40 cas GigaChat de Sber : ce que dit vraiment notre benchmark

AI-модели в этой статье
Sber – la plus grande banque russe, qui développe aussi sa propre famille de modèles d’IA, GigaChat – a publié un dossier promotionnel : quarante études de cas d’entreprises ayant adopté GigaChat et qui en détaillent les bénéfices. EdTech, MedTech, HRTech, cybersécurité, PropTech. De jolies fiches, des chiffres précis, de vraies startups.

Sur l’image : le visuel « Un pas en avant » de l’accélérateur Sber500×GigaChat – 40 startups dans 9 secteurs. Effets annoncés : processus jusqu’à x16 plus rapides, coûts réduits jusqu’à 90 %, automatisation des tâches jusqu’à 95 %, chiffre d’affaires en hausse jusqu’à 30 %.
Nous disposons d’un benchmark : 29 modèles, 4 308 évaluations indépendantes sur des tâches managériales. GigaChat y occupe la dernière place, 29e sur 29 à l’issue de la deuxième vague de tests. Cela crée une situation intéressante.
Non pas parce que Sber mentirait. Les cas sont réels, les startups existent, l’automatisation fonctionne. La vraie question est ailleurs : était-ce le modèle optimal pour les tâches que ces entreprises devaient résoudre ?
D’où viennent ce genre de cas
Le matériel promotionnel de Sber relève d’un genre bien identifié : la vendor-sponsored case study. Une entreprise raconte ses succès avec un outil précis, le fournisseur publie et fait la promotion. C’est une pratique tout à fait normale – ainsi fonctionnent toutes les grandes entreprises d’IA, de Microsoft à Anthropic.
Le problème, c’est qu’une étude de cas commanditée répond à la question « est-ce que la solution fonctionne ? » – mais pas à la question « est-ce la solution optimale ? ». Une entreprise qui a déployé un chatbot sur GigaChat et économisé 40 % du temps de ses opérateurs décrit honnêtement le résultat. Mais elle n’a pas mené d’A/B test avec Qwen 3.6 Flash – parce qu’aucune entreprise réelle ne lance un appel d’offres complet entre tous les modèles avant chaque projet.
C’est précisément pour cela que les benchmarks indépendants existent.
Ce que montre notre benchmark
Nous avons testé des modèles d’IA sur huit catégories de tâches managériales – de l’analyse de données et la recherche d’information à la planification et au travail d’équipe. Méthodologie : deux juges LLM indépendants, calibrés sur des évaluations humaines. Pour le détail de comment fonctionnent les benchmarks et pourquoi il faut leur faire confiance avec prudence.
Sber dispose aujourd’hui de deux gammes principales : GigaChat 2 Max et GigaChat Ultra. Il ne faut pas les confondre – ce sont deux modèles distincts, de niveaux de qualité différents.
Le fleuron de la gamme, c’est GigaChat Ultra. L’API est accessible aux clients entreprises sous contrat dédié ; pour les développeurs individuels, uniquement via l’interface web gigachat.ru. Dans notre benchmark, il occupe la place 28 sur 29 avec une note de 4,83 – le meilleur résultat parmi tous les modèles russes de notre test.
Le modèle principal à API publique, c’est GigaChat 2 Max, et c’est lui qu’utilisent la plupart des startups des cas. Place 29 sur 29, note 4,20. Lors de la première vague, ce même modèle obtenait 3,08 – le progrès en quelques mois est notable.
C’est une distinction importante. La majorité des startups des cas passent par l’API publique – donc par GigaChat 2 Max. Celles qui ont obtenu un accès entreprise à Ultra travaillent avec un modèle plus puissant – mais aussi à un autre prix. Voyons comment GigaChat 2 Max se débrouille sur les tâches des cas.
| Catégorie de tâches | GigaChat 2 Max | GigaChat Ultra |
|---|---|---|
| Recherche d’information | 29 / 29 (3,87) | 28 / 29 (4,71) |
| Analyse et décisions | 29 / 29 (4,39) | 28 / 29 (5,44) |
| Planification | 29 / 29 (4,33) | 28 / 29 (5,92) |
| Résolution de problèmes | 28 / 29 (4,27) | 29 / 29 (4,25) |
| Connaissance régionale | 29 / 29 (3,57) | 28 / 29 (3,98) |
| Communication | 28 / 29 (4,74) | 29 / 29 (4,74) |
| Travail d’équipe | 29 / 29 (4,41) | 28 / 29 (5,16) |
| Formation et développement | 29 / 29 (4,00) | 28 / 29 (4,48) |
Les deux modèles de Sber occupent les deux dernières places du benchmark, mais l’écart de note entre eux est sensible : Ultra obtient 5,92 en planification, Max seulement 4,33. Ultra n’est accessible par API qu’aux clients entreprises, Max via l’API publique. La plupart des startups des cas travaillent avec Max.
Quarante cas : quelles tâches au juste
J’ai lu les quarante fiches. Les tâches se regroupent en quelques grandes familles.
