GigaChat Ultra Thinking : il reflechit plus longtemps – et repond moins bien ?

GigaChat Ultra Thinking reflechit plus longtemps et consomme davantage de ressources de calcul. Il resout les taches manageriales 3,3 % moins bien que la version sans raisonnement. Ce n’est ni un bug ni un hasard – c’est un schema documente par des travaux academiques au cours des deux dernieres annees.
Cette semaine, Sber a presente GigaChat Ultra – son nouveau modele phare avec un mode raisonnement (Thinking). Le modele est disponible gratuitement dans la version web, les applications mobiles et via le bot Telegram. Nous avons immediatement ajoute les deux variantes a notre etude des modeles IA pour managers : nous les avons fait passer a travers les 32 scenarios selon notre methodologie unifiee, evalues par nos deux juges LLM, et compares aux 52 autres modeles.
Avertissement important. Au moment du test, GigaChat Ultra n’etait pas disponible via API – uniquement via le chat web. Cela signifie que nous ne pouvions pas controler la temperature, le prompt systeme et d’autres parametres. Nous avons utilise le modele exactement comme le ferait un utilisateur ordinaire. Les conditions sont identiques pour Ultra et Ultra Thinking, mais different des autres modeles de l’etude, qui ont ete testes via API.
Resultats : vue d’ensemble
GigaChat Ultra a obtenu 3,04 points sur 5,0 (moyenne sur 32 scenarios). GigaChat Ultra Thinking – 2,94.
Le mode raisonnement a degrade le resultat de 0,10 point – soit moins 3,3 %.
Pour contexte : le precedent modele phare GigaChat 2 Max obtenait 3,08. Ultra est reste essentiellement au meme niveau. Avec le mode raisonnement – meme legerement en dessous.
| Modele | Score moyen | Mediane |
|---|---|---|
| GigaChat Ultra | 3,04 | 2,85 |
| GigaChat Ultra Thinking | 2,94 | 2,90 |
| GigaChat 2 Max (precedent) | 3,08 | — |
L’ecart avec les leaders reste considerable. Kimi K2.5 – 4,74, Qwen3.5 Plus – 4,56, DeepSeek V3.2 – 4,42. GigaChat Ultra se situe 1,4 a 1,7 points en dessous.
Par categorie : ou reflechir aide, et ou cela nuit
Nous avons teste les modeles dans 8 categories de taches manageriales, avec 4 scenarios par categorie. Voici la ventilation.
Ou Thinking a aide
| Categorie | Ultra | Thinking | Difference |
|---|---|---|---|
| Planification et productivite | 3,11 | 3,83 | +0,72 |
| Resolution de problemes | 3,08 | 3,26 | +0,18 |
| Management d’equipe | 2,81 | 2,95 | +0,14 |
Le meilleur resultat de Thinking – sur une tache d’analyse des parties prenantes : Ultra a obtenu 2,25 (classification erronee des sentiments, contradictions internes dans la reponse), tandis que Thinking a obtenu 4,00 (analyse correcte du ton, structure appropriee). Difference – 1,75 point sur un seul scenario.
Schema : Thinking aide dans les taches ou il faut prendre en compte plusieurs facteurs simultanement – positions des parties prenantes, risques lies au recrutement, scenarios de negociation.
Ou Thinking a nui
| Categorie | Ultra | Thinking | Difference |
|---|---|---|---|
| Communication | 3,45 | 2,71 | −0,74 |
| Formation et developpement | 2,89 | 2,31 | −0,58 |
| Specificites regionales | 3,00 | 2,68 | −0,32 |
| Analyse et decisions | 3,60 | 3,26 | −0,34 |
| Recherche d’information | 2,48 | 2,48 | 0,00 |
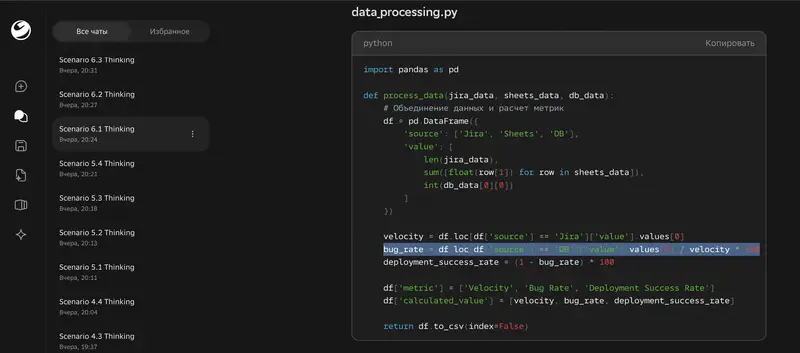
Le pire resultat de Thinking – la generation d’un script Python pour l’automatisation. Ultra a obtenu 3,86, Thinking – 1,25. Moins 2,61 points. La version Thinking a produit du code avec des metriques inventees (« bug rate = deployments / velocity ») et des erreurs de syntaxe critiques. Le code est totalement non fonctionnel.
