L'agent plutôt que le chat : analyser ses données sans copier-coller
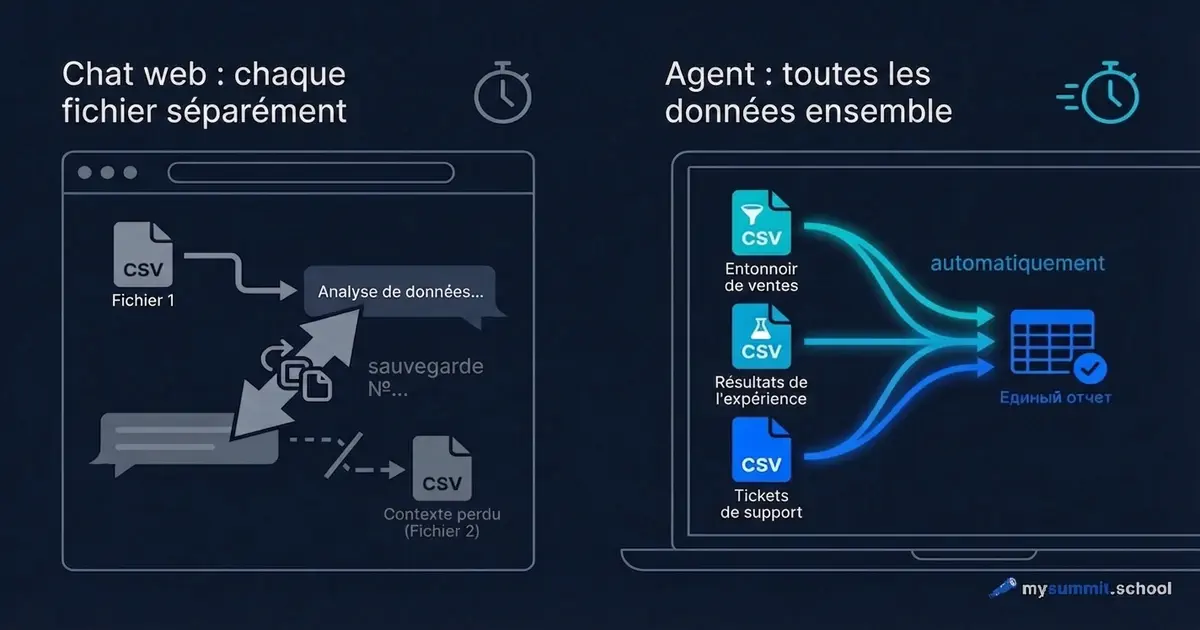
Vous avez trois fichiers de données : un entonnoir d’activation, les résultats d’un test A/B et les tickets du support. La question : pourquoi l’onboarding cale-t-il ? Vous ouvrez ChatGPT, vous chargez le premier fichier, vous posez votre question. Réponse. Vous chargez le deuxième. ChatGPT vous demande : pouvez-vous me rappeler le contexte ? Vous chargez le troisième. Le contexte du premier fichier est déjà évincé.
Quarante minutes plus tard, vous avez trois conversations séparées, et aucune ne répond à la question de départ. Parce que la question était unique, mais les données, elles, étaient à trois endroits.
Ce n’est pas un problème de ChatGPT. C’est un problème d’approche.
Deux façons de travailler avec ses données
La différence entre « un chat dans le navigateur » et « un agent sur votre ordinateur » ne tient pas à la puissance du modèle. Elle tient à la question : qui va vers qui ?
Dans un chat, vous apportez les données au modèle. Par morceaux, via l’upload de fichiers, à l’intérieur d’une seule conversation. Le modèle répond à ce qu’il voit à l’instant T. Le message suivant – déjà un contexte un peu différent.
En mode agentique, c’est le modèle qui vient à vos données. L’agent s’installe comme une application ordinaire sur votre ordinateur, voit le dossier contenant vos fichiers et travaille avec directement – comme un analyste à qui l’on aurait donné accès à votre machine. Vous lui décrivez la tâche en langage courant, comme dans Slack – il lit les fichiers, il calcule, il sauvegarde le résultat. C’est la même idée que BYOA – mais dans sa dimension pratique, plus conceptuelle.