Environ un tiers : chatbots et traitement des demandes entrantes. Une compagnie d’assurance a automatisé les réponses aux requêtes clients, un service médical a créé un assistant de prise de rendez-vous, une banque a déployé un assistant de support. C’est une tâche réelle et bien gérée par n’importe quel LLM suffisamment solide.
Autre grand groupe : génération de texte et de documents – supports marketing, descriptifs de biens immobiliers, documentation RH. Une entreprise HRTech a automatisé la rédaction de fiches de poste, une startup PropTech les descriptifs d’appartements, une plateforme MarTech les textes publicitaires pour différents segments.
Ensuite commence le terrain où les données du benchmark posent question. Analyse de documents et de données – tri de CV, dossiers médicaux, classification de requêtes. Plusieurs cas en cybersécurité : analyse de menaces, classification d’incidents, génération de rapports. Et à part, des tâches sectorielles spécifiques comme un assistant IA pour les entretiens RH ou des systèmes de recommandation pour l’EdTech.
Où les données du benchmark contredisent le marketing
Prenons trois cas de catégories différentes et regardons-les à travers les données.
L’un des cas EdTech : automatiser l’analyse de cas cliniques pour la formation des étudiants en médecine. La tâche exige une exactitude factuelle, des références sourcées correctes, l’absence d’hallucinations.
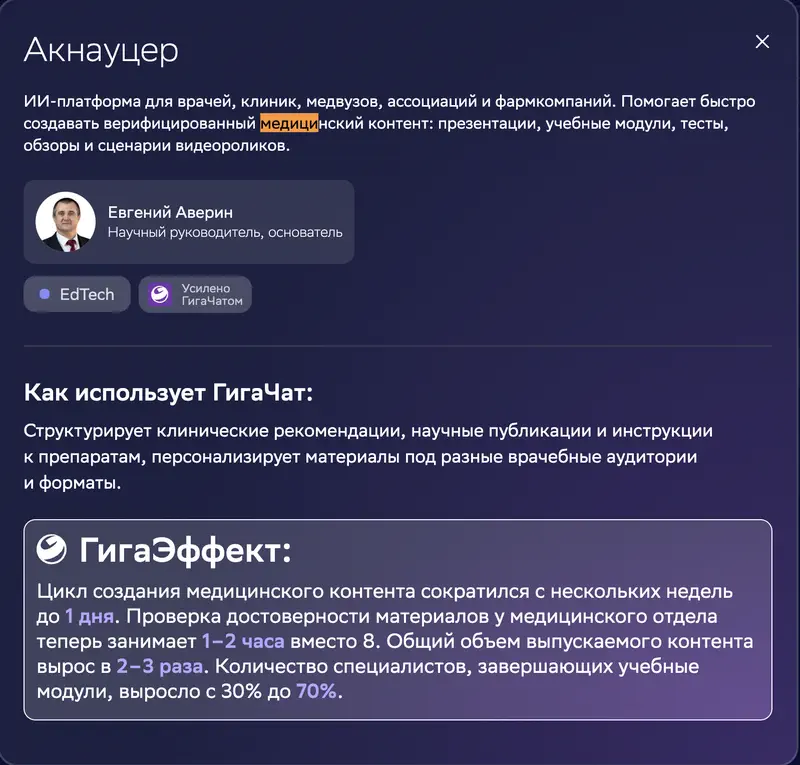
Sur la fiche du cas : Aknaucer, une plateforme IA pour la médecine. « GigaEffet » annoncé : cycle de création de contenu réduit de plusieurs semaines à 1 jour, vérification des faits de 8 heures à 1–2, volume produit multiplié par 2–3, et part des spécialistes terminant les modules de formation en hausse de 30 % à 70 %.
Notre benchmark, catégorie « recherche d’information » : GigaChat 2 Max à la dernière place, 29e sur 29. La faiblesse précise relevée dans la description : « trouve la bonne direction d’analyse, mais invente des prix d’outils, des références d’études et des normes juridiques – l’utiliser sans revérifier chaque fait est dangereux ».
Le cas est bien réel. Mais une entreprise qui ne revérifie pas chaque conclusion du modèle s’appuie sur le modèle classé dernier en exactitude parmi les 29 disponibles.
Plusieurs entreprises MarTech décrivent l’automatisation de la génération de supports publicitaires. Communication – 28e place sur 29, la catégorie la moins faible de GigaChat. Pour des textes simples et formatés, cela peut suffire.
