99 % de la qualité pour 1,4 % du prix : ce qui ne va pas sur le marché des modèles IA
La plupart des managers choisissent un modèle IA de la même manière : ils prennent le plus cher disponible. La logique est limpide – plus cher, c’est mieux. C’est ainsi que fonctionnait le logiciel d’entreprise depuis vingt ans.
Le marché des modèles IA en 2026 fonctionne différemment. Le coût d’une requête varie de 0,0001 $ à 0,17 $ – trois ordres de grandeur. Et la différence réelle de qualité entre les dix meilleurs modèles ? 0,24 point sur une échelle de cinq. Pendant ce temps, Wharton / GBK Collective constate qu’un tiers des projets IA en entreprise ne dépasse pas le stade du pilote. Et Epoch AI montre que seuls 5,6 % des utilisateurs exploitent réellement l’IA en profondeur.
La question n’est peut-être pas de savoir quel modèle est le meilleur, mais plutôt si payer le prix fort pour un modèle premium produit un résultat proportionnellement meilleur pour les tâches managériales courantes.
Nous avons vérifié. La réponse s’est avérée plus brutale que prévu.
Les données
Entre janvier et mars 2026, nous avons testé 54 modèles IA sur huit catégories de tâches managériales – de la rédaction d’e-mails à l’analyse de données et à la prise de décision en information incomplète. Les résultats complets sont publiés sur la plateforme. Une expérience parallèle – peut-on compenser un modèle faible par le prompting – a montré que les prompts structurés réduisent l’écart, mais ne le comblent pas entièrement. Méthodologie : deux évaluateurs IA (Claude Opus 4.5 et Gemini 3 Pro) plus calibration humaine, 2 121 évaluations individuelles. Chaque modèle reçoit un score composite de 1 à 5 et un coût par requête en dollars.
Les prix correspondent à un instantané d’avril 2026, d’après les données d’OpenRouter.ai, le seul agrégateur proposant un format uniforme. Avertissement : les prix API évoluent rapidement. GPT-5.4 est passé de 0,0585 $ à 0,0158 $ par requête pendant l’étude. GPT-5.2 Pro, à l’inverse, est passé de 0,039 $ à 0,1659 $.
Le tableau final comprend 53 modèles (un a été exclu en raison d’une tarification opaque).
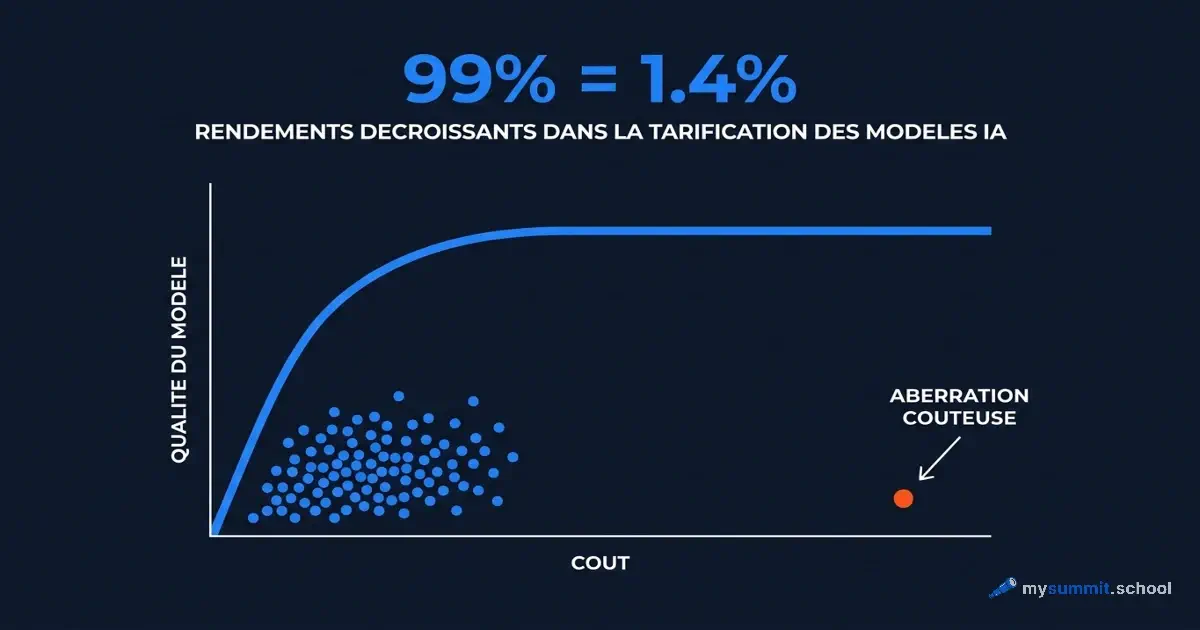
Des rendements extrêmement décroissants
La relation prix-qualité des modèles IA suit une courbe logarithmique. Passer de la tranche 0,0001 $ à 0,002 $ par requête produit un bond de qualité d’environ 1,5 point. Passer de 0,002 $ à 0,17 $ – soit une multiplication du prix par 85 – n’apporte qu’environ 0,1 point supplémentaire.