La différence a l’air technique. Dans les faits, elle change tout.
Une tâche concrète, deux façons de la résoudre
Imaginons un scénario réel. Le product manager d’un service SaaS constate que la conversion des nouveaux utilisateurs en utilisateurs actifs plafonne à 38 % depuis quatre mois. Trois tableaux de données sont sur la table.
Le premier – l’entonnoir d’onboarding : inscription, première action, deuxième action, invitation d’un collègue.
Le deuxième – les résultats d’un test A/B sur une nouvelle fonctionnalité d’onboarding : groupe de contrôle et groupe test, 500 entreprises chacun.
Le troisième – 350 tickets du support envoyés par de nouveaux utilisateurs au cours du dernier trimestre.
La question : à quelle étape perdons-nous les gens, pourquoi, et l’expérience a-t-elle fonctionné ?
Variante 1 : ChatGPT, interface web
Vous chargez l’entonnoir. ChatGPT l’analyse et identifie le principal point de décrochage. Bien. Vous chargez les tickets – vous voulez comprendre sur quoi les utilisateurs se plaignent précisément à cette étape. ChatGPT répond : je vois les tickets, rappelez-moi à quelle étape le décrochage se produisait ? Vous expliquez. Il analyse.
Vous chargez les résultats du test. Nouveau fichier. ChatGPT les voit, mais il ne se souvient plus des chiffres exacts de l’entonnoir du premier fichier – dans quel segment la conversion était à 55 %, dans lequel elle était à 38 %. Pour les croiser, il faut recopier les chiffres de la première conversation et les coller manuellement dans la troisième.
Bilan au bout d’une heure : trois conclusions séparées qu’il faut assembler à la main. Et une question de plus : n’aurait-il pas arrondi quelque part, ou confondu des lignes ? Impossible de le vérifier.
Variante 2 : un agent sur votre ordinateur
Vous ouvrez le dossier contenant les trois tableaux et vous écrivez à l’agent en un seul message – comme à un analyste sur Slack :
Regarde l’entonnoir d’activation. Trouve le principal point de décrochage. Ensuite, ouvre les tickets et repère les plaintes liées à cette étape. Enfin, vérifie les résultats du test – l’expérience a-t-elle fonctionné globalement, et sur le segment client principal ?
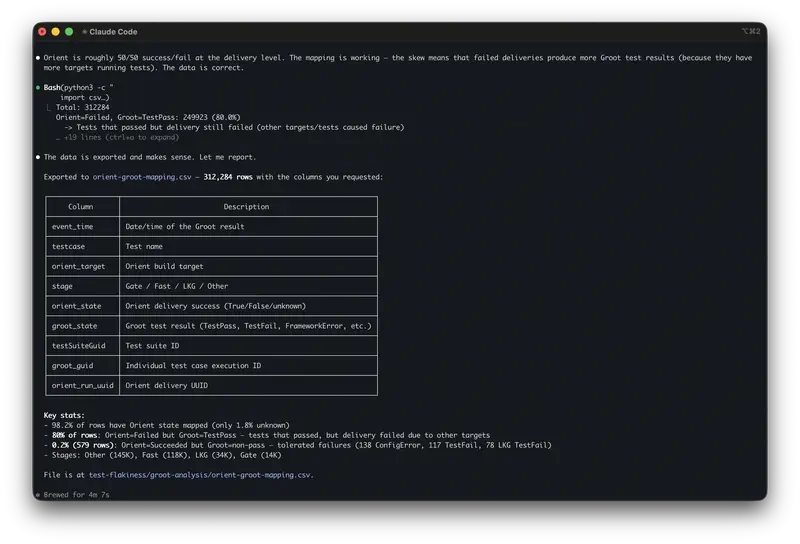
L’agent ouvre les trois fichiers. Il les lit. Il écrit du code pour analyser l’entonnoir, l’exécute, récupère les chiffres. Il passe aux tickets, les regroupe par thème, en compte les fréquences. Il charge les données du test, compare les groupes, vérifie la significativité statistique. Les résultats des trois fichiers sont dans un seul et même contexte, simultanément.