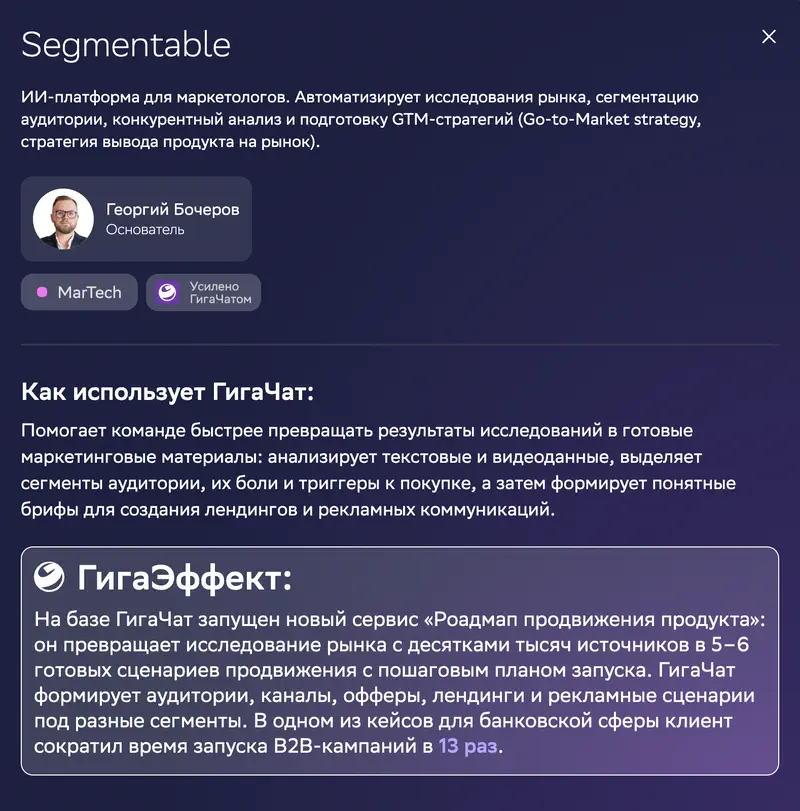
Sur la fiche du cas : Segmentable, une plateforme IA pour le marketing. « GigaEffet » annoncé : son service « feuille de route de promotion produit » transforme une étude de marché aux dizaines de milliers de sources en 5–6 scénarios de lancement prêts à l’emploi ; dans un cas bancaire, le client a divisé par 13 le temps de lancement des campagnes B2B.
Plus intéressant : la cybersécurité. L’un des cas décrit un système de classification d’incidents de sécurité et de génération de rapports de menaces. La tâche suppose une analyse précise, des conclusions concrètes, des recommandations applicables.
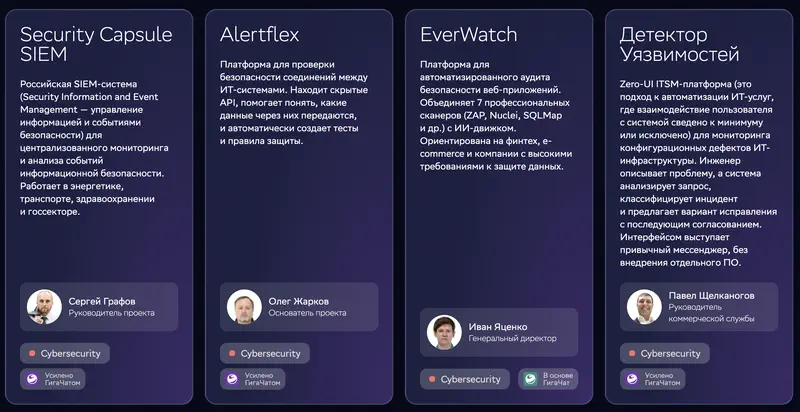
Sur l’image : quatre produits de cybersécurité basés sur GigaChat. Security Capsule SIEM – un SIEM russe pour la surveillance centralisée de la sécurité ; Alertflex – vérifie les échanges de données entre systèmes informatiques via API et génère automatiquement des règles de protection ; EverWatch – audit automatisé d’applications web combinant 7 scanners (ZAP, Nuclei, SQLMap) avec un moteur IA ; Détecteur de vulnérabilités – une plateforme ITSM Zero-UI où l’ingénieur décrit un problème dans une messagerie et le système classe l’incident et propose une correction.
Notre benchmark, catégories « analyse et décisions » et « résolution de problèmes » : 29e et 28e place sur 29. Description : « identifie correctement la direction générale de la solution, mais ne fournit ni critères pondérés, ni analyse de scénarios, ni recommandations concrètes – il reformule en réalité l’énoncé du problème ».
Un rapport de classification d’incidents rédigé par le modèle classé 29e en analyse sur 29 disponibles – c’est de l’automatisation de la production d’un document. L’analyse des menaces, elle, reste à la charge de l’humain. La différence est de taille.
Le paradoxe de la note absolue et de la note compétitive
Il y a ici une nuance importante à saisir, parce qu’elle est contre-intuitive.
