DeepSeek en 2026 : le flagship économique des IA génératives

AI-модели в этой статье
DeepSeek (souvent écrit « Deep Seek ») – une startup IA chinoise qui, en deux ans, s’est imposée parmi les leaders de l’industrie. En avril 2026, DeepSeek a lancé V4 – une génération de modèles qui rivalise avec GPT-5.4 et Claude Opus 4.6 en qualité, mais coûte 10 à 50 fois moins cher.
Pour un manager, DeepSeek c’est avant tout le prix. Une qualité au niveau des meilleurs modèles occidentaux, et un coût d’API plusieurs fois inférieur aux concurrents. DeepSeek excelle particulièrement en analytique, en raisonnement logique et en programmation. Tous les modèles sont open source sous licence MIT : vous pouvez les télécharger et les déployer sur vos propres serveurs sans restriction.
Qu’est-ce qui distingue DeepSeek ?
DeepSeek repose sur un principe d’efficacité « intelligente ». Au lieu de mobiliser tous les experts pour chaque réunion, le système convoque instantanément seulement 2 à 3 spécialistes pertinents pour la question posée (architecture Mixture-of-Experts).
- Fonctionne à moindre coût – consomme 2 à 4 fois moins de ressources de calcul grâce à l’attention hybride et à la compression du KV-cache.
- Traite des documents volumineux – fenêtre de contexte de 1 000 000 tokens (~750 000 mots, environ 2 500 pages de texte).
- Raisonne par étapes – trois modes de réflexion : réponse rapide, analyse approfondie et raisonnement maximal.
Principaux modèles DeepSeek (avril 2026)
DeepSeek V4 Pro
Le modèle phare. 1,6 trillion de paramètres, dont 49 milliards actifs par token. Un assistant universel : textes, analyse, code, manipulation de données. En qualité, il se situe au niveau de GPT-5.4 et Claude Opus 4.6 – avec un retard estimé à 3–6 mois.
- Contexte : 1 000 000 tokens (entrée) / jusqu’à 384 000 tokens (sortie)
- Trois modes de réflexion : Non-Thinking (réponses rapides), Think High (analyse approfondie), Think Max (raisonnement maximal avec auto-vérification)
- Classement Codeforces : 3 206 – niveau grand maître international
DeepSeek V4 Flash
Le modèle rapide et économique. 284 milliards de paramètres, 13 milliards actifs. Une qualité proche de Pro sur les tâches standard – pour un coût 12 fois inférieur.
- Même contexte de 1 000 000 tokens
- Mêmes trois modes de réflexion
- Idéal pour les tâches en flux : chatbots, traitement de documents, requêtes en masse
Multimodalité : Janus-Pro et Image Recognition
DeepSeek-V4 est un modèle textuel. Pour le traitement d’images, des solutions distinctes existent :
- Janus-Pro-7B – génération et reconnaissance d’images. Sur le benchmark GenEval, il atteint 80 % (DALL-E 3 – 67 %). Limitation : résolution basse de 384×384 px.
- Image Recognition Mode (bêta depuis avril 2026) – analyse d’images dans le chat DeepSeek. Reconnaît diagrammes, tableaux et captures d’écran.
DeepSeek est gratuit et puissant. Notre module ouvert montre où les managers se trompent avec n'importe quel modèle IA – 9 tâches réelles.
Sans paiement requis • Notification au lancement
Comparaison avec les concurrents
Modèles chinois
DeepSeek V4 – leader en rapport qualité-prix, mais pas le seul acteur chinois de poids :
| Modèle | Entreprise | Contexte | Point fort | Prix (output/1M) |
|---|---|---|---|---|
| DeepSeek V4-Pro | DeepSeek | 1M | Code, raisonnement, prix | 0,87 $ |
| DeepSeek V4-Flash | DeepSeek | 1M | Vitesse, tâches en masse | 0,18 $ |
| Kimi K2.6 | Moonshot AI | 256K | Tâches agentiques, jusqu’à 300 sous-agents | 4,00 $ |
| GLM-5.1 | Zhipu AI | 203K | Précision du raisonnement | ~2,00 $ |
| Qwen 3.6 Plus | Alibaba | 1M | Large couverture de tâches | ~1,50 $ |
| MiniMax M2.7 | MiniMax | 128K | Modèle auto-apprenant | ~1,20 $ |
La remise de 75 % est devenue permanente en juin 2026 – 0,87 $ pour la sortie est désormais le prix standard.
