Kohalikud LLM-id juhtidele: mida tegelikult saab kodus käivitada
Kõik, kes on piisavalt kaua töötanud ChatGPT või Claude’iga, esitavad varem või hiljem selle küsimuse: kas saaks midagi sarnast käivitada otse oma sülearvutis – ilma tellimuseta, ilma andmete lekketa, ilma serveritest sõltumata?
Aastal 2026 on vastus jah, aga reservatsioonidega, mis on vastusest endast olulisemad.
See artikkel on neile, kes juba kasutavad pilvepõhiseid LLM-e ja tahavad mõista, mida kohalik käivitamine tegelikult annab, millist riistvara selleks vaja on ja kus lõpevad ootused. Ilma tehnilise süvitsi minekuta, aga konkreetsete numbritega.
Miks üldse mudelit kohapeal käivitada
Enne kui riistvarasse süveneda, tasub vastata olulisemale küsimusele.
Pilveteenustel on kolm reaalset piirangut, mida tunnetatakse praktikas: andmete konfidentsiaalsus (te ei ole alati kindel, et kliendivestlusi ei indekseerita), sõltuvus kättesaadavusest (ChatGPT kukub tipptundidel, Claude’il on regionaalsed piirangud) ja kulud suure kasutusintensiivsuse korral.
Kohalik mudel lahendab need kolm asja korraga: andmed ei lahku teie arvutist, töötab võrguta ja pärast esialgset allalaadimist ei maksa midagi. See on selle tegelik väärtus – mitte „tasuta GPT-5 kodus", mis oleks ebaaus väide.
Küsimus on ainult selles, mis hinnaga – riistvara ja vastuste kvaliteedi mõttes.
Mis see üldse on: mudelid ja nende suurused
Keelemudeli suurust mõõdetakse tavaliselt miljardites parameetrites – numbrites, mille mudel on treeningu käigus „meelde jätnud". Tähistatakse tähega B: 7B, 14B, 70B.
Juhi jaoks ei ole see tehniline termin, vaid praktiline vihje: kui palju operatiivmälu on vaja, et mudel üldse käivituks.
Karm reegel: mudel võtab 4-bitise tihendamise puhul umbes poolteist gigabaiti mälu iga parameetrimiljardi kohta. See tähendab, et 7B-mudel võtab umbes 5 GB, 14B – umbes 9 GB, 32B – umbes 20 GB ja nii edasi. 16 GB operatiivmäluga sülearvutis ei mahu enam kõik, mis on üle 14B, täielikult kiiresse mällu – mudel hakkab „swapima" ja töötab tunduvalt aeglasemalt.
Kvantisatsioon ongi see tihendamine, millest juttu. Originaalmudel hoiab numbreid suure täpsusega; kvantisatsioon vähendab seda täpsust, et kahandada mahtu 2–4 korda. Väike kvaliteedikaotus vastutasuks võimaluse eest mudelit üldse käivitada.
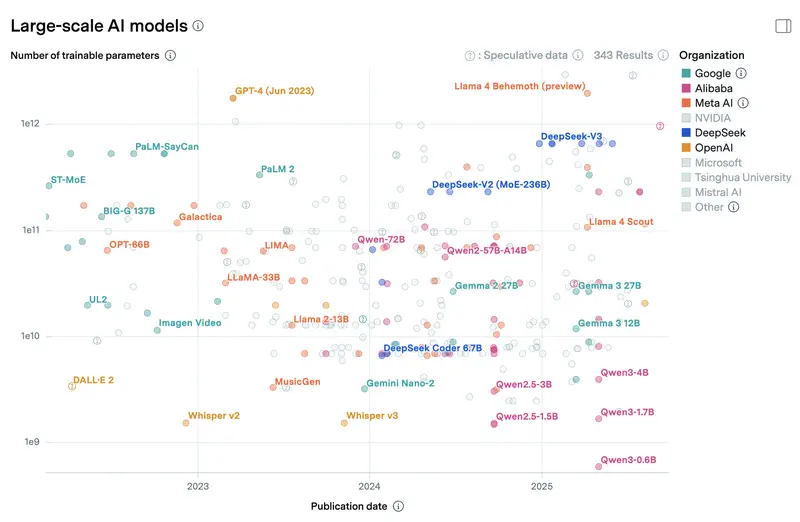
Mastaabi mõttes: pilveflagmannid nagu Claude Sonnet 4.6 ja GPT-5.4 oma parameetreid ametlikult ei avalda, aga valdkonna hinnangute järgi räägime sadadest miljarditest või triljonitest parameetritest Mixture-of-Experts arhitektuuris. Isegi kui aktiivselt töötab vaid osa (tinglikult 30–50B päringu kohta), mõõdetakse mudeli kogukaalu terabaitides ja see nõuab andmekeskust kümnete spetsiaalsete kiirendajatega. Kohalik 8B-mudel sülearvutis on umbes 1% pilveflagmanni suurusest. Sellest tulenebki kvaliteedilõhe keerukates ülesannetes: mitte sellepärast, et kohalike mudelite autorid oleks kehvemad, vaid seetõttu, et mastaap on kaks suurusjärku teine. Allpool graafik parameetrite arvuga mudelite kohta, mida saab käivitada kohapeal ja pilves – andmed Epoch AI-lt.