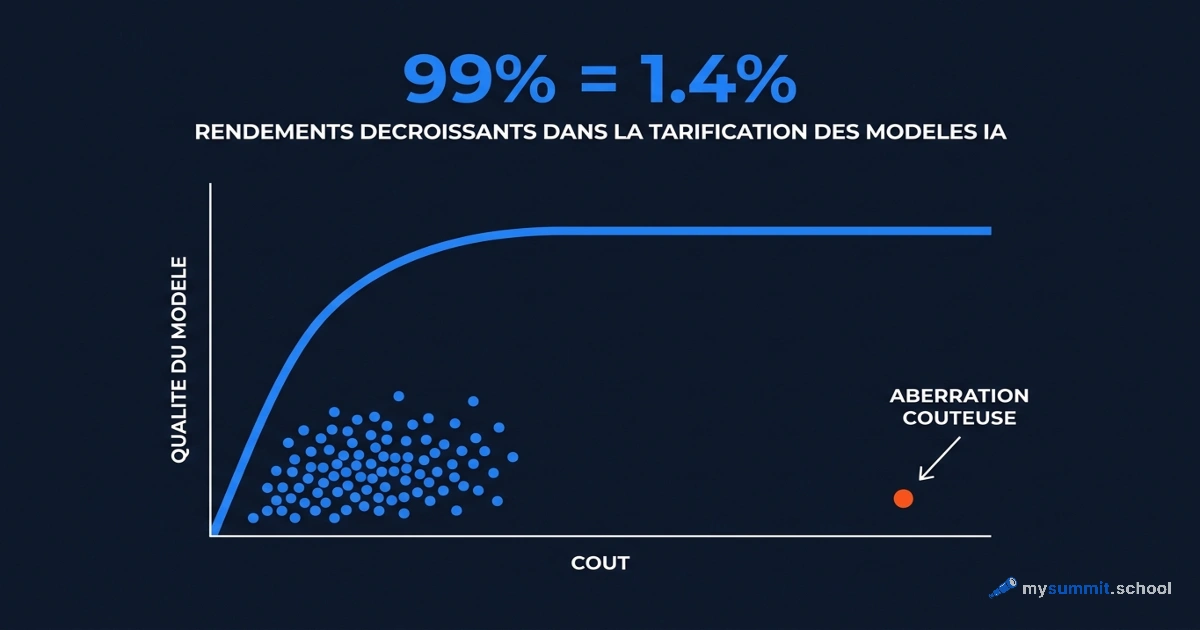
GigaChat 2 Max obtient 4,20 sur 10 – en dessous du milieu de l’échelle. Mais même la note absolue rend mal compte de la compétitivité réelle. Notre expérience sur les techniques de prompt l’a montré : même les meilleures techniques de prompting ne comblent pas l’écart entre un modèle faible et un modèle fort. GigaChat et Alice, avec des prompts optimaux, perdaient quand même face à GPT-5.4 et Claude alimentés de requêtes naïves. La version v2 est devenue plus solide – mais le principe demeure : la note absolue surestime la compétitivité.
Nous avons disséqué cet effet en détail dans l’article « Pourquoi les benchmarks d’IA mentent ». Les notes sur l’échelle s’accumulent près de la moyenne, et un petit écart de points correspond à un grand écart de fréquence de victoire. Quand Qwen 3.6 Flash obtient 7,60 dans notre benchmark contre 4,20 pour GigaChat 2 Max – on ne parle pas de « 80 % de mieux ». On parle du fait qu’en comparaison directe, Qwen l’emporte dans l’écrasante majorité des cas.
C’est pour cela que « fonctionne » et « optimal » sont deux choses différentes.
Évaluer un résultat sur des tâches réelles, comprendre quand un résultat est bon et quand il en a seulement l’air – c’est tout l’objet du module ouvert du cours. Neuf scénarios managériaux, chacun avec un piège non évident, sans inscription.
Dans les 40 cas de Sber, il n'y a aucun A/B test avec des modèles alternatifs. Dans le module ouvert : 9 tâches où vous évaluez vous-même les résultats et apprenez à distinguer ce qui fonctionne de ce qui est optimal. Gratuit.
Sans paiement requis • Notification au lancement
Un cas au microscope : ESME AI et la documentation projet
Les notes abstraites du benchmark ne montrent pas à quoi ressemble concrètement l’écart entre modèles. L’un des quarante cas permet de le voir – et au passage de comprendre où les données du benchmark s’appliquent directement et où il faut les lire avec prudence.
ESME AI – un outil pour promoteurs et entreprises générales du BTP. Une plateforme de prises de vue à 360° des chantiers, avec un assistant IA intégré. GigaChat aide à travailler avec la documentation projet et d’exécution : l’utilisateur pose une question en langage courant, l’assistant retrouve l’information dans les plans, les spécifications et les règlements. Effet annoncé : « la recherche d’information sur un projet est passée de plusieurs dizaines de minutes à quelques minutes, la prise de décision s’est accélérée de 30 à 50 % ».
La tâche est réelle. Quiconque a travaillé sur un chantier connaît cette douleur : un projet moyen, c’est des centaines, parfois des milliers de feuilles par lot (architecture, structure, CVC, plomberie, électricité), plus les spécifications, les métrés, les données générales et la couche normative (Eurocodes, DTU, normes). La question « quelle classe de béton est prévue au projet pour le plancher du 3e étage ? », c’est dix à quarante minutes à feuilleter. Le passage « de dizaines de minutes à quelques-unes » est crédible – si la recherche fonctionne vraiment.