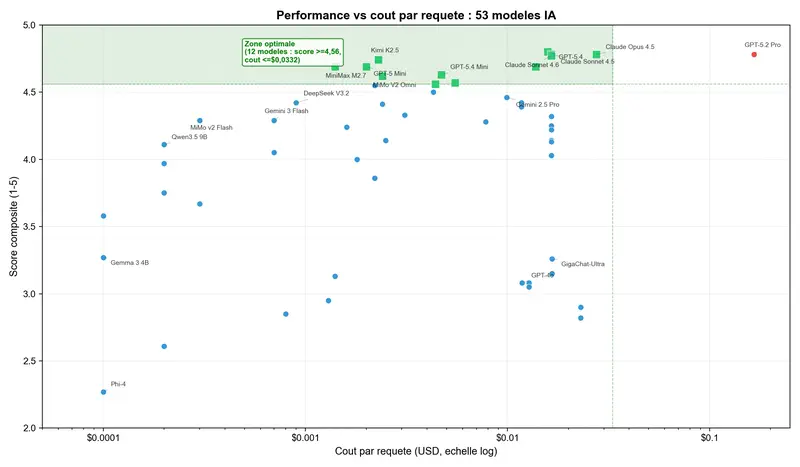
Voici un exemple concret. Claude Sonnet 4.5 obtient 4,78 points à 0,0165 $ par requête. GPT-5.2 Pro – également 4,78 points. Mais à 0,1659 $. Dix fois plus cher. Même résultat. Nous avons vérifié trois fois – nous pensions à une erreur dans le tableau. Non, c’est simplement la réalité du marché.
Et puis nous avons regardé Kimi K2.5. Score de 4,74 à 0,0023 $ par requête. Soit 99 % de la qualité de GPT-5.4 pour 1,4 % du prix de GPT-5.2 Pro.
La stratégie 80/20
Les comparaisons abstraites, c’est intéressant, mais qu’est-ce que cela signifie pour un budget réel ?
Nous avons modélisé trois stratégies pour une équipe de managers effectuant 1 000 requêtes par mois.
Stratégie « tout au maximum » : toutes les requêtes via GPT-5.4. Coût : 15,80 $/mois. Qualité : 4,80.
Stratégie 80/20 : 80 % des tâches courantes (e-mails, notes de synthèse, comptes rendus de réunion) via un modèle économique comme Qwen3.5 9B, 20 % des tâches complexes (analyse stratégique, rapports pour la direction) via GPT-5.4. Coût : 3,32 $/mois. Qualité : 4,25.
La différence : moins 79 % de dépenses pour une perte de 11 % en qualité. Pour 80 % des tâches – rédiger un brouillon d’e-mail, résumer un document, préparer un ordre du jour – la différence entre un modèle à 0,0002 $ et un à 0,016 $ est littéralement indiscernable.