Millised mudelid on aktuaalsed 2026. aasta aprillis
Avatud mudelite maastik uueneb kiiremini kui enamik ettevõtete poliitikaid. 2026. aasta aprilli pilt on ootamatu neile, kes jälgisid TI-uudiseid läbi lääne väljaannete: esirinnas ei ole praegu ainult Meta ja Google, vaid terve rida Hiina laboreid ja üks üllatus OpenAI-lt.
DeepSeek V3.2 – tingimusteta liider avatud mudelite seas. 671B MoE 37B aktiivse parameetriga päringu kohta, ilmus 2025. aasta detsembris, kontekstiaken 163 tuhat tokenit. Vaatasime DeepSeeki üksikasjalikult: juhtimisülesannetes satub see stabiilselt ülemisse klastrisse. Kohalikuks käivitamiseks täismahus V3.2 ei sobi – isiklikul riistvaral seda üles ei saa panna. Aga sellel põhinevad destillaadid (7B, 14B) töötavad 8 GB VRAM-iga ja on analüütikas ning loogikaülesannetes oluliselt tugevamad kui tavalised sama suurusega kohalikud mudelid.
Qweni perekond Alibabalt – teine võtmesuund kohapeal käivitatavate mudelite seas. Qwen 3.5 ilmus 2026. aasta veebruaris–märtsis ja katab diapasooni 0,8B-st kuni flagmani 397B MoE-ni, mis kohalikuks käivitamiseks ei ole mõeldud. Kodukasutuseks on võtmetähtsusega suurused 27B dense (~16 GB VRAM Q4, käivitub 8 GB GPU-l), 9B ja 4B. 2. aprillil ilmus Qwen 3.6-Plus MoE-arhitektuuris 1 miljoni tokeni pikkuse kontekstiga. Meie Qweni ülevaates sai perekond kõrged hinded just mitmekeelsetes ülesannetes, sealhulgas väljaspool inglise keelt.
Hiina laborid on üldiselt kujunenud lääne flagmannide täieõiguslikuks alternatiiviks. Selle ringi silmapaistvamad avatud mudelid:
- Xiaomi MiMo-V2-Pro (märts 2026) – arutlusmudel, kontekst 1 miljon tokenit.
- MiniMax M2.5 ja M2.7 (veebruar–märts 2026) – suured MoE-mudelid, kontekst 196 tuhat tokenit.
- Z.ai GLM 5.1 (7. aprill 2026) – värskeim väljaanne selles nimekirjas, kontekst 202 tuhat tokenit.
- MoonshotAI Kimi K2.5 (jaanuar 2026) – kontekst 262 tuhat tokenit.
- StepFun Step 3.5 Flash (jaanuar 2026) – kompaktsem kui teised, aga laialdaselt kasutusel konveierites.
Ühtegi neist mudelitest ei saa sülearvutis käivitada – nad töötavad API kaudu või self-hosted tõsisel riistvaral (64+ GB mälu, mitme kaardiga konfiguratsioonid). Aga nad näitavad, kus tegelikult asub avatud TI turg.
gpt-oss-120b OpenAI-lt (august 2025) – haruldane juht, kui OpenAI avaldas avatud kaalud. 120B MoE-mudel stabiilse kasutusega kaheksa kuud pärast väljaandmist. Kohalikuks käivitamiseks on vaja Mac Studio tasandit 64+ GB-ga või tööjaama kahe videokaardiga.