Pourquoi le benchmark n’est ici qu’un proxy faible
Il faut être honnête avec ses propres données. Notre benchmark mesure le raisonnement managérial : analyser une situation, planifier, conclure. La recherche dans de la documentation fonctionne autrement. C’est une tâche de type RAG (retrieval-augmented generation) : le système extrait d’abord le bon fragment d’un PDF réel du projet, et le modèle en tire la réponse – pas de la « mémoire » accumulée à l’entraînement.
Cela change la donne. La faiblesse signature de GigaChat – « invente des références d’études et des normes juridiques » – est une défaillance de génération à partir des données d’entraînement. Quand le modèle répond strictement d’après le fragment de plan fourni, cette défaillance est étouffée. La 29e place en « recherche d’information » est donc un proxy faible pour la question « l’assistant trouvera-t-il la bonne classe de béton ». Sur un RAG bien construit, même un modèle faible se comporte plus convenablement qu’en génération libre.
Ce qui casse réellement ce genre d’automatisation
Le problème, c’est que pour la documentation de construction, les principaux risques ne se situent pas là où le benchmark les mesure – et certains sont plus dangereux que des hallucinations ordinaires.
La première chose qui casse un tel système en pratique, c’est la lecture même du plan. Les plans sont des PDF vectoriels ou des DWG : du texte dans les cartouches, les annotations, les lignes de cote, les hachures et les tableaux intégrés. Les systèmes de reconnaissance universels y butent, et si le parsing s’est trompé, le modèle répond avec assurance sur un texte corrompu. Les spécifications et les métrés sont des tableaux multipages à cellules fusionnées, et la plupart des erreurs « pas la bonne valeur » naissent ici, et non dans les hallucinations.
Ensuite : la réponse se trouve rarement sur une seule feuille. « La classe de béton du plancher du 3e étage », c’est un assemblage : plan -> coupe -> spécification -> prescriptions générales sur les feuilles de structure, parfois une feuille séparée. Pour reconstituer la réponse, il faut parcourir des documents hétérogènes. C’est exactement là que l’assistant renvoie discrètement une valeur plausible mais fausse.
Il y a aussi un risque moins évident : le versionnage. La documentation est vivante : modifications, avenants, tampons « bon pour exécution », lignes rouges. Si une révision périmée s’est glissée dans l’index, l’assistant délivrera avec assurance une valeur annulée – avec une référence à une feuille réelle, mais ancienne. C’est plus dangereux qu’une hallucination : ça paraît autoritaire et vérifiable.
Enfin, le coût de l’erreur et la traçabilité. Un ingénieur ne peut pas agir sur la réponse « B25 » sans l’indication du lot, de la feuille et de la position dans la spécification. Une erreur sur la classe de béton ou d’armature, c’est un défaut de structure. Et si l’assistant ne transforme pas la vérification en un coup d’œil de trois secondes vers la source, le gain de temps s’évapore : pour faire confiance à la réponse, il faudra de toute façon retrouver la source manuellement.
Là où le benchmark reste pertinent
La tâche d’ESME a deux couches. La première – l’extraction du fait : c’est une affaire de qualité du pipeline, voir plus haut. La seconde – l’analyse et la synthèse : « évalue les risques sur ce nœud », « compare deux solutions ». L’écart entre classes de modèles se voit ici directement, et le benchmark le capte.
Nous n’avons pas accès aux prompts précis d’ESME AI, mais la couche analytique d’une telle tâche est exactement ce que nous avons testé dans l’expérience sur les techniques de prompt. Prenons un scénario comparable – une analyse business à partir de données concrètes.
La tâche de l’expérience :
Boutique en ligne d’électronique, 45 salariés. Au dernier trimestre, le chiffre d’affaires a chuté de 18 %, alors que le trafic du site a augmenté de 12 %. Le panier moyen est tombé de 8 700 à 6 200 €. Les retours sont passés de 4 % à 11 %. Le budget publicitaire a été augmenté de 30 %. Que se passe-t-il et que faire ?
Tous les modèles ont reçu le même prompt, sans aucune technique.
GigaChat 2 Max (29e place, note 3,02) a produit 53 lignes de texte. Six « causes possibles », six blocs de recommandations : « réaliser une analyse de la qualité produit », « améliorer la logistique et la livraison », « monter en compétence les salariés ». Aucun chiffre concret de l’énoncé dans l’analyse. Aucune priorisation. Conclusion : « il faut aborder le problème de manière globale ».
Pour ESME AI, cela signifie : sur la couche analytique, le modèle dira « il faut vérifier la spécification », mais ne construira sans doute pas de priorités et ne tirera pas de conclusion substantielle de ce qu’il a trouvé.
Alice AI LLM (YandexGPT – le modèle de Yandex, le « Google russe » – note 3,85) s’en est nettement mieux sortie : une structure apparaît – « analyse ABC de l’assortiment », « parseurs de prix », « test d’utilisabilité du tunnel », un bloc « priorités à court terme sur 2 semaines ». Mais la priorisation reste plate et le calendrier de gestion de crise n’est pas détaillé.