Kimi K2.6 – le principal concurrent de DeepSeek parmi les modèles chinois. Il domine les tâches agentiques (SWE-Bench Pro : 58,6 % pour Kimi contre 55,4 % pour DeepSeek V4-Pro). Capable de lancer jusqu’à 300 sous-agents en parallèle pour des tâches complexes comme le refactoring multi-heures d’une base de code. Mais il coûte 5 à 14 fois plus cher que DeepSeek.
Comparaison avec les modèles occidentaux
| Modèle | Prix (input/output par 1M) | Qualité (BenchLM, 0–100) | Contexte |
|---|---|---|---|
| Gemini 3.1 Pro | ~3,50 $ / 10,50 $ | 93 | 1–2M |
| GPT-5.5 | 5,00 $ / 25–30 $ | 92 | 1M |
| Claude Opus 4.7 | 5,00 $ / 25,00 $ | 88 | 200K |
| DeepSeek V4-Pro (Max) | 0,435 $ / 0,87 $ | 87 | 1M |
| DeepSeek V4-Flash | 0,09 $ / 0,18 $ | 77 | 1M |
DeepSeek V4-Pro obtient 87 sur 100 sur l’échelle BenchLM – seulement 1 point de moins que Claude Opus 4.7. Pour un coût 29 fois inférieur. (Le benchmark distinct de MySummit sur les tâches managériales utilise une échelle de 1 à 10 – résultats dans la section de mise à jour ci-dessous.)
Où DeepSeek V4 surpasse les concurrents
- Programmation : LiveCodeBench 93,5 % – supérieur à Gemini 3.1 Pro (91,7 %) et Claude Opus 4.6 (88,8 %)
- Recherche d’information : BrowseComp 83,4 % – supérieur à Claude Opus 4.7 (79,3 %)
- Long contexte à prix raisonnable : 1M tokens à 0,09 $ en entrée (Gemini 2.0 Flash est moins cher, mais limité à 8K en sortie)
Où DeepSeek V4 est en retrait
- Tâches agentiques complexes : Terminal-Bench 67,9 % contre 82,7 % pour GPT-5.5
- Travail multi-étapes sur le code : SWE-Bench Pro 55,4 % contre 64,3 % pour Claude Opus 4.7
- Multimodalité : pas d’analyse d’images intégrée (Claude, GPT, Gemini – en disposent)
- Communication : selon nos données, l’un des pires résultats parmi les modèles de tête pour les tâches de formulation de feedback
Apprenez à utiliser DeepSeek pour l'analytique et la validation de décisions
DeepSeek V4 avec le mode Think Max est un outil puissant pour identifier les risques dans les plans d'affaires et la modélisation financière. Notre cours montre comment utiliser une IA gratuite pour une analyse sérieuse – même si elle ne remplace pas votre outil principal.
Continuez votre apprentissage
Ouvrez le manuel et reprenez là où vous vous êtes arrêté
Application pratique pour un manager
- Traduire le technique en langage humain – résumer un rapport technique complexe en une note concise pour la direction.
- Vérifier la logique des décisions (Think Max) – chargez un business plan et demandez d’en identifier les failles. Le mode de raisonnement maximal repère des risques non évidents.
- Analyse de données – décrivez en mots ce que vous souhaitez extraire d’un fichier Excel, et DeepSeek rédige les formules ou le script.
- Travail avec des documents volumineux – chargez un règlement ou un rapport annuel (jusqu’à ~2 500 pages) et posez vos questions. Le contexte de 1M tokens accueille des bases de code entières ou des bases de connaissances d’entreprise.
- Accélérer l’équipe IT – rédaction de code, revue, tests et documentation. Classement Codeforces au niveau grand maître international.