Gemma 4 26B A4B Google’ilt – see on Gemma versioon, mida praktikas tegelikult kasutatakse. Mitte 31B ega 12B, vaid just 26B MoE-arhitektuuris 4 miljardi aktiivse parameetriga päringu kohta – sealt ka „A4B" nimes. Kontekst 262 tuhat tokenit, käivitub Ollama kaudu 16 GB mäluga sülearvutis kiiremini kui sama klassi dense-analoogid. 4B-versioon käivitub telefonis Google AI Edge Gallery kaudu.
NVIDIA Nemotron 3 Super – kontekst 262 tuhat tokenit, saadaval tasuta OpenRouteris. Populaarne valik agentide ja konveierite eksperimentideks, kus on oluline mitte kulutada iga päringu peale raha.
Mistral Nemo – kompaktne mudel CPU-inferentsiks. Mastaabilt tagasihoidlikum kui liidrid, aga klassis „töötab ilma videokaardita" on see tegelik töökoormaja.
Eraldi tasub mainida mudeleid, mida tehnilistes väljaannetes palju arutatakse, aga massikasutuses kohtab harvemini: Llama 4 Scout, Llama 3.3 70B, Phi-4, Mistral Small 3.1. Self-hosted installatsioonides kohtab neid sageli – seal määrab valiku integratsioonid ja harjumus, mitte populaarsus.
Millist riistvara on vaja ja mida te saate
Siin algab tsoon, kus ootused ja reaalsus lähevad kõige rohkem lahku.
Minimaalne variant: iga kaasaegne 16 GB RAM-iga sülearvuti
16 GB operatiivmäluga ja ilma videokaardita sülearvuti käivitab kuni 8–10B mudeleid läbi llama.cpp või Ollama, kasutades tavalist protsessorit. See töötab – aga aeglaselt.
Genereerimiskiirus CPU-l on 3–8 tokenit sekundis. ChatGPT annab teksti välja kiirusega umbes 40–80 tokenit sekundis (see on see, mida te tajute kui „prindib kiiresti"). 8 tokenit sekundis on umbes üks-kaks sõna iga kahe sekundi jooksul. Pikkade vastuste puhul tundub nagu aeglustatud film. Kasutada saab, aga alati ei ole mugav.
Lihtsate ülesannete jaoks – lühikese teksti kokkuvõte, vastus konkreetsele küsimusele – on see täitsa talutav. Iteratiivse dialoogi jaoks hakkab kiirelt tüütama.
Hea variant: Apple M-seeria või RTX 3060 12 GB
See on lävi, pärast mida hakkab kohalik LLM tunduma päris tööriistana, mitte tehnoloogia demona.
M3, M4 või M5 kiipidega Mac 16–32 GB ühendatud mäluga on tänasel päeval ilmselt parim platvorm kohalike LLM-ide jaoks. Põhjus: ühtne arhitektuur, kus CPU ja GPU jagavad sama mälu, võimaldab mudeleid kiiresti käivitada ilma lisavideokaardita. Apple’i MLX-raamistik on nende kiipide jaoks optimeeritud ja töötab samal riistvaral 20–30% kiiremini kui standardne llama.cpp.
Qwen 3.5 9B M3 Pro-l annab umbes 25–35 tokenit sekundis. Gemma 4 26B A4B (MoE aktiivse 4B-ga) M4 Max-il – 30–45 tokenit sekundis oluliselt suurema efektiivse mudelimahu juures. 32 GB-ga Mac hoiab kindlalt 15–30 tokenit sekundis 13B-klassis, 64 GB-ga – 25–50 tokenit 27–32B mudelitel. See tundub juba nagu normaalne vestluskiirus. Alates 2026. aasta märtsist läks Ollama ametlikult üle MLX-ile kui põhimootorile Apple Silicon-il – see tähendab, et pelgalt Ollama installimisega kaasaegsele Mac-ile saate juba optimeeritud jõudluse.