GPT-5.4 (1re place, note 4,38) a démarré autrement – par un calcul : « le panier moyen a baissé d’environ 29 % ». Le modèle a calculé, au lieu de reformuler l’énoncé. Ensuite : un plan anti-crise sur 10 jours avec des rôles pour chacune des 45 personnes, des hypothèses hiérarchisées et une liste d’actions « pour demain matin ».
Trois niveaux – trois classes de résultat :
| Modèle | Calcule les chiffres de l’énoncé ? | Priorise les hypothèses ? | Donne un plan opérationnel ? | Exactitude factuelle |
|---|---|---|---|---|
| GigaChat 2 Max | Non | Non | Conseils génériques | 58,9 % |
| Alice AI LLM | En partie | Non | Priorités, mais sans calendrier | 75,0 % |
| GPT-5.4 | Oui (panier -29 %) | Oui (par probabilité) | Plan sur 10 jours avec rôles | 83,9 % |
L’exactitude factuelle du tableau provient de l’expérience d’analyse business, où le modèle génère sa réponse seul, sans documents joints. Cela ne veut pas dire que l’assistant ESME se trompera sur 41 % des requêtes aux plans : en recherche grounded avec citations, le tableau est différent. Mais le chiffre révèle la classe. Là où « analyse de documentation » signifie non pas seulement retrouver une ligne, mais calculer, prioriser et assembler une conclusion, GigaChat 2 Max reste au niveau des conseils génériques.
En comparaison directe dans l’expérience, GigaChat 2 Max avec la meilleure technique de prompting ne l’emportait sur GPT-5.4 que dans 4 % des cas. Alice AI LLM – dans 28 à 36 %. À 4 % de victoires, l’écart n’est plus dans les nuances mais dans la classe même de tâches que le modèle est capable de résoudre.
Changer de modèle ici en vaut la peine : les deux alternatives russes – Alice AI LLM et DeepSeek V4 Flash – sont disponibles dans Yandex Cloud pour les entreprises russes. DeepSeek V4 Flash occupe la 12e place de notre benchmark (7,34 points) et coûte 0,20 $ / 0,60 $ par million de tokens – 12 fois moins cher que GigaChat pour une qualité nettement supérieure. Mais honnêtement : changer de modèle répare la couche analytique et réduit les hallucinations, alors que les principaux risques de chantier – parsing des plans, versionnage, traçabilité – vivent dans le pipeline, et aucun modèle ne les couvrira.
Comment rendre un tel assistant fiable
Si l’on veut construire ce produit sérieusement, l’ordre des priorités est à peu près le suivant.
Le plus grand gain de fiabilité : structurer les données plutôt que de chercher dans des PDF. Parser une bonne fois pour toutes les spécifications et les métrés dans une base vérifiée par un humain (élément -> matériau -> classe -> feuille -> révision). Alors « la classe de béton du plancher du 3e étage » devient une requête ponctuelle à une base de données, et non une recherche floue dans du texte.
Chaque réponse doit contenir une citation : lot, feuille, position – et le fragment de plan affiché. La vérification se réduit à un regard, et c’est seulement à cette condition que le gain de temps est réel.
Il faut séparer recherche et génération. L’extraction des fragments – sur des embeddings et un reranker ; le modèle – uniquement sur l’extraction finale de la réponse, avec une instruction stricte : « réponds strictement d’après le contexte, sinon dis ’non trouvé’ ». C’est précisément cela qui rend le choix d’un modèle plus fort réellement pertinent.
Il faut une couche de versions : l’assistant répond « selon la révision telle » et prévient s’il existe une version plus récente pour la feuille.
Pour les requêtes critiques – classe de béton, armature, résistance au feu – l’assistant doit avoir le droit de dire « je ne sais pas » : soit une citation exacte, soit un refus. « Non trouvé » est une fonctionnalité, pas un bug.
L’atout unique d’ESME, c’est le couplage des prises de vue à 360° avec la documentation. Le pas de « chercher dans les documents » vers « comparer le réel (la prise de vue 360°) au projet » : écarts, taux d’avancement, défauts. C’est ce pas qui répond à la véritable mission du contrôle de chantier et dépasse la simple accélération de la recherche.
Et enfin – tester sur ses propres documents. Cent requêtes réelles aux réponses vérifiées et la mesure de trois métriques : exhaustivité de la recherche, exactitude des citations, part de révisions périmées. Un benchmark universel ne dira pas à ESME si leur pipeline est sûr – seul un tel test le montrera.
Si vous n’avez pas le choix : comment améliorer le résultat de GigaChat
Admettons que vous travailliez dans une organisation où GigaChat est le seul outil autorisé. Déploiement on-premise, contrat entreprise, exigences de sécurité. Que peut-on faire ?
Notre expérience sur les techniques de prompt a testé dix approches sur GigaChat 2 Max – du cadrage par rôle au balisage XML et à la chaîne de raisonnement.