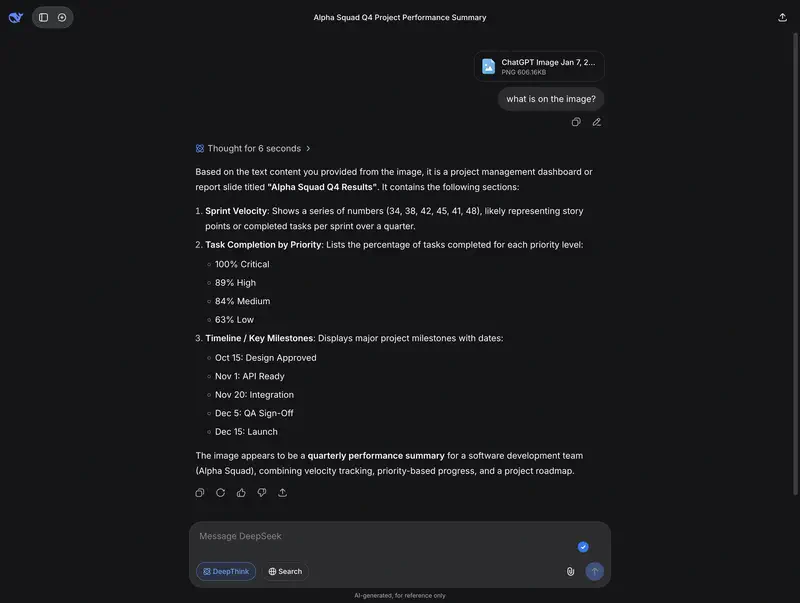
Essayez vous-même : analyse d’une décision risquée
Ci-dessous – un cas managérial avec des problèmes non évidents. Cliquez sur « Exécuter » et comparez comment l’ancien modèle (V3.2) et le nouveau (V4-Flash) gèrent la recherche de risques. Observez la profondeur du raisonnement et la précision des recommandations.
Ce qu’il faut observer dans les réponses :
- V4-Flash en mode réflexion construit une chaîne d’analyse et repère plus souvent des liens non évidents (baux + licenciements = risque réputationnel ; un pilote sur 2 boutiques n’est pas représentatif pour 40)
- V3.2 donne des réponses plus superficielles, manque souvent les interconnexions entre risques
- Kimi K2.5 structure généralement la réponse de façon plus détaillée, mais peut être excessif
Les benchmarks sont comparés. 9 tâches pratiques de manager montrent où votre approche flanche en pratique – gratuitement.
Sans paiement requis • Notification au lancement
Mise à jour : résultats du benchmark et DeepSeek sur Yandex Cloud (juillet 2026)
Dans notre benchmark de tâches managériales (42 modèles, 80 scénarios), DeepSeek V4 confirme son statut d’anomalie tarifaire sur le marché.
DeepSeek V4 Pro
0,43 $/0,87 $ pour 1M tokens (entrée/sortie). Pour 0,87 $ en tokens de sortie, DeepSeek offre une qualité pour laquelle ses voisins facturent 9 $ (Gemini 3.1 Pro) et 4,50 $ (GPT-5.4 Mini).
Pour qui : plans de déploiement de processus, scripts d’entretiens d’équipe difficiles, correspondance routinière en masse.
Pour qui pas : ROI et modèles financiers (erreurs de calcul systématiques), argumentaires juridiques, analyse de tarifs SaaS.
DeepSeek V4 Flash
0,09 $/0,18 $ pour 1M tokens. Se classe devant Gemini 3.1 Pro, tout en coûtant 130 fois moins cher (0,09 $ contre 12 $/M). Le cheval de bataille idéal pour les textes et les plans.
Pour qui : rapports hebdomadaires, classification de feedback, plans trimestriels et matrices de risques.
Pour qui pas : budgets et modèles financiers, droit international et RGPD, code d’automatisation.
DeepSeek sur Yandex Cloud : ça vaut le coup ?
Yandex propose DeepSeek V4 Flash via sa propre API. Le même modèle, mais des chiffres radicalement différents :
| Paramètre | DeepSeek en direct | Yandex Cloud | Différence |
|---|---|---|---|
| Prix input/1M | 0,09 $ | 3,00 $ | ×33 |
| Prix output/1M | 0,18 $ | 5,00 $ | ×28 |
| Résultat au benchmark | Légèrement supérieur | Légèrement inférieur | – |
Ce que vous payez : accès direct depuis la Russie sans VPN, SLA fourni par Yandex, hébergement des données en Russie, fenêtre de contexte de 1M tokens. Verdict : intéressant pour les équipes déjà sur Yandex Cloud qui automatisent des tâches sans budget IA dédié. Mais si le VPN n’est pas un problème, DeepSeek en direct est légèrement meilleur et 27 fois moins cher.
Générations précédentes
DeepSeek V3.2 (testé précédemment) – solide milieu de tableau supérieur. Particulièrement fort en planification et en résolution de problèmes. Lacune sérieuse – la communication : l’un des pires résultats parmi tous les modèles testés.
DeepSeek R1 – niveau comparable. Points forts – la recherche d’information et l’analytique, où le raisonnement par étapes apporte un avantage notable.