RTX 3060 12 GB – Windowsi kasutajatele on see kõige soodsam viis samasse liigasse pääseda. Kasutatud kaart maksab umbes 200–250 eurot ja 12 GB videomälu piisab 7B- ja 14B-mudelite mugavaks käivitamiseks. Gemma 4 26B A4B mahub samuti 12 GB-sse tänu MoE-arhitektuurile. Qwen 3.5 27B dense tervikuna 12 GB-sse ei mahu, aga Qwen 3.5 9B annab RTX 3060-l umbes 20–40 tokenit sekundis. Kiiruse poolest umbes nagu hea Mac.
Oluline nüanss termini kohta. Inferents on protsess, kus treenitud mudel vastab teie päringule (erinevalt treeningust, kus mudelit andmetele häälestatakse). GPU-inferents tähendab, et mudel töötab videokaardil, mitte protsessoril. Videokaart korrutab maatrikseid paralleelselt kümneid kordi kiiremini kui protsessor ja keelemudelite jaoks annab see vahe „sekundiline viivitus" ja „minut ootamist" vahel.
GPU-inferentsi jaoks on vaja just videomälu (VRAM), mitte tavalist operatiivmälu. RTX 3060 12 GB VRAM on 12 GB just mudeli jaoks. Kui mudel ei mahu VRAM-i, laaditakse osa RAM-i ja kiirus langeb mitu korda.
Et mõista, mida erineva suurusega mudeli eest saate, võrrelge kolme käivitust ühel ülesandel: Gemma 4 26B A4B (populaarseim Gemma OpenRouteris, käivitub sülearvutis tänu MoE-le), gpt-oss-120b (avatud kaalud OpenAI-lt, vajab Mac Studiot või kahte videokaarti) ja DeepSeek V3.2 (avatud ökosüsteemi pilveflagman, ~37B aktiivset MoE-s):
Praktikas annab Gemma 4 26B A4B struktureeritud vastuse juhtumite eristamisega – parem kui tüüpiline 8B-mudel, aga süsteemne järeldus on tavaliselt etteaimatav. gpt-oss-120b pakub nüansseeritumat strateegiat ja esitab asjakohaseid täpsustavaid küsimusi, kuigi sügavus sõltub konkreetsest päringust. DeepSeek V3.2 pilveflagmanni tasemel annab struktuuri koos prioriteetimisega, realistlike tähtaegadega ja mittetriviaalse tähelepanekuga ülejäänud nelja kohta. See ongi see vahe, mille eest pilves makstakse.
Edasijõudnu variant: 70B ja rohkem
70B-klass 4-bitises tihenduses võtab umbes 48 GB mälu (täiskvaliteedi jaoks vaja 40 GB+). Vajalik on Mac Studio 64 GB-ga, mitme videokaardiga server või tööjaam RTX 4090 24 GB-ga koos lisamäluga. RTX 4090 saab hakkama Gemma 4 26B A4B ja kuni 31B dense-mudelitega, annab välja 50–85+ tokenit sekundis. gpt-oss-120b sellesse klassi ei kuulu – 120B MoE nõuab 64+ GB ühtset mälu või kahte kaarti.
Kiirus on sealjuures 8–15 tokenit sekundis. Kvaliteet läheneb GPT-5 Mini tasemele. Aga sisenemiskulu – alates 1500–2000 eurost riistvara eest. See ei ole enam „kodus proovida", vaid teadlik investeering konkreetse põhjendusega.
20 tokenit sekundis – kas see on kiire või aeglane?
See on küsimus, mida harva selgesõnaliselt selgitatakse.
Üks token on inglise keeles umbes 3/4 sõna, vene keeles veidi vähem sõnade pikkuse tõttu. Eesti keeles sarnane suurusjärk. Kakskümmend tokenit sekundis on umbes 15 sõna sekundis ehk umbes 900 sõna minutis. Võrdluseks: keskmine inimene loeb 200–300 sõna minutis.
Kakskümmend tokenit sekundis on kiire. Te loete aeglasemalt, kui mudel kirjutab. Meeldiv kogemus.
Kaheksa tokenit sekundis on keskmiselt 6 sõna sekundis. Ikka veel loetav, aga pikkades lausetes tunneb pausi. Sobib kiirustamatute ülesannete jaoks.
Kolm tokenit sekundis on praktiliselt rea-rea haaval väljund. Pikk vastus võtab märgatavalt aega. Töötada saab, aga pideva dialoogi jaoks ei sobi.