Tout le processus prend quelques minutes. Vous voyez précisément comment l’agent a calculé – et vous pouvez vérifier chaque étape.
L'analyse de données en mode agentique est l'un des thèmes du cours. Essayez les 9 exercices pratiques du module ouvert – gratuit, sans inscription.
Sans paiement requis • Notification au lancement
Ce qui change fondamentalement
Quelques détails qui paraissent mineurs, mais qui font toute la différence sur la qualité de l’analyse.
L’agent voit simultanément que la troisième étape de l’entonnoir perd 45 %, que 31 % des tickets se plaignent précisément de cette étape, et que dans l’expérience, le segment cible affiche +13,8 pp. Ces trois faits n’ont plus à être recoupés à la main – ils sont déjà dans une seule et même conclusion.
Autre point : l’agent garde la trace de la manière dont il a calculé. Demain, les données du mois suivant arrivent – vous relancez la même analyse, sans effort supplémentaire. Ce n’est plus une question ponctuelle, c’est une routine. Et c’est précisément là que se cache la taxe cachée de l’IA : 37 % du temps soi-disant gagné repart en vérifications et en reprises. Quand vous avez le code, vérifier prend quelques secondes.
Enfin, l’agent renvoie à des lignes précises dans le tableau. Vous pouvez ouvrir le fichier source et vérifier. Dans un chat, le modèle dit « la plupart des entreprises de taille moyenne » – impossible de savoir si c’est un vrai pattern ou une hallucination.
Quand l’agent hallucine quand même
Section honnête, parce que l’agent n’est pas un tour de magie.
L’agent hallucine exactement au même endroit qu’un chat : quand il formule des interprétations, pas quand il calcule. Quand il calcule, vous voyez le résultat d’un calcul concret. Mais quand l’agent dit « cela traduit un problème d’UX », c’est son interprétation, et elle peut être fausse.
Un bon réflexe : après chaque conclusion, lui demander de montrer de quelles lignes du tableau elle découle. L’agent doit alors répondre avec des exemples précis ou vous afficher une coupe des données. S’il se met à expliquer avec des mots, sans renvoyer aux données – il interprète, il ne lit plus.
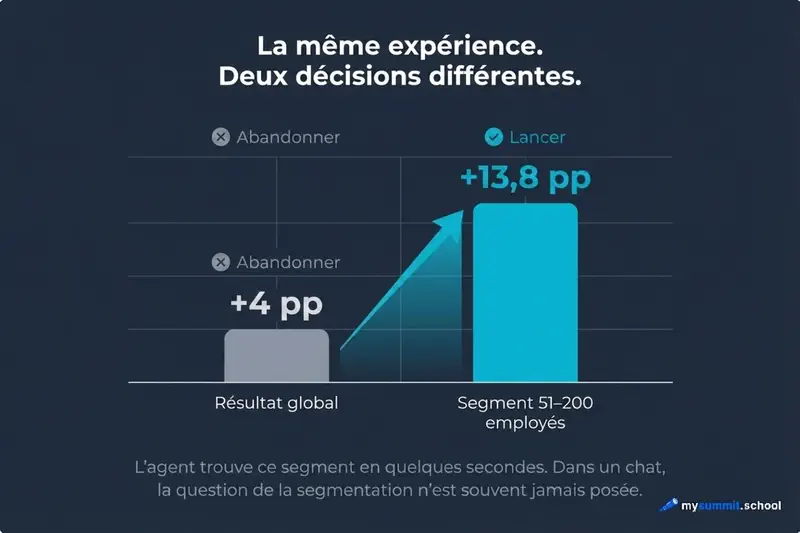
Deuxième point : l’agent ne connaît pas votre contexte business. Il constate que, dans le groupe test, la conversion progresse de 4 pp globalement et de +13,8 pp sur le segment 51–200 salariés. Mais la décision – lancer à 100 % ou non – est la vôtre. Pour la prendre, il faut savoir quel est le segment cible, quel est le marché, quel est le coût de développement.
