Make Weak Model Great Again: kas promptimine parandab nõrka mudelit?
- aasta märtsis avaldas Venemaa digiministeerium seaduseelnõu „usaldusväärsete AI-mudelite" kohta. Kui see vastu võetakse – jõustumine on kavandatud septembriks 2027 – saavad riigiasutused ja kriitilise taristu operaatorid kasutada ainult registreeritud mudeleid. ChatGPT, Claude ja Gemini, mis edastavad andmeid välisriikidesse, võidakse piirata. Venemaa seadmedele plaanitakse kohustuslikku kodumaiste närvivõrkude eelpaigaldust.
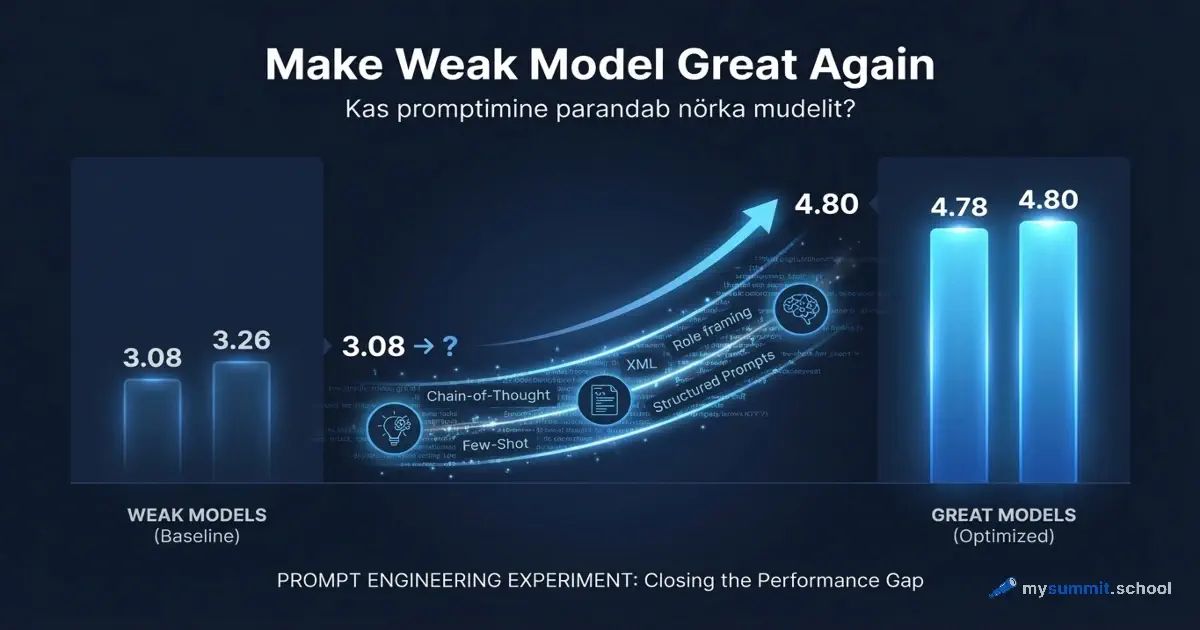
Probleem on selles, et Vene mudelid jäävad maha. Meie 54 mudeli uuringus sai GigaChat 3,26 palli 5-st, GPT-5.4 – 4,80. Vahe 32%.
Kuid see ei ole ainult Venemaa probleem. Igaüks, kes kasutab odavamat või nõrgemat mudelit – olgu see Llama, Phi, Mistral, lokaalne juurutus või mõni piirkondlik pakkuja – seisab silmitsi sama küsimusega: kas targem promptimine suudab kvaliteedilõhe sulgeda?
Mida me teeme ja milleks
Eksperiment „Make Weak Model Great Again" võtab neli mudelit, mis on Venemaal saadaval – GigaChat-Ultra, GigaChat-2-Max, Alice AI (YandexGPT) ja Qwen3 Max – ning laseb igaühe läbi kümne promptimistehnika kuuel juhtimisülesandel: alates e-kaubanduse mõõdikute analüüsist kuni Vene tööõiguseni. Võrdluseks lahendavad samu ülesandeid GPT-5.4 ja Claude Sonnet 4.6 naiivsete promptidega – et fikseerida lagi, mille poole nõrgad mudelid püüdlevad.
Need konkreetsed mudelid on testjuhtumid, kuid järeldused on universaalsed. Kui tehnika töötab GigaChatiga – see töötab Llamaga. Kui see ei tööta nõrga mudeliga üldse – pole vahet, milline nõrk mudel teil on.
Tehnikad on erinevad – alates lihtsatest, mida iga juht saab minutiga omandada (rolliülesanne, struktureeritud šabloon), kuni mitmeastmeliste dialoogideni, kus mudel esmalt analüüsib, siis kritiseerib ennast, siis täiendab vastust. Nende vahel on Chain-of-Thought („mõtle samm-sammult"), Few-Shot näited (näitame hea vastuse näidist) ja XML-struktuuriga prompt, mida tavaliselt kasutavad arendajad, mitte juhid.
Kuid kaks tehnikat teevad selle eksperimendi tõeliselt ebatavaliseks: CAPS EMPHASIS ja agressiivne toon. Internetis on palju nõuandeid – „kirjuta SUURTÄHTEDEGA ja mudel kuuletub" või „sõima seda, see annab parema tulemuse". Keegi viitab Microsofti 2024. aasta uuringule, keegi lihtsalt isiklikule kogemusele. Teaduslikku alust selle taga peaaegu ei ole, veel vähem nõrkade mudelite puhul. Lisasime mõlemad tehnikad, et lõplikult kontrollida: kas see töötab – või on see promptimise linnalegend?