Iga ülaltoodud number on klikitav link simulaatorile shir-man.com/tokens-per-second, kus tekst ilmub reaalajas etteantud kiirusega. Minut eksperimenti annab vahest paremini aimu kui ükski kirjeldus.
Võrdluseks: GPT-5 annab välja 40–80 tokenit sekundis sõltuvalt serverite koormusest. Väikesel koormusel kiiremini, tipptundidel aeglasemalt. Hea kohalik seadistus on tajukiiruselt täiesti võrreldav.
On oluline reservatsioon, millest harva räägitakse: arutlusmudelite (reasoning-mudelid) puhul on nähtav trükkimiskiirus vaid pool lugu. Enne vastamist võib selline mudel mitu minutit sisemiselt „mõelda" – genereerida varjatud arutlusahelat, mida te ei näe. Kohalik arutlusmudel sülearvutis võib kulutada sisemisele analüüsile 5–10 minutit ja seejärel veel minuti vastust trükkida kiirusega 20 tokenit sekundis. Ekraanil näeb see välja nii: esitasid küsimuse, kursor vilgub, midagi ei juhtu – mudel töötab. See on reasoning-režiimi jaoks normaalne, aga selleks tuleb valmis olla. Pilves juhtub sama asi 10–30 sekundiga tänu andmekeskuse võimsusele. Iteratiivse dialoogi jaoks on vahe kriitiline; taustaülesande jaoks („mõtle selle üle, kuni ma kohvi joon") mitte väga.
Kvaliteet: aus võrdlus
Siin tuleb ootustega olla ettevaatlik.
Kohalik 8B-mudel ei ole võrdväärne GPT-5 või Claude Sonnetiga. Seda on oluline mõista enne, mitte pärast allalaadimist. Meie 54 mudeli edetabelis sai GPT-5.4 juhtimisülesannetel 4,8 viiest, Claude Sonnet 4.5 – 4,78, Gemini 2.5 Pro – 4,46. Tüüpiline kohalik 8B-mudel jääks vahemikku 2,8–3,3 – sinna, kus samas edetabelis asuvad GigaChat-Ultra (3,26) ja Llama 4 Maverick (2,95). Mitte seetõttu, et kehvad – lihtsalt teine ülesannete klass.
Konkreetsed mudelid, mida tegelikult saab kohapeal käivitada, näevad meie võrdlustestis välja nii: Gemma 3 12B sai 3,58 (klaster 3), Qwen3 32B – 3,67, Gemma 3 27B – 3,75. See on juba huvitavam: umbes Yandexi Alice AI tase (3,86) või veidi madalam. Phi-4, 3,8B-mudel Microsoftilt, mida aktiivselt soovitatakse „nutikuse" pärast sünteetilistes testides, sai kokku 2,27 – viimane koht 54 mudeli seas. See tuletab meelde, et sünteetilised testid ja juhtimisülesanded on eri asjad. Kontrollige meie võrdlustestiga, enne kui mudelit valite.
70B ja kõrgema puhul pilt muutub. Selle klassi mudeleid ei testitud võrdlustestis otseselt, aga parameetrite järgi on nad lähedal 3. klastrile – orienteeruvalt tsoonis 3,5–3,8, see tähendab Qwen3 32B tasemel või veidi kõrgemal. See on juba tõsine tööriist enamiku igapäevaste ülesannete jaoks. Lõhe Claude Sonneti või GPT-5-ga säilib ülesannetes, mis nõuavad sügavat kontekstuaalset mõistmist või mitmekäigulisi järeldusi – aga dokumentide kokkuvõtete, mustandite ettevalmistuse ja struktureeritud päringute puhul on see tunduvalt väiksem.
Et näha lõhet oma silmaga – siin on eelarvesõbralik GPT-5.4 Nano vastu flagmann GPT-5.4 tüüpilisel juhtimisülesandel. GPT-5.4 Nano maksab suurusjärgu võrra odavamalt ja vastamiskiiruselt on võrreldav korraliku kohaliku 70B-mudeliga. Võrrelge, mis kaob nõrgema mudeli valimisel:
Vahe ei ole mitte sõnastuste ilus, vaid analüüsi sügavuses: mini-mudel võtab kolme põhjust tavaliselt võrdväärsetena ja annab üldiseid soovitusi, flagman – eraldab sümptomid juurpõhjusest ja esitab sisulisi küsimusi. Kohalik 70B käitub lähemalt mini-mudelile, kohalik 8B – tunduvalt halvemini.
