aitab töötada projekti- ja töödokumentatsiooniga: kasutaja küsib tavakeeles, abiline leiab teabe joonistelt, spetsifikatsioonidest ja eeskirjadest. Väidetav mõju: „projekti teabeotsing lühenes kümnetelt minutitelt mõne minutini, otsuste tegemine kiirenes 30–50%".
Ülesanne on reaalne. Kes on objektil töötanud, tunneb seda valu: keskmine projekt – sajad, vahel tuhanded lehed jagude kaupa (arhitektuur, konstruktsioon, küte-ventilatsioon, vesi-kanal, elekter), pluss spetsifikatsioonid, mahukoosseisud, üldandmed ja normikiht (standardid, eeskirjad). Küsimus „mis betooniklass on projekti järgi 3. korruse vahelaes?" – see on kümme kuni nelikümmend minutit lehitsemist. Lühendus „kümnetelt minutitelt mõne minutini" on usutav – kui otsing tõesti töötab.
Miks võrdlusuuring on siin nõrk proksi
Siin on oluline olla oma andmete suhtes aus. Meie võrdlusuuring mõõdab juhtimisarutlust: olukorda analüüsida, planeerida, järeldus teha. Dokumentatsiooniotsing on üles ehitatud teisiti. See on RAG-klassi ülesanne (retrieval-augmented generation): süsteem tõmbab esmalt projekti päris-PDF-ist vajaliku lõigu välja ja mudel ammutab vastuse sellest – mitte koolituse käigus kogunenud „mälust".
See muudab pilti. GigaChati firmamärgi nõrkus – „mõtleb välja viiteid uuringutele ja juriidilistele normidele" – on genereerimise tõrge koolitatud andmetest. Kui mudel vastab rangelt lisatud joonisefragmendi järgi, surutakse selline tõrge maha. Seetõttu on 29. koht „teabeotsingus" nõrk proksi küsimusele „kas abiline leiab õige betooniklassi". Hästi ehitatud RAG-il käitub isegi nõrk mudel vastuvõetavamalt kui vabas genereerimises.
Mis sellist automaatikat tegelikult lõhub
Probleem on selles, et ehitusdokumentatsiooni puhul ei asu peamised riskid seal, kus võrdlusuuring neid mõõdab – ja osa neist on ohtlikumad kui tavalised hallutsinatsioonid.
Esimene, mis sellise süsteemi praktikas lõhub, on joonise enda lugemine. Joonised on vektor-PDF-id või DWG-failid: tekst on templites, viideteksides, mõõduahelates, viirutuses ja sisseehitatud tabelites. Universaalsed tuvastussüsteemid komistavad sellel ja kui parsimine eksis, vastab mudel enesekindlalt rikutud teksti järgi. Spetsifikatsioonid ja koosseisud on mitmeleheküljelised tabelid ühendatud lahtritega ning enamik „vale väärtuse" vigu sünnib just siin, mitte hallutsinatsioonides.
Edasi – vastus asub harva ühel lehel. „3. korruse vahelae betooniklass" on seos: plaan -> lõige -> spetsifikatsioon -> üldjuhised raudbetooni lehtedel, vahel eraldi leht. Vastuse kokkupanekuks tuleb läbida erinevad dokumendid. Just siin tagastab abiline vaikselt usutava, aga vale väärtuse.
On ka vähem ilmne risk – versioonitus. Dokumentatsioon elab: muudatused, teatised, templid „tööde teostamiseks", punased jooned. Kui indeksisse sattus aegunud revisjon, annab abiline enesekindlalt tühistatud väärtuse – viitega päris-, kuid vanale lehele. See on hallutsinatsioonist ohtlikum: näeb autoriteetne ja kontrollitav välja.
Lõpuks vea hind ja viidatavus. Insener ei saa tegutseda vastuse „B25" järgi ilma viiteta köitele, lehele ja spetsifikatsiooni positsioonile. Viga betoonimargis või armatuuriklassis tähendab konstruktsioonidefekti. Ja kui abiline ei muuda kontrolli kolmesekundiliseks pilguks allikale, aurustub ajavõit ära: vastuse usaldamiseks tuleb algallikas niikuinii käsitsi üles otsida.
Kus võrdlusuuring siiski asjakohane on
ESME ülesandel on kaks kihti. Esimene – fakti ammutamine: see on torujuhtme kvaliteedist, vt eespool. Teine – analüüs ja süntees: „hinda selle sõlme riske", „võrdle kahte lahendusvarianti". Mudeliklasside vahe on siin otse näha ja võrdlusuuring tabab seda.
