Kuidas hinnatakse LLM-ide kvaliteeti 2026. aastal: juhend AI-mudelite võrdlusuuringutele juhtidele

Kujutage ette, et valite meeskonnale ametisõidukit. Üks esindusmüüja ütleb: „Meie auto on kõige kiirem." Teine: „Meil on parim kütusekulu." Kolmas: „Me oleme turvalisuse poolest liidrid." Kõigil on õigus – kuid igaüks mõõdab midagi erinevat. Ilma täpselt mõõdetu ja mõõtmisviisi mõistmiseta ei suuda te pakkumisi objektiivselt võrrelda.
Keelemudelite puhul 2026. aasta alguses on olukord veelgi keerulisem. GPT-5.3, Claude 4.6, Gemini 3, Perplexity, DeepSeek V4 – iga ettevõte väidab end olevat liider. Kuid kuidas saab juht aru, milles täpselt üks tööriist äriülesande jaoks teisest parem on?
Just siin tulevad mängu võrdlusuuringud (benchmark-testid) – standardiseeritud testid. 2026. aastaks on vanemad testid (nagu MMLU) muutunud vähem kasulikuks, kuna kõik tippmudel on õppinud need peaaegu täiuslikult läbima. Vaatame, milliseid näitajaid tasub tänapäeval tegelikult jälgida.
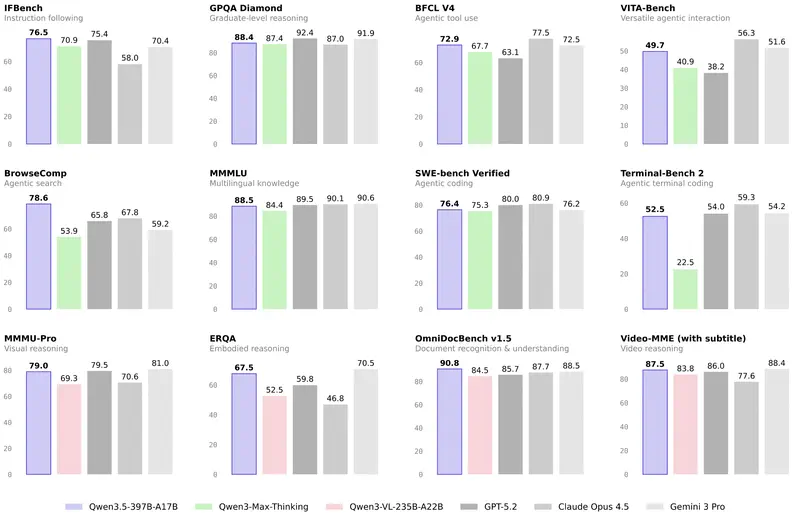
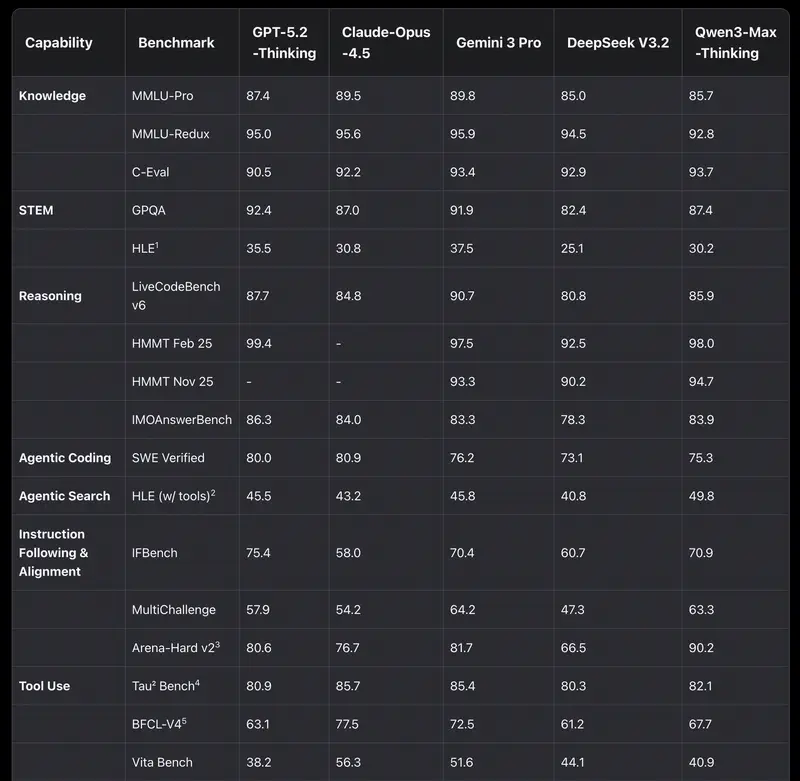
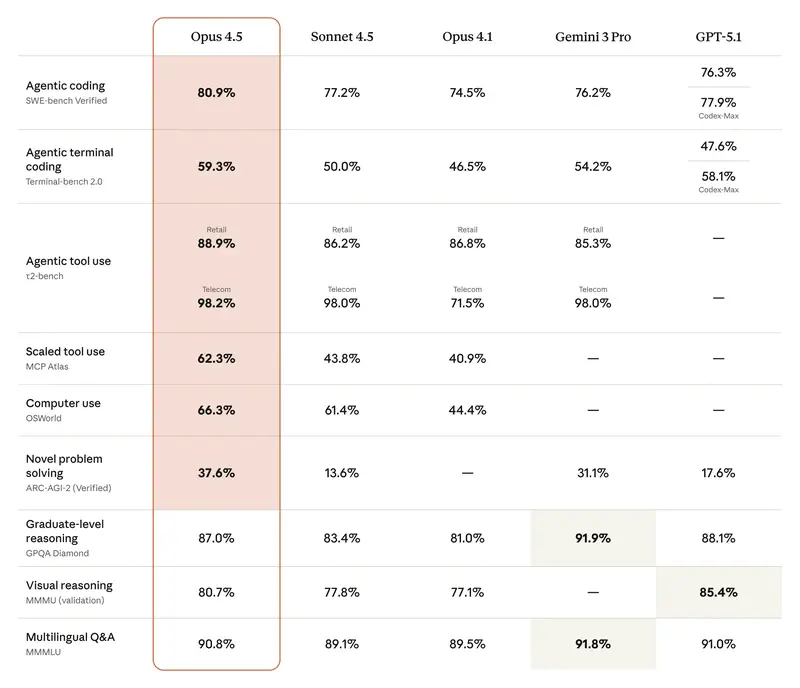
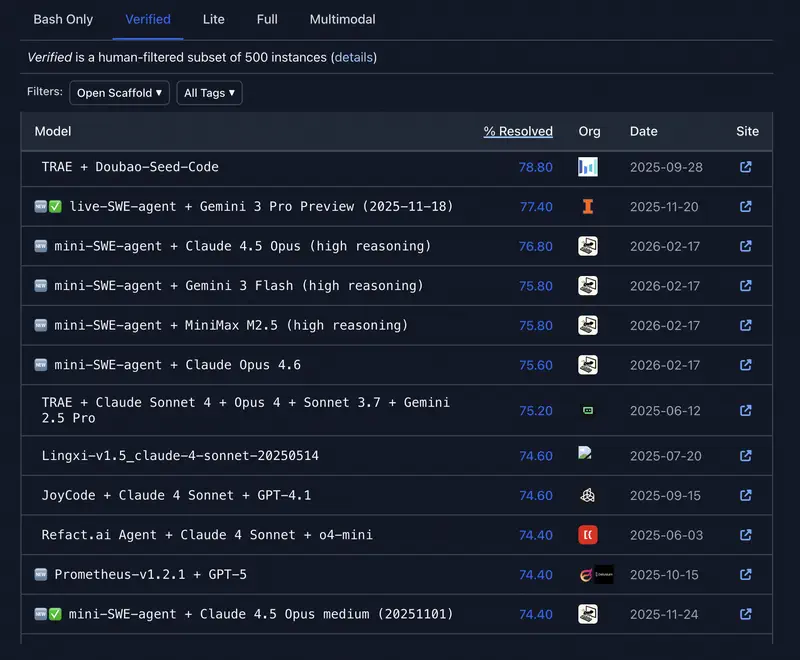
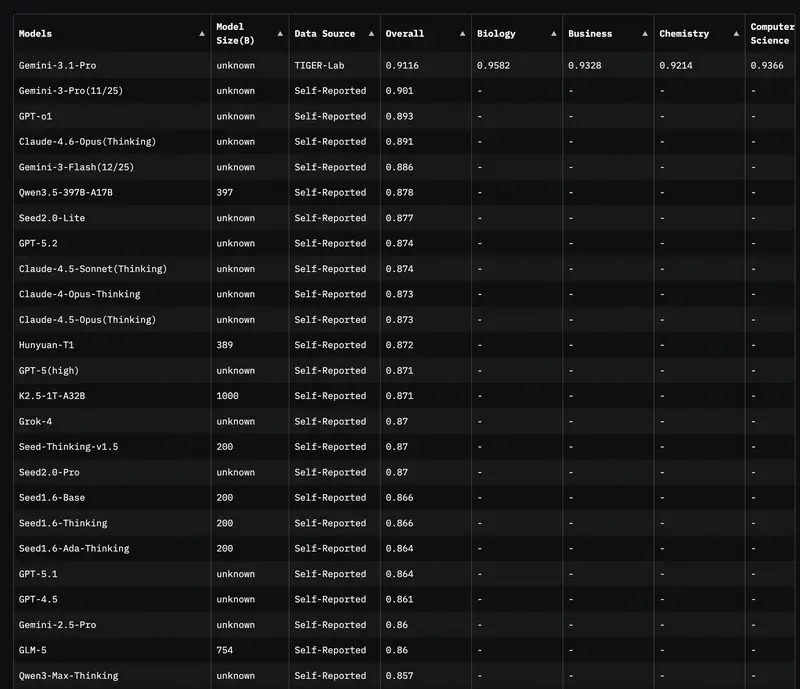
Intuitsioon versus andmed. Juhtidel on sageli „lemmik" mudel. Kuid intuitsioon pettab piirjuhtumite puhul. Kui peate põhjendama eelarvet või valima mudeli terve osakonna automatiseerimiseks – vajate objektiivseid kriteeriume.