Konkreetsed stsenaariumid, kus kohalik 8B saab hästi hakkama:
- Dokumentide ja koosolekute transkriptide kokkuvõtted
- Kirjade ja aruannete mustandite genereerimine šablooni järgi
- Lihtsad küsimused-vastused laetud dokumendi kohta
- Teksti vormindamine ja struktureerimine
Stsenaariumid, kus parem pilve juurde tagasi minna:
- Keerukas analüüs mitteilmsete järeldustega
- Töö konkureerivate hüpoteesidega
- Ülesanded, kus on oluline faktide täpsus
- Pikad mitmeetapilised juhised tingimustega
Aru saada, millist TI-d ja millal kasutada – täpselt seda teevad avatud mooduli 9 praktilist ülesannet. Proovige tasuta, ilma registreerimiseta.
Makset ei nõuta • Teavitus käivitumisel
Nutitelefon kui kohalik platvorm
Eraldi teema, mis veel aasta tagasi oli eksperiment ja nüüd on kujunenud täiesti tööstsenaariumiks.
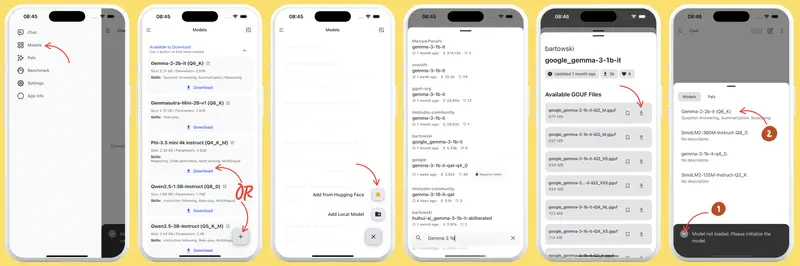
Gemma 4 4B Google’ilt (ilmus 2. aprillil 2026) on üks peamistest mobiilsetest variantidest. Käivitub läbi Google AI Edge Gallery iOS-ile ja Androidile, laaditakse alla ühe korra ja töötab täielikult võrguta. iPhone 16 Pro-l A18 Pro kiibiga ja 8 GB mäluga (1100 EUR) või Samsung Galaxy S24/S25 Ultra-l (900 EUR) – umbes 15–20 tokenit sekundis. Phi-4 3,8B Microsoftilt annab samadel seadmetel sarnase kiiruse. Llama 3.2 3B ja Qwen 3.5 4B käivituvad samuti läbi PocketPal või MLC LLM.
Qwen 3.5 versioonides 0,8B ja 4B käivitub samuti telefonides läbi PocketPal-i. Kiirus tippvoolu telefonidel (iPhone 17 Pro, Pixel 9 Pro, Samsung S24/S25) – 5–20 tokenit sekundis. Keskklassis 6 GB RAM-iga on tulemus tagasihoidlikum; mugavaks käivitamiseks on vaja seadmes minimaalselt 8 GB mälu.
Telefoni peal käivitamise praktiline väärtus on piiratud mõne stsenaariumiga: konfidentsiaalse dokumendi analüüs seal, kus internetti ei ole, kiire mustand ilma pilveligipääsuta, kontseptsiooni demonstreerimine. Regulaarseks tööks ei ole telefoni ekraan ja kasutajaliides parim keskkond. Aga võimalusena – täiesti reaalne.
Tööriistad: mida paigaldada
Ollama – lihtsaim viis alustada. Paigaldatakse nagu tavaline programm, mudelid laaditakse alla ühe käsuga (ollama pull qwen3.5:9b), töötab brauseri kaudu või mis tahes OpenAI-ga ühilduva API-ga rakendusega. Alates 2026. aasta märtsist kasutab Apple Silicon-il MLX-i. Soovitatav enamikule.
LM Studio – Ollama graafilise liidesega. Kui käsurida tekitab ebamugavust, võimaldab LM Studio sama teha visuaalse liidese kaudu: valida mudel, alla laadida, käivitada vestlus. Ressursinõudlikum.
