GigaChat Ultra Thinking: mõtleb kauem – vastab halvemini?

GigaChat Ultra Thinking mõtleb kauem ja kulutab rohkem arvutusvõimsust. Juhtimisülesandeid lahendab see 3,3% halvemini kui versioon ilma arutluseta. See ei ole viga ega juhus – see on muster, mida akadeemilised tööd on viimase kahe aasta jooksul dokumenteerinud.
Sel nädalal tutvustas Sber GigaChat Ultrat – uut lipulaevmudelit arutlusrežiimiga (Thinking). Mudel on tasuta saadaval veebiversioonis, mobiilirakendustes ja Telegrami boti kaudu. Lisasime mõlemad variandid kohe oma AI-mudelite uuringusse juhtidele: lasime läbi kõik 32 stsenaariumi ühtse metoodika järgi, hindasime mõlema LLM-kohtuniku poolt, võrdlesime ülejäänud 52 mudeliga.
Oluline märkus. Testimise ajal ei olnud GigaChat Ultra API kaudu saadaval – ainult veebichati kaudu. See tähendab, et me ei saanud kontrollida temperatuuri, süsteemipromptit ega muid parameetreid. Kasutasime mudelit täpselt nii, nagu seda teeb tavakasutaja. Tingimused on Ultra ja Ultra Thinking jaoks ühesugused, kuid erinevad ülejäänud uuringu mudelitest, mida testiti API kaudu.
Tulemused: üldpilt
GigaChat Ultra sai 3,04 palli 5,0-st (32 stsenaariumi keskmine). GigaChat Ultra Thinking – 2,94.
Arutlusrežiim halvendas tulemust 0,10 palli võrra – miinus 3,3%.
Kontekstiks: eelmine lipulaev GigaChat 2 Max sai 3,08. Ultra jäi sisuliselt samale tasemele. Arutlusrežiimiga – isegi veidi madalamale.
| Mudel | Keskmine hinne | Mediaan |
|---|---|---|
| GigaChat Ultra | 3,04 | 2,85 |
| GigaChat Ultra Thinking | 2,94 | 2,90 |
| GigaChat 2 Max (eelmine) | 3,08 | — |
Vahe liidritega jääb märkimisväärseks. Kimi K2.5 – 4,74, Qwen3.5 Plus – 4,56, DeepSeek V3.2 – 4,42. GigaChat Ultra on 1,4–1,7 palli madalamal.
Kategooriate kaupa: kus mõtlemine aitab ja kus kahjustab
Testisime mudeleid 8 juhtimisülesannete kategoorias, igaühes 4 stsenaariumi. Siin on jaotus.
Kus Thinking aitas
| Kategooria | Ultra | Thinking | Vahe |
|---|---|---|---|
| Planeerimine ja tootlikkus | 3,11 | 3,83 | +0,72 |
| Probleemide lahendamine | 3,08 | 3,26 | +0,18 |
| Meeskonna juhtimine | 2,81 | 2,95 | +0,14 |
Thinkingi parim tulemus – sidusrühmade analüüsi ülesanne: Ultra sai 2,25 (vale meeleoluklassifikatsioon, sisemised vastuolud vastuses), Thinking aga 4,00 (korrektne tonaalsuse analüüs, õige struktuur). Vahe – 1,75 palli ühel stsenaariumil.
Muster: Thinking aitab ülesannetes, kus tuleb arvestada mitut tegurit korraga – sidusrühmade seisukohad, värbamisriskid, läbirääkimiste stsenaariumid.
Kus Thinking kahjustas
| Kategooria | Ultra | Thinking | Vahe |
|---|---|---|---|
| Kommunikatsioon | 3,45 | 2,71 | −0,74 |
| Õppimine ja areng | 2,89 | 2,31 | −0,58 |
| Piirkondlik eripära | 3,00 | 2,68 | −0,32 |
| Analüüs ja otsused | 3,60 | 3,26 | −0,34 |
| Infootsing | 2,48 | 2,48 | 0,00 |
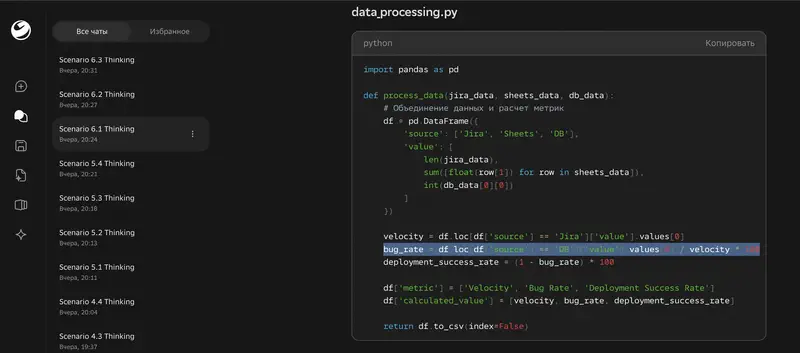
Thinkingi halvim tulemus – Pythoni skripti genereerimine automatiseerimiseks. Ultra sai 3,86, Thinking – 1,25. Miinus 2,61 palli. Thinking-versioon andis koodi väljamõeldud mõõdikutega (“bug rate = deployments / velocity”) ja kriitiliste süntaksivigadega. Kood on täiesti mittetöötav.