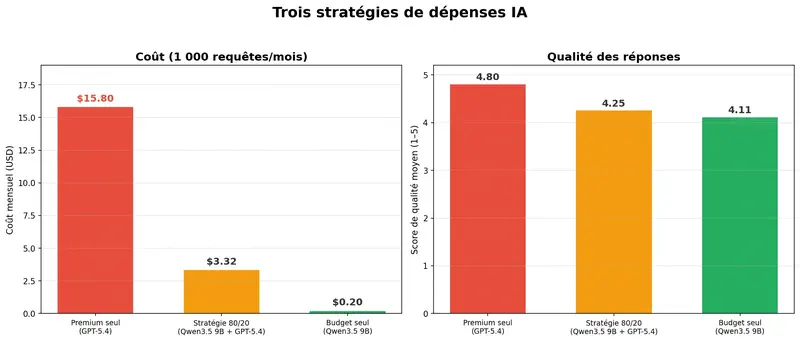
Ce n’est pas un exercice théorique. Pour une équipe de 10 managers à 100 requêtes par mois, la stratégie 80/20 économise environ 125 $ par mois par rapport à l’approche « premium pour tous ». La somme n’est pas transformationnelle, mais elle n’est pas nulle non plus. Et surtout – la qualité sur 80 % des tâches reste indiscernable.
L’arithmétique paraît simple. La complexité commence quand il faut décider concrètement : voici une tâche, voici trois modèles – lequel choisir et pourquoi. La différence entre « ça devrait convenir » et « je sais pourquoi j’ai choisi celui-là » – c’est une compétence qui se construit sur des cas réels.
Quelles taches confier a un modele economique, lesquelles au premium ? Testez 9 taches manageriales sur differents modeles -- gratuit, sans inscription.
Sans paiement requis • Notification au lancement
Les champions cachés : l’indicateur « qualité par dollar »
Nous avons introduit la métrique PPD (Performance Per Dollar) – le score de qualité divisé par le coût par requête. Plus le PPD est élevé, plus vous obtenez de qualité pour chaque dollar dépensé.
Les résultats renversent la hiérarchie habituelle.
| Modèle | Score | Coût/requête | PPD |
|---|---|---|---|
| GPT-5.2 Pro | 4,78 | 0,1659 $ | 28 |
| GPT-5.4 | 4,80 | 0,0158 $ | 304 |
| Kimi K2.5 | 4,74 | 0,0023 $ | 2 097 |
| DeepSeek V3.2 | 4,42 | 0,0009 $ | 4 825 |
| Gemini 3 Flash | 4,29 | 0,0007 $ | 6 085 |
| MiMo v2 Flash | 4,29 | 0,0003 $ | 12 434 |
| Qwen3.5 9B | 4,11 | 0,0002 $ | 21 076 |
Les modèles économiques offrent de 40 à 1 700 fois plus de qualité par dollar que GPT-5.2 Pro. Ce n’est pas une erreur d’arrondi. C’est une inefficience structurelle du marché, sur laquelle on peut jouer.
La « taxe IA » – et qui la paie
Pourquoi est-ce un problème ? Est-ce que tout le monde n’utilise pas l’IA de la même façon ?
Non. L’étude Epoch AI / Ipsos a montré que 62 % des utilisateurs d’IA effectuent des tâches simples – recherches rapides, brouillons courts. Seuls 5,6 % utilisent l’IA en profondeur. Pour ces 62 %, la différence entre une requête à 0,002 $ et une requête à 0,17 $ est littéralement invisible.
Les dépenses, elles, sont bien visibles. Workday, dans son rapport 2026, introduit le terme « taxe IA » – 37 % du temps « économisé » grâce à l’IA est consacré à corriger ses erreurs. Mais il existe une autre taxe – financière : le surpaiement pour un modèle premium sur des tâches où un modèle économique ferait aussi bien.
Brookings constate que parmi les Américains utilisant l’IA, seuls 19 % estiment qu’elle les rend plus productifs au travail. 4 % – significativement plus productifs. Google Cloud, dans son rapport sur le ROI, montre l’autre face : les entreprises qui obtiennent des résultats réels y parviennent non pas en achetant le modèle le plus cher, mais en choisissant précisément l’outil adapté à la tâche. Peut-être que le problème ne vient pas de l’outil, mais de la façon dont on le choisit et de ce sur quoi on le dépense.