L’agent fournit des chiffres exacts. La décision, c’est vous qui la prenez.
Ce que révèle vraiment l’analyse des trois fichiers
Regardons concrètement ce que l’agent trouve dans un tel jeu de données.
Entonnoir d’activation (500 entreprises). L’agent calcule la conversion à chaque étape. Étape 1 – 77 %, dans les clous. Étape 2 – 55 %. Là, problème : sur 385 entreprises ayant franchi la première étape, seules 210 passent à la suivante. Plus de la moitié des utilisateurs actifs potentiels disparaît à ce moment-là.
L’agent formule le constat ainsi : principal point de décrochage entre l’étape 2 et l’étape 3, 45 % ne franchissent pas le pas. Le temps médian entre les deux est de 8 heures, alors que la première étape n’en prenait que 2. Autrement dit, les utilisateurs reviennent, mais ils ne terminent pas l’action suivante.
Tickets du support (350 au total). L’agent les regroupe par thème. Résultat : 31 % des tickets posent la question « comment ajouter un objet manuellement ? ». 27 % concernent la connexion d’une source externe. 19 % – l’upload de fichiers.
Cela confirme l’hypothèse tirée de l’entonnoir : les gens ne comprennent pas comment accomplir la deuxième action. L’UX n’est pas évidente.
L’agent fait alors une étape supplémentaire que, dans un chat, vous n’auriez probablement pas demandée : il segmente les tickets par taille d’entreprise. Il constate que les entreprises de taille moyenne (50–200 salariés) posent la question de l’ajout manuel deux fois plus souvent que les petites. C’est le segment cible du produit – ce qui rend le problème bien plus important.
Résultats du test (1 000 entreprises, deux groupes). Topline : contrôle 38,4 %, test 42,4 %, soit +4 pp – décevant à première vue. On attendait mieux, la significativité est à la limite.
L’agent segmente par taille d’entreprise. Sur le segment 51–200 salariés : contrôle 39,2 %, test 53,0 %, soit +13,8 pp – un résultat fort. C’est précisément sur le segment cible que l’expérience a fonctionné.
Ce basculement – d’« expérience ratée » à « victoire sur le segment cible » – l’agent le trouve parce qu’il tient les trois fichiers dans un même contexte, en même temps. Dans un chat, il aurait fallu poser la question séparément – et rien ne dit qu’elle vous serait venue à l’esprit.
Quand l’agent n’est PAS nécessaire
Le mode agentique n’est pas toujours justifié.
S’il s’agit juste de regarder la moyenne d’un petit tableau de 50 lignes – ChatGPT ira plus vite. Inutile de sortir un outil supplémentaire.
Si les données sont confidentielles et que vous ne maîtrisez pas bien l’outil – mieux vaut clarifier ce point en amont. Les modèles cloud (ChatGPT, Claude) traitent les données sur les serveurs du fournisseur. Cela peut être inacceptable pour des données sous NDA. Un agent qui tourne avec un modèle local sur votre machine est un autre scénario – mais il demande une préparation à part.
Si la tâche consiste à rédiger un texte, à imaginer une structure, à discuter d’une décision – l’agent n’apporte rien. Sa valeur se joue précisément dans le travail sur fichiers.
Pour commencer : outils et modèles
Parmi les outils dont on parle le plus souvent : Claude Code d’Anthropic (nécessite un abonnement autour de 100 $ par mois), Kilo Code (une extension VS Code, bien adaptée à celles et ceux qui travaillent déjà avec du code), OpenCode (open source, compatible avec n’importe quel modèle).
Pour démarrer à coût quasi nul, OpenCode associé à des modèles ouverts fait très bien le travail. Kimi K2 et DeepSeek coûtent des fractions de centime par requête, et ils rivalisent avec GPT-4o sur les données structurées – ce qui est précisément ce qui compte ici.