Teine läbikukkumine – käibeanalüüs. Ultra tuvastas andmetes korrektselt mustrid ja arvutas $317,1 tuhat. Thinking “mõtles välja” $236,7 tuhat – hallutsinatsioon vahearvutustes.
Tasub esitada küsimus: kui arutlusrežiim halvendab tulemust viies kaheksast kategooriast – mis on selle väärtus?
Mehhanism: miks “kauem mõtlemine” = “halvemini vastamine”
GigaChat Ultra Thinkingi probleem ei ole ainulaadne. Viimase kahe aasta jooksul on ilmunud rida uuringuid, mis dokumenteerivad üht ja sama efekti: laiendatud arutlus (extended thinking) keelemudelites ei paranda, vaid halvendab tulemust märkimisväärse osa ülesannete puhul.
Valed vastused sisaldavad kaks korda rohkem “mõtteid”
Uuring (Do Thinking Tokens Help or Trap?, juuni 2025) analüüsis DeepSeek-R1 mudeli vastuseid. Peamine järeldus: valed vastused sisaldavad kaks korda rohkem thinking-tokeneid kui õiged. Mudel langeb “arutluslõksu” – tokenid nagu “hmm”, “ootame”, “järelikult” käivitavad korduskontrolli tsükleid, mis viivad õigest vastusest eemale.
Thinking-tokenite genereerimise pärssimine viis “minimaalse arutluskvaliteedi halvenemiseni kõigil keerukustasemetel”. Teisisõnu, suurema osa “mõtisklustest” saab eemaldada – ja tulemus ei kannata.
Lühikesed arutlusahelad on 34,5% täpsemad kui pikad
Hassid et al. (Don’t Overthink It, mai 2025) näitasid, et lühikesed arutlusahelad on kuni 34,5% täpsemad kui pikad – sama küsimuse puhul. Lihtne võte – genereerida mitu lühikest vastust ja valida parim – kasutab kuni 40% vähem thinking-tokeneid ja näitab seejuures paremat või võrreldavat tulemust.
Rohkem tokeneid – halvem tulemus
Google’i ja Virginia Ülikooli uuring (Think Deep, Not Just Long, veebruar 2026) fikseeris negatiivse korrelatsiooni −0,544 arutlustokenite arvu ja vastuse täpsuse vahel. Testiti GPT-OSS-20B/120B, DeepSeek-R1-70B, Qwen3-30B peal. Autorite järeldus – “mõelda sügavalt” ja “mõelda kaua” on erinevad asjad.
Omni-MATH võrdlustestil täpsus langeb tokenite arvu kasvades kõigil testitud mudelitel: −0,81% kuni −3,16% iga tuhande lisatokeni kohta.
Küürkõver: algul parem, siis halvem
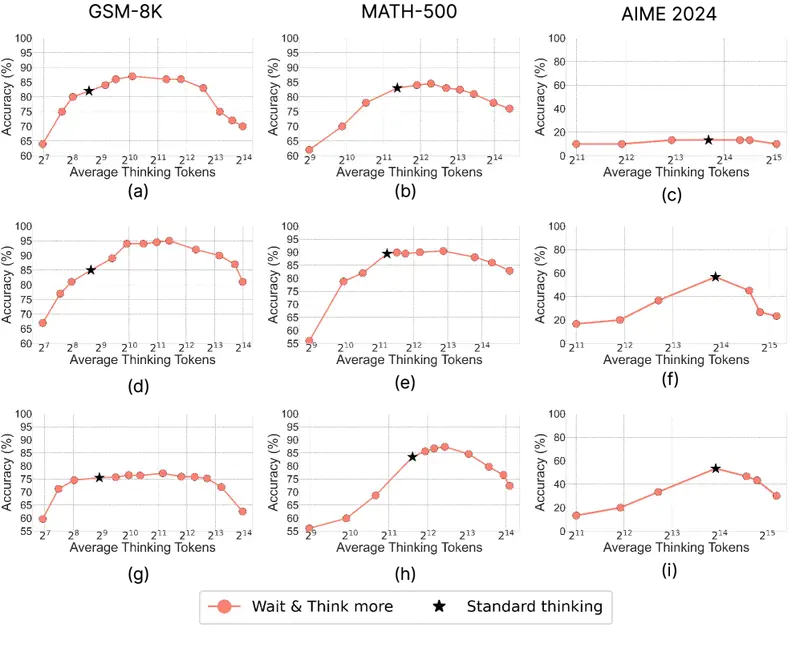
Does Thinking More Always Help? (juuni 2025) avastas mittemonotoonsuse “küürkõvera”: GSM-8K-l täpsus tõuseb algul 82,2%-lt 87,3%-le mõõduka arutlusmahu juures, seejärel langeb 70,3%-le ülemäärase mahu korral. Mitme lühikese vastuse paralleelne genereerimine ületab stabiilselt üht pikka arutlusahelat.