Miks vastus ei ole ette ilmne
Näiliselt – parem prompt -> parem tulemus. Kuid nõrkade mudelite puhul on kõik keerulisem ja olemasolevad uuringud kinnitavad seda.
Wei et al. (Google Brain, 2022) näitasid, et Chain-of-Thought – tehnika, mis sunnib mudelit „samm-sammult mõtlema" – töötab suurepäraselt suurtel mudelitel. Kuid väikestel mudelitel kutsub see esile „enesekindlaid, kuid valesid" arutlusi. Mudel annab välja viis sammu, mis näevad loogilised välja – ja jõuab vale järelduseni. Halvem, kui oleks kohe vastanud. Kas GigaChat langeb sellesse lõksu – me ei tea.
Zhang et al. (ACL 2024) tuvastasid veelgi ebameeldivama asja: väikesed mudelid on füüsiliselt võimetud oma vigu avastama. Kui palute „leia oma vastuse nõrgad kohad ja paranda seda", mudel ei kritiseeri ennast – see „enesekinnitus". Sõnastab veidi ümber, muutmata sisu. Kui meie andmed kinnitavad seda nõrkadel mudelitel – see on konkreetne järeldus: ärge raiskage aega palvel „paranda oma vastust" GigaChatile või mõnele muule nõrgale mudelile.
Ja siis on veel arhitektuurne lagi. Promptid reorganiseerivad seda, mida mudel juba teab. Need ei saa luua teadmisi, mida mudeli kaaludes pole. Kui GigaChat ei ole treeningul Vene tööseadustikku „lugenud" – ükski prompt „sa oled kogenud tööõiguse jurist" ei pane teda seadustikku õigesti tsiteerima. Parim, mida saab saavutada – et mudel ütleks „ma ei tea" enesekindla hallutsinatsiooni asemel.
Muide, meie võrdlustestis ilmnes vastuintuitiivne tulemus: GigaChat ja Alice – vene keelel treenitud mudelid – näitasid Venemaa reaalsusega seotud ülesannetel madalamat tulemust kui GPT-5.4. Tööõigus, piirkondlikud turud, kohalik äri spetsiifika – kõikides nendes teemades osutus välismaine mudel tugevamaks kui kohalik. Tõenäoliselt on GPT-5.4 lihtsalt „lugenud" rohkem materjale oma mahu tõttu. See on üks eksperimendi võtmeküsimusi: kus jookseb piir, mille järel ükski prompt ei kompenseeri teadmiste lõhet?
See on oluline igaühe jaoks, kes kasutab väiksemat mudelit – mitte ainult Venemaal. Llama 3.3 70B ei tea teie ettevõtte töösisekorraeeskirju. Mistral ei tunne teie piirkonna maksuseadusandlust. Phi ei ole lugenud teie tööstusharu raporteid. Küsimus on universaalne: kus lõpeb promptimise maagia ja algab mudeli teadmiste puudumine?
Selle uuringu promptimistehnikad saavad õppematerjalide aluseks. Proovige 9 juhi praktilist ülesannet avatud moodulis – tasuta, ilma registreerimiseta.
Makset ei nõuta • Teavitus käivitumisel
Mida juht saab tulemustest
Teeme seda teadlikult rakenduslikuks uuringuks, mitte akadeemiliseks. Teadusartiklid väikeste keelemudelite kohta keskenduvad tavaliselt automatiseeritud optimeerimisele – fine-tuning, DSPy, algoritmidel põhinev promptide parandamine. Meid huvitab teine asi: mida saab teha tavaline juht, kellel on nõrk mudel ja viis minutit päringu sõnastamiseks?
Iga tehnika puhul hindame mitte ainult tulemuse kvaliteeti, vaid ka vaeva – kui palju aega kulub prompti ümbersõnastamisele. Sest tehnika, mis parandab vastust 15%, kuid nõuab 20 minutit ettevalmistust, ei ole juhile vajalik.
Tulemuseks valmib kolm asja. Esimene – kaart „tehnika -> mudel -> ülesanne": kui teil on GigaChat dokumentide analüüsi ülesandel – millist lähenemist kasutada? Kui Alice kirja koostamisel? Teine – valmis šabloonid konkreetsete juhtimisülesannete jaoks. Ja kolmas – aus piir: millistes stsenaariumides promptimine ei aita ja parem on vahetada mudelit.
See kõik läheb õppekursusesse – ossa, kus promptimise teooria kohtub andmetega. Mitte „mis on prompt", vaid „mis tegelikult töötab, millise tööriistaga, millise ülesande jaoks".
Qwen3 Max, Alice, GigaChat – saadaval ilma VPN-ita. Kontrollige oma promptimise lähenemist juhi reaalsetel ülesannetel kursuse tasuta moodulis.
Makset ei nõuta • Teavitus käivitumisel
Millal tulemusi oodata
Eksperiment on käivitusfaasis. Täisraport ilmub siin, blogis – iga tehnika analüüsiga, konkreetsete šabloonidega ja ausa järeldusega selle kohta, kus on lagi. Kui te töötate iga päev GigaChati, Alice’i, Llama või mõne muu nõrgema mudeliga – vastus teie küsimusele valmib.
Tööriist on olemas. Nüüd – oskus
Kursuse alus käsitleb promptimist reaalsetel juhtimisülesannetel: struktuuri, rolliülesandeid, dekompositsioon, CoT. Juhtide spetsialiseerumine süvendab rakendamist planeerimises, analüütikas ja meeskonnatöös.