Résultats interactifs complets →
Analyse détaillée par catégorie – dans l’article sur les meilleurs outils IA pour managers.
Limites et risques
- Multimodalité limitée – le modèle principal V4 est textuel. L’analyse d’images est en bêta, la génération passe par Janus-Pro à basse résolution (384×384). Chez les concurrents (Claude, GPT, Gemini), la multimodalité est intégrée.
- Sécurité du contenu – les filtres de protection sont plus faibles que ceux de ChatGPT et Claude. Le modèle est plus facile à « convaincre » de générer du contenu indésirable.
- Confidentialité des données – l’entreprise est basée en Chine. Solution : télécharger le modèle (licence MIT) et le déployer localement – les versions distillées 7B et 14B de DeepSeek tournent sur un ordinateur portable standard.
- Moins d’intégrations prêtes à l’emploi – pas de plugins officiels pour CRM ou ERP. Mais le format d’API OpenAI et Anthropic est supporté – la plupart des outils fonctionnent via un adaptateur.
- Stabilité de l’API – aux heures de pointe, des latences et des défaillances surviennent. Pour les systèmes en production, il est recommandé d’utiliser des fournisseurs-proxy (DeepInfra, Together.ai, OpenRouter).
- Le chinois comme priorité – en russe, la qualité reste bonne. Selon nos données, DeepSeek V3.2 surpasse tous les modèles russes (dont Alice AI et GigaChat), même sur des tâches à spécificités russes.
Tarifs et accessibilité
| Modèle | Coût (pour 1M tokens) | Pour comparaison |
|---|---|---|
| DeepSeek V4-Flash | 0,09 $ entrée / 0,18 $ sortie | GPT-5.5 : 5 $ / 25–30 $ |
| DeepSeek V4-Pro | 0,435 $ entrée / 0,87 $ sortie | Claude Opus 4.7 : 5 $ / 25 $ |
- Accès gratuit – sur chat.deepseek.com, l’utilisation est gratuite, y compris le mode Deep Think.
- Open source (MIT) – tous les modèles sont disponibles au téléchargement, à l’usage commercial et à la modification sans restriction.
- Économie par mise en cache – les requêtes répétées coûtent 10 fois moins cher (0,014 $/1M pour Flash).
- Remise de 75 % sur V4-Pro, initialement annoncée comme temporaire, est devenue permanente en juin 2026. Les prix de 0,435 $/0,87 $ sont désormais standards.
- Heures de pointe – depuis la mi-juillet 2026, DeepSeek applique une tarification peak/off-peak : aux heures de forte charge, le prix peut dépasser le tarif standard.
Fait : DeepSeek V4-Flash coûte 97 % de moins que GPT-5.5 pour une qualité comparable sur les tâches standard. Pour une startup traitant 100M tokens par mois, le passage de Claude Opus à DeepSeek V4-Flash économise environ 2 400 $ par mois.
Ce qui a changé de V3 à V4
| Paramètre | DeepSeek V3.2 | DeepSeek V4-Pro |
|---|---|---|
| Contexte | 128K tokens | 1 000 000 tokens |
| Paramètres | 671B (37B actifs) | 1,6T (49B actifs) |
| Modes de réflexion | modèle R1 séparé | intégré (3 modes) |
| Licence | Custom open | MIT |
| Sortie max. | ~8K | 384K tokens |
| Compatibilité API | Format OpenAI | OpenAI + Anthropic |
| Puces | Nvidia H800 | Nvidia + Huawei Ascend |
Migration depuis les anciennes versions
Les anciens identifiants deepseek-chat et deepseek-reasoner sont redirigés vers V4-Flash et seront désactivés le 24 juillet 2026. Si vous utilisez l’API – mettez à jour vers deepseek/deepseek-v4-flash ou deepseek/deepseek-v4-pro.
Liens utiles
- Site officiel DeepSeek
- DeepSeek Chat – interface web gratuite
- Documentation API et tarifs
- Modèles sur Hugging Face
- Annonce V4 (rapport technique)
Cet article fait partie de la série « Revue des outils GenAI 2026 ». Tous les outils sont examinés avec des exercices pratiques dans le cours mysummit.school.











Stanislav Belyaev
Engineering Leader chez Microsoft18 ans a diriger des equipes d'ingenieurs. Fondateur de mysummit.school. 700+ diplomes chez Yandex Practicum et Stratoplan.