Meil pole juurdepääsu ESME AI konkreetsetele promptidele, aga sellise ülesande analüütiline kiht on täpselt see, mida testisime promptimistehnikate eksperimendis. Võtame võrreldava stsenaariumi – ärianalüüs konkreetsete andmete põhjal.
Eksperimendi ülesanne:
Elektroonika e-pood, 45 töötajat. Viimase kvartaliga langes käive 18%, samal ajal kasvas saidi külastatavus 12%. Keskmine ostukorv langes 8 700 rublalt 6 200 rublale. Tagastused kasvasid 4%-lt 11%-le. Reklaamieelarvet suurendati 30%. Mis toimub ja mida teha?
Kõik mudelid said sama prompti, ilma ühegi tehnikata.
GigaChat 2 Max (29. koht, hinne 3,02) andis 53 rida teksti. Kuus „võimalikku põhjust", kuus soovitusplokki: „viia läbi toote kvaliteedianalüüs", „parandada logistikat ja tarnet", „tõsta töötajate kvalifikatsiooni". Ülesande tingimusest konkreetseid numbreid analüüsis ei ole. Prioriseerimist ei ole. Kokkuvõte: „probleemi lahendamisele tuleb läheneda kompleksselt".
ESME AI jaoks tähendab see: analüütilisel kihil ütleb mudel „spetsifikatsiooni tuleb kontrollida", aga vaevalt seab prioriteete ja teeb leitust sisukat järeldust.
Alice AI LLM (YandexGPT, hinne 3,85) sai märksa paremini hakkama: tekkis struktuur – „sortimendi ABC-analüüs", „hinnaparserid", „lehtri kasutatavustest", plokk „lühiajalised prioriteedid 2 nädalaks". Aga prioriseerimine on lame, kriisivastane ajakava lahti kirjutamata.
GPT-5.4 (1. koht, hinne 4,38) alustas teisiti – arvutusega: „keskmine ostukorv langes umbes 29%". Mudel arvutas, mitte ei jutustanud tingimust ümber. Edasi: kriisivastane plaan 10 päevaks rollidega igale 45 inimesele, järjestatud hüpoteesid ja tegevuste nimekiri „homseks hommikuks".
Kolm taset – kolm tulemuseklassi:
| Mudel | Arvutab tingimuse numbrid? | Prioriseerib hüpoteese? | Annab tegevuskava? | Faktitäpsus |
|---|---|---|---|---|
| GigaChat 2 Max | Ei | Ei | Üldised nõuanded | 58,9% |
| Alice AI LLM | Osaliselt | Ei | Prioriteedid, aga ajakavata | 75,0% |
| GPT-5.4 | Jah (29% ostukorvilangus) | Jah (tõenäosuse järgi) | 10-päevane plaan rollidega | 83,9% |
Tabeli faktitäpsus pärineb ärianalüüsi eksperimendist, kus mudel genereerib vastuse ise, ilma lisatud dokumentideta. See ei tähenda, et ESME abiline eksib 41% joonistepäringutest: grounded-otsingul viidetega on pilt teine. Aga number näitab klassi. Seal, kus „dokumentatsioonianalüüs" ei tähenda lihtsalt rea leidmist, vaid arvutamist, prioriseerimist ja järelduse kokkupanekut, jääb GigaChat 2 Max üldiste nõuannete tasemele.
Eksperimendi otseses võrdluses võitis GigaChat 2 Max parima promptimistehnikaga GPT-5.4-le ainult 4% juhtudest. Alice AI LLM – 28–36%. 4% võitude juures pole vahe enam nüanssides, vaid ülesandeklassis, mida mudel suudab lahendada.
Mudelit tasub siin vahetada: mõlemad alternatiivid – Alice AI LLM ja DeepSeek V4 Flash – on kättesaadavad Yandex Cloudis. DeepSeek V4 Flash on meie võrdlusuuringus 12. kohal (7,34 punkti) ja maksab 0,20 / 0,60 dollarit miljoni tokeni kohta – 12 korda odavam kui GigaChat ja oluliselt kõrgema kvaliteediga. Aga ausalt: mudeli vahetamine parandab analüütilist kihti ja vähendab hallutsinatsioone, peamised ehitusriskid aga – joonise parsimine, versioonitus, viidatavus – elavad torujuhtmes ja neid ei sulge ükski mudel.