Peamised hindamistüübid 2026. aastal
Kaasaegne LLM-i hindamine ei ole üks number – see on arusaamine, millises „liigas" mudel mängib.
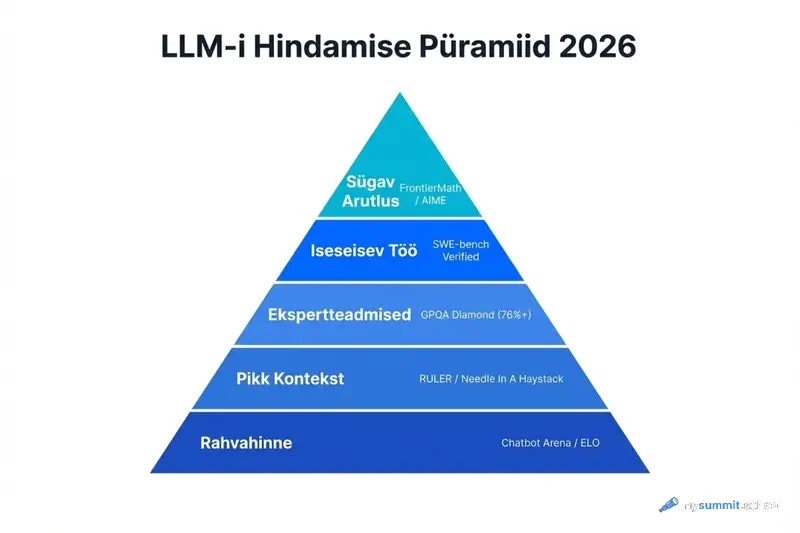
Praeguste kategooriate koondtabel
| Kategooria | Põhiline võrdlusuuring | Mida see juhile tähendab |
|---|---|---|
| Ekspertteadmised | GPQA Diamond | Kui kompetentne on mudel doktoritaseme küsimustes. Oluline auditi ja strateegia jaoks. |
| Iseseisev töö | SWE-bench Verified | Mudeli võime iseseisvalt lahendada ülesandeid koodis ja repositooriumides. „Agentsuse" näitaja. |
| Pikk kontekst | RULER / Needle In A Haystack | Kas mudel kaotab informatsiooni 1000+ leheküljega dokumendis? |
| Sügav arutlus | FrontierMath / AIME | Võime mitmeetapiliseks arutlemiseks ilma loogiliste vigadeta. |
| Rahvahinne | Chatbot Arena (LMSYS) | Kuidas hindavad mudelit päris inimesed anonüümses pimedas testis. |
1. Akadeemiline laius (MMLU ja GPQA Diamond)
Varem vaatasid kõik MMLU (testid 57 distsipliinis). Kuid 2026. aastaks on see test muutunud „põhiliseks hügieenimiinimumiks". Kui mudel saab alla 85–90%, ei kuulu see lihtsalt tipptasemele.