Jan – open-source variant, mille rõhk on privaatsusel. Töötab täielikult võrguta, ei saada ühtegi telemeetriat. Kui konfidentsiaalsus on peamine motiiv, tasub kaaluda.
llama.cpp – põhimootor, millel töötavad kõik kolm ülaltoodud tööriista. Konsooli tööriist neile, kes tahavad maksimaalset kontrolli. Juhile ilma tehnilise taustata – pigem ei.
MLX Apple’ilt – raamatukogu otse Apple’ilt mudelite käivitamiseks Silicon-il. Kasutatakse Ollama sees, aga saab ka otse. Annab 20–30% kiirusvõidu võrreldes llama.cpp-ga.
Kohalik TI on üks töövorme. Avatud moodulis on 9 juhi ülesannet erinevate tööriistadega – pilvepõhiste ja kohalikega. Proovige tasuta.
Makset ei nõuta • Teavitus käivitumisel
Agentrežiim: kohalik mudel ligipääsuga failidele
Kui olete lugenud OpenCode’ist või agentsest andmeanalüüsist, tekib loogiline küsimus: kas saab agenti kohapeal käivitada, ilma andmeid pilve saatmata?
Jah, ja see on ilmselt kõige huvitavam stsenaarium konfidentsiaalsete dokumentidega töötavatele juhtidele.
OpenCode, mida vaatasime varem üksikasjalikult, toetab kohalike mudelite ühendamist Ollama kaudu. Skeem on selline: Ollama käivitab mudeli kohapeal ja avab kohaliku API pordil 11434. OpenCode ühendub sellega pilvepõhise Claude’i asemel. Andmed ei lahku arvutist. Agent loeb teie faile, analüüsib, kirjutab tulemusi – kõik kohapeal.
Piirang on etteaimatav: kohalik 8B-mudel agentrežiimis saab hakkama lihtsamate ülesannetega kui Claude või GPT-5. Ühe-kahe dokumendi analüüsiks konkreetsete küsimuste kohta – täitsa sobib. Keerukaks mitmefaililiseks uurimiseks mittetriviaalsete järeldustega – lõhe on märgatav. Nagu näitasime konkreetsel näitel, määrab agentse analüüsi kvaliteedi eelkõige mudel, mitte raamistik.
32B-mudeli ja rohkem puhul muutub lõhe oluliselt väiksemaks. Kui teil on Mac Studio 64 GB-ga või tööjaam kahe videokaardiga – agentlik kohalik režiim 32B-mudeliga muutub täisväärtuslikuks pilve asenduseks enamiku ülesannete jaoks.
Minimaalne sisenemispunkt: mida osta
Lühidalt:
Alustamiseks – M3 või M4 kiibiga Mac 16 GB mäluga. Kui teil juba on selline Mac, on teil juba vajalik riistvara olemas. Ollama paigaldub 5 minutiga ja saate Qwen 3.5 9B või Gemma 4 26B A4B juba täna käima panna.
Mugavaks tööks 14–32B mudelitega – Mac 32 GB mäluga või PC RTX 3060/4060 12 GB-ga. RTX 3060 12 GB maksab järelturul umbes 200–250 eurot – see on odavaim tee normaalse kogemuseni Windowsil.
Pilve kompromissideta asendamiseks – Mac Studio 64 GB-ga (see on juba oluline investeering) või tööjaam kahe videokaardiga (3000 USD).
Tuleb ausalt öelda: enamiku juhtide jaoks on optimaalne vastus mitte „kohalikele mudelitele üle minna", vaid kasutada neid pilvelahenduse täiendusena. Pilv keerukate ülesannete jaoks, kus kvaliteet on oluline. Kohalik – konfidentsiaalsete andmete jaoks, võrguta töö jaoks ja juhtudeks, kus pole mõtet maksta pilve eest lihtsate operatsioonide eest.
Mis jäi ebaselgeks
Mõned asjad selguvad tavaliselt alles pärast paigaldamist, mitte enne.
Mudeli suurus allalaadimisel on lõplik suurus kettal. 8B-mudel Q4 formaadis kaalub umbes 5 GB. 32B – umbes 20 GB. Ollama kasutamisel hoitakse allalaaditud mudeleid süsteemikaustas; vahel saab väikesel kettal ootamatult ruum otsa.