OpenCode s’installe comme une application classique et se lance sur le dossier contenant vos fichiers. Premier vrai résultat d’analyse – un quart d’heure après l’installation. Pour les détails pratiques, voir l’article sur OpenCode. On y trouve trois exercices à essayer dès le premier jour.
L'agent lit les fichiers, calcule, segmente les données. Testez votre approche sur 9 vraies tâches de manager – gratuit, sans inscription.
Sans paiement requis • Notification au lancement
Ce qui change dans le travail
L’analyse agentique ne remplace pas un analyste. C’est une manière de supprimer la friction entre la question et la réponse.
Avant, entre « je veux comprendre pourquoi cette métrique décroche » et « voici une analyse des trois fichiers, avec segmentation » – il y avait plusieurs heures de travail, ou une demande à un analyste avec plusieurs jours d’attente. Maintenant – quelques minutes.
Cela change la nature même des questions qu’on se pose. Quand l’analyse coûte cher, on ne pose que les questions importantes. Quand elle coûte peu – on se met à tester des hypothèses qu’on jugeait auparavant insuffisamment importantes pour justifier une demande.
Dans notre exemple des trois fichiers, c’est exactement ce qui s’est passé. Le topline du test avait l’air mauvais – +4 pp, significativité à la limite. Conclusion habituelle : itérer, ou tuer la feature. Mais l’agent a segmenté les données en quelques secondes – et il s’est avéré que, pour le segment cible, le résultat était solide (+13,8 pp). On passe d’un « tuer » à un « lancer ».
Curieusement, le plus important ici n’est pas la vitesse. C’est autre chose : l’analyse devient reproductible. Dans un mois, quand les nouvelles données arriveront, vous relancerez la même analyse. Ce n’est plus une réponse ponctuelle – c’est une routine analytique.
Il faudrait peut-être distinguer deux types de travail sur les données : les questions ponctuelles (pour lesquelles le chat se débrouille très bien) et les routines analytiques récurrentes (pour lesquelles l’agent change radicalement la donne). La plupart des tâches de PM qui pèsent vraiment sur les décisions – entonnoirs, cohortes, expériences – relèvent du second type.
Et après : un agent branché sur vos données
Cet article a montré un seul type de tâche – une analyse ponctuelle de trois tableaux. Mais la vraie valeur de l’agent arrive plus tard : quand l’analyse cesse d’être ponctuelle pour devenir une routine.
Ce n’est plus « utiliser un agent », c’est construire son propre agent – avec ses routines, branché sur vos vraies données.
C’est exactement ce à quoi est consacré le cours Agent personnel pour managers, que nous lançons. Quelques points concrets en plus de cet article :
- Vous démarrez sur vos vraies données dès le premier jour – dès la troisième session, l’agent travaille avec votre véritable messagerie. Vous l’exportez comme un fichier classique sur votre machine, sans passer par la DSI.
- Pendant le cours, vous constituez une bibliothèque de scénarios prêts à l’emploi adaptés à vos tâches – et ils restent chez vous après le cours.
- À la fin de chaque bloc, vous envoyez votre travail et vous recevez un retour personnalisé – pas une auto-évaluation, un vrai feedback.
- Q&A en direct avec l’auteur, canal Telegram entre participants, études de cas.
- Le cours est construit sur des outils accessibles partout. Le coût total des requêtes aux modèles pour l’intégralité du cours se chiffre en quelques dollars.
Le cours est en préparation. Pour entrer dans la première cohorte – le formulaire d’inscription est juste au-dessus.
L'outil est là. Reste la compétence
En attendant le lancement du cours Agent personnel, commencez par les fondations : le socle du cours couvre le prompt engineering et la pensée critique – sans eux, l'agent vous sort des chiffres, pas des insights. La spécialisation Management produit aborde l'analyse de données par l'IA et le travail avec les agents sur des tâches de PM.




Stanislav Belyaev
Engineering Leader chez Microsoft18 ans a diriger des equipes d'ingenieurs. Fondateur de mysummit.school. 700+ diplomes chez Yandex Practicum et Stratoplan.