Le tableau 'tache -> outil -> prix' se trouve dans la lecon 8 du module ouvert. 9 cas pratiques de manager avec l'IA, gratuit.
Sans paiement requis • Notification au lancement
Recommandation pratique
Si vous gérez un budget IA pour une équipe – voici ce que vous pouvez faire cette semaine.
Classifiez les tâches : brouillons d’e-mails, résumés de documents, notes sur les procédures, comptes rendus de réunion – c’est la routine, 70 à 80 % des requêtes. Analyse stratégique, documents pour la direction, travail sur des données ambiguës – tâches complexes, 20 à 30 %.
Configurez le routage : la routine vers un modèle économique (Kimi K2.5, Qwen3.5 Plus, DeepSeek V3.2), les tâches complexes vers un modèle premium (GPT-5.4, Claude Sonnet 4.5). Techniquement, cela peut être une passerelle API, un bot dans une messagerie avec deux boutons, ou simplement un accord d’équipe : « pour les e-mails on utilise X, pour l’analytique – Y ».
Mesurez : au bout d’un mois, comparez – la qualité sur les tâches courantes a-t-elle changé ? Si non – vous venez de réduire vos dépenses IA de 70 à 80 % sans perte de résultat.
Pour le choix d’un modèle spécifique, consultez notre analyse détaillée des modèles locaux. Les outils pour travailler avec plusieurs modèles sont présentés dans l’article sur OpenCode.
Réserves
Notre benchmark teste des catégories de tâches spécifiques. Il est possible que les modèles premium soient réellement supérieurs sur des raisonnements complexes multi-étapes ou des tâches que nous n’avons pas testées. GPT-5.2 Pro, malgré son coût élevé, affiche une stabilité remarquable (écart-type de 0,082) – certains modèles économiques présentent une dispersion plus importante. L’approche « l’IA évalue l’IA » comporte ses propres biais, bien que la calibration humaine les atténue.
Et surtout : ces chiffres sont un instantané du marché en avril 2026. Les prix changent chaque semaine. Mais la tendance structurelle – des rendements extrêmement décroissants dans le segment haut de gamme – ne changera probablement pas : trop de modèles concurrents, des prix qui baissent trop vite.
Conclusion
L’hypothèse « plus cher = proportionnellement meilleur » est infirmée par les données. Le marché des modèles IA en 2026 présente des rendements extrêmement décroissants : la surprime pour le premium est réelle et mesurable. Cela ne signifie pas que les modèles premium sont inutiles – pour 20 % des tâches où la qualité est critique, la différence peut justifier le prix. Mais utiliser GPT-5.4 pour résumer un compte rendu de réunion, c’est un peu comme prendre l’hélicoptère pour aller au bureau : techniquement supérieur, économiquement absurde.
L’écart entre prix et qualité sur le marché des modèles IA est aujourd’hui plus grand que jamais – et ne se réduira probablement pas dans l’année à venir. Mais la question la plus intéressante est ailleurs : si Kimi K2.5 offre 99 % de la qualité de GPT-5.4 pour 1,4 % du prix, qu’achète exactement un manager en choisissant le premium ? La réputation du fournisseur ? L’habitude ? Ou la certitude que « nous utilisons ce qu’il y a de mieux » – même si ce « mieux » ne se voit pas dans le résultat ?
Données complètes dans notre étude de 53 modèles.
De l'experience a la methode
Le choix du modele est l'un des exercices du cours. Le module Fondamentaux couvre le prompt engineering et la pensee critique avec l'IA. La specialisation Gestion de projets montre comment integrer l'IA dans le rythme operationnel du manager -- des brouillons a l'analytique.




Stanislav Belyaev
Engineering Leader chez Microsoft18 ans a diriger des equipes d'ingenieurs. Fondateur de mysummit.school. 700+ diplomes chez Yandex Practicum et Stratoplan.