Esimene käivitus võtab aega. Ollama laeb mudeli mällu esimese päringu ajal – see võib suure mudeli puhul võtta 30–60 sekundit. Pärast seda jääb ta mällu ja järgnevad päringud on kiired.
Süsteemne prompt emakeeles töötab paremini kui selle puudumine. Enamik mudeleid on treenitud segatud andmetel, aga vastavad selles keeles, milles nendega räägitakse. Selge viide „vasta eesti keeles" seansi alguses aitab.
Kohalike ja pilvepõhiste mudelite kvaliteedi võrdluseks juhtimisülesannetes on olemas meie avalik võrdlustest – seal saab vaadata, kus konkreetsed mudelid kvaliteedis tippklassi pilvelahendustele alla jäävad.
Lõpuks, võime mudelit kohapeal käivitada ei tähenda, et nii peaks alati tegema. See on lisatööriist arusaadavate kasutustingimustega. Täpselt seda oskust – mõista, millal milline tööriist sobib – käsitleb ka meie õppeprogramm.
Huvitav on see, et tööriista valiku loogika ise – pilv või kohalik, 8B või 70B, agent või vestlus – on täpselt sama tüüpi oskus kui TI-le ülesannete oskuslik sõnastamine. Tööriistad vahetuvad iga paari kuu tagant, aga oskus ootusi kalibreerida ja ülesandele lähenemist valida – jääb.

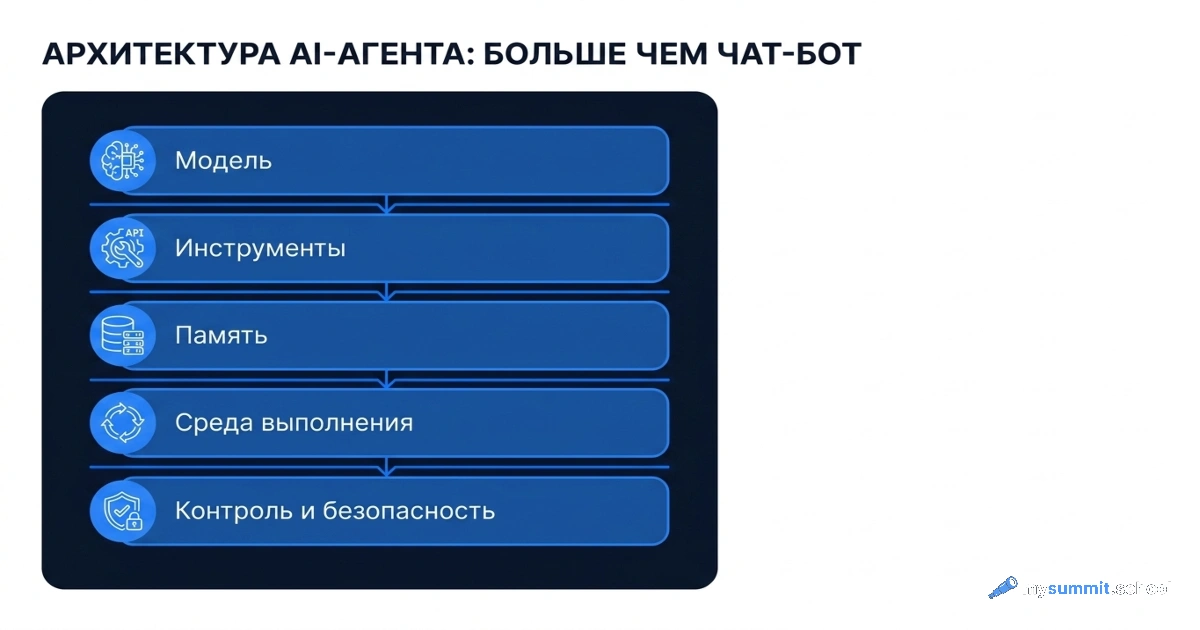


Tööriistast süsteemini
Põhiprogramm õpetab töötama iga TI-ga – pilvepõhise, kohaliku, agentsega. Spetsialiseerumine 'Projektijuht' lisab konkreetsed juhtimisülesannete stsenaariumid. Vaadake programmi täielikku struktuuri.

Stanislav Belyaev
Engineering Leader Microsoftis18 aastat insenerimeeskondade juhtimist. mysummit.school asutaja. 700+ lopetajat Yandex Practicumis ja Stratoplanis.