Le meilleur résultat est venu de la technique n°4 – le few-shot : 89 % de victoires sur le prompt naïf. Vous prenez un exemple de réponse de qualité sur une tâche proche (mais différente) et l’ajoutez au prompt, avant votre question. Le modèle se cale sur l’exemple – et produit une réponse structurée et concrète au lieu de formules génériques.
Sur la même tâche de boutique en ligne, GigaChat 2 Max avec un exemple few-shot a produit un autre résultat : au lieu d’énumérer six catégories générales – un diagnostic structuré renvoyant aux chiffres concrets de l’énoncé (« chute du panier moyen de 8 700 à 6 200 € »), un calendrier de recommandations (cette semaine / 2-3 semaines / d’ici un mois) et une section « Ce que nous ne savons pas encore ».
Données pour GigaChat 2 Max issues de l’expérience :
| Technique | Note (sur 5) | Gain par rapport à la base | Victoires vs prompt naïf |
|---|---|---|---|
| T0 (sans technique) | 3,02 | – | – |
| T4 (few-shot) | 3,63 | +20 % | 89 % |
| T2 (sortie structurée) | 3,43 | +14 % | 82 % |
| T10 (XML + Markdown) | 3,59 | +19 % | 78 % |
| T3 (chaîne de raisonnement) | 3,55 | +18 % | 79 % |
Mais voici la réserve importante : GigaChat 2 Max avec la meilleure technique (3,63) reste quand même en dessous de Qwen 3.6 Flash (7,60) ou DeepSeek V4 Pro (7,75) sans aucune technique. Le prompt engineering ne comble pas l’écart architectural – il rend un modèle faible tolérable, mais pas compétitif.
Reste la question de la source de l’exemple. La voie la plus pratique : faire passer une fois la tâche par un modèle fort (DeepSeek V4 Flash est gratuit en interface web, Kimi K2.6 est accessible sans VPN), sauvegarder le résultat et l’utiliser comme exemple pour GigaChat sur des tâches similaires. Ce n’est pas du « plagiat » – c’est de la calibration.
Les alternatives disponibles en Russie
C’est sans doute la partie la plus concrète de ce dossier. Si une entreprise d’un cas de Sber résout des tâches de notre liste, quels autres modèles lui sont accessibles – et que dit le benchmark ? Une comparaison détaillée des outils par tâche est dans la revue des outils GenAI pour le manager.
Tous les modèles listés ci-dessous fonctionnent sans VPN, sont accessibles par API et présents sur le marché russe.
| Modèle | Place (sur 29) | Note | Coût (entrée/sortie, $/M tokens) |
|---|---|---|---|
| MiMo v2.5 Pro | 3 | 8,37 | 1 $ / 3 $ |
| Kimi K2.6 | 5 | 8,27 | 0,74 $ / 3,49 $ |
| Qwen 3.6 Plus | 7 | 7,94 | 0,33 $ / 1,95 $ |
| MiMo v2.5 | 8 | 7,82 | 0,40 $ / 2 $ |
| DeepSeek V4 Pro | 10 | 7,75 | 0,43 $ / 0,87 $ |
| Qwen 3.6 Flash | 14 | 7,60 | 0,25 $ / 1,50 $ |
| MiniMax M2.7 | 15 | 7,58 | 0,30 $ / 1,20 $ |
| GigaChat 2 Max | 29 | 4,20 | 7,22 $ / 7,22 $ |
L’écart de prix est un point important, que nous avons analysé dans notre étude sur la « prime premium » des modèles d’IA. GigaChat 2 Max coûte 7,22 $ par million de tokens en entrée comme en sortie. Qwen 3.6 Flash – 0,25 $ en entrée et 1,50 $ en sortie. Pour une charge de pointe de 10 millions de tokens en entrée et autant en sortie : GigaChat reviendra à environ 144 $, Qwen 3.6 Flash à environ 17,50 $. Le tout sachant que Qwen occupe la 14e place contre la 29e.
Le faible coût n’est pas un argument en soi. GigaChat a un vrai avantage – le déploiement on-premise. Pour les banques, les administrations, les entreprises de défense, où les données ne peuvent pas quitter le périmètre interne – c’est le seul choix possible. Nous en avons parlé dans notre guide pratique de GigaChat. Mais pour les startups des cas, qui travaillent dans le cloud – l’avantage est sans objet.
Cinq questions à poser à tout fournisseur d’IA
Ce n’est pas seulement une affaire Sber. Microsoft publie des cas Copilot, Anthropic des cas Claude, Google des cas Gemini. Le format est le même. Les questions doivent l’être aussi.
Commencez par le plus simple : quelle tâche précise est automatisée – et relève-t-elle des points forts du modèle ? Un chatbot pour des questions simples fonctionne sur n’importe quel modèle. L’analyse de documents médicaux ou de risques juridiques – non.
Deuxième question : les métriques. « 40 % de temps en moins » sonne bien. Mais 40 % de quoi ? Si l’opérateur passait 20 minutes par réponse et n’en passe plus que 12, le gain est réel. Si le modèle produit un brouillon en 30 secondes mais que le relecteur passe 15 minutes à corriger, l’efficacité est tout autre. Et qu’en serait-il sans IA du tout ?
