Comment évaluer la qualité des LLM en 2026 : guide des benchmarks pour managers

Imaginez que vous choisissez une voiture de fonction pour votre équipe. Un concessionnaire dit : « Notre voiture est la plus rapide. » Un autre : « Nous avons la meilleure consommation. » Un troisième : « Nous sommes leaders en sécurité. » Ils ont tous raison – mais chacun mesure autre chose. Sans comprendre ce qui est mesuré exactement et comment, vous ne pouvez pas comparer les offres objectivement.
Avec les modèles de langage début 2026, la situation est encore plus complexe. GPT-5.3, Claude 4.6, Gemini 3, Perplexity, DeepSeek V4 – chaque entreprise revendique le leadership. Mais comment un manager peut-il comprendre concrètement en quoi un outil est meilleur qu’un autre pour une tâche professionnelle ?
C’est là qu’interviennent les benchmarks – des tests standardisés. En 2026, les anciens tests (comme MMLU) sont devenus moins utiles, car tous les modèles du haut du classement ont appris à les réussir presque parfaitement. Voyons quels indicateurs méritent vraiment d’être examinés aujourd’hui.
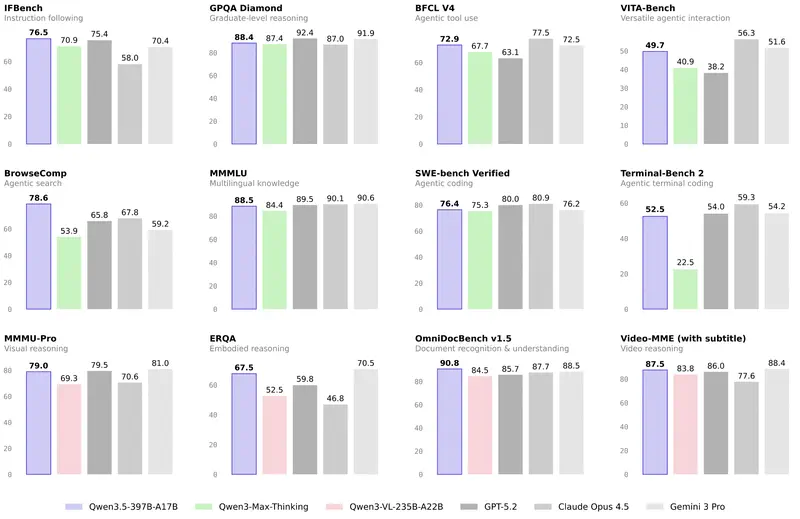
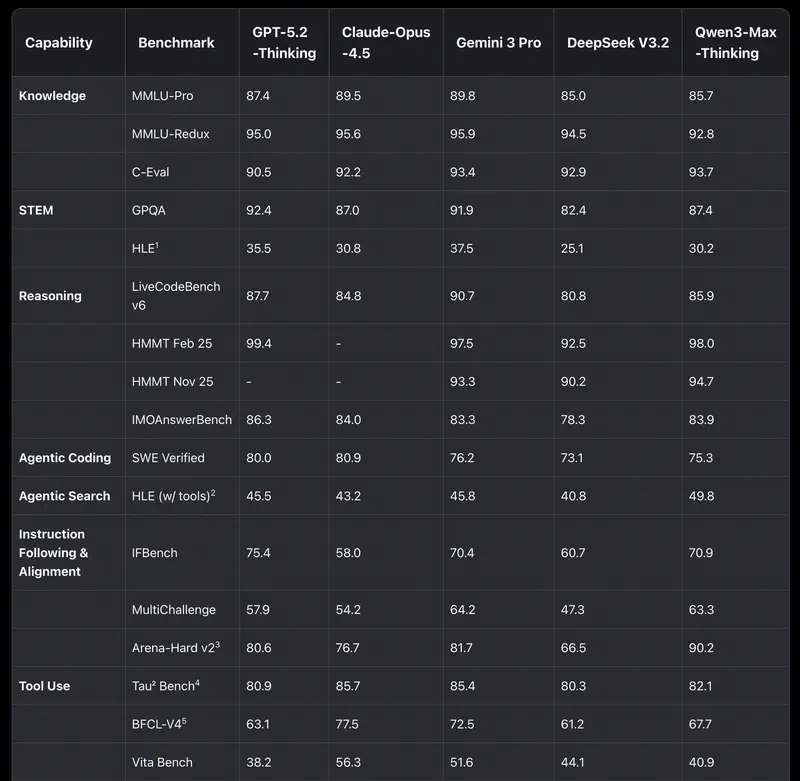
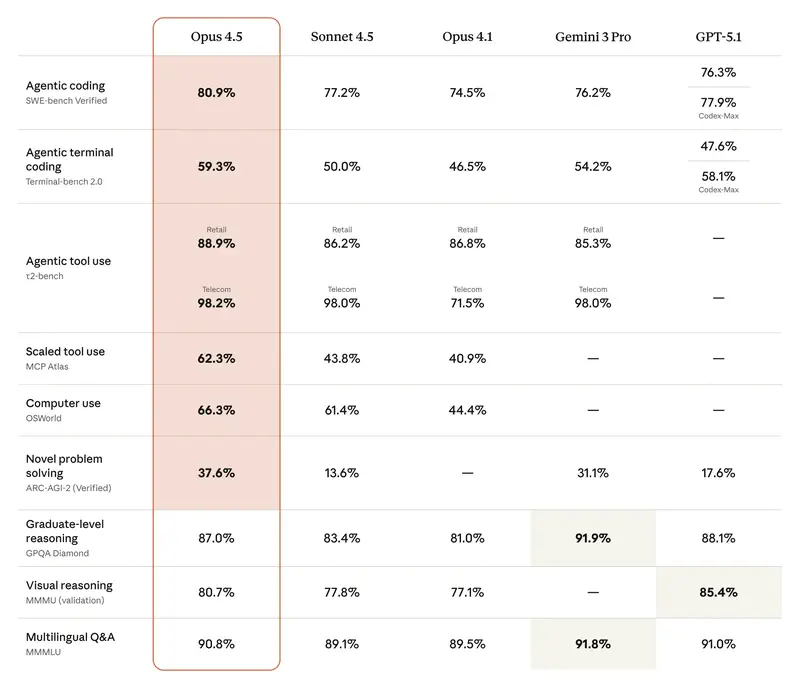
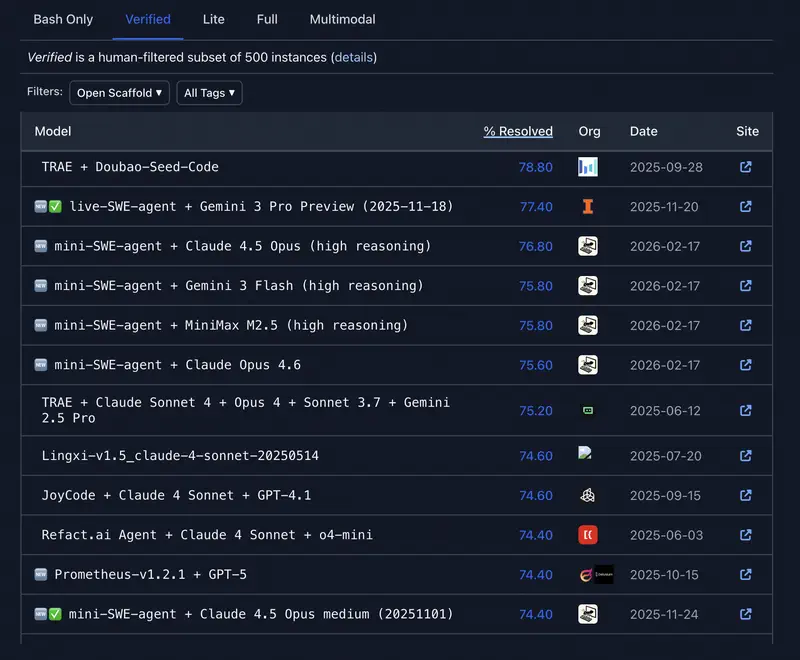
Intuition contre données. Les dirigeants ont souvent un modèle « favori ». Mais l’intuition trompe dans les cas limites. Lorsqu’il faut justifier un budget ou sélectionner un modèle pour automatiser tout un département, il faut des critères objectifs.
Principaux types d’évaluation en 2026
L’évaluation moderne des LLM ne se résume pas à un seul chiffre – il s’agit de comprendre dans quelle « ligue » joue le modèle.