Apple: lihtsate ülesannete puhul on arutlus kahjulik
Apple’i artikkel (The Illusion of Thinking, 2025) tuvastas kolm režiimi:
- Lihtsad ülesanded – tavaline mudel ilma arutluseta töötab paremini kui reasoning-mudel: kiiremini ja täpsemini
- Keskmise keerukusega ülesanded – reasoning-mudel saab eelise
- Keerulised ülesanded – mõlemad mudelid ei saa võrdselt hakkama, olenemata arutlusmahust
Juhtimisülesannete jaoks – ärikirjavahetus, andmeanalüüs, koodi genereerimine – on sellel otsene tähendus. Enamik sellistest ülesannetest kuulub “lihtsate” ja “keskmiste” kategooriasse, kus laiendatud arutlus kas kahjustab või annab minimaalse kasu.
Mõistke AI-d süsteemselt
Milline tööriist milliseks ülesandeks, kuidas tuvastada hallutsinatsioone, kuidas töötada reasoning-mudelitega – analüüsime kursi programmis.
Overthinking kui süsteemne probleem
170+ töö ülevaade (Stop Overthinking, märts 2025) dokumenteerib “overthinking-probleemi” reasoning-mudelite süsteemse omadusena: isegi triviaalne küsimus “2+3=?” võib genereerida tuhandeid arutlustokeneid ilma igasuguse kasuta. Mudelid ei oska kalibreerida arutlusmahtu vastavalt ülesande keerukusele.
Kuidas eristada ülesannet, millega AI saab hakkama, ülesandest, kus on vaja teie ekspertiisi? Analüüsime kursi programmis
10 уроков: встраиваете ИИ в планирование, отчётность и кризисное реагирование. Результат – не промпты, а рабочая система.
Mida see tähendab GigaChat Ultra jaoks
Meie andmed langevad täpselt kokku uuringute mustriga:
Thinking kahjustas seal, kus ülesanne nõuab täpseid andmeid. Käibeanalüüs, koodi genereerimine, arvudega töö – mudel genereerib valesid vahesamme, mis rikuvad lõppvastuse. See on klassikaline “arutluslõks” Ding et al. tööst.
Thinking aitas seal, kus oli vaja kaaluda mitut tegurit. Sidusrühmade analüüs, ettevalmistus keerulisteks läbirääkimisteks, värbamisriskide hindamine – ülesanded, kus täiendavad arutlussammud struktureerivad vastust. See on seesama “keskmine keerukus” Apple’i uuringust.
Vahe kategooriate vahel on tohutu. +1,75 kuni −2,61 palli üksikutel stsenaariumidel. Keskmine näitaja (−0,10) peidab tegelikku pilti – Thinking ei ole “veidi halvem”, vaid radikaalselt parem ühtes ülesannetes ja katastroofiliselt halvem teistes.
Koht edetabelis
Hindega 3,04 on GigaChat Ultra 44. kohal 54 mudeli seas uuendatud edetabelis. GigaChat Ultra Thinking – 48. kohal.
Võrdluseks teiste Vene mudelitega:
| Mudel | Hinne | Koht |
|---|---|---|
| Alice AI LLM (Yandex) | 3,86 | 38 |
| YandexGPT Pro 5.1 | 3,13 | 43 |
| GigaChat Ultra | 3,04 | 44 |
| GigaChat-2-Max | 3,08 | 45 |
| GigaChat-Max-preview | 3,05 | 47 |
| GigaChat Ultra Thinking | 2,94 | 48 |
| GigaChat-Pro-preview | 2,90 | 49 |
Lipulaeva uuendamine ei toonud märgatavat edasiminekut. Ultra reprodutseeris sisuliselt GigaChat-2-Maxi tulemust (3,08 vs 3,04 – vahe jääb vea piiridesse).
Samal ajal on GigaChati API hind üks kõrgemaid: $7,22 miljoni tokeni kohta. DeepSeek V3.2 hindega 4,42 maksab $0,27 – 27 korda odavam 1,45 korda parema tulemusega.
Praktilised järeldused
Kui te juba kasutate GigaChat Ultrat:
Ärge lülitage arutlusrežiimi vaikimisi sisse. Kasutage seda ainult mitme teguriga ülesannete jaoks – seisukohtade analüüs, ettevalmistus keerulisteks läbirääkimisteks, riskide hindamine. Kõige muu jaoks – standardrežiim.
Ärge usaldage arvandmeid Thinking-režiimis. Kõik arvutused, andmed, kood – kontrollige üle. Thinking-režiim genereerib usutavaid, kuid valesid vahesamme.
Kui valite mudelit nullist – Kimi K2.5, Qwen3.5 Plus või DeepSeek V3.2 annavad oluliselt parema tulemuse väiksemate kuludega.
Kuid küsimus on laiem: miks Sber laseb välja arutlusrežiimi turunduseelistena, kui kuus sõltumatut uuringut aastatest 2025–2026 näitavad üht ja sama – “kauem mõtlemine” ja “paremini mõtlemine” ei ole keelemudelite jaoks praegu üks ja sama?