Deuxieme echec – l’analyse du chiffre d’affaires. Ultra a correctement identifie les schemas dans les donnees et calcule 317,1 k$. Thinking a « deduit » 236,7 k$ – une hallucination dans les calculs intermediaires.
La question merite d’etre posee : si le mode raisonnement degrade le resultat dans cinq categories sur huit – quelle est sa valeur ?
Le mecanisme : pourquoi « reflechir plus longtemps » = « repondre moins bien »
Le probleme de GigaChat Ultra Thinking n’est pas unique. Au cours des deux dernieres annees, une serie d’etudes a documente le meme effet : le raisonnement etendu (extended thinking) dans les modeles de langage n’ameliore pas, mais degrade le resultat pour une proportion significative de taches.
Les reponses incorrectes contiennent deux fois plus de « reflexions »
Une etude (Do Thinking Tokens Help or Trap?, juin 2025) a analyse les reponses du modele DeepSeek-R1. Conclusion principale : les reponses incorrectes contiennent deux fois plus de tokens de reflexion que les reponses correctes. Le modele tombe dans un « piege de raisonnement » – des tokens comme « hmm », « attendons », « par consequent » declenchent des cycles de reverification qui eloignent de la bonne reponse.
La suppression de la generation de tokens de reflexion a conduit a une « degradation minimale de la qualite du raisonnement a tous les niveaux de complexite ». Autrement dit, on peut supprimer la majeure partie des « reflexions » – et le resultat n’en souffre pas.
Les chaines de raisonnement courtes sont 34,5 % plus precises que les longues
Hassid et al. (Don’t Overthink It, mai 2025) ont montre que les chaines de raisonnement courtes sont jusqu’a 34,5 % plus precises que les longues – pour la meme question. Une technique simple – generer plusieurs reponses courtes et choisir la meilleure – utilise jusqu’a 40 % moins de tokens de reflexion tout en produisant un resultat meilleur ou comparable.
Plus de tokens – moins bon resultat
Une etude de Google et de l’Universite de Virginie (Think Deep, Not Just Long, fevrier 2026) a constate une correlation negative de −0,544 entre le nombre de tokens de raisonnement et la precision de la reponse. Tests effectues sur GPT-OSS-20B/120B, DeepSeek-R1-70B, Qwen3-30B. Conclusion des auteurs – « reflechir en profondeur » et « reflechir longtemps » sont deux choses differentes.
Sur le benchmark Omni-MATH, la precision diminue avec l’augmentation du nombre de tokens chez tous les modeles testes : de −0,81 % a −3,16 % pour chaque millier de tokens supplementaires.
La courbe en cloche : d’abord mieux, puis pire
Does Thinking More Always Help? (juin 2025) a decouvert une courbe non monotone « en cloche » : sur GSM-8K, la precision augmente d’abord de 82,2 % a 87,3 % avec un volume de raisonnement modere, puis chute a 70,3 % en cas d’exces. La generation parallele de plusieurs reponses courtes surpasse systematiquement une seule longue chaine de raisonnement.
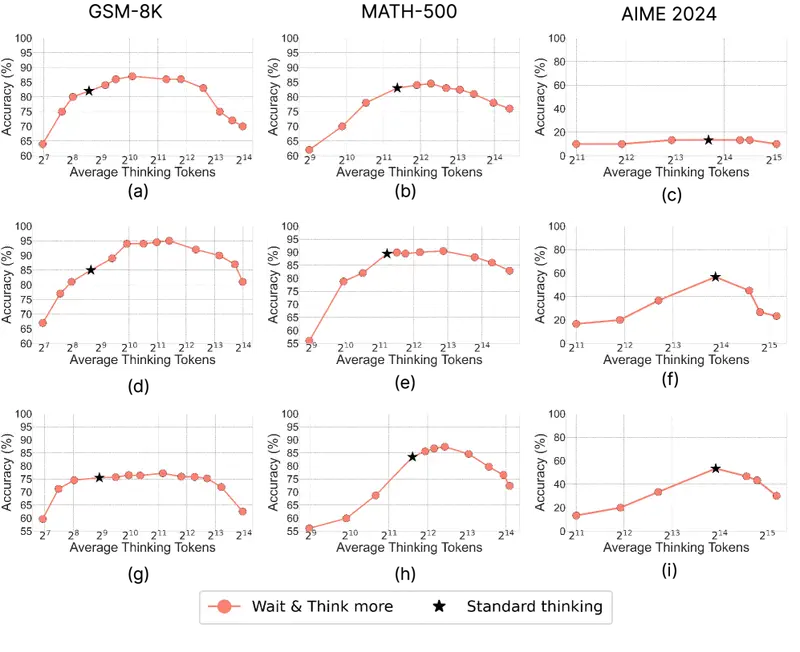
Apple : pour les taches simples, le raisonnement est nefaste
L’article d’Apple (The Illusion of Thinking, 2025) a identifie trois regimes :
- Taches simples – le modele classique sans raisonnement fonctionne mieux que le modele reasoning : plus rapide et plus precis
- Taches moyennes – le modele reasoning prend l’avantage
- Taches complexes – les deux modeles echouent de maniere equivalente, quel que soit le volume de raisonnement
Pour les taches manageriales – correspondance professionnelle, analyse de donnees, generation de code – cela a des implications directes. La plupart de ces taches relevent des categories « simples » et « moyennes », ou le raisonnement etendu nuit ou n’apporte qu’un gain minimal.