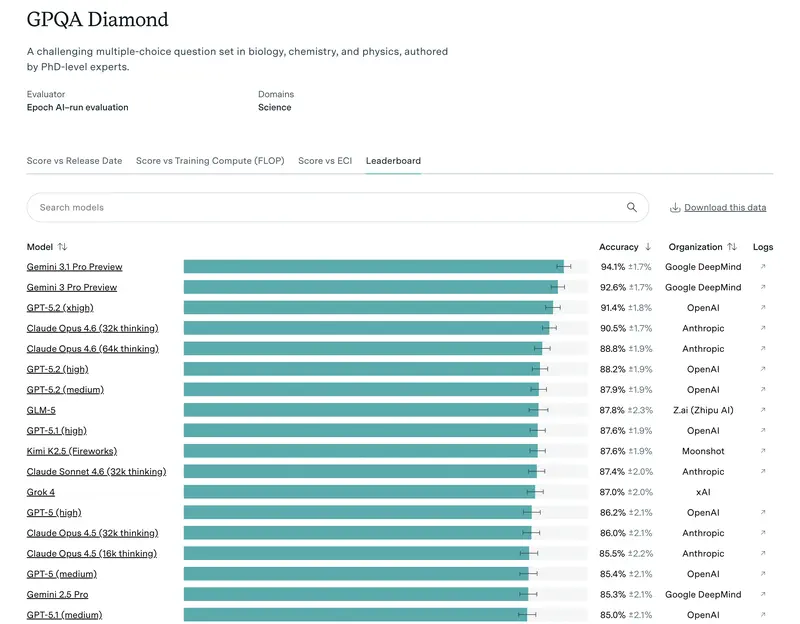
Täna on kuldstandard GPQA Diamond. Need on küsimused, mis on nii keerulised, et isegi internetti kasutavad inimesed-eksperdid eksivad nendes 60% juhtudel. Kui mudel saab siin 75%+, tähendab see, et võite usaldada sellele kõige keerulisemate juriidiliste või finansdokumentide kontrollimise.
2. Agentlik tõhusus (SWE-bench ja GAIA)
Juhtide jaoks on see 2026. aasta kõige olulisem näitaja. See mõõdab mitte „kõne ilu", vaid võimet tööd teha.
- SWE-bench Verified – näitab, mitu reaalset tarkvaraviga suutis mudel ise leida ja parandada.
- GAIA – testib mudelit ülesannetel, mis nõuavad brauseri kasutamist, failide otsimist ja tööriistadega töötamist.
3. Kasutajahinnangud: Chatbot Arena
Kõige autoriteetne „rahva" edetabel. lmarena.ai platvormil võrdlevad inimesed mudelite vastuseid pimesi.
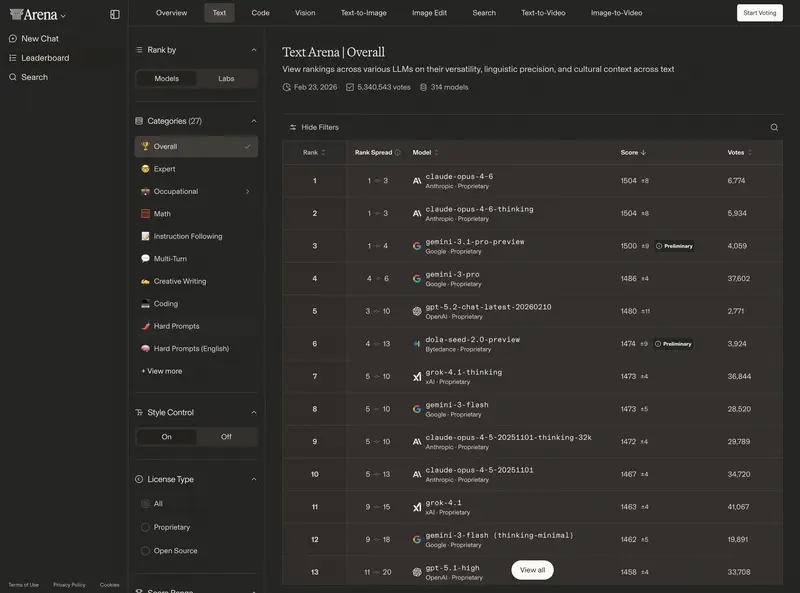
ELO-reiting 2026 (orientiirид):
- 1400–1500+: „superintellekti" mudelid (GPT-5.3, Claude 4.6 Opus, Gemini 3 Ultra).
- 1300–1400: suurepärased tööratsud (GPT-5-mini, Sonnet 4.6, DeepSeek V4).
- Alla 1200: vananenud või spetsialiseeritud mudelid.
Erinevus 30–50 ELO punkti on igapäevases kirjavahetuses praktiliselt märkamatu. Erinevus 100+ punkti tähendab kvalitatiivset hüpet intelligentsuses ja juhiste mõistmises.