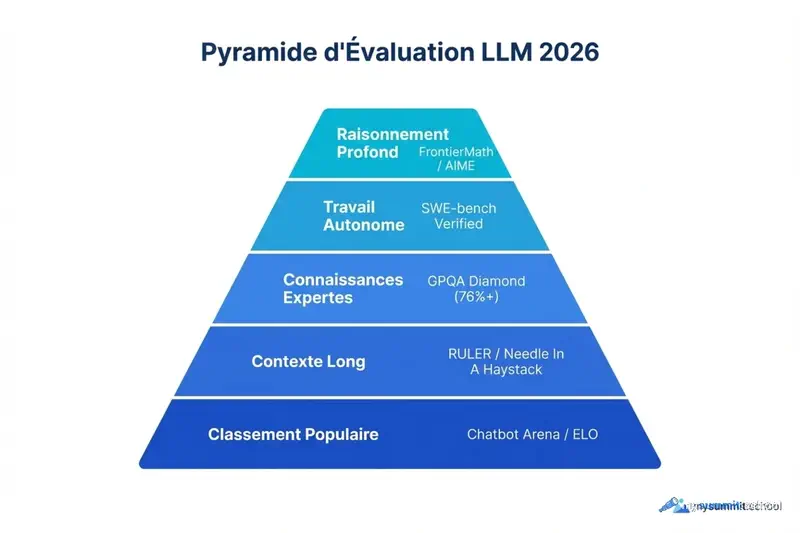
Tableau récapitulatif des catégories actuelles
| Catégorie | Benchmark clé | Ce que ça signifie pour le manager |
|---|---|---|
| Connaissances expertes | GPQA Diamond | Le niveau de compétence du modèle sur des questions de niveau doctoral. Important pour l’audit et la stratégie. |
| Travail autonome | SWE-bench Verified | Capacité du modèle à résoudre des tâches dans du code et des dépôts de manière indépendante. Indicateur d’« agence ». |
| Contexte long | RULER / Needle In A Haystack | Le modèle perd-il de l’information dans un document de plus de 1 000 pages ? |
| Raisonnement profond | FrontierMath / AIME | Capacité à raisonner en plusieurs étapes sans lacunes logiques. |
| Classement populaire | Chatbot Arena (LMSYS) | Comment de vraies personnes évaluent le modèle dans un test aveugle et anonyme. |
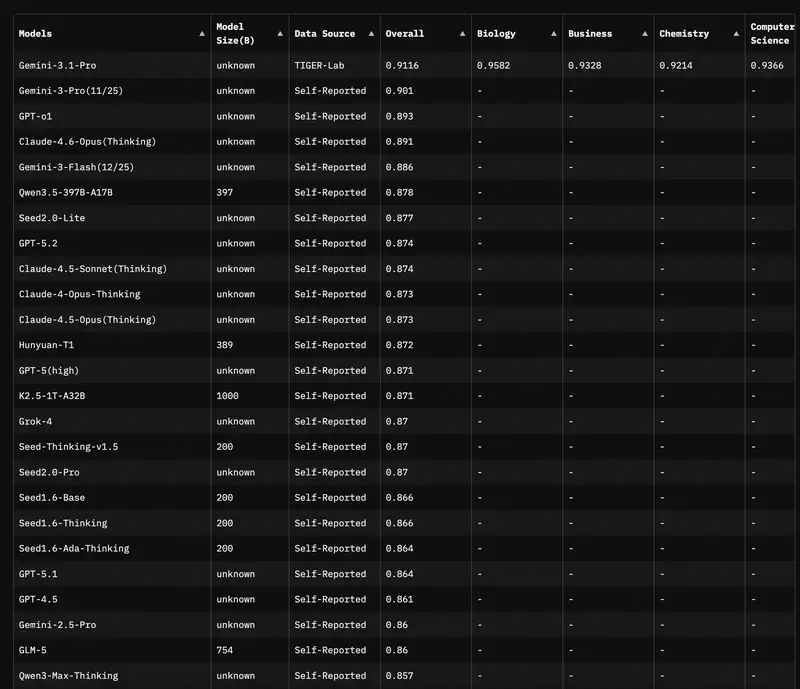
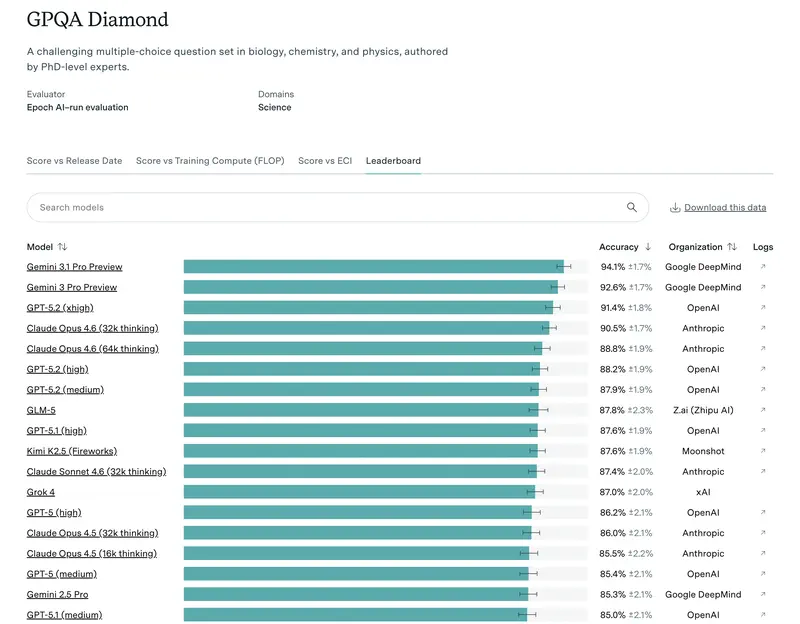
1. Étendue académique (MMLU et GPQA Diamond)
Tout le monde regardait autrefois le MMLU (tests sur 57 disciplines). Mais en 2026, ce test est devenu un « minimum hygiénique de base ». Si un modèle obtient moins de 85–90 %, il ne fait tout simplement pas partie du haut du classement.