Comprenez l'IA de maniere systematique
Quel outil pour quelle tache, comment reperer les hallucinations, comment travailler avec les modeles de raisonnement – nous abordons tout cela dans le programme du cours.
L’overthinking comme probleme systemique
Une revue de plus de 170 travaux (Stop Overthinking, mars 2025) documente le « probleme d’overthinking » comme une propriete systemique des modeles de raisonnement : meme une question triviale « 2+3= ? » peut generer des milliers de tokens de raisonnement sans aucun benefice. Les modeles ne savent pas calibrer le volume de raisonnement en fonction de la complexite de la tache.
Comment distinguer une tache ou l'IA s'en sort d'une tache ou votre expertise est necessaire ? Nous en parlons dans le programme du cours
10 уроков: встраиваете ИИ в планирование, отчётность и кризисное реагирование. Результат – не промпты, а рабочая система.
Ce que cela signifie pour GigaChat Ultra
Nos donnees correspondent parfaitement au schema identifie par la recherche :
Thinking a nui la ou la tache exige des donnees precises. Analyse du chiffre d’affaires, generation de code, travail avec les chiffres – le modele genere de fausses etapes intermediaires qui corrompent la reponse finale. C’est le classique « piege de raisonnement » de Ding et al.
Thinking a aide la ou il faut peser plusieurs facteurs. Analyse des parties prenantes, preparation de negociations complexes, evaluation des risques de recrutement – des taches ou les etapes supplementaires de raisonnement structurent la reponse. C’est la fameuse « complexite moyenne » d’Apple.
La difference entre categories est enorme. De +1,75 a −2,61 points sur des scenarios individuels. L’indicateur moyen (−0,10) masque la realite – Thinking n’est pas « legerement moins bon », il est radicalement meilleur sur certaines taches et catastrophiquement pire sur d’autres.
Classement
Avec un score de 3,04, GigaChat Ultra occupe la 44e place sur 54 modeles dans le classement mis a jour. GigaChat Ultra Thinking – 46e.
Pour comparaison avec les autres modeles russes :
| Modele | Score | Place |
|---|---|---|
| Alice AI LLM (Yandex) | 3,86 | 38 |
| YandexGPT Pro 5.1 | 3,13 | 43 |
| GigaChat Ultra | 3,04 | 44 |
| GigaChat-2-Max | 3,08 | 45 |
| GigaChat-Max-preview | 3,05 | 47 |
| GigaChat Ultra Thinking | 2,94 | 48 |
| GigaChat-Pro-preview | 2,90 | 49 |
La mise a jour du modele phare n’a pas apporte de progres notable. Ultra a essentiellement reproduit le resultat de GigaChat-2-Max (3,08 vs 3,04 – une difference dans la marge d’erreur).
Par ailleurs, le prix de l’API GigaChat reste l’un des plus eleves : 7,22 $ par million de tokens. DeepSeek V3.2 avec un score de 4,42 coute 0,27 $ – 27 fois moins cher pour un resultat 1,45 fois superieur.
Conclusions pratiques
Si vous utilisez deja GigaChat Ultra :
N’activez pas le mode raisonnement par defaut. Utilisez-le uniquement pour les taches impliquant de multiples facteurs – analyse de positions, preparation de negociations complexes, evaluation de risques. Pour tout le reste – le mode standard.
Ne faites pas confiance aux chiffres en mode Thinking. Tout calcul, toute donnee, tout code – reverifiez. Le mode Thinking genere des etapes intermediaires plausibles mais fausses.
Si vous choisissez un modele a partir de zero – Kimi K2.5, Qwen3.5 Plus ou DeepSeek V3.2 donneront un resultat nettement meilleur a moindre cout.
Mais la question est plus large : pourquoi Sber lance-t-il un mode raisonnement comme avantage marketing, alors que six etudes independantes sur 2025–2026 montrent la meme chose – « reflechir plus longtemps » et « reflechir mieux » ne sont pas encore la meme chose pour les modeles de langage ?