Un test avec des modèles alternatifs a-t-il été mené ? Presque jamais. C’est compréhensible : l’entreprise résout un problème business, elle ne fait pas de tests comparatifs. Mais l’absence d’A/B test signifie que « GigaChat nous a permis de » se lit plus justement comme « avec GigaChat, nous avons réussi à » – sans affirmer que d’autres modèles auraient fait pire.
Sujet à part : la revérification. Si la tâche exige des données exactes (références factuelles, citations juridiques, conclusions médicales) et qu’il n’y a pas de contrôle systématique de chaque conclusion – c’est un risque. La question n’est pas de savoir si le modèle hallucine parfois. La question est de savoir combien d’erreurs passeront entre les mailles du filet et quel est leur coût.
Et enfin : que se passe-t-il dans les cas limites ? La plupart des produits d’IA fonctionnent bien sur les requêtes typiques. Ce qui est intéressant, c’est le comportement sur l’atypique – une région rare, une situation non standard, un cas-limite juridique. C’est précisément là que l’écart entre la 3e et la 29e place se manifeste le plus fortement.
Cliquez sur « Lancer » et comparez les réponses. Observez la précision : le modèle nomme-t-il de vrais standards et de vraies métriques de sécurité, ou se limite-t-il à des formules générales ? C’est précisément là que se révèle l’écart entre la 5e et la 29e place du benchmark.
Un aveu honnête : le progrès est réel
GigaChat 2 Max à la dernière place – mais il faut le comprendre en dynamique. Lors de la première vague de tests, la même gamme obtenait 3,08. Aujourd’hui, 4,20. Une hausse de 36 % en quelques mois – c’est un progrès qualitatif significatif, même si la position au classement reste la dernière.
Le travail d’ingénierie de Sber est perceptible. Si le rythme se maintient, dans un an ou deux, GigaChat pourrait se retrouver dans la moitié supérieure du tableau. C’est une question ouverte, et il est dans l’intérêt des utilisateurs russes que la réponse soit positive.
Les quarante startups des cas font, elles aussi, un vrai travail. L’automatisation sur GigaChat fonctionne pour beaucoup d’entre elles. Pour une partie des tâches – surtout celles liées à la correspondance professionnelle et aux chatbots simples – le choix est raisonnable. Pour d’autres, les données du benchmark posent la question de l’optimalité.
Il est possible qu’une partie d’entre elles aient choisi GigaChat pour des raisons non techniques : contrat entreprise déjà en place avec Sber, exigences de sécurité, pression de la direction. Ce sont aussi des considérations réelles, que le benchmark ne prend pas en compte.
La vraie question est ailleurs : au moment de prendre une décision technique sur le choix d’un modèle – que vérifiez-vous ?
Distinguer « le modèle a donné un résultat plausible » de « le modèle a donné un résultat juste » est une compétence qui ne se forge que sur des tâches concrètes. C’est exactement ce qui se travaille dans le module ouvert du cours : neuf scénarios managériaux où l’écart entre « ça sonne convaincant » et « c’est juste » n’a rien d’évident.
Quarante cas sans A/B test, c'est la norme du marketing fournisseur. Dans le module ouvert, vous travaillez la compétence d'évaluation des résultats sur 9 tâches managériales. Gratuit, sans inscription.
Sans paiement requis • Notification au lancement
Que faire de cette information
Si vous utilisez GigaChat – surtout en format on-premise ou Enterprise – ce n’est pas un argument pour basculer dès maintenant. Il y a des tâches où le modèle fonctionne convenablement. Il y a des situations où l’on n’a pas le choix.
L’action utile : comprendre dans quelles tâches vous vous appuyez sur l’exactitude de GigaChat, et quel niveau de revérification est intégré chez vous. Notre revue détaillée de GigaChat et notre test de GigaChat Ultra Thinking montrent les situations précises où le modèle se trompe le plus souvent : recherche d’information, normes juridiques, données régionales.
Si vous prenez une décision sur le choix d’un modèle pour un nouveau projet – les données du benchmark et les cinq questions ci-dessus vous donnent une structure. Le classement complet des 29 modèles, ventilé par catégorie, est sur la page de notre recherche.
Si vous lisez le prochain cas fournisseur – peu importe qu’il vienne de Sber, de Microsoft ou d’Anthropic – posez les mêmes cinq questions. Les réponses, en général, ne sont pas dans le texte du cas.
Des cas à l'évaluation autonome
Le troisième chapitre du cours décortique huit outils d'IA avec des données : ce que chacun sait faire, où il hallucine, pour quelles tâches il est optimal. Des résultats de tests sur des tâches managériales, et non une reprise du marketing.



Stanislav Belyaev
Engineering Leader chez Microsoft18 ans a diriger des equipes d'ingenieurs. Fondateur de mysummit.school. 700+ diplomes chez Yandex Practicum et Stratoplan.