4. Pikk kontekst: RULER ja „keskel kadunud" probleem
aasta mudelid väidavad kontekstiakende kohta 1–2 miljonit tokenit. Kuid akna suurus ≠ töö kvaliteet sellega. Võrdlusuuring RULER ja test Needle In A Haystack kontrollivad, kas mudel suudab leida ja õigesti kasutada informatsiooni, mis on peidetud pika dokumendi erinevatesse osadesse.
aastaks on mõlemad testid muutunud pigem baasmiinimumiks. Tippmudel on õppinud pikast tekstist üksikuid fakte leidma. Kuid 2025. aasta uuringud näitasid, et suur kontekstiaken ei garanteeri usaldusväärset arutlemist – mudel võib leida õige fragmendi eraldivõetult, kuid eksib, kui seda tuleb integreerida keerulise ümbritseva kontekstiga. Seetõttu kontrollivad uued testid (RULERv2, Sequential-NIAH, MMNeedle) mitte lihtsat otsimist, vaid mitmeetapilist informatsiooni agregeerimist dokumendi erinevatest osadest.
Peamine lõks kannab nime Lost in the Middle – mudelid töötavad kindlalt dokumendi alguse ja lõpuga, kuid hallutsineerivad või jätavad vahele fakte keskelt. See on kriitiline, kui laadite mudelisse 200-leheküljelist lepingut või aastaaruannet.
Praktiline nõuanne: Pärast pika dokumendi laadimist esitage mudelile küsimus just teksti keskel asuva teabe kohta. Kui vastus on ebatäpne või väljamõeldud – mudel ei tule teie andmemahuga toime.
„Sügava mõtlemise" mudelite hindamine (Reasoning)
O3 (OpenAI), R2 (DeepSeek) ja Opus Thinking (Anthropicu) mudelite ilmumisega tekkis uus hindamisprobleem. Need mudelid võivad vastuse üle „mõelda" 10 sekundist 5 minutini.
Kuidas hinnata nende kvaliteeti juhina?
- Väljundi täpsus – kui ülesanne on strateegiline (nt ühinemisriskide arvutamine), pole ooteaeg oluline – oluline on ainult täpsus.
- Läbipaistvus (CoT) – hea arutlusmudel peaks näitama samm-sammult protsessi (Chain-of-Thought). See võimaldab teil selle loogikat auditeerida.
Praktiline juhend: kuidas mudelit valida
LLM-i valimine äris 2026. aastal järgib kolmeastmelist algoritmi.
Samm 1 – Määrake roll
Mida teeb AI 80% ajast?
| Roll | Põhiline mõõdik |
|---|---|
| Strateeg / Analüütik | GPQA Diamond, FrontierMath |
| Digitaalne töötaja (Agent) | SWE-bench, GAIA |
| Kommunikaator (Kirjad, vestlused) | Chatbot Arena ELO (Overall) |
| Dokumentide audiitor | Long Context Benchmarks (RULER) |
Samm 2 – Kontrollige võrdlusuuringuid
Leidke valitud kategoorias 2–3 liidrit. Ärge vaadake tarnijate reklaamgraafikuid (nad valivad alati testid, kus nad on esimesed) – kasutage sõltumatuid ressursse:
- LMSYS Chatbot Arena – üldise „inimlikkuse" ja dialoogi kvaliteedi hindamiseks.
- Vectara Hallucination Leaderboard 2026 – kui faktiline täpsus on teie jaoks kriitiliselt oluline.
- LiveCodeBench / SWE-bench Verified – kui otsite AI-programmeerijat või agenti.
Samm 3 – „Proovisõit" oma andmetega
Võtke 5 kõige keerukamat reaalset juhtumit oma tööst eelmisel nädalal. Käitage need läbi valitud mudelite. Hinnake mitte „ilu", vaid järelduste täpsust ja juhiste täitmise täielikkust.
„Eksaminõu" lõks. 2026. aastal on levinud „andmete saastamise" praktika – mudeleid treenitakse spetsiaalselt populaarsete võrdlusuuringute küsimuste põhjal. Seetõttu on teie enda salajased andmed parim ja ainus tõeliselt aus võrdlustest.
Võrguühenduseta ülesanne: minge Chatbot Arenasse, valige kategooria „Hard Prompts" ja vaadake top 3 mudelit. Need on teie peamised kandidaadid kõige keerukamate tööülesannete lahendamiseks sel kvartalil.
Kasulikud lingid
- LMSYS Chatbot Arena
- GPQA Diamond
- SWE-bench Verified
- GAIA Benchmark
- Vectara Hallucination Leaderboard
- RULER (pikk kontekst)
See artikkel on osa sarjast „GenAI tööriistade ülevaade 2026". Kõiki tööriistu käsitletakse praktiliste harjutustega kursuses mysummit.school.