Kuidas teha sellist abilist usaldusväärseks
Kui ehitada sellist toodet tõsiselt, on prioriteetide järjekord umbes selline.
Suurim usaldusväärsuse võit – struktureerida andmed PDF-otsingu asemel. Parsida spetsifikatsioonid ja koosseisud üks kord inimese kontrollitud andmebaasi (element -> materjal -> klass -> leht -> revisjon). Siis muutub „3. korruse vahelae betooniklass" täppispäringuks andmetele, mitte häguseks tekstiotsinguks.
Iga vastus peab sisaldama viidet: köide, leht, positsioon – ja näidatud joonisefragment. Kontroll muutub pilguks ja ainult siis on ajavõit reaalne.
Otsing ja genereerimine tasub lahutada. Fragmentide ammutamine – embeddingute ja reranker’i abil, mudel – ainult vastuse lõplikul ammutamisel range juhisega „vasta rangelt konteksti järgi, muidu ütle „ei leitud"". Just see muudab tugevama mudeli valiku mõttekaks.
Vaja on versioonikihti: abiline vastab „revisjoni nr X järgi" ja hoiatab, kui lehel on värskem versioon.
Kriitiliste päringute jaoks – betooniklass, armatuur, tulekindluspiir – peab abilisel olema õigus öelda „ei tea": kas täpne viide või keeldumine. „Ei leitud" on funktsioon, mitte viga.
ESME ainulaadne vara – 360°-võtte sidumine dokumentatsiooniga. Samm „dokumentides otsimiselt" sammule „võrdle fakti (360°-võtet) projektiga": kõrvalekalded, valmidusprotsent, defektid. Just see samm katab ehitusjärelevalve reaalse ülesande ja läheb otsingu kiirendamisest kaugemale.
Ja lõpuks – kontrollida oma dokumentidel. Sada päris-päringut kontrollitud vastustega ja kolme mõõdiku mõõtmine: otsingu täielikkus, viidete täpsus, aegunud revisjonide osakaal. Universaalne võrdlusuuring ei ütle ESME-le, kas nende torujuhe on turvaline – seda näitab ainult selline test.
Kui valikut pole: kuidas GigaChati tulemust parandada
Oletame, et töötate organisatsioonis, kus GigaChat on ainus lubatud tööriist. On-premise, ärileping, infoturbenõuded. Mida saab teha?
Meie promptimistehnikate eksperiment kontrollis kümmet lähenemist GigaChat 2 Maxil – rollifreimingust XML-märgenduse ja arutlusahelani.
Parima tulemuse näitas tehnika nr 4 – few-shot: 89% võite naiivse prompti üle. Te võtate näite kvaliteetsest vastusest sarnasele (aga teisele) ülesandele ja lisate selle prompti enne oma küsimust. Mudel kalibreerub näidise järgi – ja annab struktureeritud, konkreetse vastuse üldiste fraaside asemel.
Samal e-poe ülesandel andis GigaChat 2 Max few-shot-näitega teise tulemuse: kuue üldise kategooria loetelu asemel – struktureeritud diagnoos viidetega tingimuse konkreetsetele numbritele („keskmise ostukorvi langus 8 700-lt 6 200 rublale"), soovituste ajakava (see nädal / 2–3 nädalat / kuu jooksul) ja sektsioon „Mida me veel ei tea".
GigaChat 2 Maxi andmed eksperimendist:
| Tehnika | Hinne (5-st) | Tõus baasist | Võite vs naiivne prompt |
|---|---|---|---|
| T0 (tehnikateta) | 3,02 | – | – |
| T4 (few-shot) | 3,63 | +20% | 89% |
| T2 (struktureeritud väljund) | 3,43 | +14% | 82% |
| T10 (XML + Markdown) | 3,59 | +19% | 78% |
| T3 (arutlusahel) | 3,55 | +18% | 79% |
Aga siin on oluline reservatsioon: GigaChat 2 Max parima tehnikaga (3,63) on endiselt madalam kui Qwen 3.6 Flash (7,60) või DeepSeek V4 Pro (7,75) ilma ühegi tehnikata. Promptimine ei sulge arhitektuurilist vahet – see teeb nõrga mudeli talutavaks, mitte konkurentsivõimeliseks.