Aujourd’hui, l’étalon-or est GPQA Diamond. Ce sont des questions si difficiles que même des experts humains avec accès à internet se trompent dans 60 % des cas. Si un modèle obtient 75 %+ ici, cela signifie que vous pouvez lui confier la vérification des documents juridiques ou financiers les plus complexes.
2. Efficacité agentique (SWE-bench et GAIA)
Pour les managers, c’est la métrique la plus importante en 2026. Elle mesure non pas la « beauté du discours », mais la capacité à accomplir le travail.
- SWE-bench Verified – montre combien de bugs logiciels réels le modèle a pu trouver et corriger seul.
- GAIA – teste le modèle sur des tâches nécessitant l’utilisation du navigateur, la recherche de fichiers et l’usage d’outils.
3. Évaluations utilisateurs : Chatbot Arena
Le classement « populaire » le plus fiable. Sur la plateforme lmarena.ai, les utilisateurs comparent les réponses des modèles à l’aveugle.
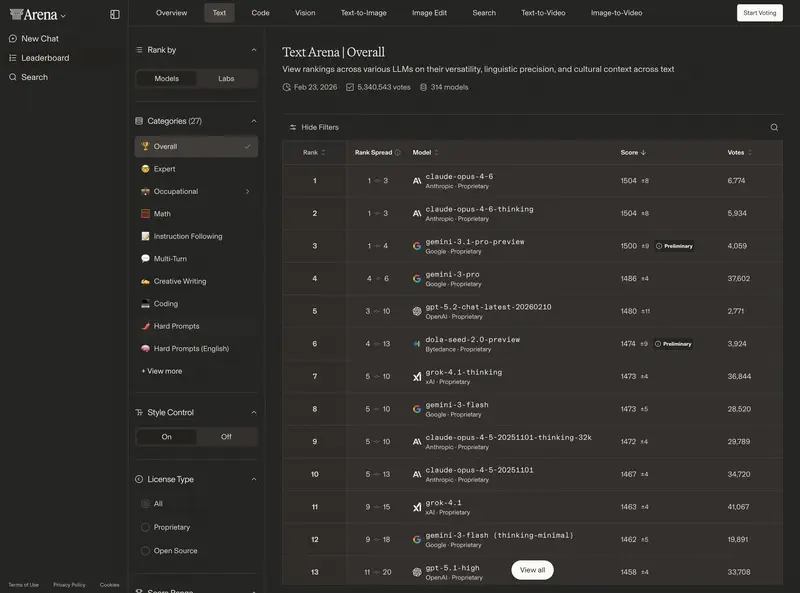
ELO 2026 (repères) :
- 1400–1500+ : modèles de « superintelligence » (GPT-5.3, Claude 4.6 Opus, Gemini 3 Ultra).
- 1300–1400 : excellents chevaux de travail (GPT-5-mini, Sonnet 4.6, DeepSeek V4).
- En dessous de 1200 : modèles obsolètes ou spécialisés.
Une différence de 30–50 points ELO est pratiquement invisible dans la correspondance quotidienne. Une différence de 100+ points signifie un saut qualitatif en intelligence et en compréhension des instructions.