Jääb näidise allika küsimus. Kõige praktilisem tee: ajada ülesanne üks kord läbi tugeva mudeli (DeepSeek V4 Flash on veebiliideses tasuta, Kimi K2.6 saadaval ilma VPN-ita), salvestada tulemus ja kasutada näidisena GigaChati jaoks sarnastel ülesannetel. See ei ole „spikerdamine" – see on kalibreerimine.
Alternatiivid: mida valida GigaChati asemel
See on ehk materjali kõige konkreetsem osa. Kui Sberi juhtumi ettevõte lahendab ülesandeid meie nimekirjast, mis mudelid on talle veel kättesaadavad – ja mida ütleb võrdlusuuring? Tööriistade põhjalik võrdlus ülesannete kaupa – GenAI-tööriistade ülevaates juhile.
Kõik allpool loetletud mudelid on saadaval API kaudu.
| Mudel | Koht (29-st) | Hinne | Hind (sisend/väljund, $/M tokenit) |
|---|---|---|---|
| MiMo v2.5 Pro | 3 | 8,37 | $1 / $3 |
| Kimi K2.6 | 5 | 8,27 | $0,74 / $3,49 |
| Qwen 3.6 Plus | 7 | 7,94 | $0,33 / $1,95 |
| MiMo v2.5 | 8 | 7,82 | $0,40 / $2 |
| DeepSeek V4 Pro | 10 | 7,75 | $0,43 / $0,87 |
| Qwen 3.6 Flash | 14 | 7,60 | $0,25 / $1,50 |
| MiniMax M2.7 | 15 | 7,58 | $0,30 / $1,20 |
| GigaChat 2 Max | 29 | 4,20 | $7,22 / $7,22 |
Hinnavahe on oluline punkt ja lahkasime seda TI-mudelite „lisatasu-maksu" analüüsis. GigaChat 2 Max maksab 7,22 dollarit miljoni tokeni kohta nii sisendis kui väljundis. Qwen 3.6 Flash – 0,25 dollarit sisendis ja 1,50 dollarit väljundis. Kui ettevõttel on tipukoormus 10 miljonit tokenit sisendis ja sama palju väljundis: GigaChat läheb maksma umbes 144 dollarit, Qwen 3.6 Flash – umbes 17,50 dollarit. Seejuures on Qwen 14. kohal 29. vastu.
Odavus iseenesest pole argument. GigaChatil on reaalne eelis – on-premise juurutus. Pankadele, riigiasutustele, kaitsetööstusele, kus andmed ei tohi turvakontuurist lahkuda – see on ainus valik. Sellest kirjutasime GigaChati praktilises juhendis. Aga juhtumite idufirmadele, kes töötavad pilves – eelis pole asjakohane.
Viis küsimust igale TI-müüjale
See pole ainult Sberist. Microsoft avaldab Copiloti juhtumeid, Anthropic – Claude’i, Google – Gemini juhtumeid. Vorming on sama. Küsimused peavad samuti olema samad.
Alustage kõige lihtsamast: milline ülesanne täpselt on automatiseeritud – ja kas see kuulub mudeli tugevatesse külgedesse? Lihtsate küsimuste vestlusrobot töötab igal mudelil. Meditsiinidokumentide või juriidiliste riskide analüüs – juba mitte.
Teine küsimus – mõõdikute kohta. „Vähendasime aega 40%" kõlab hästi. Aga 40% millest? Kui operaator kulutas vastusele 20 minutit ja nüüd kulutab 12 – sääst on reaalne. Kui mudel annab mustandi 30 sekundiga, aga toimetaja kulutab parandustele 15 minutit – tõhusus on teistsugune. Ja mis oleks olnud üldse ilma TI-ta?
Kas test alternatiivsete mudelitega tehti? Peaaegu kunagi mitte. See on arusaadav: ettevõte lahendab äriülesannet, mitte ei tegele võrdleva testimisega. Aga A/B-testi puudumine tähendab, et sõnu „GigaChat võimaldas meil" on õigem lugeda kui „GigaChatiga me suutsime" – ilma väiteta, et teised mudelid oleksid andnud halvema tulemuse.
Eraldi teema – ülekontroll. Kui ülesanne nõuab täpseid andmeid (faktiviiteid, juriidilisi viiteid, meditsiinilisi järeldusi) ja iga järelduse süstemaatilist kontrolli pole – see on risk. Küsimus pole selles, kas mudel vahel hallutsineerib. Küsimus on selles, kui palju vigu läbi pääseb ja milline on nende hind.