4. Contexte long : RULER et le problème du « perdu au milieu »
Les modèles de 2026 revendiquent des fenêtres de contexte de 1 à 2 millions de tokens. Mais la taille de la fenêtre ≠ la qualité du traitement de cette fenêtre. Le benchmark RULER et le test Needle In A Haystack vérifient si le modèle peut trouver et utiliser correctement des informations cachées dans différentes parties d’un long document.
En 2026, ces deux tests sont devenus davantage un minimum de base. Les modèles du haut de gamme ont appris à localiser des faits isolés dans un long texte. Mais les recherches de 2025 ont montré qu’une grande fenêtre de contexte ne garantit pas un raisonnement fiable – le modèle peut trouver le bon fragment de manière isolée, mais échoue lorsqu’il faut l’intégrer dans un contexte environnant complexe. C’est pourquoi les nouveaux tests (RULERv2, Sequential-NIAH, MMNeedle) vérifient désormais non plus la simple recherche, mais l’agrégation multi-étapes d’informations provenant de différentes parties du document.
Le principal piège s’appelle Lost in the Middle – les modèles gèrent avec assurance le début et la fin du document, mais hallucinent ou omettent des faits du milieu. C’est critique si vous chargez un contrat de 200 pages ou un rapport annuel dans le modèle.
Conseil pratique : Après avoir chargé un long document, posez au modèle une question portant précisément sur des informations situées au milieu du texte. Si la réponse est inexacte ou inventée, le modèle ne gère pas votre volume de données.
Évaluation des modèles de « réflexion approfondie » (Reasoning)
Avec l’arrivée des modèles o3 (OpenAI), R2 (DeepSeek) et Opus Thinking (Anthropic), un nouveau problème d’évaluation est apparu. Ces modèles peuvent « réfléchir » à une réponse de 10 secondes à 5 minutes.
Comment évaluer leur qualité en tant que manager ?
- Précision du résultat – si la tâche est stratégique (par exemple, calculer les risques d’une fusion), le temps d’attente n’a pas d’importance – seule la justesse compte.
- Transparence (CoT) – un bon modèle de raisonnement doit montrer son processus étape par étape (Chain-of-Thought). Cela vous permet d’auditer sa logique.
Guide pratique : comment choisir un modèle
Le choix d’un LLM pour les affaires en 2026 suit un algorithme en trois étapes.
Étape 1 – Définir le rôle
Que fera l’IA 80 % du temps ?
| Rôle | Métrique principale |
|---|---|
| Stratège / Analyste | GPQA Diamond, FrontierMath |
| Employé numérique (Agent) | SWE-bench, GAIA |
| Communicant (Emails, chats) | Chatbot Arena ELO (Overall) |
| Auditeur de documents | Long Context Benchmarks (RULER) |
Étape 2 – Vérifier les benchmarks
Trouvez 2–3 leaders dans la catégorie choisie. Ne regardez pas les graphiques publicitaires des éditeurs (ils choisissent toujours les tests où ils arrivent premiers) – utilisez des ressources indépendantes :
- LMSYS Chatbot Arena – pour l’évaluation globale de la « naturalité » et de la qualité du dialogue.
- Vectara Hallucination Leaderboard 2026 – si la précision factuelle est cruciale pour vous.
- LiveCodeBench / SWE-bench Verified – si vous cherchez un programmeur IA ou un agent.
Étape 3 – « Essai routier » sur vos propres données
Prenez 5 des cas réels les plus complexes de votre travail de la semaine passée. Faites-les passer par les modèles sélectionnés. Évaluez non pas la « beauté », mais la précision des conclusions et l’exhaustivité du suivi des instructions.
Le piège de l’« entraînement à l’examen ». En 2026, la pratique de la « contamination des données » est répandue – les modèles sont entraînés spécifiquement sur les questions des benchmarks populaires. C’est pourquoi vos propres données privées sont le meilleur et le seul benchmark véritablement honnête.
Exercice hors ligne : rendez-vous sur Chatbot Arena, sélectionnez la catégorie « Hard Prompts » et observez le top 3 des modèles. Ce sont vos principaux candidats pour résoudre les tâches professionnelles les plus complexes ce trimestre.
Liens utiles
- LMSYS Chatbot Arena
- GPQA Diamond
- SWE-bench Verified
- GAIA Benchmark
- Vectara Hallucination Leaderboard
- RULER (contexte long)
Cet article fait partie de la série « Revue des outils GenAI 2026 ». Tous les outils sont présentés avec des exercices pratiques dans le cours mysummit.school.