Ja lõpuks: mis juhtub piirjuhtumitel? Enamik TI-tooteid töötab tüüpilistel päringutel hästi. Huvitav on käitumine ebatüüpilistel – haruldane piirkond, ebastandardne olukord, seaduse piiripealne juhtum. Just siin avaldub 3. ja 29. koha vahe kõige tugevamini.
Vajutage „Käivita" ja võrrelge vastuseid. Pange tähele konkreetsust: kas mudel nimetab reaalseid infoturbe standardeid ja mõõdikuid, või piirdub üldiste fraasidega? Just siin avaldub vahe 5. ja 29. koha vahel võrdlusuuringus.
Aus tunnistus: edasiminek on reaalne
GigaChat 2 Max on viimasel kohal – aga seda on oluline mõista dünaamikas. Esimeses testlaines oli sama liini hinne 3,08. Praegu – 4,20. Kasv 36% paari kuuga – see on kvaliteedis märkimisväärne edasiminek, isegi kui koht edetabelis jääb viimaseks.
Sberi inseneritöö on märgatav. Kui tempo säilib – aasta-paari pärast võib GigaChat sattuda tabeli ülemisse poolde. See on lahtine küsimus ja kasutajate huvides on, et vastus oleks positiivne.
Nelikümmend juhtumite idufirmat teevad samuti reaalset tööd. GigaChatil põhinev automaatika töötab paljudel neist. Osa ülesannete jaoks – eriti ärikirjavahetuse ja lihtsate vestlusrobotitega seotud – on valik mõistlik. Teiste ülesannete jaoks tõstatab võrdlusuuringu andmestik optimaalsuse küsimuse.
Võimalik, et osa neist valis GigaChati mittetehnilistel põhjustel: Sberiga on juba ärileping, infoturbenõuded, juhtkonna surve. Need on samuti reaalsed kaalutlused, mida võrdlusuuring ei arvesta.
Küsimus on muus: tehnilise otsuse tegemisel mudeli valikust – mida te kontrollite?
Eristada „mudel andis usutava tulemuse" ja „mudel andis õige tulemuse" on oskus, mis areneb ainult konkreetsetel ülesannetel. Just seda harjutatakse kursuse avatud moodulis: üheksa juhtimisstsenaariumi, kus vahe „kõlab veenvalt" ja „õige" vahel pole ilmne.
Nelikümmend juhtumit ilma A/B-testita on müüjaturunduse norm. Avatud moodulis harjutate tulemuse hindamise oskust 9 juhtimisülesandel. Tasuta, ilma registreerimiseta.
Makset ei nõuta • Teavitus käivitumisel
Mida selle teabega peale hakata
Kui te kasutate GigaChati – eriti on-premise või Enterprise vormingus – pole see argument kohe ümber lülitada. On ülesandeid, kus mudel töötab vastuvõetavalt. On olukordi, kus valikut pole.
Kasulik tegevus – mõista, millistes ülesannetes te GigaChati täpsusele toetute ja milline ülekontrolli tase teil sisse ehitatud on. Meie GigaChati üksikasjalik ülevaade ja GigaChat Ultra Thinkingu test näitavad konkreetseid olukordi, kus mudel eksib kõige sagedamini: teabeotsing, juriidilised normid, piirkondlikud andmed.
Kui te teete otsust mudeli valikust uue projekti jaoks – võrdlusuuringu andmed ja viis ülaltoodud küsimust annavad struktuuri. 29 mudeli täielik edetabel kategooriate kaupa – meie uuringu lehel.
Kui loete järgmist müüjajuhtumit – ükskõik kas Sberilt, Microsoftilt või Anthropicult – esitage samad viis küsimust. Nende vastuseid ei ole tavaliselt juhtumi tekstis.
Juhtumitelt iseseisva hindamiseni
Kursuse kolmas peatükk lahkab kaheksat TI-tööriista andmetega: mida igaüks oskab, kus hallutsineerib, milliste ülesannete jaoks on optimaalne. Juhtimisülesannete testimise tulemused, mitte turunduse ümberjutustus.



Stanislav Belyaev
Engineering Leader Microsoftis18 aastat insenerimeeskondade juhtimist. mysummit.school asutaja. 700+ lopetajat Yandex Practicumis ja Stratoplanis.